Low-Rank Decay for Grokking in Scale-Invariant Transformers: A Spectral-Geometric View
Pith reviewed 2026-06-28 07:35 UTC · model grok-4.3
The pith
In scale-invariant transformers, Low-Rank Decay continues reshaping weights after memorization via its tangential subgradient, unlike L2 decay, and thereby expands the data fraction at which grokking occurs on modular tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
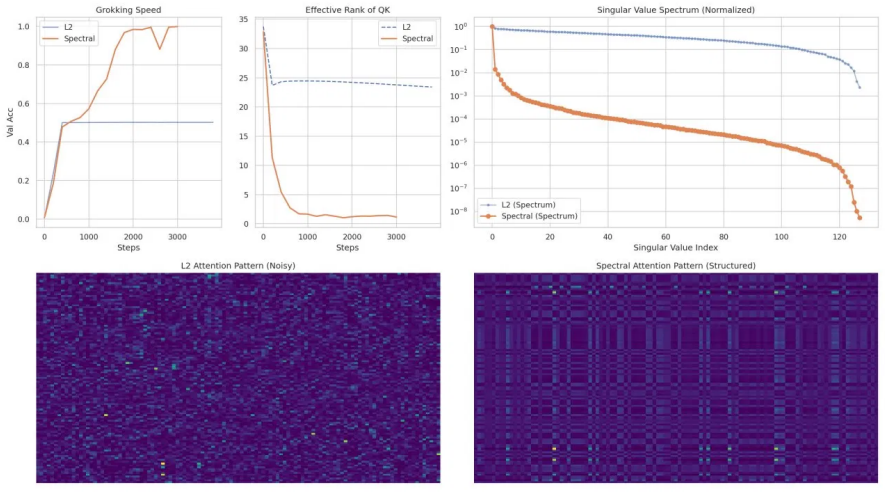
Low-Rank Decay supplies a tangential regularization direction that persists in the scale-invariant regime after task gradients reach zero; consequently the singular values of the normalized layers continue to decay, the effective rank of Query/Key matrices collapses, and the data-fraction threshold for grokking on modular arithmetic is enlarged.
What carries the argument
Low-Rank Decay (LRD), whose subgradient is the polar factor UV^T of the nuclear-norm proximal operator and therefore retains a tangential component even when the weight is constrained to the unit sphere by normalization.
If this is right
- LRD induces rapid effective-rank collapse in Query/Key matrices on modular arithmetic tasks.
- LRD expands the data-fraction boundary at which delayed generalization (grokking) occurs.
- After task gradients vanish, LRD continues to compress singular values while standard L2 decay cannot.
- The needle-to-fan expansion of the nuclear-norm subdifferential supplies the geometric mechanism near low-rank strata.
Where Pith is reading between the lines
- The same tangential regularization could be examined in other normalized architectures where radial penalties lose influence after early training.
- Measuring the evolution of singular-value spectra under LRD on non-algorithmic sequence tasks would test whether the rank-compression effect extends beyond modular arithmetic.
Load-bearing premise
The polar factor UV^T of the nuclear-norm subgradient supplies a non-zero tangential component that continues to reshape the function after task gradients vanish in the scale-invariant regime.
What would settle it
Applying Low-Rank Decay to the same modular-arithmetic training runs and observing neither measurable drop in effective rank of the Query/Key matrices nor any increase in the range of data fractions that exhibit grokking would falsify the claimed dynamical advantage over L2 decay.
Figures

read the original abstract
Modern Transformer architectures frequently employ normalization mechanisms such as RMSNorm and Query-Key Normalization, making parts of the model approximately scale-invariant with respect to weight magnitudes. In this regime, standard Frobenius-norm weight decay acts purely along the radial direction of the weight space and cannot directly simplify the function represented by the normalized layer. We study grokking in small algorithmic tasks through this lens and propose \emph{Low-Rank Decay} (LRD), a nuclear-norm-like spectral regularizer whose subgradient -- the polar factor $UV^\top$ -- retains a tangential component even in the scale-invariant setting. This distinction has a concrete dynamical consequence: after the model memorizes the training set and task gradients vanish, L2 decay can no longer reshape the weight spectrum, whereas LRD continues to compress singular values in an $\ell_1$-like fashion. On modular arithmetic tasks, we find that LRD induces rapid effective-rank collapse in Query/Key matrices and expands the data-fraction boundary at which delayed generalization (grokking) occurs. We further provide a spectral-geometric interpretation through the ``needle-to-fan'' expansion of the nuclear-norm subdifferential near low-rank strata.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that in scale-invariant Transformer components (RMSNorm + QK-norm), standard L2 weight decay acts only radially and cannot reshape the function after task gradients vanish, whereas Low-Rank Decay (LRD) — a nuclear-norm regularizer whose subgradient is the polar factor UV^T — retains a tangential component that continues to compress singular values in an ℓ1-like manner. On modular arithmetic tasks this produces rapid effective-rank collapse in Query/Key matrices and expands the training-data fraction at which grokking occurs; the paper supplies a spectral-geometric account via the “needle-to-fan” expansion of the nuclear-norm subdifferential near low-rank strata.
Significance. If the claimed tangential mechanism is isolated and shown to be responsible for the observed rank collapse, the work supplies both a practical spectral regularizer for scale-invariant networks and a geometric explanation for delayed generalization. The explicit contrast between radial L2 decay and the subdifferential geometry of LRD is a clear conceptual advance.
major comments (2)
- [§3.2, Eq. (8)] §3.2, Eq. (8): the assertion that UV^T remains non-aligned with the radial direction (and therefore supplies persistent tangential drive) after task gradients vanish is stated without an explicit inner-product calculation under the concrete normalization (RMSNorm + QK-norm). The derivation assumes generic scale-invariance; a direct verification that ⟨UV^T, W⟩ = 0 (or a small residual) is required to support the central dynamical distinction.
- [§5.2, Table 2] §5.2, Table 2 and Figure 5: the reported expansion of the grokking data-fraction boundary is shown for LRD versus L2, but no control experiment isolates the tangential component from generic spectral bias (e.g., an ℓ1 penalty applied directly to singular values or a low-rank projection step). Without this ablation the observed rank collapse could arise from optimization artifacts unrelated to the claimed geometric mechanism.
minor comments (2)
- The term “needle-to-fan” expansion is introduced in the abstract and §4 but is not given a one-sentence definition on first use; a brief parenthetical gloss would improve readability.
- [§5.1] Notation for the effective rank (e.g., participation ratio versus numerical rank) is used interchangeably in §5.1; a single consistent definition and symbol would eliminate ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and outline revisions that will strengthen the manuscript's support for the claimed tangential mechanism.
read point-by-point responses
-
Referee: [§3.2, Eq. (8)] §3.2, Eq. (8): the assertion that UV^T remains non-aligned with the radial direction (and therefore supplies persistent tangential drive) after task gradients vanish is stated without an explicit inner-product calculation under the concrete normalization (RMSNorm + QK-norm). The derivation assumes generic scale-invariance; a direct verification that ⟨UV^T, W⟩ = 0 (or a small residual) is required to support the central dynamical distinction.
Authors: The manuscript presents the non-alignment from the general scale-invariance property induced by RMSNorm + QK-norm, under which the loss is invariant to radial rescaling. We agree, however, that an explicit inner-product verification tailored to this normalization would provide stronger support. In the revision we will add a direct calculation confirming that ⟨UV^T, W⟩ = 0 (or a negligible residual) holds under the concrete normalization, thereby verifying that the polar factor retains a tangential component after task gradients vanish. revision: yes
-
Referee: [§5.2, Table 2] §5.2, Table 2 and Figure 5: the reported expansion of the grokking data-fraction boundary is shown for LRD versus L2, but no control experiment isolates the tangential component from generic spectral bias (e.g., an ℓ1 penalty applied directly to singular values or a low-rank projection step). Without this ablation the observed rank collapse could arise from optimization artifacts unrelated to the claimed geometric mechanism.
Authors: We acknowledge that the present experiments contrast LRD only with L2 decay and do not include ablations that isolate the tangential subdifferential effect from other spectral biases. While the geometric account and the observed difference in rank collapse support the mechanism, additional controls would strengthen attribution. We will add experiments applying an ℓ1 penalty directly to singular values and low-rank projection steps in the revised manuscript. revision: yes
Circularity Check
No significant circularity; central claims rest on proposed mechanism and empirical observation
full rationale
The paper defines LRD via the nuclear-norm subgradient UV^T and states its tangential component as a direct consequence of that definition in the scale-invariant regime. The claimed dynamical distinction (L2 decay becomes purely radial while LRD continues to compress singular values) follows from the standard subdifferential of the nuclear norm without redefinition or reduction to fitted parameters. The reported effects on effective-rank collapse and grokking boundaries are presented as empirical outcomes on modular arithmetic tasks. No load-bearing step reduces by construction to a self-citation, an ansatz smuggled via prior work, or a fitted input renamed as prediction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The subdifferential of the nuclear norm at a matrix X with SVD X= U Sigma V^T is UV^T plus a term in the orthogonal complement of the range of U and V.
invented entities (1)
-
Low-Rank Decay regularizer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Power, Y
A. Power, Y. Burda, H. Edwards, I. Babuschkin, and V. Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. InICLR Workshop on Deep Learning for Code, 2022. 8
2022
-
[2]
Nanda, L
N. Nanda, L. Chan, T. Liberum, J. Smith, and J. Steinhardt. Progress measures for grokking via mechanistic interpretability. InInternational Conference on Learning Representations, 2023
2023
-
[3]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017
2017
-
[4]
Zhang and R
B. Zhang and R. Sennrich. Root mean square layer normalization. InAdvances in Neural Information Processing Systems, 2019
2019
-
[5]
Theoretical Analysis of Auto Rate-Tuning by Batch Normalization
S. Arora, Z. Li, and K. Lyu. Theoretical analysis of auto rate-tuning by batch normalization. arXiv preprint arXiv:1812.03981, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Z. Li, S. Arora, and A. Jadbabaie. Learning over-parametrized two-layer neural networks beyond NTK. InConference on Learning Theory, 2020
2020
-
[7]
E. J. Cand` es and B. Recht. Exact matrix completion via convex optimization.Foundations of Computational Mathematics, 9(6):717–772, 2009
2009
-
[8]
E. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Yunis, K
D. Yunis, K. Garg, M. Braverman, and S. Kakade. Grokking, rank minimization and general- ization in deep learning. InICML MI Workshop, 2024
2024
- [10]
-
[11]
Z. Liu, O. Kitouni, N. Nolte, E. Michaud, M. Tegmark, and M. Williams. Omnigrok: Grokking beyond algorithmic data. InInternational Conference on Learning Representations, 2023
2023
-
[12]
Y. Xu. Low-dimensional and transversely curved optimization dynamics in grokking.arXiv preprint arXiv:2602.16746, 2026. 9
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.