Signed Dual Attention: Capturing Signed Dependencies in Time Series Forecasting
Pith reviewed 2026-06-28 06:58 UTC · model grok-4.3
The pith
Signed Dual Attention models both positive and negative time series dependencies in one shared block without extra parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Signed Dual Attention is a novel attention formulation that captures both positive and negative relational patterns without additional parameters. By leveraging a dual message-passing scheme inspired by correlation structures, it propagates both supportive and contrastive information within a single shared block, effectively achieving the expressiveness of two-head attention without additional parameters.
What carries the argument
Signed Dual Attention, a dual message-passing scheme that handles supportive and contrastive information in one shared attention block.
If this is right
- The module integrates directly into existing transformer architectures for time series forecasting.
- It produces performance gains in forecasting tasks that require modeling signed relations.
- It delivers two-head attention expressiveness at the parameter cost of a single block.
- It supports development of more parameter-efficient transformer variants.
Where Pith is reading between the lines
- The same dual scheme could be tested on signed graph tasks outside time series.
- Performance comparisons on datasets with explicit negative correlations would directly test the signed modeling benefit.
- The block might reduce total parameter count when replacing multi-head attention layers in other sequence models.
Load-bearing premise
A single shared dual message-passing block can carry both positive and negative signals at the full expressiveness level of two separate attention heads.
What would settle it
A controlled experiment on time series with known opposing dependencies where Signed Dual Attention matches or exceeds two-head attention performance only when extra parameters are added.
Figures

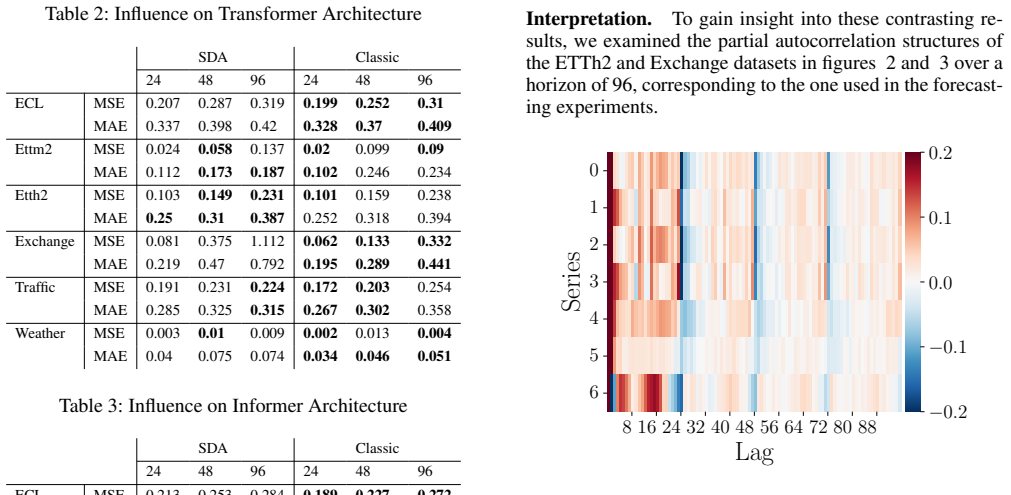
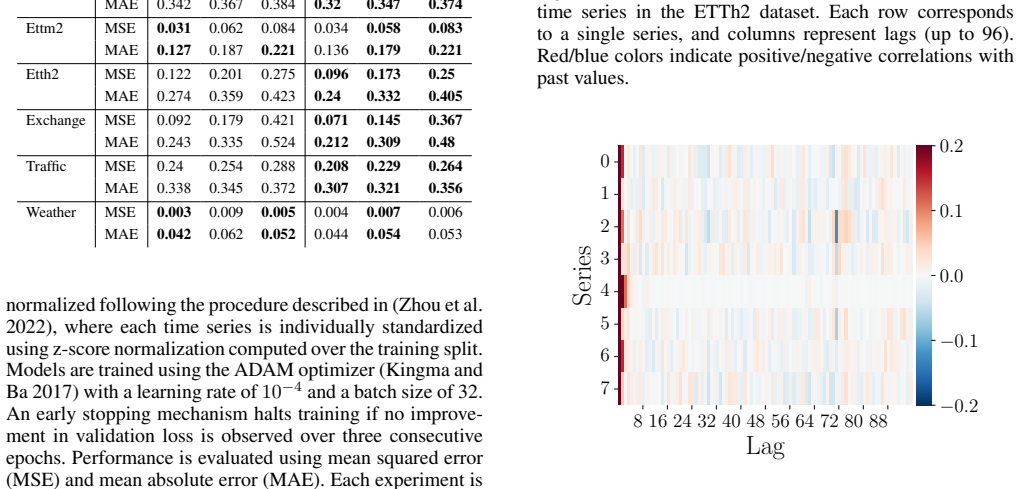
read the original abstract
Initially developed for natural language processing, Transformer architectures and attention mechanisms are now central to a wide range of deep learning models, including applications in time series forecasting. A standard attention mechanism, however, implicitly assumes homophilic interactions, limiting its ability to model data with positive and negative dependencies, such as time series. In this work, we introduce the Signed Dual Attention, a novel attention formulation that captures both positive and negative relational patterns without additional parameters. By leveraging a dual message-passing scheme inspired by correlation structures, Signed Dual Attention propagates both supportive and contrastive information within a single shared block, effectively achieving the expressiveness of two head attention without additional parameters. This module can be seamlessly integrated into existing architectures and can yield performance gains in certain situations, requiring signed relational modeling. This approach opens a pathway toward more expressive and parameter-efficient transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Signed Dual Attention, a novel attention mechanism for time series forecasting. It uses a dual message-passing scheme inspired by correlation structures to capture both positive and negative relational patterns within a single shared block, claiming this achieves the expressiveness of two-head attention without additional parameters. The module is presented as integrable into existing architectures and potentially yielding performance gains for signed relational modeling.
Significance. If the expressiveness equivalence and parameter-free property hold, the approach could provide a more efficient way to model signed dependencies in transformers for time series tasks, addressing limitations of standard homophilic attention.
major comments (1)
- [Abstract] Abstract: the central claim that the dual scheme 'effectively achieving the expressiveness of two head attention without additional parameters' is asserted without any explicit attention equations, derivation, or argument demonstrating that the shared projection matrices and dual paths span the same function class as two independent heads (e.g., no proof that positive/negative paths are not linearly coupled).
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address the concern regarding the abstract's central claim below, and we will revise the manuscript accordingly to improve clarity and support for the expressiveness argument.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the dual scheme 'effectively achieving the expressiveness of two head attention without additional parameters' is asserted without any explicit attention equations, derivation, or argument demonstrating that the shared projection matrices and dual paths span the same function class as two independent heads (e.g., no proof that positive/negative paths are not linearly coupled).
Authors: We agree that the abstract, being a high-level summary, does not contain the explicit equations or full derivation. The main manuscript (Section 3) defines Signed Dual Attention via explicit dual message-passing equations that use shared projection matrices to compute positive and negative relational updates in parallel within one block. The design ensures the two paths operate on distinct signed correlation structures, allowing independent aggregation of supportive and contrastive information. We acknowledge that a formal proof equating the spanned function class exactly to two independent heads (and ruling out linear coupling) is not provided; the claim is presented as effective equivalence based on the dual-path construction. We will revise the abstract to include a brief reference to Section 3 and a short qualifier on the design rationale, and we will add a concise supporting argument or sketch in the main text to address the coupling concern. revision: yes
Circularity Check
No derivation chain or equations presented; expressiveness claim asserted without visible reduction to inputs
full rationale
The manuscript abstract states the central claim that Signed Dual Attention achieves the expressiveness of two-head attention without additional parameters via a dual message-passing scheme, but supplies neither explicit attention equations, a derivation of the equivalence, nor any self-citations. No load-bearing steps, fitted parameters renamed as predictions, or self-referential definitions are visible in the provided text. The derivation chain cannot be walked because none is exhibited; therefore no circularity of the enumerated kinds can be identified. The result is treated as self-contained against external benchmarks for the purpose of this analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chronos: Learning the Language of Time Series
Chronos: Learning the Language of Time Series. arXiv:2403.07815. Bahdanau, D.; Cho, K.; and Bengio, Y
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Neural Machine Translation by Jointly Learning to Align and Translate
Neural Ma- chine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473. Bertasius, G.; Wang, H.; and Torresani, L
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Is Space-Time At- tention All You Need for Video Understanding? arXiv:2102.05095. Box, G. E. P.; and Jenkins, G. M. 1970.Time Series Analysis: Forecasting and Control. San Francisco, CA: Holden-Day. Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; Agarwal, S.; Herbert-V oss, A.; Kru...
-
[4]
Language Models are Few-Shot Learners
Language Models are Few-Shot Learners. arXiv:2005.14165. Chen, J.; Li, G.; Hopcroft, J. E.; and He, K
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[5]
SignGT: Signed Attention-based Graph Transformer for Graph Represen- tation Learning. arXiv:2310.11025. Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; Uszkoreit, J.; and Houlsby, N
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929. Grassia, M.; and Mangioni, G. 2022.wsGAT: Weighted and Signed Graph Attention Networks for Link Prediction, 369–375. Springer International Publishing. ISBN 9783030934095. Hamilton, J. D. 1994.Time Series Analysis. Princeton, NJ: Prince- ton University Press. Hua...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
Signed Graph Attention Networks. arXiv:1906.10958. Joshi, C. K
-
[8]
Transformers are Graph Neural Networks. arXiv:2506.22084. Kingma, D. P.; and Ba, J
-
[9]
Adam: A Method for Stochastic Optimization
Adam: A Method for Stochastic Optimization. arXiv:1412.6980. Kitaev, N.; Łukasz Kaiser; and Levskaya, A
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Reformer: The Efficient Transformer
Reformer: The Efficient Transformer. arXiv:2001.04451. Lai, G.; Chang, W.-C.; Yang, Y .; and Liu, H
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[11]
Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks
Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks. arXiv:1703.07015. Lim, B.; Arik, S. O.; Loeff, N.; and Pfister, T
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Arik, Nicolas Loeff, and Tomas Pfister
Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting. arXiv:1912.09363. Nie, Y .; Nguyen, N. H.; Sinthong, P.; and Kalagnanam, J
-
[13]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
A Time Series is Worth 64 Words: Long-term Forecasting with Trans- formers. arXiv:2211.14730. Pan, Y .; Ji, X.; You, J.; Li, L.; Liu, Z.; Zhang, X.; Zhang, Z.; and Wang, M
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv:1912.01703. Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, L.; and Polosukhin, I
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[15]
Attention Is All You Need. arXiv:1706.03762. Wang, S.; Li, B.; Khabsa, M.; Fang, H.; and Ma, H
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Linformer: Self-Attention with Linear Complexity
Lin- former: Self-Attention with Linear Complexity. arXiv:2006.04768. Wang, X.; Sun, S.; Xie, L.; and Ma, L
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[17]
Efficient Conformer with Prob-Sparse Attention Mechanism for End-to-EndSpeech Recognition. arXiv:2106.09236. Wu, H.; Xu, J.; Wang, J.; and Long, M
-
[18]
Autoformer: Decom- position Transformers with Auto-Correlation for Long-Term Series Forecasting. arXiv:2106.13008. Zeng, T.; and Li, J
-
[19]
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. arXiv:2012.07436. Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; and Jin, R
-
[20]
FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting. arXiv:2201.12740
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.