Context-as-AI-Service: Surfacing Cross-File Dependency Chains for LLM-Generated Developer Documentation
Pith reviewed 2026-06-28 05:35 UTC · model grok-4.3
The pith
A retrieval layer called CAIS enables LLM agents to trace cross-file dependencies when reviewing and generating developer documentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
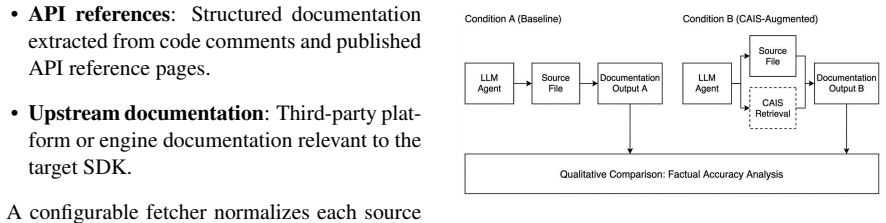
CAIS is a retrieval layer that LLM agents query to find evidence across the codebase as they review or generate documentation. In two case studies on a production SDK, the CAIS-augmented agent using Claude Sonnet 4.6 produced the same five missing-documentation fixes as the baseline in API-reference review but surfaced four additional findings the baseline missed, including two cross-file factual errors and two underspecified API comments. In tutorial validation it surfaced one executable bug, one API-usage improvement, and two missing prerequisites that the baseline did not catch. Over five runs per condition, adding CAIS reduced wall-clock time by 22% to 34% across the two tasks and lowere
What carries the argument
Context-as-AI-Service (CAIS), a retrieval layer that indexes source code, API references, and upstream documentation then enables agents to query the index through tool calls that combine keyword and semantic search.
If this is right
- The CAIS-augmented agent identifies two cross-file factual errors and two underspecified API comments missed by the baseline in API reference review.
- The CAIS-augmented agent identifies one executable bug, one API-usage improvement, and two missing prerequisites in tutorial validation that the baseline misses.
- Adding CAIS reduces wall-clock time by 22% to 34% across the two documentation tasks.
- Adding CAIS lowers input-token usage in the agent workflows.
Where Pith is reading between the lines
- CAIS could be applied to other LLM-assisted software engineering tasks such as code review or test generation to surface hidden dependencies.
- Testing CAIS on multiple SDKs or with different base LLMs would help determine if the time savings and extra findings generalize.
- The method assumes that the indexed content captures the relevant dependency chains, which may not hold for very large or poorly documented codebases.
Load-bearing premise
The two case studies on a single production SDK with Claude Sonnet 4.6, using a baseline that already includes ordinary repository tools, sufficiently isolate the benefit of the added retrieval layer and that the surfaced findings represent meaningful improvements in documentation quality.
What would settle it
Performing the API-reference review and tutorial validation tasks multiple times with only the baseline agent and verifying that it consistently misses the four and three additional findings reported with CAIS.
Figures

read the original abstract
LLM agents increasingly write and maintain developer documentation, but usefulness and accuracy often rely on dependency chains that are not obvious to follow. Even with more files in context, the agent must still decide which cross-file dependencies to trace. We present Context-as-AI-Service (CAIS), a retrieval layer that LLM agents query to find evidence across the codebase as they review or generate documentation. CAIS indexes source code, API references, and upstream documentation, then enables agents to query the index through tool calls that combine keyword and semantic search. We evaluate CAIS in two case studies using Claude Sonnet 4.6 on a production SDK: improving API reference comments in a core source file and validating an LLM-generated tutorial. In both studies, the baseline already had ordinary repository tools such as file reads, keyword search, and symbol navigation. CAIS adds a retrieval layer on top, so the comparison isolates added retrieval rather than basic repository access. In the API-reference review, the CAIS-augmented agent produced the same 5 missing-documentation fixes as the baseline and surfaced 4 findings the baseline missed: 2 cross-file factual errors and 2 underspecified API comments. In the tutorial validation, it surfaced 1 executable bug, 1 API-usage improvement, and 2 missing prerequisites that the baseline pipeline did not catch. These findings required tracing non-obvious dependency chains across utility files, framework internals, usage examples, tests, and component-creation logic. Over five runs per condition, adding CAIS reduced wall-clock time by 22% to 34% across the two tasks and lowered input-token usage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Context-as-AI-Service (CAIS), a retrieval layer that LLM agents query via tool calls combining keyword and semantic search to surface cross-file dependency chains from indexed source code, API references, and documentation. It evaluates CAIS in two case studies on a production SDK using Claude Sonnet 4.6, with a baseline that already includes file reads, keyword search, and symbol navigation. The claims are that CAIS-augmented agents surface additional issues (4 in API-reference review: 2 cross-file factual errors and 2 underspecified comments; 3 in tutorial validation: 1 executable bug, 1 API-usage improvement, and 2 missing prerequisites) while reducing wall-clock time by 22-34% and input-token usage over five runs per condition.
Significance. If the reported findings hold after validation, the work demonstrates a practical, incremental retrieval service that isolates added value over standard repository tooling for LLM-driven documentation tasks. The concrete counts of surfaced issues and the measured efficiency gains (time and tokens) provide tangible evidence of benefit in handling non-obvious dependency chains across utility files, tests, and examples. This design point—layering a queryable index atop basic tools—could usefully inform agent architectures in software engineering.
major comments (3)
- [Evaluation] Evaluation section (case studies): the claim that CAIS surfaced 4 additional findings the baseline missed (2 cross-file factual errors, 2 underspecified API comments) and 3 in the tutorial task rests solely on author-determined outcomes from five runs, without reported expert review, ground-truth documentation, or blinded comparison demonstrating the baseline could not reach them despite equivalent effort. This directly affects whether the quality delta can be attributed to the retrieval layer.
- [Evaluation] Evaluation section: time reductions of 22% to 34% and lowered input-token usage are reported over five runs per condition, yet no statistical analysis, variance measures, error bars, or significance tests are provided to support the reliability of these quantitative results.
- [Case Studies] Case study descriptions: the evaluation uses only a single production SDK; while this yields specific examples of cross-file tracing, the absence of additional systems limits assessment of whether the benefit of the CAIS retrieval layer generalizes.
minor comments (2)
- [Abstract] Abstract: the model is referred to as 'Claude Sonnet 4.6'; the methods section should specify the exact version, temperature, and any system prompts used for reproducibility.
- Consider adding a summary table listing findings by condition (baseline vs. CAIS) and task to improve readability of the results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation methodology. We address each major comment below and will make targeted revisions to improve transparency and acknowledge limitations without overstating the current results.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (case studies): the claim that CAIS surfaced 4 additional findings the baseline missed (2 cross-file factual errors, 2 underspecified API comments) and 3 in the tutorial task rests solely on author-determined outcomes from five runs, without reported expert review, ground-truth documentation, or blinded comparison demonstrating the baseline could not reach them despite equivalent effort. This directly affects whether the quality delta can be attributed to the retrieval layer.
Authors: We agree that the additional findings were identified through author inspection of agent outputs rather than independent expert review or blinded assessment. In the revised manuscript we will add a detailed subsection describing the verification process for each finding (cross-referencing against source files, API specs, and test results) and will explicitly list this as a methodological limitation. The case studies remain useful for illustrating concrete dependency chains that CAIS enabled the agent to surface in the reported runs, but we will not claim they constitute a controlled quality comparison. revision: partial
-
Referee: [Evaluation] Evaluation section: time reductions of 22% to 34% and lowered input-token usage are reported over five runs per condition, yet no statistical analysis, variance measures, error bars, or significance tests are provided to support the reliability of these quantitative results.
Authors: We accept this observation. The revision will report per-run wall-clock times and token counts, include standard deviations, and present the data with error bars. Given the small number of runs we will frame the results as descriptive rather than inferential and will avoid significance testing. revision: yes
-
Referee: [Case Studies] Case study descriptions: the evaluation uses only a single production SDK; while this yields specific examples of cross-file tracing, the absence of additional systems limits assessment of whether the benefit of the CAIS retrieval layer generalizes.
Authors: The evaluation is confined to one production SDK, which restricts generalizability claims. We will add an explicit Limitations subsection that states this constraint and outlines future work to evaluate CAIS on additional codebases. The current results are presented as concrete illustrations of the retrieval layer's utility rather than broad empirical proof. revision: partial
Circularity Check
No circularity: empirical case studies with direct baseline comparison
full rationale
The paper presents CAIS as a retrieval layer evaluated through two case studies on a production SDK using Claude Sonnet 4.6. The baseline already includes standard repository tools, and CAIS is added on top for isolation. Reported outcomes (identical fixes plus additional findings, plus 22-34% time/token reductions over five runs) are direct observations from agent runs, with no equations, fitted parameters, predictions derived from inputs, or derivation chains. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the abstract or described structure. The evaluation is self-contained against the stated baseline without reducing to self-definition or renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author=. 2021 , archivePrefix=. doi:10.48550/arXiv.2107.03374 , url=. 2107.03374 , journal=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374 2021
-
[2]
2023 , url=
Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming , booktitle=. 2023 , url=
2023
-
[3]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems 33 (NeurIPS 2020) , editor=. 2020 , doi=
2020
-
[4]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Syntax-Aware Retrieval Augmented Code Generation , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=. 2023 , publisher=. doi:10.18653/v1/2023.findings-emnlp.90 , url=
-
[5]
Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
Retrieval Augmented Code Generation and Summarization , author=. Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=. 2021 , publisher=. doi:10.18653/v1/2021.findings-emnlp.232 , url=
-
[6]
Sridhara, Giriprasad and Hill, Emily and Muppaneni, Divya and Pollock, Lori and Vijay-Shanker, K. , booktitle=. Towards Automatically Generating Summary Comments for. 2010 , publisher=. doi:10.1145/1858996.1859006 , url=
-
[7]
Proceedings of the 22nd International Conference on Program Comprehension , pages=
Automatic Documentation Generation via Source Code Summarization of Method Context , author=. Proceedings of the 22nd International Conference on Program Comprehension , pages=. 2014 , publisher=. doi:10.1145/2597008.2597149 , url=
-
[8]
Proceedings of the 26th International Conference on Program Comprehension , pages=
Deep Code Comment Generation , author=. Proceedings of the 26th International Conference on Program Comprehension , pages=. 2018 , publisher=. doi:10.1145/3196321.3196334 , url=
-
[9]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
A Transformer-based Approach for Source Code Summarization , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=. 2020 , address=. doi:10.18653/v1/2020.acl-main.449 , url=
-
[10]
Automatic Code Documentation Generation Using
Khan, Junaed Younus and Uddin, Gias , booktitle=. Automatic Code Documentation Generation Using. 2022 , publisher=. doi:10.1145/3551349.3559548 , url=
-
[11]
Proceedings of the 46th International Conference on Software Engineering , pages=
Large Language Models are Few-Shot Summarizers: Multi-Intent Comment Generation via In-Context Learning , author=. Proceedings of the 46th International Conference on Software Engineering , pages=. 2024 , publisher=. doi:10.1145/3597503.3608134 , url=
-
[12]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle=
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle=. 2024 , url=
2024
-
[13]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=. 2024 , url=
2024
-
[14]
2025 , url =
Ma, Xueguang and Lin, Xi Victoria and Oguz, Barlas and Lin, Jimmy and Yih, Wen-tau and Chen, Xilun , journal =. 2025 , url =
2025
-
[15]
and Clarke, Charles L
Cormack, Gordon V. and Clarke, Charles L. A. and B. Reciprocal rank fusion outperforms Condorcet and individual rank learning methods , booktitle =. 2009 , organization=
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.