PersonaTree: Structured Lifecycle Memory for Person Understanding in LLM Agents
Pith reviewed 2026-06-28 06:13 UTC · model grok-4.3
The pith
PersonaTree builds a three-level tree of evidence-supported person claims to make long-term understanding explicit in LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
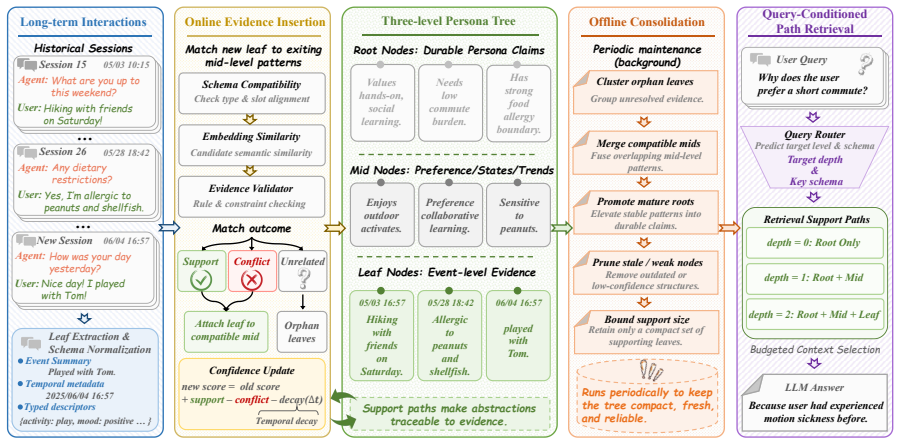
PersonaTree realizes schema formation as a three-level persona tree with explicit support paths from evidence to claims, maintained by conservative writing, confidence-guided consolidation, and query-conditioned path retrieval that returns only the evidence depth required by each query.
What carries the argument
A three-level persona tree with explicit support paths from evidence to claims, updated by conservative writing, confidence-guided consolidation, and query-conditioned path retrieval.
If this is right
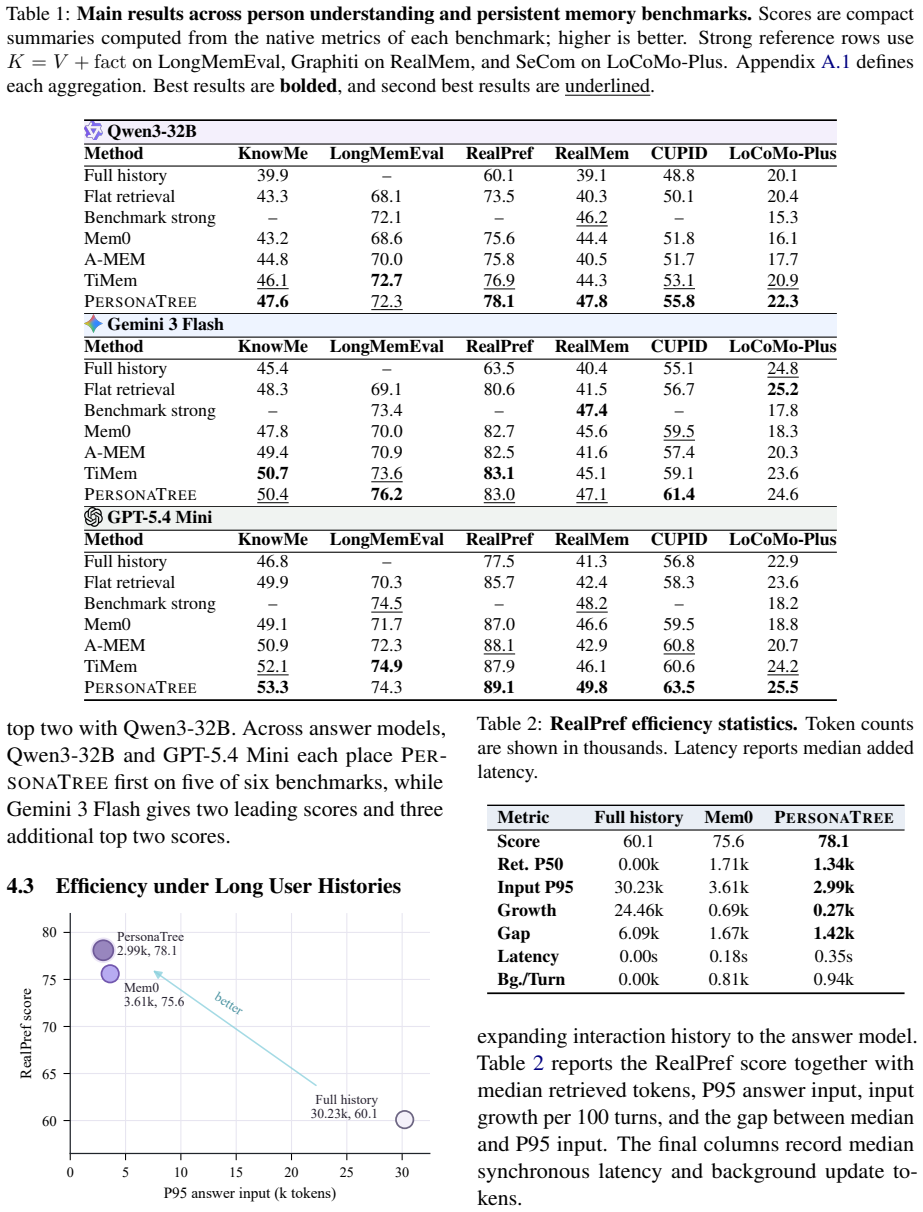
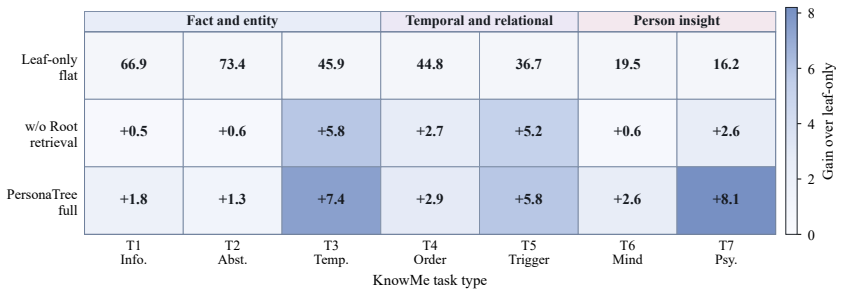
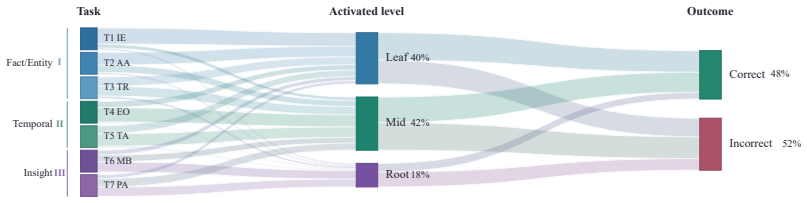
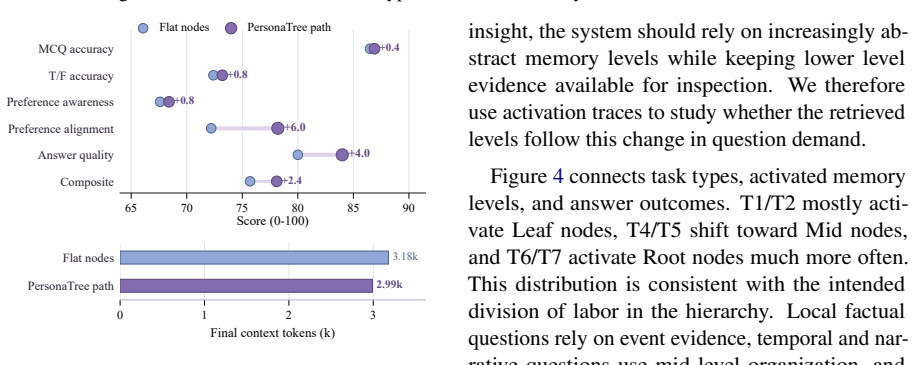
- The hierarchy component improves performance on abstract person understanding tasks such as KnowMe.
- Support-path retrieval improves alignment on preference tasks such as RealPref at comparable context length.
- The overall method reaches first place in twelve of eighteen compact scores across six benchmarks.
- Top-two placement holds in sixteen of the eighteen evaluated settings.
Where Pith is reading between the lines
- The same tree-plus-path design could be tested on non-person domains that also require abstraction from evidence streams, such as task schema learning.
- Conservative writing rules may incidentally limit hallucinated claims in long-horizon agent memory.
- Explicit support paths open the possibility of user-facing explanations that cite the exact interaction evidence behind a persona claim.
Load-bearing premise
Conservative writing, confidence-guided consolidation, and query-conditioned path retrieval on a three-level tree will produce reusable person-level claims that generalize beyond the tested benchmarks and answer backbones.
What would settle it
PersonaTree failing to rank first or second on a new person-understanding benchmark or with a fourth answer backbone would falsify the claim of broad superiority.
Figures

read the original abstract
Persistent LLM agents require memory representations that make the formation of person understanding explicit across long term interaction. Existing agent memory methods emphasize information retention and retrieval, yet give limited account of how accumulated interaction evidence is abstracted into person understanding. We view this process as schema formation, where situated evidence is abstracted into reusable patterns and stable person level claims. We introduce PersonaTree, a structured lifecycle memory framework that realizes this view as a three level persona tree with explicit support paths from evidence to claims. PersonaTree maintains the tree through conservative writing, confidence guided consolidation, and query conditioned path retrieval, returning only the evidence depth required by each query. Across six person understanding and persistent memory benchmarks with three answer backbones, PersonaTree ranks first in 12 of 18 compact scores and reaches the top two in 16 settings. Ablations show that hierarchy improves abstract person understanding on KnowMe, while support path retrieval improves RealPref alignment under a comparable context budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PersonaTree, a three-level persona tree framework for structured lifecycle memory in LLM agents that treats person understanding as schema formation. It maintains the tree via conservative writing, confidence-guided consolidation, and query-conditioned path retrieval to return only the required evidence depth. Evaluated across six person understanding and persistent memory benchmarks with three answer backbones, PersonaTree ranks first in 12 of 18 compact scores and top-two in 16 settings; ablations attribute gains on KnowMe to hierarchy and on RealPref to support-path retrieval.
Significance. If the empirical rankings hold under the stated mechanisms, the work provides an explicit, hierarchical alternative to retention-focused agent memory, potentially enabling more stable and reusable person-level claims over long interactions. The explicit support paths and lifecycle operations are a concrete realization of schema formation that could be adopted in persistent agent designs.
major comments (2)
- [Abstract] Abstract: the central claim that the three operations produce reusable person-level claims that generalize is load-bearing for the schema-formation framing, yet the evaluation is confined to the six listed benchmarks with no reported tests on unseen interaction distributions, longer horizons, or additional backbones; this leaves the performance numbers (first in 12/18, top-2 in 16/18) without direct support for the generalization asserted in the introduction.
- [Evaluation section] Evaluation section (ablations paragraph): the statements that hierarchy improves abstract understanding on KnowMe and support-path retrieval improves RealPref alignment are presented without accompanying statistical tests, run-to-run variance, or controls for total token budget, making it impossible to determine whether the reported gains are robust or merely artifacts of the specific benchmark splits.
minor comments (2)
- The three operations (conservative writing, confidence-guided consolidation, query-conditioned path retrieval) are named but not given pseudocode or precise algorithmic descriptions, which would aid reproducibility.
- Table or figure captions for the 18 compact scores should explicitly list the six benchmarks and three backbones to allow readers to map the rankings without cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below with clarifications and note planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the three operations produce reusable person-level claims that generalize is load-bearing for the schema-formation framing, yet the evaluation is confined to the six listed benchmarks with no reported tests on unseen interaction distributions, longer horizons, or additional backbones; this leaves the performance numbers (first in 12/18, top-2 in 16/18) without direct support for the generalization asserted in the introduction.
Authors: The six benchmarks cover a range of person-understanding and persistent-memory tasks, including abstract reasoning (KnowMe) and preference alignment (RealPref), which we selected to probe the reusability of claims produced by the tree operations. We acknowledge, however, that the manuscript reports no experiments on explicitly held-out interaction distributions, longer horizons, or further backbones. We will revise the abstract and introduction to qualify the generalization language more precisely and align it with the evaluated scope. revision: partial
-
Referee: [Evaluation section] Evaluation section (ablations paragraph): the statements that hierarchy improves abstract understanding on KnowMe and support-path retrieval improves RealPref alignment are presented without accompanying statistical tests, run-to-run variance, or controls for total token budget, making it impossible to determine whether the reported gains are robust or merely artifacts of the specific benchmark splits.
Authors: We agree that statistical tests, run-to-run variance, and explicit token-budget controls are needed to substantiate the ablation claims. In the revision we will rerun the ablations with multiple seeds, report standard deviations, perform significance tests, and add token-usage comparisons to confirm that observed gains are not artifacts of benchmark splits or context length. revision: yes
Circularity Check
No circularity; empirical rankings on external benchmarks
full rationale
The paper introduces PersonaTree as a three-level tree memory framework with operations (conservative writing, confidence-guided consolidation, query-conditioned path retrieval) and evaluates it empirically across six benchmarks and three backbones, reporting rankings (first in 12/18 scores). No equations, derivations, fitted parameters, or self-citation chains appear in the provided text. Central claims are performance results against external benchmarks rather than quantities derived by construction from the paper's own inputs. This is self-contained empirical work with no load-bearing reductions to self-definition or prior author results.
Axiom & Free-Parameter Ledger
invented entities (1)
-
PersonaTree
no independent evidence
Reference graph
Works this paper leans on
-
[1]
, author=
Remembering: a study in experimental and social psychology. , author=. 1932 , publisher=
1932
-
[2]
Theoretical issues in reading comprehension , year=
Schemata: The building blocks of cognition , author=. Theoretical issues in reading comprehension , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
A-mem: Agentic memory for llm agents , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
, author=
MemGPT: towards LLMs as operating systems. , author=. 2023 , publisher=
2023
-
[17]
Proceedings of the AAAI conference on artificial intelligence , volume=
Memorybank: Enhancing large language models with long-term memory , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[18]
International Conference on Learning Representations , volume=
From isolated conversations to hierarchical schemas: Dynamic tree memory representation for llms , author=. International Conference on Learning Representations , volume=
-
[20]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[23]
Science China Information Sciences , volume=
The rise and potential of large language model based agents: A survey , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[25]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Lamp: When large language models meet personalization , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[26]
Findings of the association for computational linguistics: NAACL 2024 , pages=
PersonaLLM: Investigating the ability of large language models to express personality traits , author=. Findings of the association for computational linguistics: NAACL 2024 , pages=
2024
-
[27]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[28]
Transactions on Machine Learning Research , year=
Cognitive architectures for language agents , author=. Transactions on Machine Learning Research , year=
-
[29]
International conference on machine learning , pages=
Retrieval augmented language model pre-training , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[30]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[31]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[32]
Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
Leveraging passage retrieval with generative models for open domain question answering , author=. Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
-
[33]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[34]
International Conference on Learning Representations , volume=
Raptor: Recursive abstractive processing for tree-organized retrieval , author=. International Conference on Learning Representations , volume=
-
[36]
Advances in neural information processing systems , volume=
Hipporag: Neurobiologically inspired long-term memory for large language models , author=. Advances in neural information processing systems , volume=
-
[37]
International conference on learning representations , volume=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. International conference on learning representations , volume=
-
[38]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Evaluating very long-term conversational memory of llm agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[39]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Membench: Towards more comprehensive evaluation on the memory of llm-based agents , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[41]
International Conference on Learning Representations , volume=
MetaGPT: Meta programming for a multi-agent collaborative framework , author=. International Conference on Learning Representations , volume=
-
[42]
First conference on language modeling , year=
Autogen: Enabling next-gen LLM applications via multi-agent conversations , author=. First conference on language modeling , year=
-
[43]
International conference on machine learning , pages=
Improving language models by retrieving from trillions of tokens , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[44]
Journal of Machine Learning Research , volume=
Atlas: Few-shot learning with retrieval augmented language models , author=. Journal of Machine Learning Research , volume=
-
[45]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Precise zero-shot dense retrieval without relevance labels , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Active retrieval augmented generation , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[47]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[48]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avi Sil, and Hannaneh Hajishirzi. 2024. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In International conference on learning representations, volume 2024, pages 9112--9141
2024
-
[49]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, and 1 others. 2024. Longbench: A bilingual, multitask benchmark for long context understanding. In Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119--3137
2024
-
[50]
FC Bartlett. 1932. Remembering: a study in experimental and social psychology. Macmillan
1932
-
[51]
Haonan Bian, Zhiyuan Yao, Sen Hu, Zishan Xu, Shaolei Zhang, Yifu Guo, Ziliang Yang, Xueran Han, Huacan Wang, and Ronghao Chen. 2026. Realmem: Benchmarking llms in real-world memory-driven interaction. arXiv preprint arXiv:2601.06966
arXiv 2026
-
[52]
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, and 1 others. 2022. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pages 2206--2240. PMLR
2022
-
[53]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413
Pith/arXiv arXiv 2025
-
[54]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130
Pith/arXiv arXiv 2024
-
[55]
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, and 1 others. 2025. Lightmem: Lightweight and efficient memory-augmented generation. arXiv preprint arXiv:2510.18866
Pith/arXiv arXiv 2025
-
[56]
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. 2023. Precise zero-shot dense retrieval without relevance labels. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1762--1777
2023
-
[57]
Qianyun Guo, Yibo Li, Yue Liu, and Bryan Hooi. 2026. Towards realistic personalization: Evaluating long-horizon preference following in personalized user-llm interactions. arXiv preprint arXiv:2603.04191
arXiv 2026
-
[58]
Bernal J Guti \'e rrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. Hipporag: Neurobiologically inspired long-term memory for large language models. Advances in neural information processing systems, 37:59532--59569
2024
-
[59]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. 2020. Retrieval augmented language model pre-training. In International conference on machine learning, pages 3929--3938. PMLR
2020
-
[60]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, and 1 others. 2024. Metagpt: Meta programming for a multi-agent collaborative framework. In International Conference on Learning Representations, volume 2024, pages 23247--23275
2024
-
[61]
Yuanzhe Hu, Yu Wang, and Julian McAuley. 2025 a . Evaluating memory in llm agents via incremental multi-turn interactions. arXiv preprint arXiv:2507.05257
Pith/arXiv arXiv 2025
-
[62]
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, and 1 others. 2025 b . Memory in the age of ai agents. arXiv preprint arXiv:2512.13564
Pith/arXiv arXiv 2025
-
[63]
Gautier Izacard and Edouard Grave. 2021. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume, pages 874--880
2021
-
[64]
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research, 24(251):1--43
2023
-
[65]
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, and Jad Kabbara. 2024. Personallm: Investigating the ability of large language models to express personality traits. In Findings of the association for computational linguistics: NAACL 2024, pages 3605--3627
2024
-
[66]
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 7969--7992
2023
-
[67]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769--6781
2020
-
[68]
Tae Soo Kim, Yoonjoo Lee, Yoonah Park, Jiho Kim, Young-Ho Kim, and Juho Kim. 2025. Cupid: Evaluating personalized and contextualized alignment of llms from interactions. arXiv preprint arXiv:2508.01674
arXiv 2025
-
[69]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, and 1 others. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459--9474
2020
-
[70]
Kai Li, Xuanqing Yu, Ziyi Ni, Yi Zeng, Yao Xu, Zheqing Zhang, Xin Li, Jitao Sang, Xiaogang Duan, Xuelei Wang, and 1 others. 2026 a . Timem: Temporal-hierarchical memory consolidation for long-horizon conversational agents. arXiv preprint arXiv:2601.02845
Pith/arXiv arXiv 2026
-
[71]
Yifei Li, Weidong Guo, Lingling Zhang, Rongman Xu, Muye Huang, Hui Liu, Lijiao Xu, Yu Xu, and Jun Liu. 2026 b . Locomo-plus: Beyond-factual cognitive memory evaluation framework for llm agents. arXiv preprint arXiv:2602.10715
arXiv 2026
-
[72]
Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, Huayi Lai, Jihao Zhao, Yezhaohui Wang, and 1 others. 2025. Memos: An operating system for memory-augmented generation (mag) in large language models. arXiv preprint arXiv:2505.22101
arXiv 2025
-
[73]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts. Transactions of the association for computational linguistics, 12:157--173
2024
-
[74]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating very long-term conversational memory of llm agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851--13870
2024
-
[75]
Charles Packer, Vivian Fang, Shishir\_G Patil, Kevin Lin, Sarah Wooders, and Joseph\_E Gonzalez. 2023. Memgpt: towards llms as operating systems
2023
-
[76]
Joon Sung Park, Joseph O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1--22
2023
-
[77]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: a temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956
Pith/arXiv arXiv 2025
-
[78]
Alireza Rezazadeh, Zichao Li, Wei Wei, and Yujia Bao. 2025. From isolated conversations to hierarchical schemas: Dynamic tree memory representation for llms. In International Conference on Learning Representations, volume 2025, pages 990--1023
2025
-
[79]
DE RUMELHART. 1980. Schemata: The building blocks of cognition. Theoretical issues in reading comprehension
1980
-
[80]
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2024. Lamp: When large language models meet personalization. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7370--7392
2024
-
[81]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher Manning. 2024. Raptor: Recursive abstractive processing for tree-organized retrieval. In International Conference on Learning Representations, volume 2024, pages 32628--32649
2024
-
[82]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems, 36:8634--8652
2023
-
[83]
Theodore Sumers, Shunyu Yao, Karthik R Narasimhan, and Thomas L Griffiths. 2023. Cognitive architectures for language agents. Transactions on Machine Learning Research
2023
-
[84]
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong. 2025. Membench: Towards more comprehensive evaluation on the memory of llm-based agents. In Findings of the Association for Computational Linguistics: ACL 2025, pages 19336--19352
2025
-
[85]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291
Pith/arXiv arXiv 2023
-
[86]
Tiannan Wang, Meiling Tao, Ruoyu Fang, Huilin Wang, Shuai Wang, Yuchen Eleanor Jiang, and Wangchunshu Zhou. 2024. Ai persona: Towards life-long personalization of llms. arXiv preprint arXiv:2412.13103
arXiv 2024
-
[87]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. 2024 a . Longmemeval: Benchmarking chat assistants on long-term interactive memory. arXiv preprint arXiv:2410.10813
Pith/arXiv arXiv 2024
-
[88]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, and 1 others. 2024 b . Autogen: Enabling next-gen llm applications via multi-agent conversations. In First conference on language modeling
2024
-
[89]
Tingyu Wu, Zhisheng Chen, Ziyan Weng, Shuhe Wang, Chenglong Li, Shuo Zhang, Sen Hu, Silin Wu, Qizhen Lan, Huacan Wang, and 1 others. 2026. Knowme-bench: Benchmarking person understanding for lifelong digital companions. arXiv preprint arXiv:2601.04745
Pith/arXiv arXiv 2026
-
[90]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, and 1 others. 2025. The rise and potential of large language model based agents: A survey. Science China Information Sciences, 68(2):121101
2025
-
[91]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2026. A-mem: Agentic memory for llm agents. Advances in Neural Information Processing Systems, 38:17577--17604
2026
-
[92]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629
Pith/arXiv arXiv 2022
-
[93]
Yanwei Yue, Boci Peng, Xuanbo Fan, Jiaxin Guo, Qiankun Li, and Yan Zhang. 2026. Mem-t: Densifying rewards for long-horizon memory agents. arXiv preprint arXiv:2601.23014
arXiv 2026
-
[94]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Memorybank: Enhancing large language models with long-term memory. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724--19731
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.