Recognition: 2 theorem links
· Lean TheoremLow-Dimensional and Transversely Curved Optimization Dynamics in Grokking
Pith reviewed 2026-05-15 21:29 UTC · model grok-4.3
The pith
Curvature growth in directions orthogonal to a low-dimensional subspace precedes grokking in transformer training on modular arithmetic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
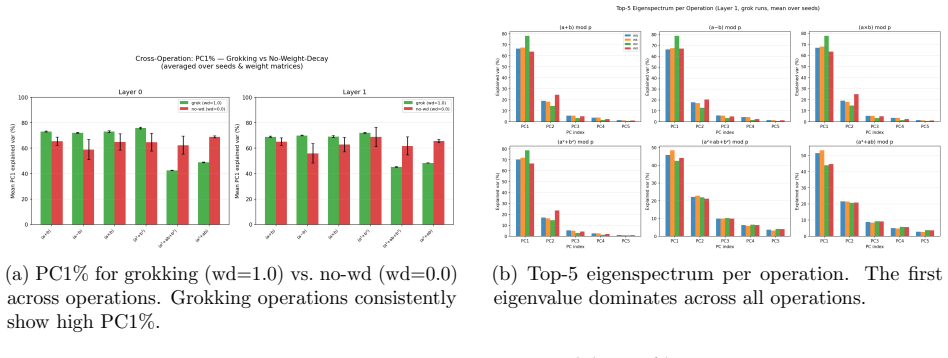
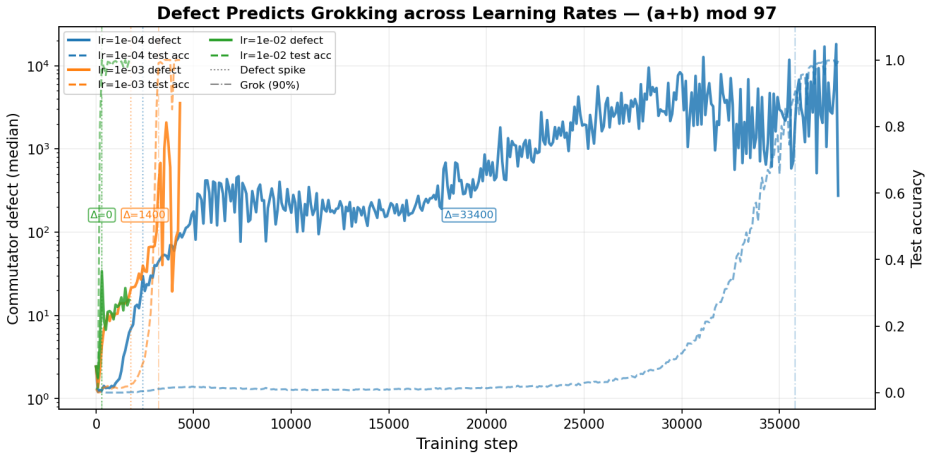
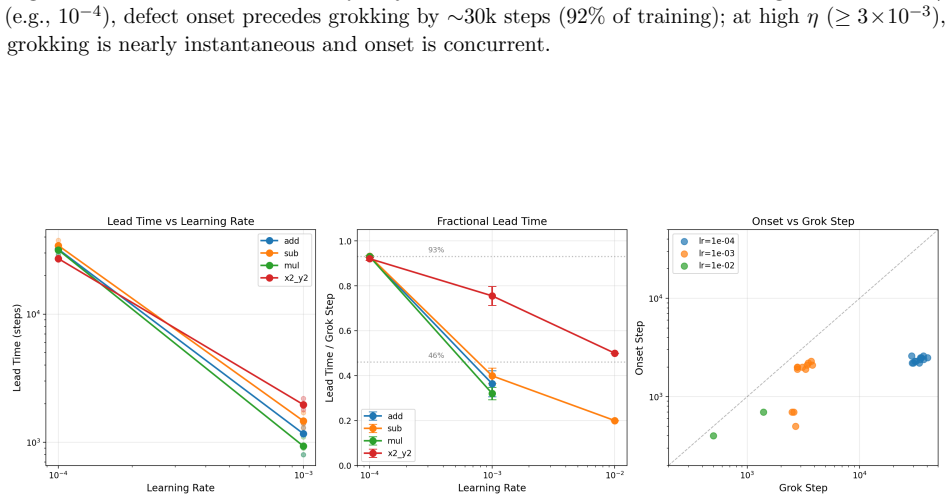
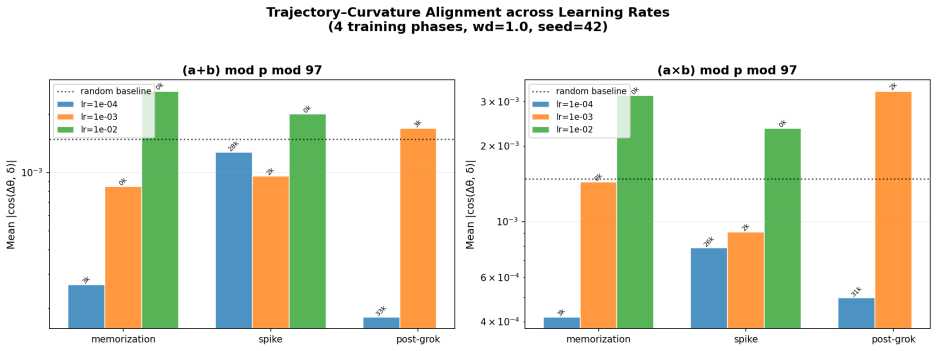
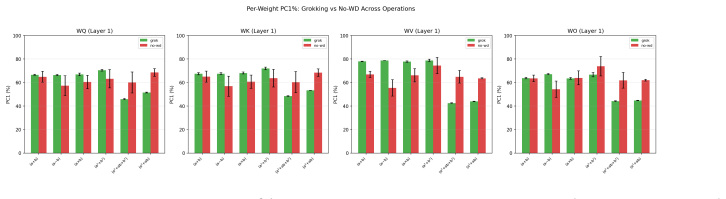
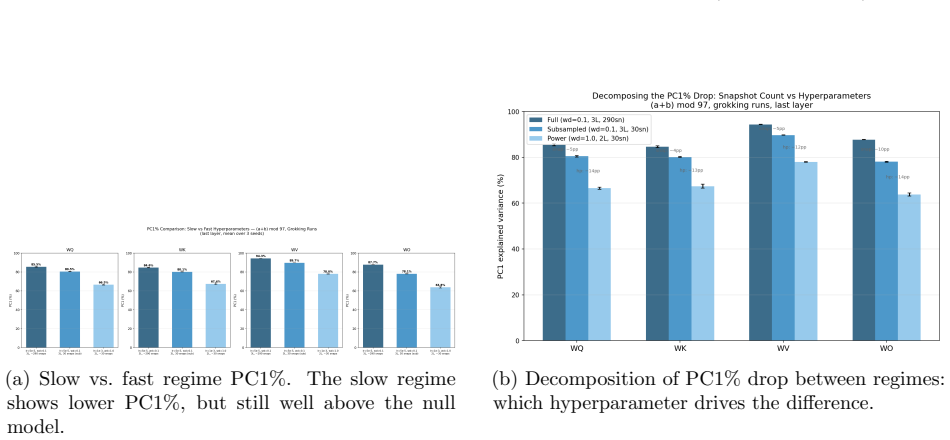
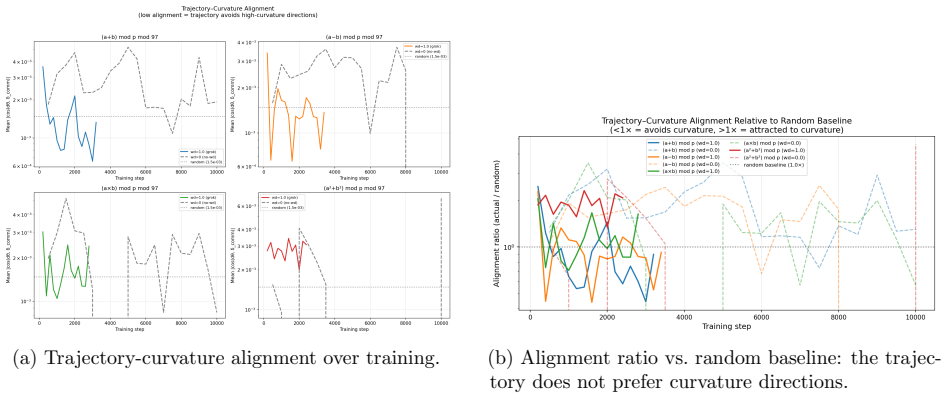
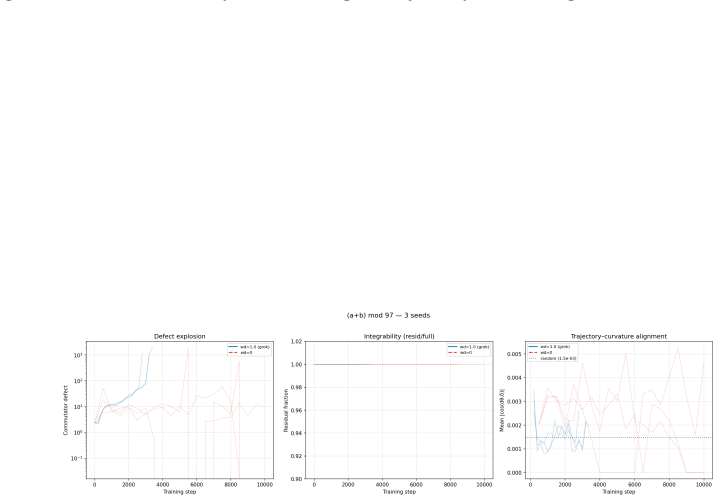
PCA of attention weight trajectories shows optimization evolves predominantly within a low-dimensional execution subspace that captures 68-83% of variance. Commutator defects of successive gradient steps grow in directions orthogonal to this subspace, and this transverse curvature increase precedes generalization with a power-law lead time. Suppressing motion along the subspace blocks grokking in a monotonic dose-response, whereas artificially boosting curvature defects leaves generalization unchanged. These dynamics support the account of grokking as escape from a metastable regime of low-dimensional confinement plus transverse curvature accumulation.
What carries the argument
The low-dimensional execution subspace from PCA of attention trajectories, together with commutator defects of gradient steps measured and projected in directions transverse to it.
If this is right
- Grokking requires continued motion along the learned low-dimensional subspace.
- Transverse curvature accumulation is a consistent precursor to generalization but is not sufficient by itself.
- The lead time between curvature growth and generalization scales as a power law with the grokking timescale.
- The same geometric pattern appears across standard and slow learning-rate regimes and multiple random seeds.
- Orthogonal gradient flow is necessary for grokking but boosting curvature alone does not trigger it.
Where Pith is reading between the lines
- If the subspace encodes functional computation steps, then selectively perturbing its principal components could be used to control or accelerate generalization timing in related tasks.
- The power-law scaling of lead time suggests the process may share features with critical phenomena where transverse curvature reaches a threshold.
- Analogous measurements of transverse curvature could be applied to larger models or different data domains to test whether low-dimensional confinement explains other delayed-generalization phenomena.
- The necessity of subspace motion implies that methods restricting effective dimensionality during early training may delay or prevent grokking.
Load-bearing premise
Commutator defects of successive gradient steps give a faithful measure of the relevant transverse curvature, and the PCA-derived subspace tracks the functional execution dynamics rather than a projection artifact.
What would settle it
A training run where generalization occurs without prior orthogonal curvature growth, or where substantial curvature growth fails to produce generalization even though subspace motion continues.
Figures



















read the original abstract
Grokking -- the delayed transition from memorization to generalization in small algorithmic tasks -- remains poorly understood. We present a geometric analysis of optimization dynamics in transformers trained on modular arithmetic. PCA of attention weight trajectories reveals that training evolves predominantly within a low-dimensional execution subspace, with a single principal component capturing 68-83% of trajectory variance. To probe loss-landscape geometry, we measure commutator defects -- the non-commutativity of successive gradient steps -- and project them onto this learned subspace. We find that curvature grows sharply in directions orthogonal to the execution subspace while the trajectory remains largely confined to it. Importantly, curvature growth consistently precedes generalization across learning rates and hyperparameter regimes, with the lead time obeying a power law in the grokking timescale. Causal intervention experiments show that motion along the learned subspace is necessary for grokking, while artificially increasing curvature is insufficient. Together, these results support a geometric account in which grokking reflects escape from a metastable regime characterized by low-dimensional confinement and transverse curvature accumulation. All findings replicate across this learning-rate range, a qualitatively different slow regime (lr=5e-5, wd=0.1, 3 layers), and three random seeds, though alignment dynamics differ quantitatively between regimes. Causal intervention experiments establish that orthogonal gradient flow is necessary but not sufficient for grokking: suppressing it prevents generalization with a monotonic dose-response across four operations, while artificially boosting curvature defects has no effect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that grokking in transformers on modular arithmetic arises from low-dimensional confinement of optimization trajectories to an execution subspace (identified via PCA of attention weights, capturing 68-83% variance) combined with accumulation of transverse curvature (proxied by projected commutator defects of successive gradient steps). Curvature growth precedes generalization with a power-law lead time, and causal interventions show subspace motion is necessary while boosting curvature is insufficient; results replicate across learning rates, a slow regime, and seeds.
Significance. If the commutator-defect proxy is validated as a curvature measure, the work supplies a concrete geometric mechanism for the delayed transition from memorization to generalization, supported by direct empirical measurements, dose-response interventions, and cross-regime replication rather than post-hoc fitting.
major comments (2)
- [Methods / commutator defect definition] The section defining and interpreting commutator defects: the manuscript equates projected non-commutativity of successive gradient steps with growth of transverse curvature in the loss landscape, yet supplies no derivation, correlation analysis, or comparison to the Hessian quadratic form (or its eigenvalues) in the orthogonal complement. Without this link the reported precedence, power-law lead time, and geometric account rest on an unverified identification.
- [Section 3.1] PCA subspace construction (Section 3.1): the claim that the dominant principal component corresponds to functional execution dynamics (rather than an optimization artifact) is load-bearing for the transverse-curvature narrative, but the paper does not report controls such as comparison with random projections, functional equivalence tests on held-out inputs, or ablation of the projection step.
minor comments (2)
- [Abstract / Figure 4] Abstract and results figures: error bars, exact definitions of commutator defects, and full exclusion criteria for the power-law fits are omitted, making quantitative claims harder to assess.
- [Section 3.2] Notation: the distinction between 'commutator defect' and standard discrete-gradient non-commutativity should be clarified with an explicit formula in the main text rather than only in the appendix.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below, agreeing to strengthen the manuscript with additional derivations, correlations, and controls as suggested.
read point-by-point responses
-
Referee: [Methods / commutator defect definition] The section defining and interpreting commutator defects: the manuscript equates projected non-commutativity of successive gradient steps with growth of transverse curvature in the loss landscape, yet supplies no derivation, correlation analysis, or comparison to the Hessian quadratic form (or its eigenvalues) in the orthogonal complement. Without this link the reported precedence, power-law lead time, and geometric account rest on an unverified identification.
Authors: We agree that a more explicit link is needed. In the revised manuscript, we will add a derivation relating the projected commutator defect to the quadratic form of the loss in the transverse directions (based on the non-commutativity of gradient flows on a Riemannian manifold) and include empirical correlations with the eigenvalues of the Hessian projected onto the orthogonal complement, computed at representative checkpoints. This will validate the proxy and support the reported precedence and power-law scaling. revision: yes
-
Referee: [Section 3.1] PCA subspace construction (Section 3.1): the claim that the dominant principal component corresponds to functional execution dynamics (rather than an optimization artifact) is load-bearing for the transverse-curvature narrative, but the paper does not report controls such as comparison with random projections, functional equivalence tests on held-out inputs, or ablation of the projection step.
Authors: We will incorporate the requested controls in the revision. We will report: (1) explained variance comparisons against random projections of matching dimensionality, (2) functional equivalence tests evaluating model outputs and generalization on held-out inputs when dynamics are confined to the PCA subspace versus random subspaces, and (3) ablations of the projection step showing its effect on curvature measurements. These will confirm that the subspace captures functional execution rather than artifacts. revision: yes
Circularity Check
No significant circularity; claims rest on direct empirical measurements
full rationale
The paper reports observational results from PCA on attention trajectories and measurements of commutator defects projected onto the resulting subspace. Curvature growth preceding generalization and the power-law lead time are presented as measured patterns across regimes, not quantities derived from or defined in terms of the subspace or defect definitions themselves. No equations reduce a prediction to a fitted input by construction, no self-citations bear load on the central geometric account, and no ansatz or uniqueness theorem is imported. The derivation chain is self-contained against the reported data and interventions.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math PCA on attention weight trajectories identifies a dominant low-dimensional execution subspace
- domain assumption Commutator defects of successive gradient steps quantify relevant curvature orthogonal to the subspace
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The commutator defect quantifies the non-commutativity of successive gradient steps... D ∝ Lie bracket of stochastic gradient vector fields, serving as a proxy for local nonlinearity
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Weight evolution during grokking is essentially one-dimensional: a single principal component captures 68–83% of variance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
The Lifecycle of the Spectral Edge: From Gradient Learning to Weight-Decay Compression
The spectral edge transitions from a gradient-driven functional direction before grokking to a perturbation-flat, ablation-critical compression axis at grokking, forming three universality classes predicted by a gap f...
-
Spectral Edge Dynamics Reveal Functional Modes of Learning
Spectral edge dynamics during grokking reveal task-dependent low-dimensional functional modes over inputs, such as Fourier modes for modular addition and cross-term decompositions for x squared plus y squared.
-
Spectral Edge Dynamics: An Analytical-Empirical Study of Phase Transitions in Neural Network Training
Spectral gaps in the Gram matrix of parameter updates control phase transitions such as grokking in neural network training.
Reference graph
Works this paper leans on
-
[1]
Unifying grokking and double descent.arXiv preprint arXiv:2303.06173,
Xander Davies, Lauro Langosco, and David Krueger. Unifying grokking and double descent.arXiv preprint arXiv:2303.06173,
-
[2]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
Grokking as the transition from lazy to rich training dynamics.arXiv preprint arXiv:2310.06110,
Tanishq Kumar, Blake Bordelon, Samuel J Gershman, and Cengiz Pehlevan. Grokking as the transition from lazy to rich training dynamics.arXiv preprint arXiv:2310.06110,
-
[4]
Measuring the intrinsic dimension of objective landscapes
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes. InInternational Conference on Learning Representations, 2018a. Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. Visualizing the loss landscape of neural nets. InAdvances in Neural Information Processing Systems, vol...
-
[5]
Kaifeng Lyu, Jikai Jin, Zhiyuan Li, Simon S Du, Jason D Lee, and Wei Hu. Dichotomy of early and late phase implicit biases can provably induce grokking.arXiv preprint arXiv:2311.18817,
-
[6]
William Merrill, Nikolaos Tsilivis, and Aman Shukla. A tale of two circuits: Grokking as competition of sparse and dense subnetworks.arXiv preprint arXiv:2303.11873,
-
[8]
Neel Nanda, Lawrence Chan, Tom Liberum, Jess Smith, and Jacob Steinhardt
URLhttps://arxiv.org/abs/2602.01434. Neel Nanda, Lawrence Chan, Tom Liberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability.arXiv preprint arXiv:2301.05217,
-
[9]
Grokking: Generalization beyond overfitting on small algorithmic datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. InICLR 2022 Workshop on MATH-AI,
work page 2022
-
[10]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
URLhttps://arxiv.org/abs/2201.02177. Vimal Thilak, Etai Littwin, Shuangfei Zhai, Omid Saremi, Roni Paiss, and Joshua Susskind. The slingshot mechanism: An empirical study of adaptive optimizers and the grokking phenomenon. arXiv preprint arXiv:2206.04817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390,
Vikrant Varma, Rohin Shah, Zachary Kenton, J´ anos Kram´ ar, and Neel Nanda. Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390,
-
[12]
Yongzhong Xu. Low-dimensional execution manifolds in transformer learning dynamics: Evidence from modular arithmetic tasks.arXiv preprint arXiv:2602.10496, 2026a. URL https://arxiv. org/abs/2602.10496. Yongzhong Xu. The spectral edge thesis: Intra-signal gap dynamics in transformer training.arXiv preprint arXiv:2603.28964, 2026b. URLhttps://arxiv.org/abs/...
-
[13]
Defect onset at step 2000, grokking at step 3600 (lead = 1600 steps). (b) Lead time quantification. Left: onset step vs. grok step (all points above diagonal). Right: lead time by operation (sign testp <0.001). Figure 7: Temporal ordering: curvature growth precedes generalization. (a) Regime comparison: invariance, defect, and nor- malized lead time are c...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.