CYGNET: Cypher Gate for Neural Execution Triage and Cost Containment
Pith reviewed 2026-06-28 06:47 UTC · model grok-4.3
The pith
A pre-execution gate using a mirror graph catches every structural Cypher error from language models at zero false positives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
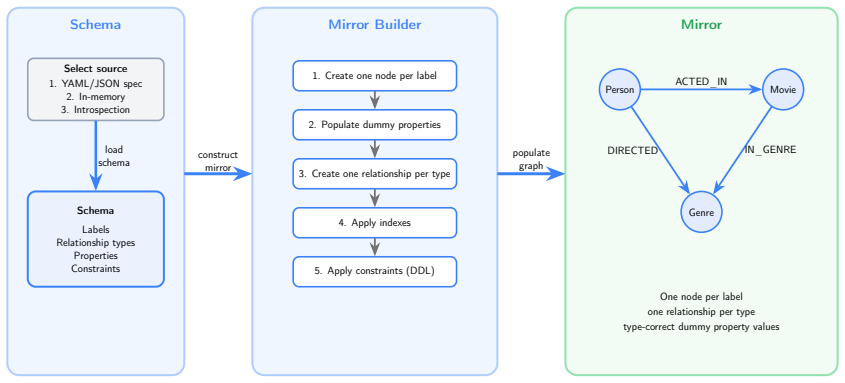
CYGNET validates structure through a four-backend chain culminating in execution against a mirror graph at 5.6 ms median latency. Structurally broken queries are routed to a corrector that iterates structured error feedback through a language model. On seven CypherBench schemas the pipeline maintains generation accuracy on every model tested. The corrector achieves 81% to 95% success across five models. On a template-generated corpus the gate catches 100% of parse errors, 100% of constraint violations, and 100% of schema-reference errors in path queries with labelled endpoints, at zero false positives across 1135 queries.
What carries the argument
The four-backend validation chain that executes queries against a mirror graph to detect structural failures before production.
If this is right
- The pipeline preserves generation accuracy on every model tested across 2348 questions.
- The corrector repairs 81% to 95% of broken queries (mean 89%).
- Property sibling-swaps that remain valid on the target label mark the formal boundary between structural and semantic validation.
- A planner-based cost gate flags catastrophic plan structures before execution.
Where Pith is reading between the lines
- The same staged gate could be applied to other query languages and graph stores beyond Neo4j.
- The separation of structural from semantic checks suggests a modular defense that later layers can build upon.
- Low median latency supports insertion into real-time agent loops without noticeable slowdown.
Load-bearing premise
The mirror graph is an exact structural replica of the production database and the four-backend chain covers all possible structural failure modes.
What would settle it
A query that passes the gate yet produces a parse error, constraint violation, or schema-reference error when executed on the production database would falsify the claim.
Figures


read the original abstract
Language models acting as agents over knowledge graphs generate Cypher queries that fail structurally (crashing at the database) or semantically (executing but returning wrong results). We place a pre-execution gate between query generation and a production Neo4j database. The gate validates structure through a four-backend chain culminating in execution against a mirror graph at 5.6 ms median latency. Structurally broken queries are routed to a corrector that iterates structured error feedback through a language model. On seven CypherBench schemas (2348 questions, ACL 2025) the pipeline maintains generation accuracy on every model tested, confirming it operates as a safe defensive layer. The corrector achieves 81% to 95% success across five models (mean 89%). On a template-generated corpus across nine schemas the gate catches 100% of parse errors, 100% of constraint violations, and 100% of schema-reference errors in path queries with labelled endpoints, at zero false positives across 1135 queries. Property sibling-swaps where the substituted name is valid on the target label score 0%, marking the formal boundary where structural validation ends and semantic validation must begin. A planner-based cost gate flags catastrophic plan structures before execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CYGNET, a pre-execution gate placed between LLM-generated Cypher queries and a production Neo4j database. It employs a four-backend validation chain ending in execution against a mirror graph (median 5.6 ms latency), routes structurally invalid queries to an iterative LM corrector, and adds a planner-based cost gate. On CypherBench (seven schemas, 2348 questions) the pipeline preserves generation accuracy; the corrector achieves 81-95% success (mean 89%). On a template corpus across nine schemas the gate reports 100% detection of parse errors, constraint violations, and schema-reference errors in labelled-endpoint path queries at 0% false positives over 1135 queries, while property sibling-swaps that remain syntactically valid score 0%.
Significance. If the mirror-graph fidelity and backend-coverage assumptions can be independently verified, the work supplies a concrete, low-latency defensive layer that separates structural from semantic validation for LLM agents over graph databases. The explicit 0% result on valid-name sibling swaps usefully demarcates the boundary at which structural triage must hand off to semantic checking.
major comments (3)
- [Abstract] Abstract: the headline result (100% catch of parse, constraint, and schema-reference errors at 0 FP on 1135 queries) is obtained by final-stage execution against the mirror graph, yet the manuscript supplies neither a verification procedure confirming that the mirror schema, labels, relationships, and constraints are bitwise identical to the production Neo4j instance nor a completeness argument that the four-backend chain exercises every possible structural Cypher failure mode.
- [Abstract] Abstract / Results: the reported performance figures (100% catch rates, 0 false positives, 89% mean corrector success) are presented as direct measurements on fixed benchmark sets with no dataset splits, error analysis, or description of how the template-generated corpus was constructed to ensure coverage of the claimed error classes, rendering the central empirical claims unverifiable from the given text.
- [Abstract] Abstract: the transfer of the reported rates to live production queries rests on the untested assumptions that the mirror graph is an exact replica and that the four backends exhaustively cover all structural failure modes; any divergence or unexercised Cypher construct would falsify the claimed 100%/0% figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments identifying gaps in verifiability. We address each point below and will revise the manuscript to incorporate additional detail on mirror construction, corpus methodology, and assumption caveats while preserving the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline result (100% catch of parse, constraint, and schema-reference errors at 0 FP on 1135 queries) is obtained by final-stage execution against the mirror graph, yet the manuscript supplies neither a verification procedure confirming that the mirror schema, labels, relationships, and constraints are bitwise identical to the production Neo4j instance nor a completeness argument that the four-backend chain exercises every possible structural Cypher failure mode.
Authors: We agree the current text lacks an explicit verification procedure. In revision we will add a methods subsection describing mirror construction via Neo4j schema export, constraint replication, and automated metadata checksums to confirm bitwise identity on labels, relationships, and constraints. For completeness, we will expand the discussion to argue that the four backends (parser, schema validator, constraint checker, mirror execution) systematically target all structural failure modes detectable without query intent, while noting that exhaustive enumeration of every Cypher construct remains an open formal question. revision: yes
-
Referee: [Abstract] Abstract / Results: the reported performance figures (100% catch rates, 0 false positives, 89% mean corrector success) are presented as direct measurements on fixed benchmark sets with no dataset splits, error analysis, or description of how the template-generated corpus was constructed to ensure coverage of the claimed error classes, rendering the central empirical claims unverifiable from the given text.
Authors: The template corpus is generated from parameterized templates explicitly designed to inject the targeted error classes across the nine schemas; the full manuscript methods section enumerates the templates and resulting query counts. To improve verifiability we will add an expanded description of template construction, a per-error-class breakdown of the 1135 queries, and a short error analysis. Because the evaluation is exhaustive rather than a sampled training regime, no train/test splits were applied; we will insert a brief justification for reporting on the complete fixed sets. revision: yes
-
Referee: [Abstract] Abstract: the transfer of the reported rates to live production queries rests on the untested assumptions that the mirror graph is an exact replica and that the four backends exhaustively cover all structural failure modes; any divergence or unexercised Cypher construct would falsify the claimed 100%/0% figures.
Authors: We accept that transfer to production depends on these assumptions and will revise the discussion to state them explicitly, describe the synchronization protocol used to keep the mirror current, and note the sibling-swap result as the boundary beyond which semantic validation is required. We will also add a limitations paragraph acknowledging that unexercised Cypher constructs could affect coverage and that the 100%/0% figures are benchmark-specific. revision: yes
Circularity Check
No circularity: empirical measurements on fixed benchmarks with no fitted quantities or self-referential derivations
full rationale
The paper reports direct empirical measurements of error detection rates (100% catch at 0% false positives on 1135 template queries) obtained by executing the four-backend validation chain against a mirror graph. No equations, parameter fitting, or derivation steps are described that would reduce the reported outcomes to the inputs by construction. The core claims rest on benchmark execution results rather than any self-definitional, fitted-prediction, or self-citation load-bearing structure. Assumptions about mirror-graph fidelity are external to the measurement process itself and do not create circularity in the reported detection statistics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Knowledge graph-guided retrieval augmented generation
Xiangrong Zhu, Yuexiang Xie, Yi Liu, Yaliang Li, and Wei Hu. Knowledge graph-guided retrieval augmented generation. InProceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pages 8912–8924, 2025. doi: 10.18653/v1/2025.naacl-long.449
-
[2]
Graph retrieval-augmented generation: A survey.ACM Transactions on Information Systems, 44(2):1–52, 2026
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. Graph retrieval-augmented generation: A survey.ACM Transactions on Information Systems, 44(2):1–52, 2026
2026
-
[3]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From lo- cal to global: A graph RAG approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
Pith/arXiv arXiv 2024
-
[4]
Cypher: An evolving query language for property graphs
Nadime Francis, Alastair Green, Paolo Guagliardo, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Stefan Plantikow, Mats Rydberg, Petra Selmer, and Andrés Taylor. Cypher: An evolving query language for property graphs. InProceedings of the 2018 International Conference on Management of Data (SIGMOD), pages 1433–1445, 2018. doi: 10.1145/ 3183713.3190657
arXiv 2018
-
[5]
Reham Omar, Abdelghny Orogat, Ibrahim Abdelaziz, Omij Mangukiya, Panos Kalnis, and Essam Mansour. Chatty-KG: A multi-agent AI system for on-demand conversational question answering over knowledge graphs.Proceedings of the ACM on Management of Data, 4(1): 18:1–18:26, 2026. doi: 10.1145/3786632
-
[6]
Xinjie Zhao, Moritz Blum, Rui Yang, Boming Yang, Luis Márquez Carpintero, Mónica Pina-Navarro, Tony Wang, Xin Li, Huitao Li, Yanran Fu, Rongrong Wang, Juntao Zhang, and Irene Li. AGENTiGraph: An interactive knowledge graph platform for LLM-based chatbots utilising private data.arXiv preprint arXiv:2410.11531, 2024
arXiv 2024
-
[7]
Ioanna Mandilara, Christina Maria Androna, Eleni Fotopoulou, Anastasios Zafeiropoulos, and Symeon Papavassiliou. Decoding the mystery: How can LLMs turn text into Cypher in complex knowledge graphs?IEEE Access, 13:80981–81001, 2025. doi: 10.1109/ACCESS. 2025.3567759
-
[8]
CypherQueryCorrector in the LangChain Neo4j integration
LangChain. CypherQueryCorrector in the LangChain Neo4j integration. Python pack- age, langchain-neo4j, 2023. https://python.langchain.com/docs/integrations/graphs/ neo4j_cypher/
2023
-
[9]
mcp-neo4j-cypher: Model context protocol server for Neo4j
Neo4j Labs. mcp-neo4j-cypher: Model context protocol server for Neo4j. GitHub repository, 2024.https://github.com/neo4j-contrib/mcp-neo4j
2024
-
[10]
Makbule Gulcin Ozsoy. Extending confidence-based Text2Cypher with grammar and schema aware filtering.arXiv preprint arXiv:2605.10318, 2026. 20
Pith/arXiv arXiv 2026
-
[11]
Aman Tiwari, Shiva Krishna Reddy Malay, Vikas Yadav, Masoud Hashemi, and Sath- wik Tejaswi Madhusudhan. SynthCypher: A fully synthetic data generation framework for text-to-Cypher querying in knowledge graphs.arXiv preprint arXiv:2412.12612, 2024
arXiv 2024
-
[12]
SyntheT2C: Generating synthetic data for fine-tuning large language models on the text- to-Cypher task
Zijie Zhong, Linqing Zhong, Zhaoze Sun, Qingyun Jin, Zengchang Qin, and Xiaofan Zhang. SyntheT2C: Generating synthetic data for fine-tuning large language models on the text- to-Cypher task. InProceedings of the 31st International Conference on Computational Linguistics (COLING), 2025
2025
-
[13]
Pragmatic Bookshelf, 2013
Terence Parr.The Definitive ANTLR 4 Reference. Pragmatic Bookshelf, 2013
2013
-
[14]
Saurabh Deochake and Debajyoti Mukhopadhyay. Cost trade-offs of reasoning and non- reasoning large language models in text-to-SQL.arXiv preprint arXiv:2512.22364, 2025
arXiv 2025
-
[15]
Laredo, Malik Magdon-Ismail, Louis Mandel, and Erik Wittern
Georgios Mavroudeas, Guillaume Baudart, Alan Cha, Martin Hirzel, Jim A. Laredo, Malik Magdon-Ismail, Louis Mandel, and Erik Wittern. Learning GraphQL query costs.arXiv preprint arXiv:2108.11139, 2021
arXiv 2021
-
[16]
MAC-SQL: A multi-agent collaborative framework for text-to-SQL
Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Linzheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, and Zhoujun Li. MAC-SQL: A multi-agent collaborative framework for text-to-SQL. InProceedings of the 31st International Conference on Computational Linguistics (COLING), pages 540–557, 2025
2025
-
[17]
Wang, and Xi Victoria Lin
Ansong Ni, Srinivasan Iyer, Dragomir Radev, Veselin Stoyanov, Wen-tau Yih, Sida I. Wang, and Xi Victoria Lin. LEVER: Learning to verify language-to-code generation with execution. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[18]
RAMPART: Retrieval-augmented multi-block prompt assembly and registry toolkit, 2026
Nikodem Tomczak. RAMPART: Retrieval-augmented multi-block prompt assembly and registry toolkit, 2026. Paper submitted for publication
2026
-
[19]
Synthetic text-to-Cypher GPT-4 turbo dataset
Tomasz Bratanic. Synthetic text-to-Cypher GPT-4 turbo dataset. Hugging Face dataset, 2024.https://huggingface.co/datasets/tomasonjo/synthetic-text2cypher-gpt4turbo
2024
-
[20]
Enhancing Text2Cypher with schema filtering
Makbule Gulcin Ozsoy. Enhancing Text2Cypher with schema filtering. InProceedings of the 4th International Workshop on LLM-Integrated Knowledge Graph Generation from Text (LLM-TEXT2KG), co-located with ESWC 2025, volume 4020 ofCEUR Workshop Proceedings. CEUR-WS.org, 2025. arXiv:2505.05118
arXiv 2025
-
[21]
CypherBench: Towards precise retrieval over full-scale modern knowledge graphs in the LLM era
Yanlin Feng, Simone Papicchio, and Sajjadur Rahman. CypherBench: Towards precise retrieval over full-scale modern knowledge graphs in the LLM era. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8934–8958, Vienna, Austria, 2025. Association for Computational Linguistics. doi: 10.1865...
-
[22]
libcypher-parser: A parser library for the Cypher graph query language
Chris Leishman. libcypher-parser: A parser library for the Cypher graph query language. GitHub repository, 2017.https://github.com/cleishm/libcypher-parser
2017
-
[23]
Text2Cypher: Bridging natural language and graph databases
Makbule Gulcin Ozsoy, Leila Messallem, Jon Besga, and Gianandrea Minneci. Text2Cypher: Bridging natural language and graph databases. InProceedings of the Workshop on Generative AI and Knowledge Graphs (GenAIK), co-located with COLING 2025, pages 100–108, 2025. arXiv:2412.10064
arXiv 2025
-
[24]
Quoc-Bao-Huy Tran, Aagha Abdul Waheed, Syed Mudasir, and Sun-Tae Chung. Refining Text2Cypher on small language model with reinforcement learning leveraging semantic information.Applied Sciences, 15(15):8206, 2025. doi: 10.3390/app15158206. 21
-
[25]
Text2Cypher across languages: Evaluating and finetuning LLMs
Makbule Gulcin Ozsoy and William Tai. Text2Cypher across languages: Evaluating and finetuning LLMs. InProceedings of the International Conference on Natural Language Processing and Information Retrieval (NLPIR), 2025. arXiv:2506.21445
arXiv 2025
-
[26]
Chang, Fei Huang, Reynold Cheng, and Yongbin Li
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C.-C. Chang, Fei Huang, Reynold Cheng, and Yongbin Li. Can LLM already serve as a database interface? a BIGbenchforlarge-scaledatabasegroundedtext-to-SQLs. InAdvances in Neural Information Processing S...
2023
-
[27]
DIN-SQL: Decomposed in-context learning of text-to-SQL with self-correction
Mohammadreza Pourreza and Davood Rafiei. DIN-SQL: Decomposed in-context learning of text-to-SQL with self-correction. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[28]
RetrySQL: Text-to-SQL training with retry data for self-correcting query generation
Alicja Rączkowska, Riccardo Belluzzo, Piotr Zieliński, Joanna Baran, and Paweł Olszewski. RetrySQL: Text-to-SQL training with retry data for self-correcting query generation. In Proceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[29]
Yushan Zhu, Wen Zhang, Long Jin, Mengshu Sun, Ling Zhong, Zhiqiang Liu, Juan Li, Lei Liang, Chong Long, Chao Deng, and Junlan Feng. Self-correction distillation for structured data question answering.arXiv preprint arXiv:2511.07998, 2025
arXiv 2025
-
[30]
Robust text-to-SQL generation with execution-guided decoding
Chenglong Wang, Kedar Tatwawadi, Marc Brockschmidt, Po-Sen Huang, Yi Mao, Oleksandr Polozov, and Rishabh Singh. Robust text-to-SQL generation with execution-guided decoding. arXiv preprint arXiv:1807.03100, 2018
Pith/arXiv arXiv 2018
-
[31]
Teaching large language models to self-debug.arXiv preprint arXiv:2304.05128, 2023
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug.arXiv preprint arXiv:2304.05128, 2023
Pith/arXiv arXiv 2023
-
[32]
Next-generation database interfaces: A survey of LLM-based text-to-SQL.IEEE Transactions on Knowledge and Data Engineering, 2025
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, and Xiao Huang. Next-generation database interfaces: A survey of LLM-based text-to-SQL.IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[33]
Liang Shi, Zhengju Tang, Nan Zhang, Xiaotong Zhang, and Zhi Yang. A survey on employing large language models for text-to-SQL tasks.ACM Computing Surveys, 58(2):1–37, 2026. doi: 10.1145/3737873
-
[34]
Aditi Singh, Akash Shetty, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. A survey of large language model-based generative AI for text-to-SQL: Benchmarks, applications, use cases, and challenges.arXiv preprint arXiv:2412.05208, 2025
arXiv 2025
-
[35]
KnowledgeGraphQueryEngine: Knowledge graph integration for LlamaIndex
LlamaIndex. KnowledgeGraphQueryEngine: Knowledge graph integration for LlamaIndex. Python package, 2024.https://docs.llamaindex.ai/
2024
-
[36]
Maciej Besta, Łukasz Jarmocik, Orest Hrycyna, Shachar Klaiman, Konrad Mączka, Robert Gerstenberger, Jürgen Müller, Piotr Nyczyk, Hubert Niewiadomski, and Torsten Hoefler. GraphSeek: Next-generation graph analytics with LLMs.arXiv preprint arXiv:2602.11052, 2026. A Corrector prompt examples The following listings show the user prompt each corrector sends t...
arXiv 2026
-
[37]
did_you_mean has one strong match -- substitute and return
-
[38]
did_you_mean is empty but available_in_scope is short -- pick the most semantically plausible option
-
[39]
category
available_in_scope_truncated is True -- did_you_mean is the only hint; if empty, abort --- # Refinement intent (attempt 1) ## Failing query MATCH (n:Moive) RETURN n.title ## Failure category: schema ## Error payload (JSON) {"category":"schema", "unknown_reference":"Moive", ...} --- # Schema: label Movie - movieId: STRING (required) - title: STRING (requir...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.