Self-Evolving Deep Research via Joint Generation and Evaluation
Pith reviewed 2026-06-28 06:28 UTC · model grok-4.3
The pith
A shared-parameter model jointly evolves a research solver and its evaluator to sustain optimization on open-ended tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
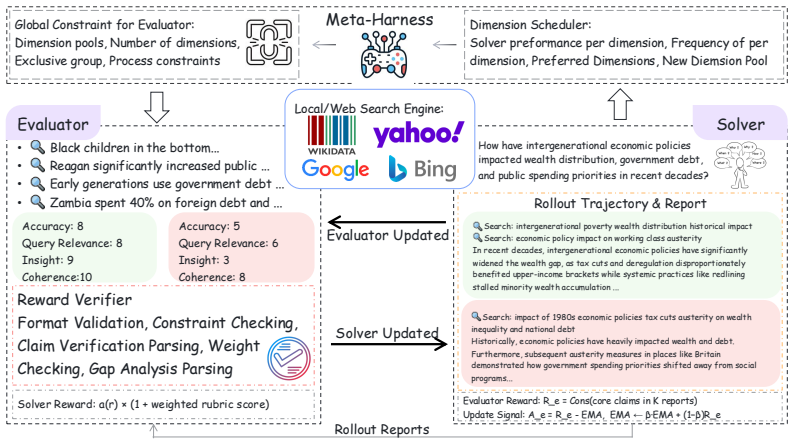
SCORE is a self-evolving co-evolutionary training framework that places an evaluator and a solver inside the same parameter set so they improve jointly; a meta-harness then dynamically adjusts the evaluation environment according to the solver’s current performance, pushing the evaluator toward valid dimensions and deeper search. Experiments on deep-research benchmarks show consistent gains in report quality, demonstrating that co-evolving evaluation and generation supplies sustained optimization pressure where isolated modules plateau.
What carries the argument
The SCORE shared-parameter co-evolutionary loop controlled by a meta-harness that scales evaluation depth with solver performance.
If this is right
- Report generation quality rises steadily instead of saturating.
- Evaluation rubrics adapt automatically to the solver’s current level.
- The same model can serve as both generator and judge without separate training runs.
- Open-ended research agents become trainable without hand-crafted reward functions.
Where Pith is reading between the lines
- The method could transfer to other subjective-output domains such as hypothesis generation or long-form creative writing.
- Shared parameters may reduce the usual misalignment between a separate judge and the generator it scores.
- If the harness tuning is insufficient, the loop risks rewarding superficial improvements that the evaluator itself learns to accept.
Load-bearing premise
The meta-harness can keep raising evaluation standards in response to solver gains without letting the shared model settle on trivial or biased criteria.
What would settle it
Train the same base model once with the full SCORE loop and once with a frozen static evaluator; if final report quality is statistically indistinguishable, the co-evolutionary claim does not hold.
Figures




read the original abstract
Large Language Models (LLMs) have become increasingly adopted in daily applications, with deep research standing out as a particularly important capability. Unlike traditional question-answering (QA) tasks, deep research report generation lacks definitive ground-truth, making reward design inherently unverifiable and limiting effective reinforcement learning. Existing approaches mitigate this challenge with LLM-as-a-judge and query-dependent evaluation rubrics, but they still rely on static evaluators that cannot adapt their standards as the solver improves, leading to insufficient and eventually saturated optimization pressure. We address this limitation with a \textbf{s}elf-evolving \textbf{co}-evolutionary training framework for deep \textbf{re}search evaluation and generation (SCORE), which tightly couples an evaluator and a solver in a shared-parameter learning process. Rather than treating generation and evaluation as isolated modules, we leverage their intrinsic connection to enable joint improvement within a single shared-parameter model. To restrict this process, we introduce a meta-harness, which dynamically controls the evaluation environment based on solver performance, encouraging valid evaluation dimensions and sufficiently deep evaluator search. Extensive experiments on deep research benchmarks demonstrate consistent improvement in report generation quality, showing that co-evolving evaluation and generation is a promising direction for training open-ended research agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SCORE, a self-evolving co-evolutionary training framework for deep research report generation and evaluation. It tightly couples an evaluator and solver within a single shared-parameter model and introduces a meta-harness that dynamically modulates the evaluation environment according to solver performance signals, with the goal of sustaining optimization pressure and avoiding saturation. The abstract asserts that extensive experiments on deep research benchmarks demonstrate consistent improvement in report generation quality.
Significance. If the empirical claims and the meta-harness mechanism hold, the work would constitute a substantive contribution to training LLMs on open-ended tasks lacking ground truth, by replacing static LLM-as-a-judge evaluators with a jointly evolving system. The shared-parameter co-evolution idea directly targets the saturation problem identified in prior approaches and could influence future agent training pipelines if the harness is shown to maintain valid evaluation dimensions.
major comments (2)
- [Abstract] Abstract: the central empirical claim that the framework yields 'consistent improvement in report generation quality' is stated without any metrics, ablation results, baseline comparisons, or description of the experimental protocol, so the soundness of the SCORE framework cannot be assessed from the supplied text.
- [Abstract] Abstract: the meta-harness is asserted to 'dynamically control the evaluation environment based on solver performance, encouraging valid evaluation dimensions and sufficiently deep evaluator search,' yet no analysis, pseudocode, or experimental evidence is supplied to show that this external pressure is sufficient to prevent the shared-parameter model from converging on trivial or self-reinforcing rubrics, which is load-bearing for the co-evolutionary claim.
Simulated Author's Rebuttal
We thank the referee for highlighting issues with the abstract's level of detail. We address each comment below and will revise the abstract accordingly to improve clarity and informativeness while preserving its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that the framework yields 'consistent improvement in report generation quality' is stated without any metrics, ablation results, baseline comparisons, or description of the experimental protocol, so the soundness of the SCORE framework cannot be assessed from the supplied text.
Authors: The abstract is intended as a high-level summary and therefore omits specific numbers and protocol details, which are provided in the full manuscript (Experiments section, including quantitative metrics on deep research benchmarks, ablation studies on shared-parameter co-evolution, and comparisons against static LLM-as-a-judge baselines). We agree the abstract could better convey the empirical support and will revise it to include representative performance gains and a brief protocol outline. revision: yes
-
Referee: [Abstract] Abstract: the meta-harness is asserted to 'dynamically control the evaluation environment based on solver performance, encouraging valid evaluation dimensions and sufficiently deep evaluator search,' yet no analysis, pseudocode, or experimental evidence is supplied to show that this external pressure is sufficient to prevent the shared-parameter model from converging on trivial or self-reinforcing rubrics, which is load-bearing for the co-evolutionary claim.
Authors: The meta-harness design, including its performance-signal modulation to avoid rubric collapse, along with supporting analysis and pseudocode, appears in Section 3; empirical results demonstrating sustained optimization pressure are in the Experiments section. The abstract does not include these elements. We will revise the abstract to briefly note the harness mechanism and its role in maintaining valid evaluation dimensions. revision: yes
Circularity Check
No circularity; framework proposal is self-contained without reductions to inputs
full rationale
The paper describes a methodological proposal for a co-evolutionary training framework (SCORE) that jointly trains evaluator and solver via shared parameters, with a meta-harness to modulate the environment. The abstract and available text contain no equations, parameter fits presented as predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior work. No derivation chain reduces any claimed result to its own inputs by construction; the approach is an empirical training recipe whose validity rests on external benchmarks rather than internal redefinition. This is the normal case of a non-circular systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://docs.gptr.dev/docs/gpt-researcher/ getting-started/introduction
gpt-researcher. URL https://docs.gptr.dev/docs/gpt-researcher/ getting-started/introduction
-
[2]
URLhttps://github.com/langchain-ai/open_deep_research
open-deep-research. URLhttps://github.com/langchain-ai/open_deep_research
-
[3]
URL https://openai.com/zh-Hans-CN/index/ introducing-gpt-5-2/
Introduction gpt-5.2, 2025. URL https://openai.com/zh-Hans-CN/index/ introducing-gpt-5-2/
2025
-
[4]
Hongbo Bai, Yujin Zhou, Yile Wu, Chi-Min Chan, Pengcheng Wen, Kunhao Pan, Sirui Han, and Yike Guo. Glance-or-gaze: Incentivizing lmms to adaptively focus search via reinforcement learning.arXiv preprint arXiv:2601.13942, 2026
Pith/arXiv arXiv 2026
-
[5]
Agentcpm-explore: Realizing long-horizon deep exploration for edge-scale agents, 2026
Haotian Chen, Xin Cong, Shengda Fan, Yuyang Fu, Ziqin Gong, Yaxi Lu, Yishan Li, Boye Niu, Chengjun Pan, Zijun Song, Huadong Wang, Yesai Wu, Yueying Wu, Zihao Xie, Yukun Yan, Zhong Zhang, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Agentcpm-explore: Realizing long-horizon deep exploration for edge-scale agents, 2026. URLhttps://arxiv.org/abs/ 2602.06485
arXiv 2026
-
[6]
SPar: Self-play with tree-search refinement to improve instruction-following in large language models
Jiale Cheng, Xiao Liu, Cunxiang Wang, Xiaotao Gu, Yida Lu, Dan Zhang, Yuxiao Dong, Jie Tang, Hongning Wang, and Minlie Huang. SPar: Self-play with tree-search refinement to improve instruction-following in large language models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=9chRqsPOGL
2025
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URLhttps://arxiv.org/abs/2507.06261
Pith/arXiv arXiv 2025
-
[8]
Deepseek-v3.2: Pushing the frontier of open large language models, 2025
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, et al. Deepseek-v3.2: Pushing the frontier of open large language models, 2025. URL https://arxiv.org/abs/2512.02556
Pith/arXiv arXiv 2025
-
[9]
On group relative policy optimization collapse in agent search: The lazy likelihood-displacement,
Wenlong Deng, Yushu Li, Boying Gong, Yi Ren, Christos Thrampoulidis, and Xiaoxiao Li. On group relative policy optimization collapse in agent search: The lazy likelihood-displacement,
-
[10]
URLhttps://arxiv.org/abs/2512.04220
-
[11]
Sutherland, Xiaoxiao Li, and Christos Thram- poulidis
Wenlong Deng, Yi Ren, Muchen Li, Danica J. Sutherland, Xiaoxiao Li, and Christos Thram- poulidis. On the effect of negative gradient in group relative deep reinforcement optimization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=2K9QsDaqkM
2026
-
[12]
Adarubric: Task-adaptive rubrics for llm agent evaluation, 2026
Liang Ding. Adarubric: Task-adaptive rubrics for llm agent evaluation, 2026. URL https: //arxiv.org/abs/2603.21362
Pith/arXiv arXiv 2026
-
[13]
A survey on code generation with llm-based agents.arXiv preprint arXiv:2508.00083, 2025
Yihong Dong, Xue Jiang, Jiaru Qian, Tian Wang, Kechi Zhang, Zhi Jin, and Ge Li. A survey on code generation with llm-based agents.arXiv preprint arXiv:2508.00083, 2025
Pith/arXiv arXiv 2025
-
[14]
Deepresearch bench: A comprehensive benchmark for deep research agents
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Licheng Zhang, Xiaorui Wang, and Zhendong Mao. Deepresearch bench: A comprehensive benchmark for deep research agents. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=hQ0K2Hhq7H. 10
2026
-
[15]
SeRL: Self-play reinforcement learning for large language models with limited data
Wenkai Fang, Shunyu Liu, Yang Zhou, Kongcheng Zhang, Tongya Zheng, Kaixuan Chen, Mingli Song, and Dacheng Tao. SeRL: Self-play reinforcement learning for large language models with limited data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=ZF93vyH9He
2026
-
[16]
Dr-arena: an automated evaluation framework for deep research agents, 2026
Yiwen Gao, Ruochen Zhao, Yang Deng, and Wenxuan Zhang. Dr-arena: an automated evaluation framework for deep research agents, 2026. URL https://arxiv.org/abs/2601. 10504
2026
-
[17]
The llama 3 herd of models, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, et al. The llama 3 herd of models, 2024. URLhttps://arxiv.org/abs/2407. 21783
2024
-
[18]
How far can unsupervised RLVR scale LLM training? InThe Fourteenth International Conference on Learning Representations, 2026
Bingxiang He, Yuxin Zuo, Zeyuan Liu, Shangziqi Zhao, Zixuan Fu, Junlin Yang, Cheng Qian, Kaiyan Zhang, Yuchen Fan, Ganqu Cui, Xiusi Chen, Youbang Sun, Xingtai Lv, Xuekai Zhu, Li Sheng, Ran Li, Huan ang Gao, Yuchen Zhang, Lifan Yuan, Bowen Zhou, Zhiyuan Liu, and Ning Ding. How far can unsupervised RLVR scale LLM training? InThe Fourteenth International Con...
2026
-
[19]
Step-deepresearch technical report, 2025
Chen Hu, Haikuo Du, Heng Wang, Lin Lin, Mingrui Chen, Peng Liu, Ruihang Miao, Tianchi Yue, Wang You, Wei Ji, Wei Yuan, Wenjin Deng, Xiaojian Yuan, Xiaoyun Zhang, Xiangyu Liu, Xikai Liu, Yanming Xu, Yicheng Cao, Yifei Zhang, Yongyao Wang, Yubo Shu, Yurong Zhang, Yuxiang Zhang, Zheng Gong, Zhichao Chang, Binyan Li, Dan Ma, Furong Jia, Hongyuan Wang, Jiayu L...
arXiv 2025
-
[20]
R-zero: Self-evolving reasoning LLM from zero data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning LLM from zero data. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=96apU6YzSO
2026
-
[21]
NeMo guardrails: A toolkit for controllable and safe LLM applications with pro- grammable rails
Yucheng Jiang, Yijia Shao, Dekun Ma, Sina Semnani, and Monica Lam. Into the unknown un- knowns: Engaged human learning through participation in language model agent conversations. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9917–9955, Miami, Flo...
-
[22]
Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=Rwhi91ideu
2025
-
[23]
Prometheus: Inducing fine- grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine- grained evaluation capability in language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=8euJaTveKw
2024
-
[24]
Meta-harness: End-to-end optimization of model harnesses, 2026
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses, 2026. URL https://arxiv.org/ abs/2603.28052
Pith/arXiv arXiv 2026
-
[25]
Writing-rl: Advancing long-form writing via adaptive curriculum reinforcement learning, 2026
Xuanyu Lei, Chenliang Li, Yuning Wu, Kaiming Liu, Weizhou Shen, Peng Li, Ming Yan, Fei Huang, Ya-Qin Zhang, and Yang Liu. Writing-rl: Advancing long-form writing via adaptive curriculum reinforcement learning, 2026. URLhttps://arxiv.org/abs/2506.05760. 11
Pith/arXiv arXiv 2026
-
[26]
The dawn after the dark: An empirical study on factuality hallucination in large language models
Junyi Li, Jie Chen, Ruiyang Ren, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. The dawn after the dark: An empirical study on factuality hallucination in large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),...
-
[27]
Multiple human motion understanding
Lei Li, Sen Jia, and Jenq-Neng Hwang. Multiple human motion understanding. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 6297–6305, 2026
2026
-
[28]
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420– ...
-
[29]
Webthinker: Empowering large reasoning models with deep research capability
Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yongkang Wu, Ji-Rong Wen, Yutao Zhu, and Zhicheng Dou. Webthinker: Empowering large reasoning models with deep research capability. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[30]
URLhttps://openreview.net/forum?id=7LKKHBAMzH
-
[31]
Agentcpm-report: Interleaving drafting and deepening for open-ended deep research, 2026
Yishan Li, Wentong Chen, Yukun Yan, Mingwei Li, Sen Mei, Xiaorong Wang, Kunpeng Liu, Xin Cong, Shuo Wang, Zhong Zhang, Yaxi Lu, Zhenghao Liu, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Agentcpm-report: Interleaving drafting and deepening for open-ended deep research, 2026. URLhttps://arxiv.org/abs/2602.06540
arXiv 2026
-
[32]
SPIRAL: Self-play on zero-sum games incentivizes reasoning via multi-agent multi-turn reinforcement learning
Bo Liu, Simon Yu, Zichen Liu, Leon Guertler, Penghui Qi, Daniel Balcells, Mickel Liu, Cheston Tan, Weiyan Shi, Min Lin, Wee Sun Lee, and Natasha Jaques. SPIRAL: Self-play on zero-sum games incentivizes reasoning via multi-agent multi-turn reinforcement learning. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //ope...
2026
-
[33]
Search self-play: Pushing the frontier of agent capability without supervision
Hongliang Lu, Yuhang Wen, Pengyu Cheng, Ruijin Ding, Haotian Xu, Jiaqi Guo, Chutian Wang, Haonan Chen, xiaoxi jiang, and guanjunjiang. Search self-play: Pushing the frontier of agent capability without supervision. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=ZmGirmNJqE
2026
-
[34]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
Pith/arXiv arXiv 2025
-
[35]
Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148, 2026
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148, 2026
Pith/arXiv arXiv 2026
-
[36]
Assisting in writing Wikipedia-like articles from scratch with large language models
Yijia Shao, Yucheng Jiang, Theodore Kanell, Peter Xu, Omar Khattab, and Monica Lam. Assisting in writing Wikipedia-like articles from scratch with large language models. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T...
-
[37]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open 12 language models.CoRR, abs/2402.03300, 2024. URL https://doi.org/10.48550/arXiv. 2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[38]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297. ACM, March 2025. doi: 10.1145/3689031.3696075. URL http://dx.doi.org/ 10.1145/3689031.3696075
-
[39]
Intrinsic entropy of context length scaling in llms
Jingzhe Shi, Qinwei Ma, Hongyi Liu, Hang Zhao, Jenq-Neng Hwang, and Lei Li. Intrinsic entropy of context length scaling in llms. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[40]
Iterative self-incentivization empowers large language models as agentic searchers
Zhengliang Shi, Lingyong Yan, Dawei Yin, Suzan Verberne, Maarten de Rijke, and Zhaochun Ren. Iterative self-incentivization empowers large language models as agentic searchers. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=s9NkfkUuEr
2026
-
[41]
R1-searcher: Incentivizing the search capability in llms via reinforcement learning, 2025
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning, 2025. URLhttps://arxiv.org/abs/2503.05592
Pith/arXiv arXiv 2025
-
[42]
SimpleDeepSearcher: Deep information seeking via web-powered reasoning trajectory synthesis
Shuang Sun, Huatong Song, Yuhao Wang, Ruiyang Ren, Jinhao Jiang, Junjie Zhang, Fei Bai, Jia Deng, Wayne Xin Zhao, Zheng Liu, Lei Fang, Zhongyuan Wang, and Ji-Rong Wen. SimpleDeepSearcher: Deep information seeking via web-powered reasoning trajectory synthesis. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Find...
-
[43]
Beyond verifiable rewards: Scaling reinforcement learning in language models to unverifiable data
Yunhao Tang, Sid Wang, Lovish Madaan, and Remi Munos. Beyond verifiable rewards: Scaling reinforcement learning in language models to unverifiable data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum?id=pc6M9h3T9m
2026
-
[44]
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models, 2025
5 Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models, 2025. URL https:// arxiv.org/abs/2508.06471
Pith/arXiv arXiv 2025
-
[45]
Yeerpan Tuohetiyaer, Yuye Zhu, Yan Hu, Siyuan Lu, and Zhongfeng Wang. Deep-research eval: An automated framework for assessing quality and reliability in long-form reports. Applied Sciences, 16(5), 2026. ISSN 2076-3417. doi: 10.3390/app16052546. URL https: //www.mdpi.com/2076-3417/16/5/2546
-
[46]
Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
1992
-
[47]
Ho, Linjun Zhang, Haoyu Wang, Wenqi Shi, and Carl Yang
Ran Xu, Yuchen Zhuang, Zihan Dong, Ruiyu Wang, Yue Yu, Joyce C. Ho, Linjun Zhang, Haoyu Wang, Wenqi Shi, and Carl Yang. Acesearcher: Bootstrapping reasoning and search for LLMs via reinforced self-play. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=jSgCM0uZn3
2026
-
[48]
3dsceneeditor: Controllable 3d scene editing with gaussian splatting
Ziyang Yan, Yihua Shao, Minwen Liao, Siyu Chen, Nan Wang, Muyuan Lin, Jenq-Neng Hwang, Hao Zhao, Fabio Remondino, and Lei Li. 3dsceneeditor: Controllable 3d scene editing with gaussian splatting. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1852–1863, March 2026
2026
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[50]
Trajectory-LLM: A language-based data generator for trajectory prediction in autonomous driving
Kairui Yang, Zihao Guo, Gengjie Lin, Haotian Dong, Zhao Huang, Yipeng Wu, Die Zuo, Jibin Peng, Ziyuan Zhong, Xin WANG, Qing Guo, Xiaosong Jia, Junchi Yan, and Di Lin. Trajectory-LLM: A language-based data generator for trajectory prediction in autonomous driving. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://open...
2025
-
[51]
Countllm: Towards generalizable repetitive action counting via large language model
Ziyu Yao, Xuxin Cheng, Zhiqi Huang, and Lei Li. Countllm: Towards generalizable repetitive action counting via large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[52]
Zhenrui Yue, Kartikeya Upasani, Xianjun Yang, Suyu Ge, Shaoliang Nie, Yuning Mao, Zhe Liu, and Dong Wang. Dr. zero: Self-evolving search agents without training data.arXiv preprint arXiv:2601.07055, 2026
arXiv 2026
-
[53]
EvolveSearch: An iterative self- evolving search agent
Ding-Chu Zhang, Yida Zhao, Jialong Wu, Liwen Zhang, Baixuan Li, Wenbiao Yin, Yong Jiang, Yu-Feng Li, Kewei Tu, Pengjun Xie, and Fei Huang. EvolveSearch: An iterative self- evolving search agent. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Lang...
-
[54]
Beyond length scaling: Synergizing breadth and depth for generative reward models, 2026
Qiyuan Zhang, Yufei Wang, Tianhe Wu, Can Xu, Qingfeng Sun, Kai Zheng, Xue Liu, and Chen Ma. Beyond length scaling: Synergizing breadth and depth for generative reward models, 2026. URLhttps://arxiv.org/abs/2603.01571
arXiv 2026
-
[55]
A survey on self-play methods in reinforcement learning.arXiv preprint arXiv:2408.01072, 2024
Ruize Zhang, Zelai Xu, Chengdong Ma, Chao Yu, Wei-Wei Tu, Wenhao Tang, Shiyu Huang, Deheng Ye, Wenbo Ding, Yaodong Yang, et al. A survey on self-play methods in reinforcement learning.arXiv preprint arXiv:2408.01072, 2024
arXiv 2024
-
[56]
Xin Zhang, Shen Chen, Jiale Zhou, and Lei Li. Psgs: Text-driven panorama sliding scene generation via gaussian splatting.arXiv preprint arXiv:2602.00463, 2026
arXiv 2026
-
[57]
Absolute zero: Reinforced self-play reasoning with zero data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=neZSGqhxDa
2025
-
[58]
Learning to reason without external rewards
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to reason without external rewards. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=OU9nFEYR2M
2026
-
[59]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[60]
Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. DeepResearcher: Scaling deep research via reinforcement learning in real-world environments. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language P...
-
[61]
Lras: Advanced legal reasoning with agentic search, 2026
Yujin Zhou, Chuxue Cao, Jinluan Yang, Lijun Wu, Conghui He, Sirui Han, and Yike Guo. Lras: Advanced legal reasoning with agentic search, 2026. URL https://arxiv.org/abs/2601. 07296. 14 A Limitations Despite the effectiveness of our self-evolving framework, we acknowledge several limitations in our current study. First, the unique nature of deep research r...
2026
-
[62]
the raw evaluator-side consistency signal estimates the expected reproducibility induced by a rubric under repeated solver rollouts
-
[63]
no other means
the shared-parameter solver-evaluator alternating updates follow, to first order, a KL- regularized surrogate descent direction, with only a higher-order residual due to sequential updating. G Experiments G.1 Training Details Table 2: Main training hyperparameters in SCORE. Category Configuration Learning rate1×10 −6 Warmup 5 steps, warmup ratio 0.05 Trai...
2048
-
[64]
C o m p r e h e n s i v e n e s s ( I n f o r m a t i o n C ov er ag e ) - E va lua te the breadth , depth , and r e l e v a n c e of i n f o r m a t i o n cov er ag e . - Ensure the article covers key i n f o r m a t i o n areas , perspectives , and depths n e c e s s a r y to achieve c o m p r e h e n s i v e market or s i t u a t i o n a l an al ysi s ...
-
[65]
22 - Assess whether the a na ly sis goes beyond a s u p e r f i c i a l listing of factors to uncover core drivers , subtle mechanisms , and second - order effects
Insight ( A n a l y t i c a l Depth ) - E va lua te the depth , originality , logic , and value of the a na ly sis and c o n c l u s i o n s . 22 - Assess whether the a na ly sis goes beyond a s u p e r f i c i a l listing of factors to uncover core drivers , subtle mechanisms , and second - order effects . - Examine if the c o n c l u s i o n s and r e c...
-
[66]
- Check for strict a d h e r e n c e to scope l i m i t a t i o n s ( e
I n s t r u c t i o n F o l l o w i n g ( R e s p o n s i v e n e s s & R e l e v a n c e ) - E va lua te whether the report accurately , completely , and di re ct ly r es pon ds to all spe ci fi c instructions , questions , and core o b j e c t i v e s within the ‘< task > ‘. - Check for strict a d h e r e n c e to scope l i m i t a t i o n s ( e . g . ,...
-
[67]
d i m e n s i o n _ c o n s t r a i n t s
R e a d a b i l i t y ( P r e s e n t a t i o n Quality ) - E va lua te the clarity of structure , fluency of language , e f f e c t i v e n e s s of data presentation , and overall ease of u n d e r s t a n d i n g . - Assess s t r u c t u r a l logic ( clear f r a m e w o r k and logical flow ) , la ng ua ge p r e c i s i o n ( fluent , g r a m m a t i ...
-
[68]
{ m u s t _ i n c l u d e } is always re qu ir ed as the primary scoring d i m e n s i o n . Select exactly {k -1} a d d i t i o n a l d i m e n s i o n s from the r e m a i n i n g pool and assign weights , each a d d i t i o n a l dimension ’ s weight must be within [{ Weight Min } , { Weight Max }]
-
[69]
Verify key claims and c i t a t i o n s in each report using the a v a i l a b l e search tool
-
[70]
Perform i n d e p e n d e n t re sea rc h from the o ri gi na l query to i de nti fy i m p o r t a n t gaps not covered by each report
-
[71]
[ Base D i m e n s i o n ]
Score each report on every se le cte d d i m e n s i o n using the e vi de nce you found . ## Tool - use pr ot oc ol : - When you need ex te rn al evidence , you can use search tools with search query in this format : < search > your search query here </ search > - The content inside < search > must be only the query text . Do not output JSON , function -...
-
[72]
Think inside < think > and </ think > before each action and after each new search result
-
[73]
Use the exact format < search > your query here </ search > to issue a search
When ex te rn al e vi den ce is needed , emit exactly one s t a n d a l o n e search query . Use the exact format < search > your query here </ search > to issue a search
-
[74]
Do not output JSON , tool names , XML attributes , bullet lists , or m ult ip le queries in one search block
The content inside < search > must be only the query text . Do not output JSON , tool names , XML attributes , bullet lists , or m ult ip le queries in one search block
-
[75]
Prefer natural web search queries : start broad , then narrow to verification , recent developments , entity - s pec if ic facts , or missing p e r s p e c t i v e s
-
[76]
Prefer m ul ti ple s e q u e n t i a l sea rc he s over one o v e r l o a d e d query
-
[77]
Stop s e a r c h i n g once you can answer c o n f i d e n t l y
Use search to verify i m p o r t a n t claims , gather evidence , and close i n f o r m a t i o n gaps . Stop s e a r c h i n g once you can answer c o n f i d e n t l y
-
[78]
The e n v i r o n m e n t will return search results between < observation > and </ observation >
-
[79]
When you have enough evidence , write the final re sp on se only inside < answer > and </ answer >
-
[80]
24 Listing 5: Prompt for solver 25
In the final answer , s y n t h e s i z e the evidence , note u n c e r t a i n t y when necessary , and include source m en ti ons or a short Sources section . 24 Listing 5: Prompt for solver 25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.