Scaling Datasets for Multi-Sensor, Multi-Agent, and Multi-Domain Learning in Autonomous Systems
Pith reviewed 2026-06-28 04:22 UTC · model grok-4.3
The pith
A modular pipeline creates terabyte-scale ground-truth datasets for multi-sensor multi-agent autonomous systems across ground aerial and infrastructure domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
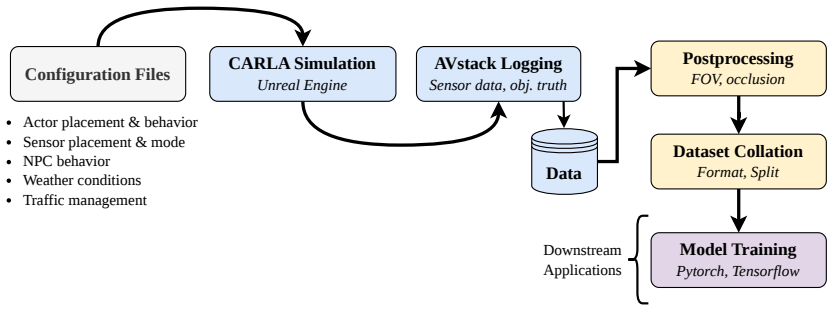
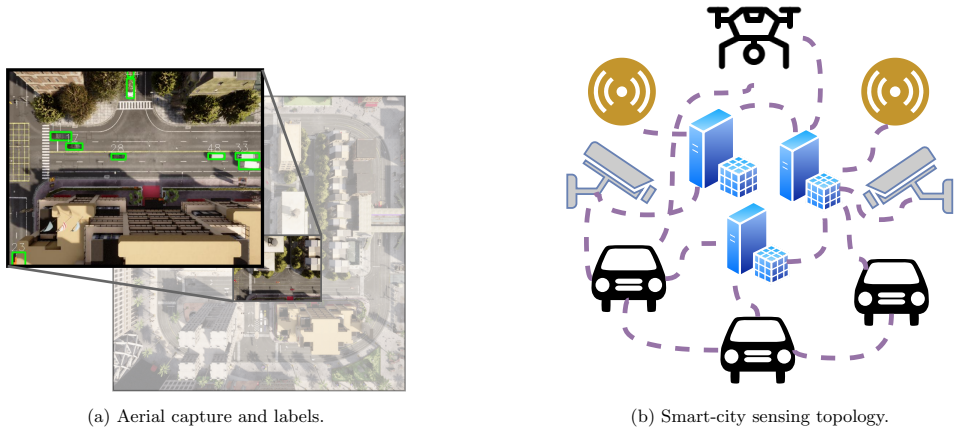
The paper presents a modular dataset generation pipeline that creates terabyte-scale, ground-truth-labeled data for ground, aerial, and infrastructure-based autonomous systems. It supports single- and multi-agent configurations with flexible sensor suites and enables controllable experimentation across challenging conditions. Perception and fusion studies confirm that the generated data can support application-specific training and collaborative autonomy.
What carries the argument
A modular dataset generation pipeline that produces large-scale labeled synthetic data for various autonomy configurations.
If this is right
- Supports both single-agent and multi-agent setups with customizable sensors.
- Allows experimentation in diverse and challenging conditions.
- Enables training for perception tasks and sensor fusion in collaborative scenarios.
Where Pith is reading between the lines
- Such pipelines could reduce reliance on costly real-world data collection for initial model development.
- The approach might extend to other simulation environments beyond the one used here.
- Validation on real hardware would be needed to confirm transferability of learned models.
Load-bearing premise
The synthetic data generated will closely enough match real-world sensor behaviors, vehicle dynamics, and interactions for the trained models to work in practice.
What would settle it
Training models on the generated data and testing them on real-world multi-agent sensor recordings; poor performance relative to models trained on real data would indicate the claim does not hold.
Figures


read the original abstract
Existing datasets cannot support large-scale learning in multi-agent, multi-sensor, or multi-domain autonomy, where diversity and coordination are essential. We present a modular dataset generation pipeline that creates terabyte-scale, ground-truth-labeled data for ground, aerial, and infrastructure-based systems using the AVstack framework and CARLA simulator. Supporting single- and multi-agent configurations with flexible sensor suites, the pipeline enables controllable experimentation across challenging conditions. Representative perception and fusion studies show how generated data can support application-specific training and collaborative autonomy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a modular dataset generation pipeline built on the AVstack framework and CARLA simulator that produces terabyte-scale, ground-truth-labeled synthetic data for ground, aerial, and infrastructure-based autonomous systems. It supports single- and multi-agent configurations with flexible sensor suites for controllable experimentation under challenging conditions, and includes representative perception and fusion studies to illustrate utility for application-specific training and collaborative autonomy.
Significance. If the pipeline is robustly implemented and the studies demonstrate clear utility, the work could help address the scarcity of large-scale, labeled, multi-agent/multi-domain datasets in autonomy research. The modular design enabling controllable multi-sensor and multi-agent setups is a positive contribution for simulation-based experimentation.
major comments (2)
- [Abstract and representative studies] Abstract and representative studies: the statement that these studies 'show how generated data can support application-specific training and collaborative autonomy' lacks any quantitative results, error analysis, performance metrics, or comparison to real data, which is load-bearing for the central utility claim.
- [Pipeline description] Pipeline description (likely §3): the claim of creating 'terabyte-scale' data is not supported by details on generation throughput, storage requirements, actual dataset sizes produced in the reported experiments, or scaling behavior, leaving the scaling assertion unverified.
minor comments (1)
- [Figures] Figure captions and legends should explicitly state sensor configurations, agent counts, and environmental conditions for each example to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the quantitative support for our claims.
read point-by-point responses
-
Referee: [Abstract and representative studies] Abstract and representative studies: the statement that these studies 'show how generated data can support application-specific training and collaborative autonomy' lacks any quantitative results, error analysis, performance metrics, or comparison to real data, which is load-bearing for the central utility claim.
Authors: We acknowledge that the representative studies, while illustrative of the pipeline's utility for application-specific training and collaborative autonomy, would be strengthened by additional quantitative elements. In the revised version we will expand these sections to include performance metrics, error analysis, and comparisons to real data where available. revision: yes
-
Referee: [Pipeline description] Pipeline description (likely §3): the claim of creating 'terabyte-scale' data is not supported by details on generation throughput, storage requirements, actual dataset sizes produced in the reported experiments, or scaling behavior, leaving the scaling assertion unverified.
Authors: We will augment §3 with concrete details on generation throughput, storage requirements, measured dataset sizes from the reported experiments, and scaling behavior to substantiate the terabyte-scale claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a modular dataset generation pipeline using the AVstack framework and CARLA simulator to produce terabyte-scale labeled synthetic data for multi-agent, multi-sensor, and multi-domain autonomy scenarios. No mathematical derivations, equations, fitted parameters, or predictions appear in the abstract or described studies; the central claim concerns the existence, controllability, and intra-simulation utility of the pipeline rather than any reduction of outputs to inputs by construction. Representative perception and fusion studies are empirical demonstrations within the simulator, not load-bearing derivations. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a manner that would render the result equivalent to its inputs. The work is self-contained as a description of a generation tool and its application to simulation experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vision meets robotics: The kitti dataset,
Geiger, A., Lenz, P., Stiller, C., and Urtasun, R., “Vision meets robotics: The kitti dataset,”The Int. Journal of Robotics Research32(11), 1231–1237 (2013)
2013
-
[2]
nuscenes: A multimodal dataset for autonomous driving,
Caesar, H., Bankiti, V., Lang, A. H., Vora, S., et al., “nuscenes: A multimodal dataset for autonomous driving,” in [IEEE/CVF CVPR], 11621–11631 (2020)
2020
-
[3]
Scalability in perception for autonomous driving: Waymo open dataset,
Sun, P., Kretzschmar, H., et al., “Scalability in perception for autonomous driving: Waymo open dataset,” in [IEEE/CVF CVPR], 2446–2454 (2020)
2020
-
[4]
The pascal visual object classes (voc) challenge,
Everingham, M., Van Gool, L., Williams, C. K., Winn, J., and Zisserman, A., “The pascal visual object classes (voc) challenge,”International journal of computer vision88, 303–338 (2010)
2010
-
[5]
Mi- crosoft coco: Common objects in context,
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Doll´ ar, P., and Zitnick, C. L., “Mi- crosoft coco: Common objects in context,” in [Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13], 740–755, Springer (2014)
2014
-
[6]
The cityscapes dataset for semantic urban scene understanding,
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., and Schiele, B., “The cityscapes dataset for semantic urban scene understanding,” in [Proceedings of the IEEE conference on computer vision and pattern recognition], 3213–3223 (2016)
2016
-
[7]
Summary of nhtsa heavy-vehicle vehicle-to-vehicle safety communications research,
Chang, J., “Summary of nhtsa heavy-vehicle vehicle-to-vehicle safety communications research,” tech. rep. (2016)
2016
-
[8]
Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication,
Xu, R., Xiang, H., Xia, X., Han, X., Li, J., and Ma, J., “Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication,” in [2022 ICRA], 2583–2589 (2022)
2022
-
[9]
A cooperative perception environment for traffic operations and control,
Chen, H., Liu, B., Zhang, X., Qian, F., Mao, Z. M., and Feng, Y., “A cooperative perception environment for traffic operations and control,”arXiv preprint arXiv:2208.02792(2022)
-
[10]
Avstack: An open-source, reconfigurable platform for au- tonomous vehicle development,
Hallyburton, R. S., Zhang, S., and Pajic, M., “Avstack: An open-source, reconfigurable platform for au- tonomous vehicle development,” in [Proceedings of the ACM/IEEE 14th International Conference on Cyber- Physical Systems (with CPS-IoT Week 2023)], 209–220 (2023)
2023
-
[11]
A modular platform for collaborative, distributed sensor fusion,
Hallyburton, R. S., Zelter, N., Hunt, D., Angell, K., and Pajic, M., “A modular platform for collaborative, distributed sensor fusion,” in [Proceedings of the ACM/IEEE 14th International Conference on Cyber- Physical Systems (with CPS-IoT Week 2023)], 268–269 (2023)
2023
-
[12]
Carla: An open urban driving simula- tor,
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., and Koltun, V., “Carla: An open urban driving simula- tor,” in [CoRL], 1–16, PMLR (2017)
2017
-
[13]
Airsim: High-fidelity visual and physical sim. for avs,
Shah, S., Dey, D., Lovett, C., and Kapoor, A., “Airsim: High-fidelity visual and physical sim. for avs,” in [Field and service robotics], 621–635, Springer (2018)
2018
-
[14]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X., Sun, S., Feng, W., Liu, Z., Xu, J., et al., “Mmdetection: Open mmlab detection toolbox and benchmark,”arXiv preprint arXiv:1906.07155(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[15]
MMDetection3D: OpenMMLab next-generation platform for general 3D object detection
“MMDetection3D: OpenMMLab next-generation platform for general 3D object detection.”https:// github.com/open-mmlab/mmdetection3d(2020)
2020
-
[16]
Frustum pointnets for 3d object detection from rgb-d data,
Qi, C. R., Liu, W., Wu, C., Su, H., and Guibas, L. J., “Frustum pointnets for 3d object detection from rgb-d data,” in [IEEE CVPR], 918–927 (2018)
2018
-
[17]
Second: Sparsely embedded convolutional detection,
Yan, Y., Mao, Y., and Li, B., “Second: Sparsely embedded convolutional detection,”Sensors18(10), 3337 (2018)
2018
-
[18]
Pointpillars: Fast encoders for object detection from point clouds,
Lang, A., Vora, S., Caesar, H., Zhou, L., Yang, J., and Beijbom, O., “Pointpillars: Fast encoders for object detection from point clouds,” in [IEEE/CVF CVPR], 12697–12705 (2019)
2019
-
[19]
Datasets, models, and algorithms for multi-sensor, multi-agent autonomy using avstack,
Hallyburton, R. S. and Pajic, M., “Datasets, models, and algorithms for multi-sensor, multi-agent autonomy using avstack,”arXiv preprint arXiv:2312.04970(2023)
-
[20]
Ab3dmot: A baseline for 3d multi-object tracking and new evaluation metrics,
Weng, X., Wang, J., Held, D., and Kitani, K., “Ab3dmot: A baseline for 3d multi-object tracking and new evaluation metrics,”arXiv preprint arXiv:2008.08063(2020)
-
[21]
Eagermot: 3d multi-object tracking via sensor fusion,
Kim, A., Oˇ sep, A., and Leal-Taix´ e, L., “Eagermot: 3d multi-object tracking via sensor fusion,” in [ICRA], 11315–11321 (2021)
2021
-
[22]
V2x misbehavior and collective perception service: Considerations for standardization,
Ansari, M. R., Monteuuis, J.-P., Petit, J., and Chen, C., “V2x misbehavior and collective perception service: Considerations for standardization,” in [2021 IEEE Conference on Standards for Communications and Networking (CSCN)], 1–6, IEEE (2021)
2021
-
[23]
Data fusion in decentralized sensor networks,
Grime, S. and Durrant-Whyte, H. F., “Data fusion in decentralized sensor networks,”Control engineering practice2(5), 849–863 (1994)
1994
-
[24]
General decentralized data fusion with covariance intersection,
Julier, S. and Uhlmann, J. K., “General decentralized data fusion with covariance intersection,” in [Handbook of multisensor data fusion], 339–364, CRC Press (2017)
2017
-
[25]
Hallyburton, R. S., Hunt, D., Luo, S., and Pajic, M., “A multi-agent security testbed for the analysis of attacks and defenses in collaborative sensor fusion,”arXiv preprint arXiv:2401.09387(2024)
-
[26]
A dynamic trust model for mobile ad hoc networks,
Liu, Z., Joy, A. W., and Thompson, R. A., “A dynamic trust model for mobile ad hoc networks,” in [Proceedings of the 10th IEEE International Workshop on Future Trends of Distributed Computing Systems (FTDCS)], 80–85 (2004)
2004
-
[27]
Computing of trust in wireless networks,
Zhu, H., Bao, F., and Deng, R. H., “Computing of trust in wireless networks,” in [IEEE 60th Vehicular Technology Conference, 2004. VTC2004-Fall. 2004],4, 2621–2624, IEEE (2004)
2004
-
[28]
Exploiting trust for resilient hypothesis testing with malicious robots,
Cavorsi, M., Akg¨ un, O. E., Yemini, M., Goldsmith, A. J., and Gil, S., “Exploiting trust for resilient hypothesis testing with malicious robots,”IEEE Transactions on Robotics(2024)
2024
-
[29]
Bayesian methods for trust in collaborative multi-agent autonomy,
Hallyburton, R. S. and Pajic, M., “Bayesian methods for trust in collaborative multi-agent autonomy,” in [2024 IEEE 63rd Conference on Decision and Control (CDC)], 470–476, IEEE (2024)
2024
-
[30]
Security-aware sensor fusion with mate: the multi-agent trust estimator,
Hallyburton, R. S. and Pajic, M., “Security-aware sensor fusion with mate: the multi-agent trust estimator,” in [Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security], 2009– 2023 (2025)
2025
-
[31]
Trust-based assured sensor fusion in distributed aerial autonomy,
Hallyburton, R. S. and Pajic, M., “Trust-based assured sensor fusion in distributed aerial autonomy,” in [Proceedings of the ACM/IEEE 16th International Conference on Cyber-Physical Systems (with CPS-IoT Week 2025)], 1–12 (2025)
2025
-
[32]
Learning by cheating,
Chen, D., Zhou, B., Koltun, V., and Kr¨ ahenb¨ uhl, P., “Learning by cheating,” in [CoRL], 66–75, PMLR (2020)
2020
-
[33]
End-to-end model-free reinforcement learning for urban driving using implicit affordances,
Toromanoff, M., Wirbel, E., and Moutarde, F., “End-to-end model-free reinforcement learning for urban driving using implicit affordances,” in [IEEE/CVF CVPR], 7153–7162 (2020)
2020
-
[34]
Multi-modal fusion transformer for end-to-end autonomous driv- ing,
Prakash, A., Chitta, K., and Geiger, A., “Multi-modal fusion transformer for end-to-end autonomous driv- ing,” in [IEEE/CVF CVPR], 7077–7087 (2021)
2021
-
[35]
Trajectron++: Dynamically-feasible trajec- tory forecasting with heterogeneous data,
Salzmann, T., Ivanovic, B., Chakravarty, P., and Pavone, M., “Trajectron++: Dynamically-feasible trajec- tory forecasting with heterogeneous data,” in [European Conference on Computer Vision], 683–700, Springer (2020)
2020
-
[36]
Liu, Y., Hallyburton, S., Kim, J., Lin, Y., Li, Y., Wang, Q., Ye, H., Sun, J., Pajic, M., Chen, Y., et al., “Llavida: A large language vision driving assistant for explicit reasoning and enhanced trajectory planning,” arXiv preprint arXiv:2512.18211(2025)
-
[37]
Probabilistic segmentation for robust field of view estimation,
Hallyburton, R. S., Hunt, D., He, Y., He, J., and Pajic, M., “Probabilistic segmentation for robust field of view estimation,”arXiv preprint arXiv:2503.07375(2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.