Enhancing MedSAM with a Lightweight Box Predictor for Medical Image Segmentation
Pith reviewed 2026-06-28 07:14 UTC · model grok-4.3
The pith
A lightweight box predictor integrated into MedSAM estimates bounding boxes from single clicks to improve medical image segmentation accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Box Predictor module, trained independently on embedding features from single clicks, generates approximate bounding boxes that provide spatial guidance to MedSAM, reducing ambiguity of point prompts and yielding improved segmentation performance across diverse medical imaging modalities and anatomical structures.
What carries the argument
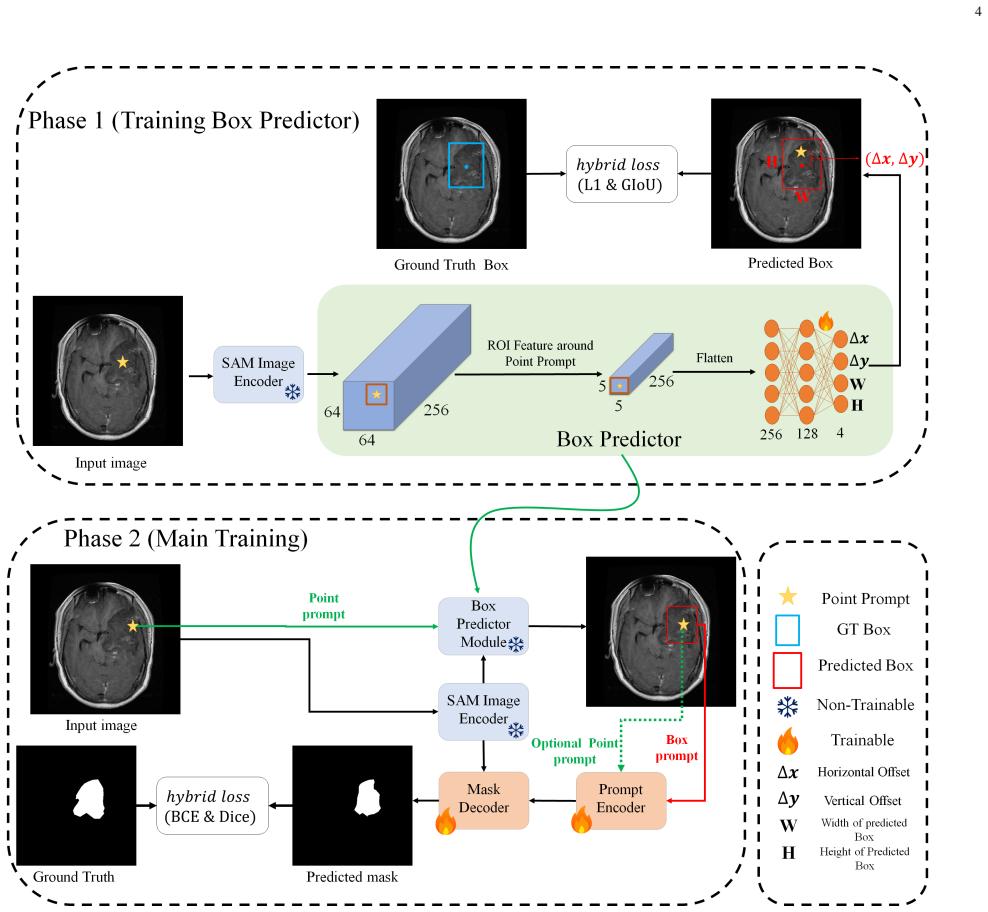
The lightweight Box Predictor that takes localized image embedding features from a single click and outputs an approximate bounding box for use as prompt in MedSAM.
If this is right
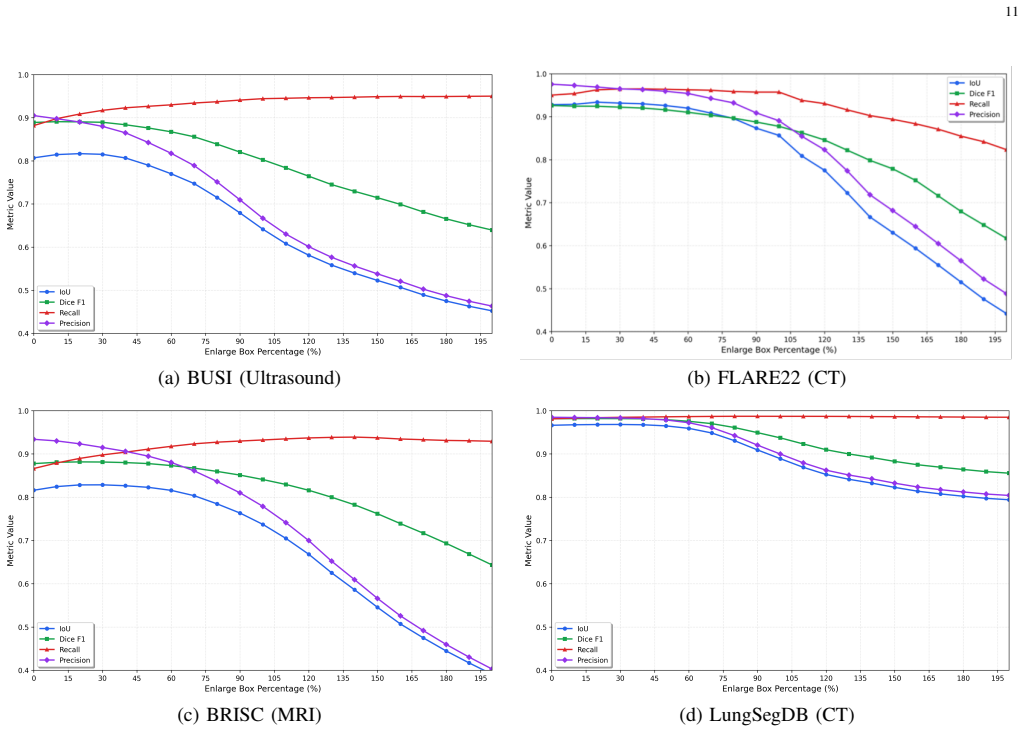
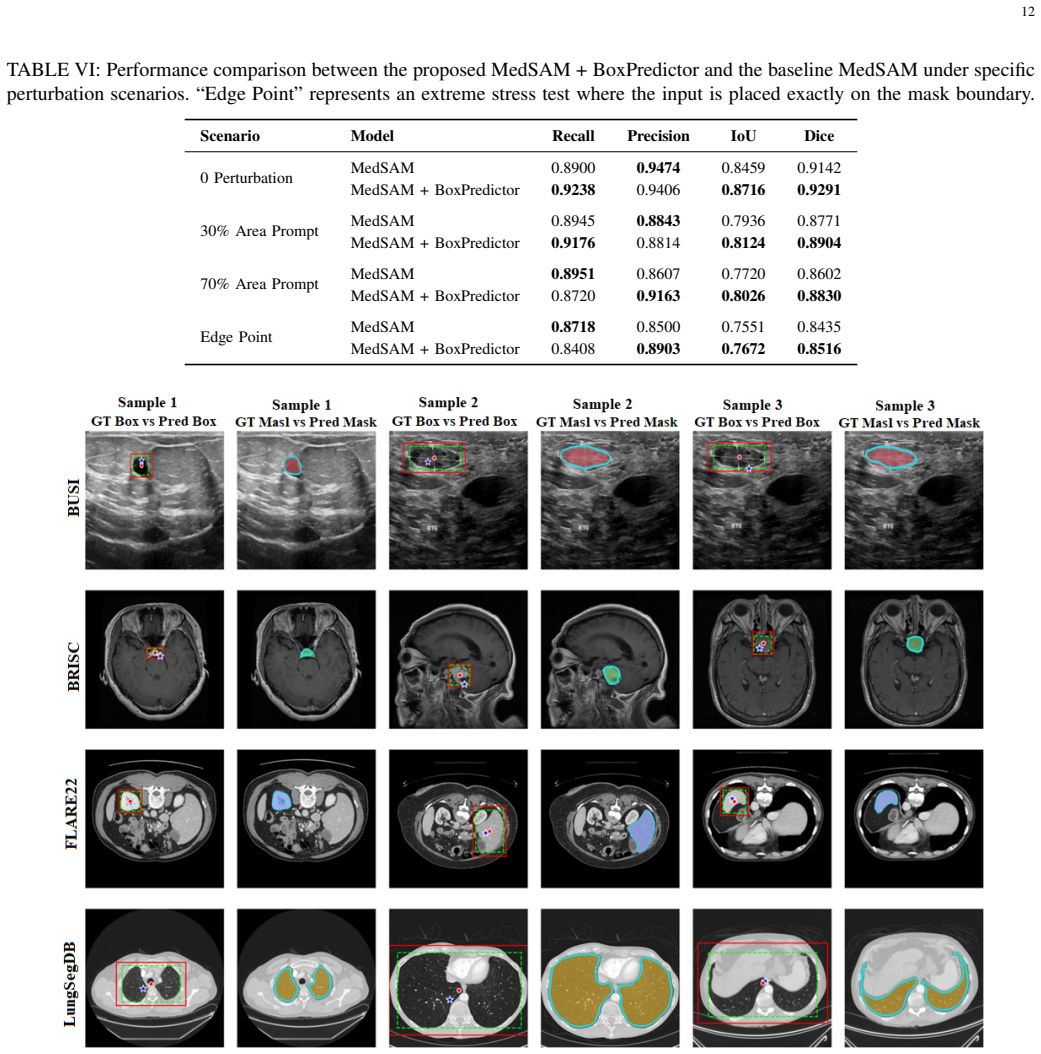
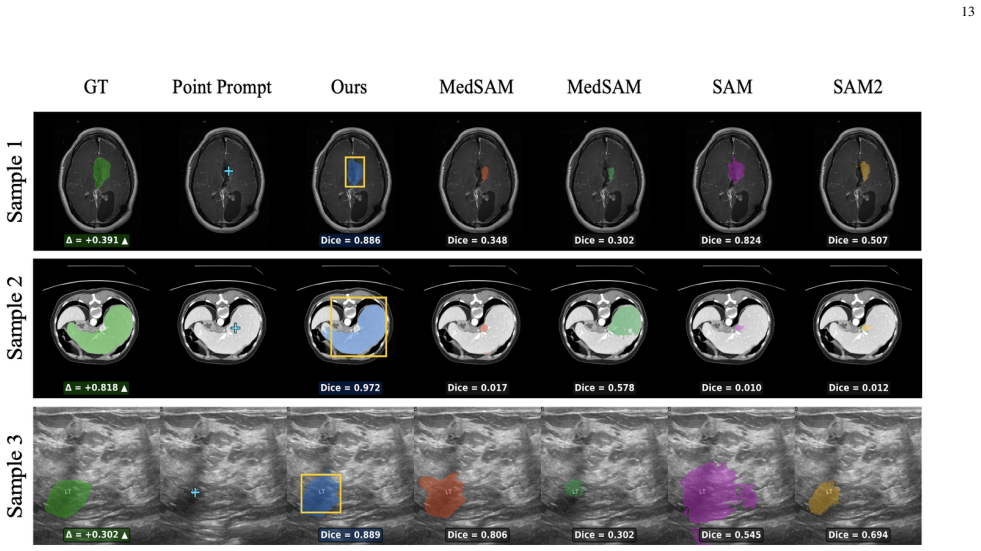
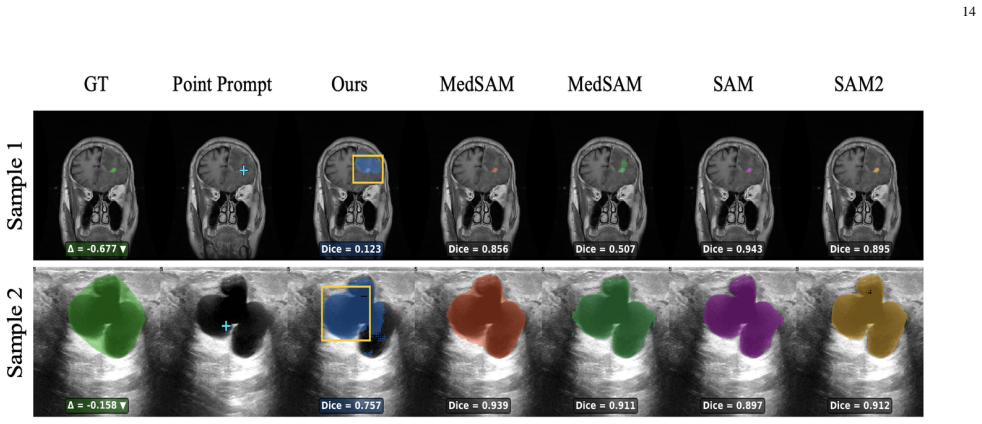
- Segmentation Dice scores reach 0.89 on BUSI, 0.93 on FLARE22, 0.88 on BRISC, and 0.98 on LungSegDB.
- Only 1.6M additional parameters are introduced with negligible inference overhead.
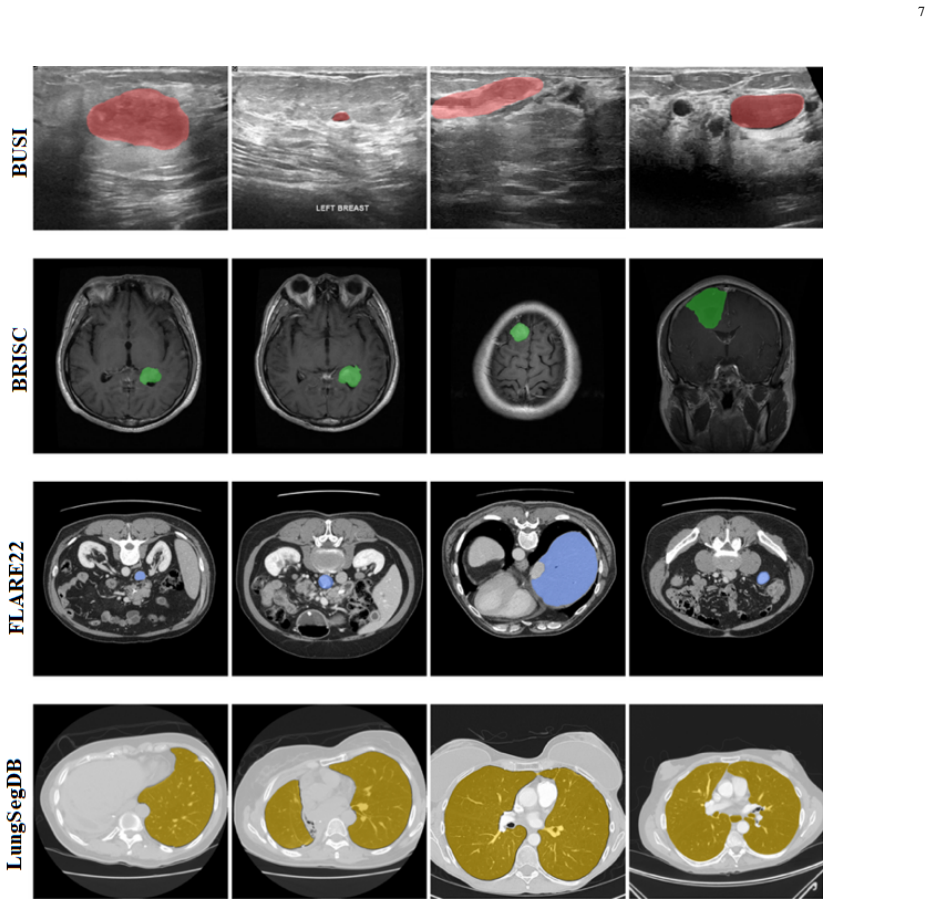
- The method generalizes across CT, MRI, and ultrasound modalities on four datasets.
- Two-stage training allows the Box Predictor to be trained independently before integration with frozen or fine-tuned MedSAM.
Where Pith is reading between the lines
- Similar lightweight predictors could be developed for other prompt types like scribbles in foundation models for segmentation.
- The approach might reduce the need for multiple clicks in interactive medical annotation workflows.
- Testing on more varied clinical datasets could reveal if performance holds for rare pathologies.
Load-bearing premise
Training the Box Predictor independently on localized embedding features from single clicks produces bounding boxes that reliably reduce prompt ambiguity in MedSAM without introducing new failure modes on irregular structures.
What would settle it
Observing that on datasets with highly irregular structures the integrated model produces lower Dice scores than MedSAM using only point prompts would falsify the central claim.
Figures
read the original abstract
Semantic segmentation in medical imaging is a critical yet challenging task due to data scarcity and high variability across modalities. While foundation models like the Segment Anything Model (SAM) show promise, they often struggle with medical images without specific adaptation. Moreover, point prompts, despite being the most natural form of user interaction, provide insufficient spatial context for reliable segmentation, particularly when target structures are irregular or poorly contrasted. In this paper, we propose an enhanced segmentation framework that integrates a lightweight Box Predictor module into the MedSAM architecture. The Box Predictor estimates an approximate bounding box from a single user click using localized image embedding features, providing spatial guidance that reduces the ambiguity of point prompts, while introducing only 1.6M additional parameters and negligible inference overhead. We introduce a two-stage training pipeline where the Box Predictor is trained independently before being integrated into MedSAM. To validate the generalization capability of our method, we conduct extensive evaluations on four diverse datasets (FLARE22, BRISC, BUSI, LungSegDB) spanning distinct imaging modalities, including CT, MRI, and Ultrasound. Our method improves segmentation accuracy and robustness across varied anatomical structures and imaging domains, achieving Dice scores of 0.89 (BUSI), 0.93 (FLARE22), 0.88 (BRISC), and 0.98 (LungSegDB). Code is available at https://github.com/Amirhosseinmovahedi/MedSAM-BoxPredictor
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes enhancing MedSAM by integrating a lightweight (1.6M-parameter) Box Predictor module that estimates an approximate bounding box from a single user click on localized image embeddings. This is intended to reduce point-prompt ambiguity for irregular or low-contrast structures. The method uses a two-stage training pipeline (independent Box Predictor training followed by integration into MedSAM) and reports Dice scores of 0.89 (BUSI), 0.93 (FLARE22), 0.88 (BRISC), and 0.98 (LungSegDB) on four datasets spanning CT, MRI, and ultrasound, claiming improved accuracy and robustness with negligible inference overhead.
Significance. If the performance gains hold under proper controls, the work would demonstrate a practical, low-parameter way to convert point prompts into box prompts for medical foundation models, addressing a known limitation of SAM-family models on variable medical data. The two-stage design and public code release would also support reproducibility.
major comments (3)
- [Abstract] Abstract: The central performance claim (Dice scores of 0.89–0.98) is presented without any baseline comparisons (e.g., original MedSAM with point prompts only, or SAM with box prompts), error bars, statistical tests, or dataset split details. This prevents assessment of whether the reported gains are attributable to the Box Predictor or to other factors.
- [Abstract] Abstract (two-stage pipeline description): The claim that the independently trained Box Predictor reliably reduces prompt ambiguity when integrated into MedSAM lacks supporting evidence such as box-IoU metrics, ablation on joint vs. separate training, or failure-case analysis on irregular structures (e.g., BUSI/BRISC). Without this, the integration step remains an unvalidated assumption.
- [Abstract] Abstract (evaluation): No ablation is described that isolates the contribution of the Box Predictor (e.g., MedSAM with oracle boxes vs. predicted boxes), leaving open whether the Dice improvements reflect genuine ambiguity reduction or dataset-specific effects.
minor comments (1)
- [Abstract] Abstract: The phrase 'extensive evaluations' is used but the provided results consist only of four aggregate Dice numbers; more granular metrics (e.g., per-structure or per-modality breakdowns) would strengthen the generalization claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the abstract to better contextualize the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim (Dice scores of 0.89–0.98) is presented without any baseline comparisons (e.g., original MedSAM with point prompts only, or SAM with box prompts), error bars, statistical tests, or dataset split details. This prevents assessment of whether the reported gains are attributable to the Box Predictor or to other factors.
Authors: The full manuscript contains baseline comparisons against MedSAM with point prompts and specifies the dataset splits used. We will revise the abstract to include these comparisons and error bars. revision: yes
-
Referee: [Abstract] Abstract (two-stage pipeline description): The claim that the independently trained Box Predictor reliably reduces prompt ambiguity when integrated into MedSAM lacks supporting evidence such as box-IoU metrics, ablation on joint vs. separate training, or failure-case analysis on irregular structures (e.g., BUSI/BRISC). Without this, the integration step remains an unvalidated assumption.
Authors: The methods and results sections provide box-IoU metrics for the Box Predictor, ablations on joint versus separate training, and discussion of performance on irregular structures. We will update the abstract to reference these supporting results. revision: yes
-
Referee: [Abstract] Abstract (evaluation): No ablation is described that isolates the contribution of the Box Predictor (e.g., MedSAM with oracle boxes vs. predicted boxes), leaving open whether the Dice improvements reflect genuine ambiguity reduction or dataset-specific effects.
Authors: The experimental evaluation in the full manuscript includes ablations that isolate the Box Predictor by comparing against oracle boxes. We will revise the abstract to summarize this ablation. revision: yes
Circularity Check
No circularity: empirical results on external datasets with no derivations or self-referential reductions
full rationale
The paper describes an empirical two-stage training pipeline for a lightweight Box Predictor integrated into MedSAM, evaluated via Dice scores on four external datasets (BUSI, FLARE22, BRISC, LungSegDB). No equations, mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. Performance claims are presented as direct experimental outcomes rather than reductions to inputs by construction. The method is self-contained against external benchmarks with no visible circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- Box Predictor parameters =
1.6M
axioms (1)
- domain assumption Point prompts alone provide insufficient spatial context for reliable segmentation of irregular or poorly contrasted medical structures.
invented entities (1)
-
Lightweight Box Predictor module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Icad- segnet: Efficient and accurate semi-automatic segmentation of intracra- nial atherosclerotic plaques based on low-rank adaptation,
J. Yuan, L. Mei, Q. Wang, Y . Cao, Z. Li, and B. Liu, “Icad- segnet: Efficient and accurate semi-automatic segmentation of intracra- nial atherosclerotic plaques based on low-rank adaptation,”Biomedical Signal Processing and Control, vol. 112, p. 108936, 2026
2026
-
[2]
Adapting sam with a triple-prompt strategy for one-shot semantic segmentation,
A. Fateh, M. R. Mohammadi, and M. R. Jahed-Motlagh, “Adapting sam with a triple-prompt strategy for one-shot semantic segmentation,” Neurocomputing, p. 133301, 2026
2026
-
[3]
Msdnet: Multi- scale decoder for few-shot semantic segmentation via transformer-guided prototyping,
A. Fateh, M. R. Mohammadi, and M. R. J. Motlagh, “Msdnet: Multi- scale decoder for few-shot semantic segmentation via transformer-guided prototyping,”Image and Vision Computing, p. 105672, 2025
2025
-
[4]
Cdsg-sam: A cross-domain self-generating prompt few-shot brain tumor segmentation pipeline based on sam,
Y . Yang, X. Fang, X. Li, Y . Han, and Z. Yu, “Cdsg-sam: A cross-domain self-generating prompt few-shot brain tumor segmentation pipeline based on sam,”Biomedical Signal Processing and Control, vol. 100, p. 106936, 2025
2025
-
[5]
Sam-myonet: A fine-grained perception myocardial ultrasound segmentation network based on segment anything model with prior knowledge driven,
Y . Ying, X. Fang, Y . Zhao, X. Zhao, Y . Zhou, G. Du, Y . Zhan, T. Gao, A. Li, D. Sunet al., “Sam-myonet: A fine-grained perception myocardial ultrasound segmentation network based on segment anything model with prior knowledge driven,”Biomedical Signal Processing and Control, vol. 110, p. 108117, 2025
2025
-
[6]
Advances in deep learning for semantic segmentation of low-contrast images: A systematic review of methods, challenges, and future directions,
C. Urrea and M. V ´elez, “Advances in deep learning for semantic segmentation of low-contrast images: A systematic review of methods, challenges, and future directions,”Sensors, vol. 25, no. 7, p. 2043, 2025
2043
-
[7]
Sit-sam: A semantic-integration transformer that adapts the segment anything model to zero-shot medical image semantic segmentation,
W. Shi, J. He, and Y . Shen, “Sit-sam: A semantic-integration transformer that adapts the segment anything model to zero-shot medical image semantic segmentation,”Biomedical Signal Processing and Control, vol. 110, p. 108086, 2025
2025
-
[8]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inInternational Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
2015
-
[9]
Encoder- decoder with atrous separable convolution for semantic image segmen- tation,
L.-C. Chen, Y . Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder- decoder with atrous separable convolution for semantic image segmen- tation,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 801–818
2018
-
[10]
Labelling instructions matter in biomedical image analysis,
T. R ¨adsch, A. Reinke, V . Weru, M. D. Tizabi, N. Schreck, A. E. Kavur, B. Pekdemir, T. Roß, A. Kopp-Schneider, and L. Maier-Hein, “Labelling instructions matter in biomedical image analysis,”Nature Machine Intelligence, vol. 5, no. 3, pp. 273–283, 2023
2023
-
[11]
Deep learning with noisy labels: Exploring techniques and remedies in medical image analysis,
D. Karimi, H. Dou, S. K. Warfield, and A. Gholipour, “Deep learning with noisy labels: Exploring techniques and remedies in medical image analysis,”Medical image analysis, vol. 65, p. 101759, 2020
2020
-
[12]
Comparison of fine-tuning strategies for transfer learning in medical image classification,
A. Davila, J. Colan, and Y . Hasegawa, “Comparison of fine-tuning strategies for transfer learning in medical image classification,”Image and Vision Computing, vol. 146, p. 105012, 2024
2024
-
[13]
Navigating data scarcity using foundation models: A benchmark of few-shot and zero-shot learning approaches in medical imaging,
S. Woerner and C. F. Baumgartner, “Navigating data scarcity using foundation models: A benchmark of few-shot and zero-shot learning approaches in medical imaging,” inInternational Workshop on Founda- tion Models for General Medical AI. Springer, 2024, pp. 30–39
2024
-
[14]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[15]
Ma-sam: Modality-agnostic sam adaptation for 3d medical image segmentation,
C. Chen, J. Miao, D. Wu, A. Zhong, Z. Yan, S. Kim, J. Hu, Z. Liu, L. Sun, X. Liet al., “Ma-sam: Modality-agnostic sam adaptation for 3d medical image segmentation,”Medical Image Analysis, vol. 98, p. 103310, 2024
2024
-
[16]
Segment anything model for medical image segmentation: Current applications and future directions,
Y . Zhang, Z. Shen, and R. Jiao, “Segment anything model for medical image segmentation: Current applications and future directions,”Com- puters in Biology and Medicine, vol. 171, p. 108238, 2024
2024
-
[17]
Segment anything model for medical images?
Y . Huang, X. Yang, L. Liu, H. Zhou, A. Chang, X. Zhou, R. Chen, J. Yu, J. Chen, C. Chenet al., “Segment anything model for medical images?”Medical Image Analysis, vol. 92, p. 103061, 2024
2024
-
[18]
Towards segment anything model (sam) for med- ical image segmentation: A survey,
Y . Zhang and R. Jiao, “Towards segment anything model (sam) for med- ical image segmentation: A survey,”arXiv preprint arXiv:2305.03678, 2023
-
[19]
Segment anything in medical images,
J. Ma, Y . He, F. Li, L. Han, C. You, and B. Wang, “Segment anything in medical images,”Nature Communications, vol. 15, no. 1, p. 654, 2024
2024
-
[20]
Fully automated sam for single-source domain generalization in medical image segmentation,
H. Zhuo, L. Ma, H. Zhao, S. Zhou, D. Sun, and Y . Fu, “Fully automated sam for single-source domain generalization in medical image segmentation,”arXiv preprint arXiv:2507.17281, 2025
-
[21]
Eviprompt: A training-free evidential prompt generation method for adapting segment anything model in medical images,
Y . Xu, J. Tang, A. Men, and Q. Chen, “Eviprompt: A training-free evidential prompt generation method for adapting segment anything model in medical images,”IEEE Transactions on Image Processing, 2024
2024
-
[22]
Sam 2: Segment anything in images and videos,
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll´ar, and C. Feichtenhofer, “Sam 2: Segment anything in images and videos,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[23]
Medical sam 2: Segment medical images as video via segment anything model 2,
J. Zhu, A. Hamdi, Y . Qi, Y . Jin, and J. Wu, “Medical sam 2: Segment medical images as video via segment anything model 2,”arXiv preprint arXiv:2408.00874, 2024
-
[24]
Sam2-unet: Segment anything 2 makes strong encoder for natural and medical image segmentation,
X. Xiong, Z. Wu, S. Tan, W. Li, F. Tang, Y . Chen, S. Li, J. Ma, and G. Li, “Sam2-unet: Segment anything 2 makes strong encoder for natural and medical image segmentation,”arXiv preprint arXiv:2408.08870, 2024
-
[25]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, J. Lei, T. Ma, B. Guo, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. R¨adle, T. Afouras, E. Mavroudi, K. Xu, T.-H. Wu, Y . Zhou, L. Momeni, R. Hazra, S. Ding, S. Vaze, F. Porcher, F. Li, S. Li, A. Kamath, H. K. Cheng, P. Doll ´ar, N. Ravi, K. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Medicosam: Towards foun- dation models for medical image segmentation,
A. Archit, L. Freckmann, and C. Pape, “Medicosam: Towards foun- dation models for medical image segmentation,”arXiv preprint arXiv:2501.11734, 2025
-
[27]
Pp- sam: Perturbed prompts for robust adaption of segment anything model for polyp segmentation,
M. M. Rahman, M. Munir, D. Jha, U. Bagci, and R. Marculescu, “Pp- sam: Perturbed prompts for robust adaption of segment anything model for polyp segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4989–4995
2024
-
[28]
Masksam: Auto-prompt sam with mask classification for volumetric medical image segmentation,
B. Xie, H. Tang, B. Duan, D. Cai, Y . Yan, and G. Agam, “Masksam: Auto-prompt sam with mask classification for volumetric medical image segmentation,” inProceedings of the IEEE/CVF International Confer- ence on Computer Vision, 2025, pp. 24 423–24 433
2025
-
[29]
Learning to prompt segment anything models,
J. Huang, K. Jiang, J. Zhang, H. Qiu, L. Lu, S. Lu, and E. Xing, “Learning to prompt segment anything models,”arXiv preprint arXiv:2401.04651, 2024
-
[30]
Robust box prompt based sam for medical image segmentation,
Y . Huang, X. Yang, H. Zhou, Y . Cao, H. Dou, F. Dong, and D. Ni, “Robust box prompt based sam for medical image segmentation,” in International Workshop on Machine Learning in Medical Imaging. Springer, 2024, pp. 1–11. 16
2024
-
[31]
Pa-sam: Prompt adapter sam for high-quality image segmentation,
Z. Xie, B. Guan, W. Jiang, M. Yi, Y . Ding, H. Lu, and L. Zhang, “Pa-sam: Prompt adapter sam for high-quality image segmentation,” in 2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2024, pp. 1–6
2024
-
[32]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[33]
Medclip: Contrastive learning from unpaired medical images and text,
Z. Wang, Z. Wu, D. Agarwal, and J. Sun, “Medclip: Contrastive learning from unpaired medical images and text,” inProceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing, vol. 2022, 2022, p. 3876
2022
-
[34]
Enhancing sam with efficient prompting and preference optimiza- tion for semi-supervised medical image segmentation,
A. Konwer, Z. Yang, E. Bas, C. Xiao, P. Prasanna, P. Bhatia, and T. Kass- Hout, “Enhancing sam with efficient prompting and preference optimiza- tion for semi-supervised medical image segmentation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 20 990–21 000
2025
-
[35]
Towards universal text-driven ct image segmentation,
Y . Li, Y . Lai, M. Thor, D. Marshall, Z. Buchwald, D. S. Yu, and X. Yang, “Towards universal text-driven ct image segmentation,”arXiv preprint arXiv:2503.06030, 2025
-
[36]
Generalized intersection over union: A metric and a loss for bounding box regression,
H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese, “Generalized intersection over union: A metric and a loss for bounding box regression,” inProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, 2019, pp. 658–666
2019
-
[37]
Unleashing the strengths of unlabelled data in deep learning-assisted pan-cancer abdominal organ quantification: the flare22 challenge,
J. Ma, Y . Zhang, S. Gu, C. Ge, S. Mae, A. Young, C. Zhu, X. Yang, K. Meng, Z. Huanget al., “Unleashing the strengths of unlabelled data in deep learning-assisted pan-cancer abdominal organ quantification: the flare22 challenge,”The Lancet Digital Health, vol. 6, no. 11, pp. e815– e826, 2024
2024
-
[38]
Dataset of breast ultrasound images,
W. Al-Dhabyani, M. Gomaa, H. Khaled, and A. Fahmy, “Dataset of breast ultrasound images,”Data in brief, vol. 28, p. 104863, 2020
2020
-
[39]
Brisc: Annotated dataset for brain tumor segmentation and classification,
A. Fateh, Y . Rezvani, S. Moayedi, S. Rezvani, F. Fateh, M. Fateh, and V . Abolghasemi, “Brisc: Annotated dataset for brain tumor segmentation and classification,”Scientific Data, 2026
2026
-
[40]
Fusionlungnet: Multi- scale fusion convolution with refinement network for lung ct image segmentation,
S. Rezvani, M. Fateh, Y . Jalali, and A. Fateh, “Fusionlungnet: Multi- scale fusion convolution with refinement network for lung ct image segmentation,”Biomedical Signal Processing and Control, vol. 107, p. 107858, 2025
2025
-
[41]
Is sam 2 better than sam in medical image segmentation?
S. Sengupta, S. Chakrabarty, and R. Soni, “Is sam 2 better than sam in medical image segmentation?”arXiv preprint arXiv:2408.04212, 2024
-
[42]
Segment anything in medical images and videos: Benchmark and deployment,
J. Ma, S. Kim, F. Li, M. Baharoon, R. Asakereh, H. Lyu, and B. Wang, “Segment anything in medical images and videos: Benchmark and deployment,”arXiv preprint arXiv:2408.03322, 2024
-
[43]
Segment anything model 2: An application to 2d and 3d medical images,
H. Dong, H. Gu, Y . Chen, J. Yang, Y . Chen, and M. A. Mazurowski, “Segment anything model 2: An application to 2d and 3d medical images,”arXiv preprint arXiv:2408.00756, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.