OSCAR: Omni-Embodiment Action-Conditioned World Model for Robotics
Pith reviewed 2026-06-28 06:32 UTC · model grok-4.3
The pith
OSCAR conditions a video world model on 2D kinematic skeletons to evaluate robot policies virtually with strong correlation to real-world results across embodiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
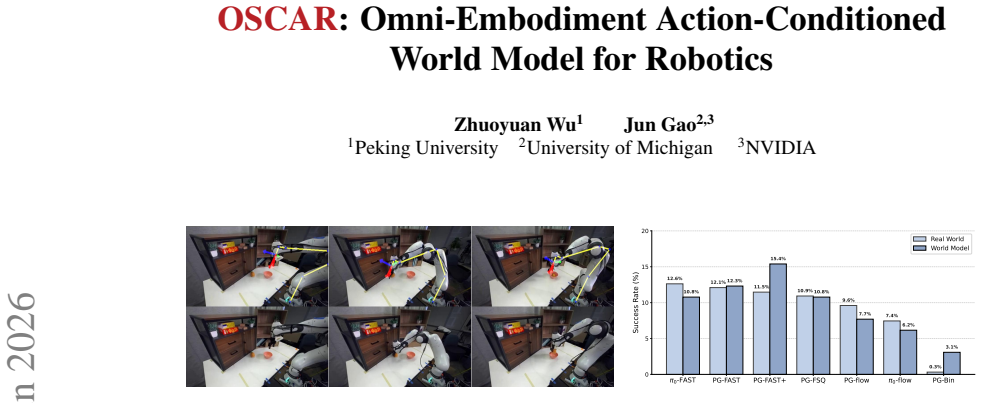
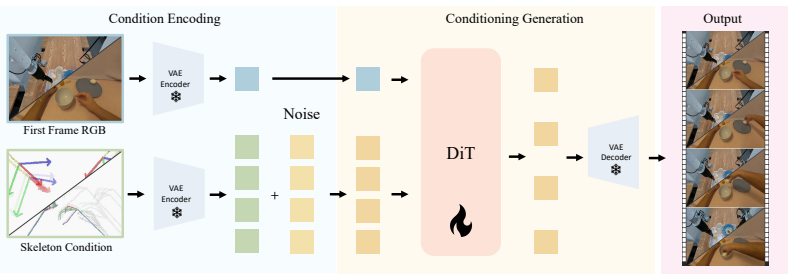
OSCAR is a precise action-conditioned video world model finetuned from Cosmos-Predict2.5-2B on a single GH200 GPU using a cleaned joint dataset from diverse robot and human sources. By adopting 2D kinematic skeleton rendering as a unified conditioning representation, the model improves action following, appearance quality, and motion consistency over baselines and produces virtual policy evaluations that show significant correlation with real-world robot performance.
What carries the argument
2D kinematic skeleton rendering as a unified conditioning representation that carries action information across robot arms and human hands
Load-bearing premise
The 2D kinematic skeleton rendering supplies enough precise action detail to work equally well for every robot arm and human hand without embodiment-specific loss of fidelity.
What would settle it
A collection of robot policies whose performance rankings or scores in OSCAR-generated videos differ substantially from the rankings obtained when the same policies are run on physical robots.
Figures








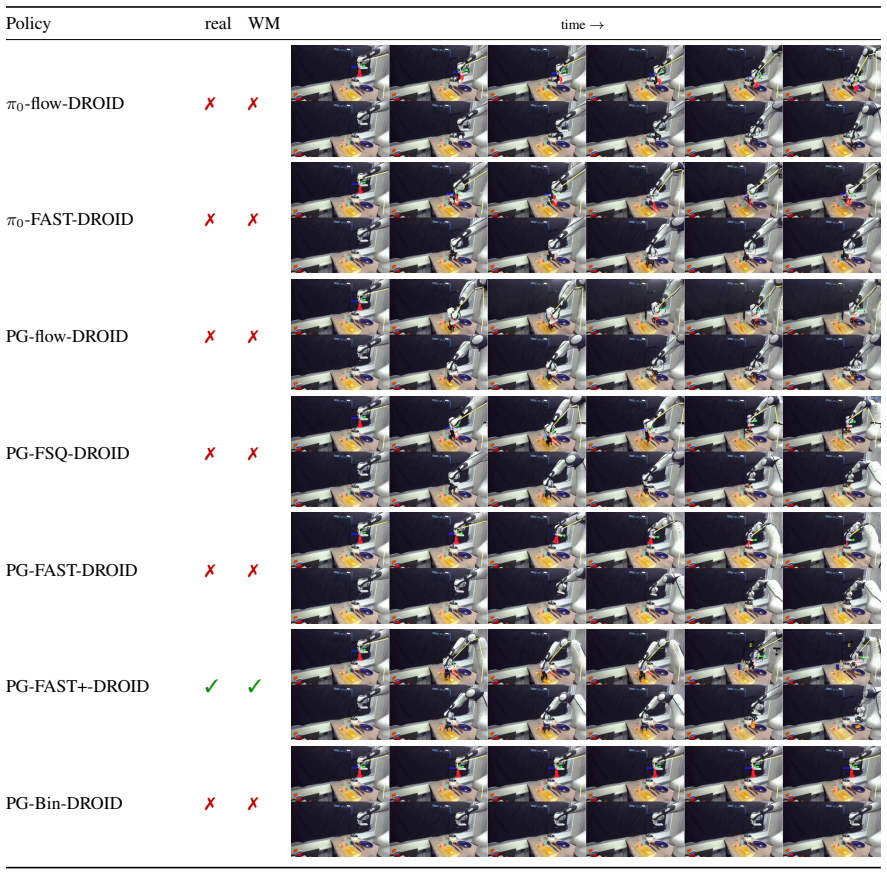
read the original abstract
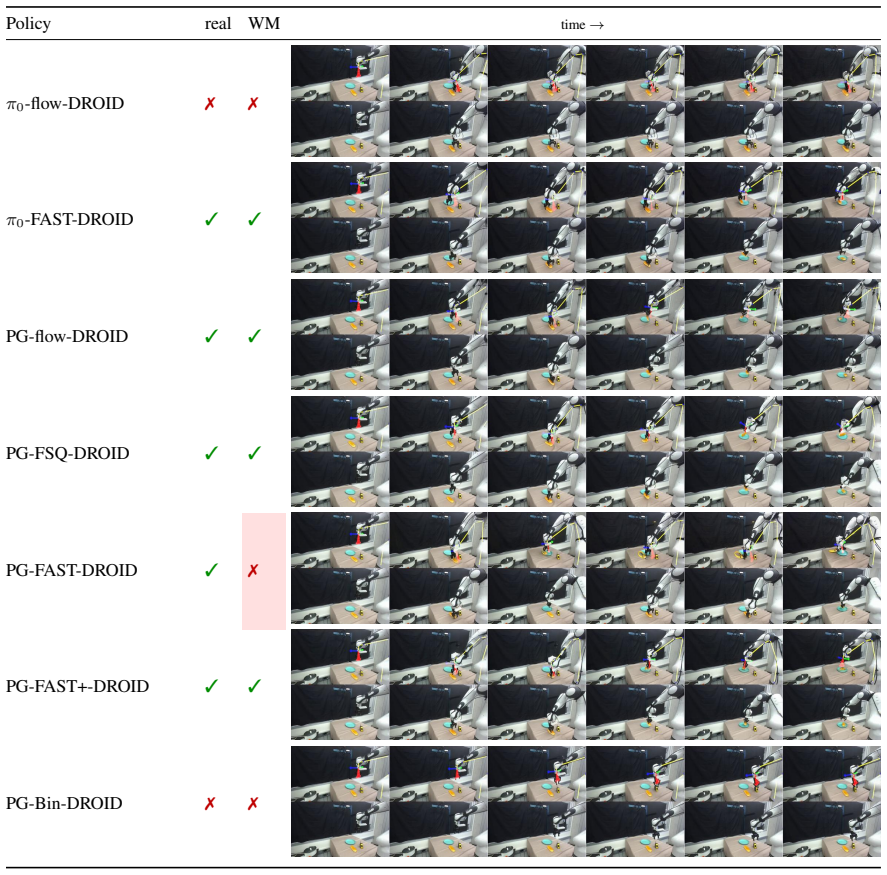
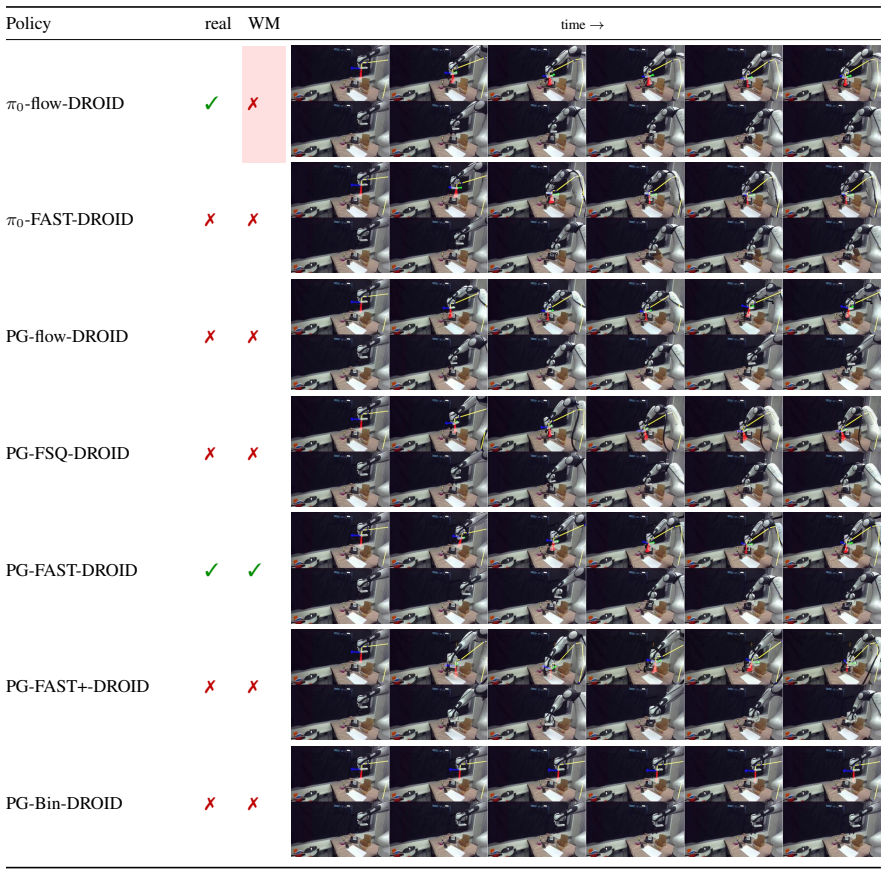
We present OSCAR, a precise action-conditioned video world model that generalizes across different robot embodiments and enables robot policy evaluation. Existing video world models face three main challenges for real-world robot evaluation: limited scenario diversity in current robot training datasets, imprecise action following, and poor generalization across embodiments for broad adoption. We tackle these challenges from two perspectives. At its core is a large-scale standardized data pipeline that curates, filters, and deduplicates broad robotics and egocentric human datasets, yielding a clean joint-training dataset that spans diverse tasks, scenarios, actions, and robot embodiments. To condition the video model, we adopt 2D kinematic skeleton rendering as a unified conditioning representation that generalizes across different robot arms or even human hands. We finetune the Cosmos-Predict2.5-2B model on a single GH200 GPU. Our model achieves significant improvement on action following, appearance quality, and motion consistency, compared to existing baselines, which either have a much larger model size or require more GPUs. We further deploy OSCAR to evaluate robot policies from RoboArena. Extensive experiments demonstrate the significant correlation between our virtual policy evaluation in OSCAR and real-world evaluation, paving the way for the future where robot policies can be purely evaluated in virtual generated worlds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OSCAR, an action-conditioned video world model for robotics that uses 2D kinematic skeleton rendering as a unified conditioning signal across robot arms and human hands. It describes a large-scale data curation pipeline combining robotics and egocentric human datasets, finetuning of the Cosmos-Predict2.5-2B model on a single GH200 GPU, claimed improvements in action following/appearance/motion consistency over baselines, and a significant correlation between virtual policy evaluations (on RoboArena policies) and real-world results.
Significance. If the reported virtual-real correlation is supported by quantitative evidence, the work could enable lower-cost policy evaluation by shifting testing into generated worlds. The standardized data pipeline and embodiment-agnostic conditioning approach address practical barriers in current video world models, though the lack of reported metrics prevents gauging the magnitude of these advances.
major comments (2)
- [Abstract] Abstract: the claims of 'significant improvement on action following' and 'significant correlation between our virtual policy evaluation in OSCAR and real-world evaluation' are presented without any quantitative metrics, baseline comparisons, dataset sizes, statistical details, or evaluation protocol; this absence makes the central data-to-claim link unevaluable from the manuscript.
- [Method] Method (conditioning representation): the assertion that 2D kinematic skeleton rendering 'generalizes across different robot arms or even human hands' and preserves 'precise action information' is load-bearing for both the cross-embodiment claim and the virtual-real correlation; the manuscript does not address or test whether projection from 3D joint configurations to 2D discards depth/out-of-plane cues that would degrade fidelity for kinematically dissimilar embodiments.
minor comments (1)
- [Abstract] Abstract: model size (2B) and training hardware (single GH200) are stated, but no corresponding numbers are given for the baselines against which improvements are claimed.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the two major comments point-by-point below, clarifying where quantitative details appear in the manuscript and acknowledging where additional discussion is warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of 'significant improvement on action following' and 'significant correlation between our virtual policy evaluation in OSCAR and real-world evaluation' are presented without any quantitative metrics, baseline comparisons, dataset sizes, statistical details, or evaluation protocol; this absence makes the central data-to-claim link unevaluable from the manuscript.
Authors: The abstract is intentionally concise and high-level. Quantitative results—including specific action-following metrics versus baselines, the reported correlation coefficient between virtual and real policy evaluations, dataset sizes after deduplication, and the full evaluation protocol—are provided in the Experiments and Results sections. To make the abstract self-contained, we will revise it to include the key numerical highlights (e.g., correlation value and relative improvements) while preserving brevity. revision: yes
-
Referee: [Method] Method (conditioning representation): the assertion that 2D kinematic skeleton rendering 'generalizes across different robot arms or even human hands' and preserves 'precise action information' is load-bearing for both the cross-embodiment claim and the virtual-real correlation; the manuscript does not address or test whether projection from 3D joint configurations to 2D discards depth/out-of-plane cues that would degrade fidelity for kinematically dissimilar embodiments.
Authors: The 2D skeleton rendering was selected precisely because it yields a compact, embodiment-agnostic signal that can be generated from any 3D joint set. The manuscript demonstrates cross-embodiment generalization through training and evaluation on multiple robot arms plus human-hand data. However, we agree that an explicit analysis of information loss from 3D-to-2D projection (depth/out-of-plane cues) is not present. We will add a dedicated paragraph discussing this potential limitation and its implications for kinematically dissimilar embodiments. revision: partial
Circularity Check
No significant circularity: central claim is empirical correlation with external real-world data
full rationale
The paper presents OSCAR as a finetuned video world model using 2D kinematic skeleton rendering for cross-embodiment conditioning, with the load-bearing claim being an observed correlation between its virtual policy evaluations (on RoboArena policies) and separate real-world evaluations. This correlation is reported as an experimental outcome resting on external measurements rather than any derivation, equation, or fitted quantity internal to the model. No self-citations, uniqueness theorems, ansatzes, or renamings are invoked in a load-bearing way; the conditioning choice is stated as an adoption without reducing the correlation result to a self-definition. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Atreya, K
P. Atreya, K. Pertsch, T. Lee, M. J. Kim, A. Jain, A. Kuramshin, C. Neary, E. S. Hu, K. Arora, K. Ellis, et al. Roboarena: Distributed real-world evaluation of generalist robot policies. InConference on Robot Learning, pages 336–364. PMLR, 2025
2025
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
-
[5]
Y . Liao, P. Zhou, S. Huang, D. Yang, S. Chen, Y . Jiang, Y . Hu, J. Cai, S. Liu, J. Luo, et al. Genie envisioner: A unified world foundation platform for robotic manipulation.arXiv preprint arXiv:2508.05635, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, and other. World simulation with video foundation models for physical AI.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation. InAdvances in neural information processing systems, volume 36, pages 9156–9172, 2023
2023
-
[8]
S. Yang, Y . Du, S. K. S. Ghasemipour, J. Tompson, L. P. Kaelbling, D. Schuurmans, and P. Abbeel. Learning interactive real-world simulators. InInternational Conference on Learning Representations, 2024
2024
-
[9]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. InInternational Conference on Learning Representations, 2024
2024
-
[10]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations. InInternational Conference on Machine Learning, pages 24328–24346. PMLR, 2025
2025
-
[11]
F. Zhu, H. Wu, S. Guo, Y . Liu, C. Cheang, and T. Kong. Irasim: A fine-grained world model for robot manipulation.Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9834–9844, 2025
2025
-
[12]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies. InICLR 2026 the 2nd Workshop on World Models: Understanding, Modelling and Scaling, 2026
2026
-
[13]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models.Conference on Robot Learning, pages 5170–5194, 2025
2025
-
[14]
Jiang, S
Y . Jiang, S. Chen, S. Huang, L. Chen, P. Zhou, Y . Liao, X. HE, C. Liu, H. Li, M. Yao, et al. Enerverse-ac: Envisioning embodied environments with action condition.NeurIPS 2025 Workshop on Embodied World Models for Decision Making, 2025
2025
-
[15]
Y . Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-World: A controllable generative world model for robot manipulation. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[16]
S. Gao, S. Zhou, Y . Du, J. Zhang, and C. Gan. Adaworld: Learning adaptable world models with latent actions.International Conference on Machine Learning, pages 18744–18771, 2025
2025
-
[17]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, et al. Dream- dojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026. 9
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, and S. Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Computer Vision, pages 306–324. Springer, 2024
2024
-
[20]
X. Yang, B. Li, S. Xu, N. Wang, C. Ye, Z. Chen, M. Qin, Y . Du, X. Jin, H. Zhao, and H. Zhao. ORV: 4D occupancy-centric robot video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[21]
Y . Wang, C. Wen, H. Guo, S. Peng, M. Qin, H. Bao, X. Zhou, and R. Hu. Precise action-to-video generation through visual action prompts.Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12713–12724, 2025
2025
-
[22]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
H. Zhen, Q. Sun, H. Zhang, J. Li, S. Zhou, Y . Du, and C. Gan. TesserAct: Learning 4D embodied world models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[24]
X. Li, K. Hsu, J. Gu, O. Mees, K. Pertsch, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kirmani, et al. Evaluating real-world robot manipulation policies in simulation. InConference on Robot Learning, pages 3705–3728. PMLR, 2025
2025
- [25]
-
[26]
J. Quevedo, A. K. Sharma, Y . Sun, V . Suryavanshi, P. Liang, and S. Yang. Worldgym: World model as an environment for policy evaluation.arXiv preprint arXiv:2506.00613, 2025
- [27]
- [28]
-
[29]
Romero, D
J. Romero, D. Tzionas, and M. J. Black. Embodied hands: Modeling and capturing hands and bodies together.ACM Transactions on Graphics (Proc. SIGGRAPH Asia), 36(6):245:1–245:17, 2017
2017
-
[30]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang, et al. AgiBot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
H.-S. Fang, H. Fang, Z. Tang, J. Liu, J. Wang, H. Zhu, and C. Lu. RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot.RSS 2023 Workshop on Learning for Task and Motion Planning, 2023
2023
- [32]
-
[33]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. DROID: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
R. Takanami, P. Khrapchenkov, S. Morikuni, J. Arima, Y . Takaba, S. Maeda, T. Okubo, G. Sano, S. Sekioka, A. Kadoya, et al. Airoa moma dataset: A large-scale hierarchical dataset for mobile manipulation.arXiv preprint arXiv:2509.25032, 2025
-
[35]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [36]
-
[37]
Damen, H
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, et al. The epic-kitchens dataset: Collection, challenges and baselines.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11):4125–4141, 2020. 10
2020
-
[38]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11975–11986, 2023
2023
-
[39]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Horé and D
A. Horé and D. Ziou. Image quality metrics: Psnr vs. ssim. In2010 20th International Conference on Pattern Recognition, pages 2366–2369, 2010
2010
-
[41]
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
2004
-
[42]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[43]
Towards Accurate Generative Models of Video: A New Metric & Challenges
T. Unterthiner, S. van Steenkiste, K. Kurach, R. Marinier, M. Michalski, and S. Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[45]
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.Advances in Neural Information Processing Systems, 38:35928–35959, 2026
2026
-
[46]
J. Lu, Z. Liang, T. Xie, F. Richter, S. Lin, S. Liu, and M. C. Yip. Ctrnet-x: Camera-to-robot pose estimation in real-world conditions using a single camera. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 1914–1920. IEEE, 2025
1914
-
[47]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), pages 611–626, 2023
2023
-
[48]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2018
2018
-
[49]
Ho and T
J. Ho and T. Salimans. Classifier-free diffusion guidance.NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2022
2021
-
[50]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18995–19012, 2022. 11 A Technical Appendix A.1 Data curation pipeline A.1.1 Datase...
2022
-
[51]
You need to describe the main subject of the video in detail, including their appearance, actions, expressions, and surrounding environment
-
[52]
You need to emphasize movement information in the input and different camera angles
-
[53]
Your output should convey natural movement attributes, incorporating natural actions related to the described subject category, using simple and direct verbs as much as possible
-
[54]
You should reference the detailed information in the video, such as character actions, clothing, backgrounds, and emphasize the details in the video
-
[55]
Control the rewritten prompt to around 80–100 words
-
[56]
12 Example of the rewritten English prompt:
No matter what language the user inputs, you must always output in English. 12 Example of the rewritten English prompt:
-
[57]
The girl wears a white square collar puff sleeve dress, decorated with pleats and buttons
A Japanese fresh film-style photo of a young East Asian girl with double braids sitting by the boat. The girl wears a white square collar puff sleeve dress, decorated with pleats and buttons. She has fair skin, delicate features, and slightly melancholic eyes, staring directly at the camera. Her hair falls naturally, with bangs covering part of her forehe...
-
[58]
She has long dark purple hair and red eyes, wearing a dark gray skirt and a light gray top with a white waist tie and a name tag in bold Chinese characters that says “Ziyang”
An anime illustration in vibrant thick painting style of a white girl with cat ears holding a folder, showing a slightly dissatisfied expression. She has long dark purple hair and red eyes, wearing a dark gray skirt and a light gray top with a white waist tie and a name tag in bold Chinese characters that says “Ziyang”. The background has a light yellow i...
-
[59]
The crocodile’s skin is rough and grayish-white, resembling stone or wood texture
CG game concept digital art featuring a huge crocodile with its mouth wide open, with trees and thorns growing on its back. The crocodile’s skin is rough and grayish-white, resembling stone or wood texture. Its back is lush with trees, shrubs, and thorny protrusions. With its mouth agape, the crocodile reveals a pink tongue and sharp teeth. The background...
-
[60]
Breaking Bad
In the style of an American drama promotional poster, Walter White sits in a metal folding chair wearing a yellow protective suit, with the words “Breaking Bad” written in sans-serif English above him, surrounded by piles of dollar bills and blue plastic storage boxes. He wears glasses, staring forward, dressed in a yellow jumpsuit, with his hands resting...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.