Selective Coupling of Decoupled Informative Regions: Masked Attention Alignment for Data-Free Quantization of Vision Transformers
Pith reviewed 2026-06-28 06:59 UTC · model grok-4.3
The pith
Vision transformers concentrate semantics in sparse attention patches that can be isolated to generate better synthetic data for quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
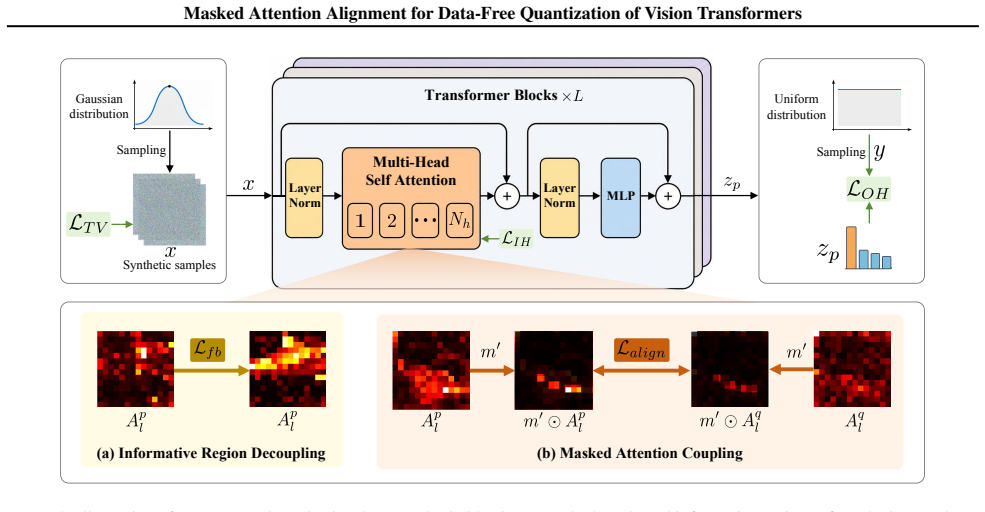
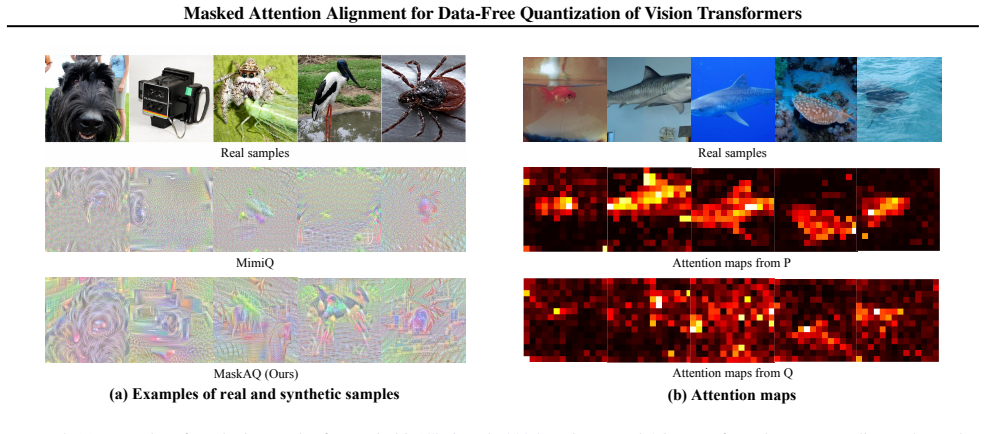
The semantics in the self-attention mechanism is predominantly localized to a sparse subset of patches, called informative regions; the informative regions dominate the mutual information between synthetic samples and Q's outputs. Maximizing differential entropy over patch similarity of synthetic samples decouples these informative regions from noisy background, after which the regions are selected to align full-precision models with the quantized model Q via a masked attention alignment objective, yielding high-quality synthetic samples that are refreshed periodically to adapt to the evolving state of Q.
What carries the argument
Masked attention alignment objective, which uses differential-entropy maximization on patch similarity to decouple informative regions and then selectively couples them to align full-precision and quantized ViT models.
If this is right
- Synthetic samples exhibit reduced distribution mismatch with the input distribution expected by quantized ViTs.
- Performance exceeds prior data-free quantization methods across multiple ViT backbones and downstream tasks.
- Periodic sample refreshing allows the synthetic data to track changes in the quantized model throughout training.
- Mutual information between synthetic samples and quantized outputs is preserved by focusing alignment on the decoupled informative regions.
Where Pith is reading between the lines
- The sparsity finding may extend to other attention-heavy architectures such as language models or multimodal transformers.
- If the informative regions prove stable across tasks, precomputed region masks could accelerate repeated quantization runs.
- The entropy-based decoupling step could be tested with alternative similarity metrics to see whether region isolation improves.
- The selective coupling idea suggests that attention sparsity itself could be exploited in other model-compression pipelines beyond quantization.
Load-bearing premise
Maximizing differential entropy over patch similarity of synthetic samples will reliably isolate the informative regions that actually drive the quantized model's outputs.
What would settle it
An experiment that masks the entropy-selected patches versus random patches and finds no larger change in the quantized model's output distribution or accuracy would falsify the claim that the selected regions dominate the relevant mutual information.
Figures



read the original abstract
Data-Free Quantization (DFQ) addresses data security concerns by synthesizing samples, without accessing real data. It has garnered increasing attention in the context of Vision Transformers (ViTs), owing to the superiority of the self-attention mechanism compared to classical convolutional operation. However, previous DFQ arts for ViTs often suffer from a distribution mismatch between synthetic samples and input distribution expected by quantized models Q, resulting in the suboptimal performance. In this paper, we propose a novel Masked Attention Alignment approach for Data-Free Quantization of ViTs, named MaskAQ, revealing that: 1) the semantics in the self-attention mechanism is predominantly localized to a sparse subset of patches, called informative regions; 2) the informative regions dominate the mutual information between synthetic samples and Q's outputs. To these ends, we incorporate differential entropy maximum over patch similarity of synthetic samples, to decouple informative regions from noisy background. To couple with varied Q, the informative regions are selected to align full-precision models with Q via a masked attention alignment objective, thus yielding high-quality synthetic samples. Furthermore, a periodic sample refreshing strategy comes up to endow MaskAQ with the capacity to continually adapt to the evolving state of Q throughout the training process, to preserve desirable mutual information with synthetic samples. Extensive experiments verify the merits of MaskAQ over state-of-the-art approaches across multiple backbones and downstream tasks. Our code is available at https://github.com/hfutqian/MaskAQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MaskAQ, a data-free quantization method for Vision Transformers. It claims that self-attention semantics localize to sparse 'informative regions' that dominate mutual information between synthetic samples and quantized model outputs. The approach decouples these regions via differential entropy maximization over patch similarity statistics of synthetic samples, then couples them to the quantized model Q through a masked attention alignment objective; a periodic sample refreshing strategy adapts to Q's evolving state during training. Experiments reportedly demonstrate superiority over prior DFQ methods across multiple ViT backbones and tasks.
Significance. If the core assumptions hold and the method generalizes, MaskAQ could meaningfully advance data-free quantization for attention-based models by mitigating distribution mismatch through targeted region alignment rather than global statistics. The public code release supports reproducibility and allows direct verification of the reported gains.
major comments (2)
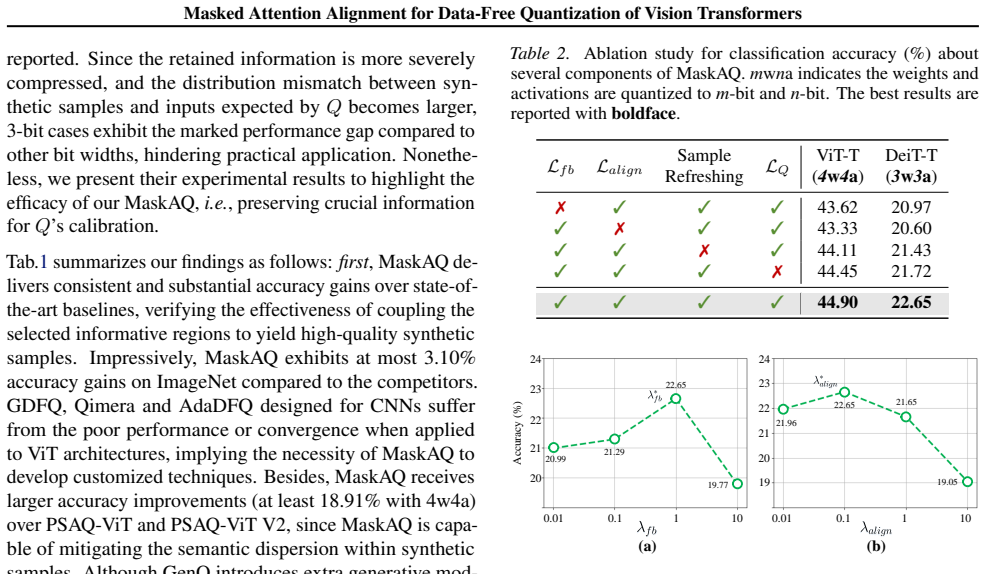
- [Abstract / §3] Abstract and Method (no equation shown): the central claim that 'informative regions dominate the mutual information between synthetic samples and Q's outputs' is asserted without a derivation showing why differential entropy maximization on patch-similarity matrices must select patches that actually carry the dominant MI term with Q for arbitrary ViT architectures or bit-widths. This assumption is load-bearing for both the decoupling and the subsequent masked alignment steps.
- [§3.2] Method description: the masked attention alignment objective assumes rather than demonstrates that the entropy-selected mask preserves the dominant MI term when coupled to Q; if the criterion selects generator-salient but low-attention patches in the target Q, the alignment cannot recover the claimed dominance. No cross-architecture or cross-bit-width analysis is referenced to test this.
minor comments (1)
- [Abstract] The abstract is unusually long and contains multiple distinct claims; condensing the motivation and contributions would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. Below we address each major comment directly, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and Method (no equation shown): the central claim that 'informative regions dominate the mutual information between synthetic samples and Q's outputs' is asserted without a derivation showing why differential entropy maximization on patch-similarity matrices must select patches that actually carry the dominant MI term with Q for arbitrary ViT architectures or bit-widths. This assumption is load-bearing for both the decoupling and the subsequent masked alignment steps.
Authors: The claim originates from empirical observations that self-attention semantics in ViTs concentrate in sparse patches, which we support with attention visualizations in the manuscript. Differential entropy maximization over patch-similarity statistics is introduced to promote diversity among patches and thereby isolate regions with high semantic content. While a general closed-form derivation applicable to every architecture and bit-width is not provided, the approach is motivated by the information-theoretic intuition that maximizing entropy of similarity distributions reduces redundancy and highlights dominant contributors to model outputs. In the revised manuscript we will expand §3 with additional discussion of this rationale, including further visualizations that correlate the selected regions with attention weights in both the generator and Q. revision: partial
-
Referee: [§3.2] Method description: the masked attention alignment objective assumes rather than demonstrates that the entropy-selected mask preserves the dominant MI term when coupled to Q; if the criterion selects generator-salient but low-attention patches in the target Q, the alignment cannot recover the claimed dominance. No cross-architecture or cross-bit-width analysis is referenced to test this.
Authors: We agree that an explicit demonstration of MI preservation would improve clarity. The current experimental section already reports results across multiple ViT backbones (DeiT, PVT, Swin) and bit-width configurations (W4A4, W8A8), with consistent gains over prior DFQ methods. To directly address the concern, the revised version will include a new ablation subsection that quantifies the overlap between entropy-selected masks and high-attention regions in Q, together with a comparison of mutual-information estimates (or proxy metrics) before and after alignment. This analysis will be performed across the same set of architectures and bit-widths already evaluated. revision: yes
Circularity Check
No circularity; derivation rests on empirical assumptions validated externally
full rationale
The paper's central claims—that informative regions dominate mutual information and can be isolated via differential entropy maximization on patch similarity—are presented as observations motivating the MaskAQ method, with the masked attention alignment and periodic refreshing as practical steps. No equations, self-citations, or fitted parameters are shown in the provided text that reduce the claimed performance gains or the MI dominance to a quantity defined by construction from the same synthetic samples or outputs. The approach is framed as relying on extensive experiments across backbones and tasks for verification, making the derivation self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450,
-
[2]
Dosovitskiy, A. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929,
Pith/arXiv arXiv 2010
-
[3]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.),Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stan- ford, CA,
2000
-
[4]
arXiv:2102.05426. 10 Masked Attention Alignment for Data-Free Quantization of Vision Transformers Li, Y ., Kim, Y ., Lee, D., Kundu, S., and Panda, P. Genq: Quantization in low data regimes with generative syn- thetic data. InEuropean Conference on Computer Vision, pp. 216–235. Springer,
-
[5]
Lin, Y ., Zhang, T., Sun, P., Li, Z., and Zhou, S. Fq-vit: Post-training quantization for fully quantized vision trans- former.arXiv preprint arXiv:2111.13824,
-
[6]
Tishby, N., Pereira, F. C., and Bialek, W. The informa- tion bottleneck method.arXiv preprint physics/0004057,
-
[7]
12 Masked Attention Alignment for Data-Free Quantization of Vision Transformers A
doi: 10.1109/CVPR.2017.544. 12 Masked Attention Alignment for Data-Free Quantization of Vision Transformers A. Details of Related Work As indicated in Sec.1 of the main body, we provide the comprehensive review of related work in this section, which mainly encompasses Vision Transformer architectures, data-driven quantization and data-free quantization ap...
-
[8]
Other lines of research modify the ViT architecture to better capture multi-scale and local visual structure
introduced a data-efficient training method with token-based distillation, achieving competitive performance on ImageNet without massive external datasets and thus facilitating practical ViT adoption. Other lines of research modify the ViT architecture to better capture multi-scale and local visual structure. For example, Swin Transformer (Liu et al., 202...
2020
-
[9]
and video recognition (Arnab et al., 2021; Neimark et al., 2021). Therefore, the DFQ for ViTs are directly influenced by their architectural distinctions from Convolutional Neural Networks (CNNs), including patch-based tokenization, LayerNorm usage, attention-driven operations, and the distribution sensitivity of multi-head activations. A.2. Data-Driven Q...
2021
-
[10]
However, both QAT and PTQ necessitate access to the original training data, which poses significant risks to data privacy and security in data-sensitive application scenarios
employs Hessian-aware reconstruction techniques with improved importance weighting to stabilize ultra-low precision (3-4 bit) quantization for ViTs. However, both QAT and PTQ necessitate access to the original training data, which poses significant risks to data privacy and security in data-sensitive application scenarios. A.3. Data-Free Quantization for ...
2020
-
[11]
and our MaskAQ, apart from the corresponding real samples. C. Additional Discussions and Results As indicated in Sec.3.1 of the main body, we further offer additional discussions and more experimental results. C.1. Additional Results on Object Detection and Semantic Segmentation Tasks Apart from the image classification task in the main body, we further r...
2014
-
[12]
Table 3 suggests that our MaskAQ achieves great improvements over other approaches
and PSAQ-ViT V2 (Li et al., 2023a), we adopt the results reported in MimiQ (Choi et al., 2025). Table 3 suggests that our MaskAQ achieves great improvements over other approaches. For example, MaskAQ exhibits at most 0.92 and 1.24 gains on the COCO and ADE20K datasets, compared to state-of-the-art approaches,e.g., MimiQ. The above fact further confirms th...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.