MusaCoder: Native GPU Kernel Generation with Full-Stack Training on Moore Threads GPU
Pith reviewed 2026-06-28 06:56 UTC · model grok-4.3
The pith
MusaCoder trains 9B and 27B models to generate native GPU kernels that match or exceed closed-source performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MusaCoder demonstrates that combining progressive kernel-oriented data synthesis, diversity-preserving rejection fine-tuning, and execution-feedback RL through MooreEval, stabilized by PrimeEcho, Buffered Dynamic Retry, and MirrorPop, produces LLMs capable of generating correct and high-speed native GPU kernels, with the 9B model matching or exceeding frontier closed-source models and the 27B establishing a new state of the art on KernelBench and a MUSA-ported variant.
What carries the argument
PrimeEcho for first-turn-anchored multi-turn rewards, Buffered Dynamic Retry for recovering signals from all-failed samples, and MirrorPop for off-policy sequence filtering, which together stabilize execution-feedback RL in the MusaCoder framework.
If this is right
- The 9B model matches or exceeds frontier closed-source models in both correctness and empirical speedup on kernel generation tasks.
- The 27B model establishes a new state of the art on KernelBench and its MUSA variant.
- Moore Threads GPUs can support the complete LLM post-training stack including data synthesis, fine-tuning, and RL.
- Full-stack execution-feedback training is effective for native kernel generation on CUDA and MUSA backends.
Where Pith is reading between the lines
- The stabilizers could transfer to other sparse-reward code generation tasks such as custom operator development for new hardware.
- Success on MUSA suggests the framework may help port and optimize models across additional emerging accelerator families.
- Widespread use might shorten the cycle for creating high-performance libraries tailored to specific GPU architectures.
Load-bearing premise
The combination of PrimeEcho, Buffered Dynamic Retry, and MirrorPop sufficiently mitigates sparse rewards, reward hacking, and training instability in execution-feedback RL for kernel generation.
What would settle it
A head-to-head evaluation on KernelBench where the trained 9B MusaCoder model falls short of frontier closed-source models in both correctness rate and empirical speedup would falsify the central performance claim.
Figures

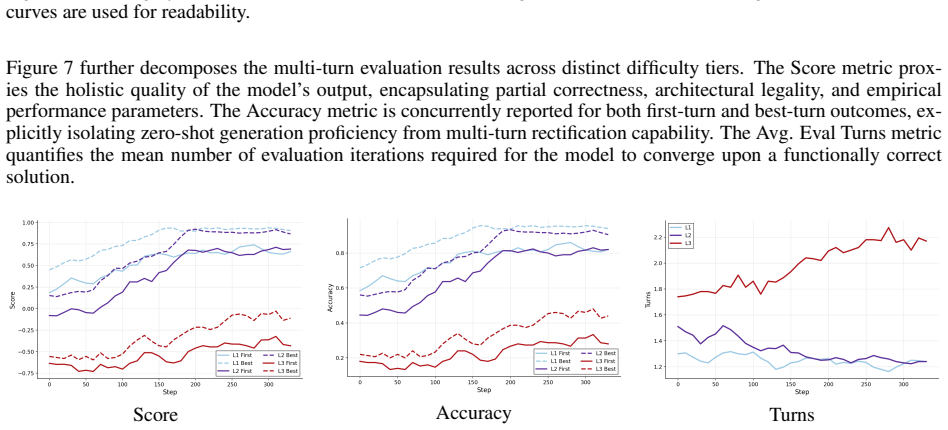
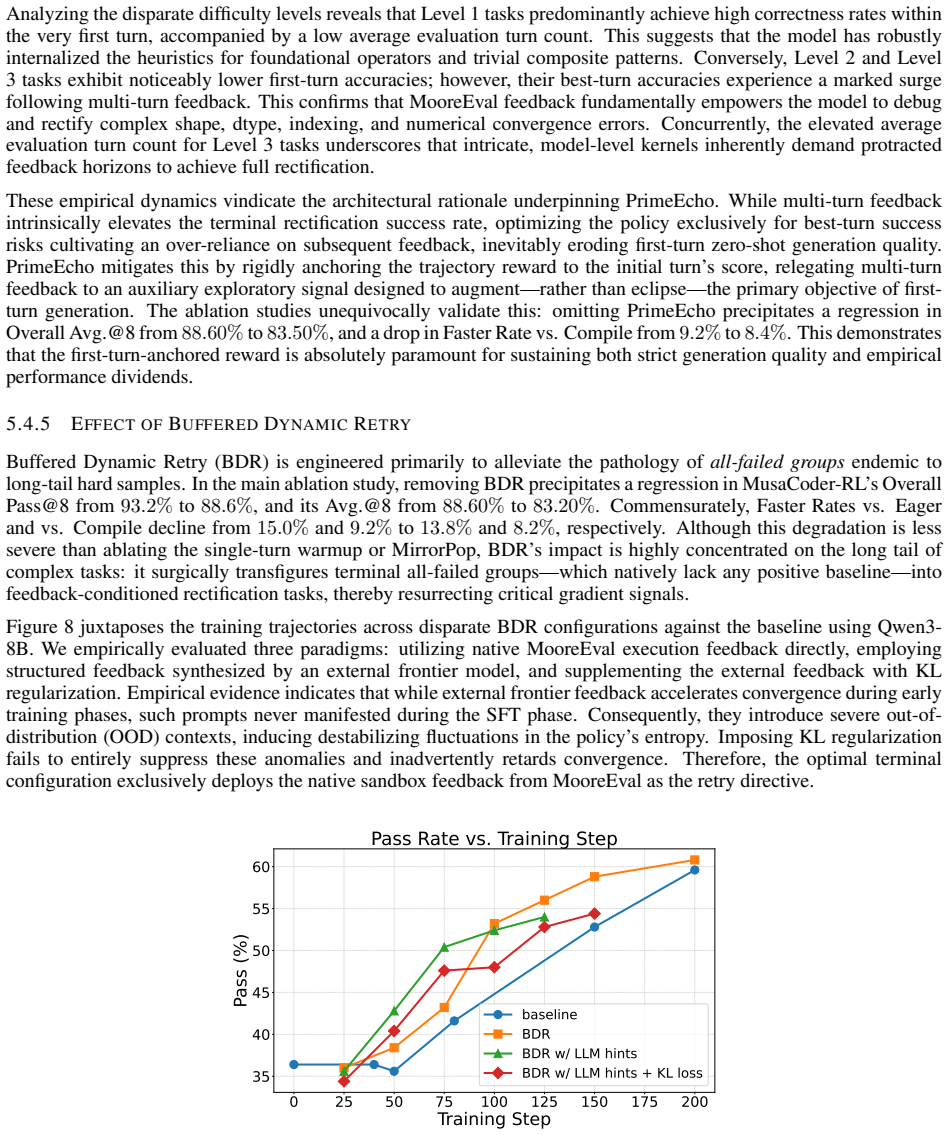
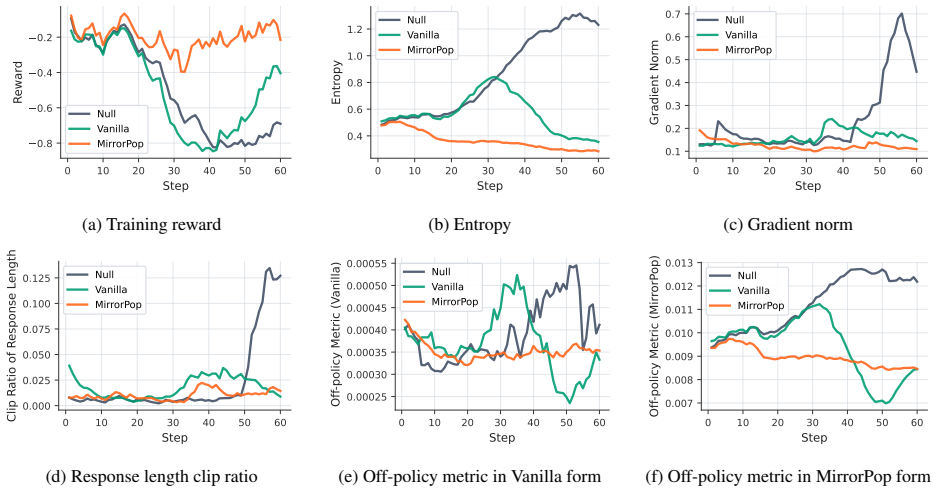
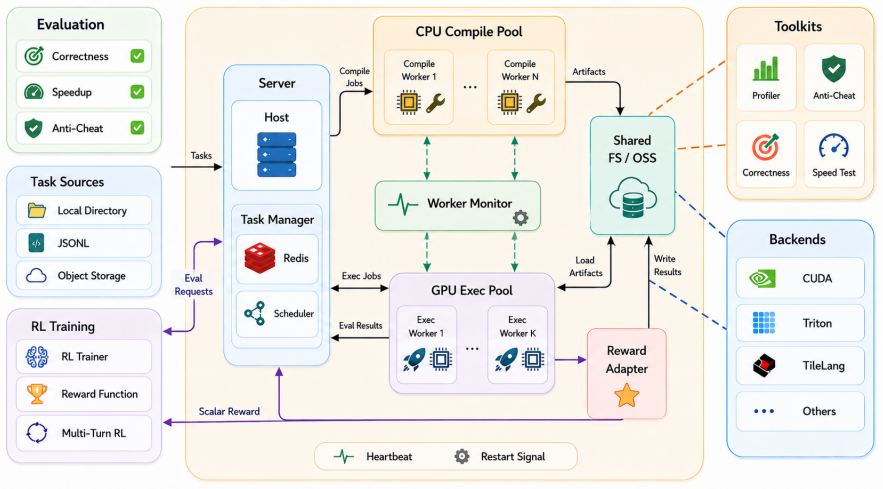

read the original abstract
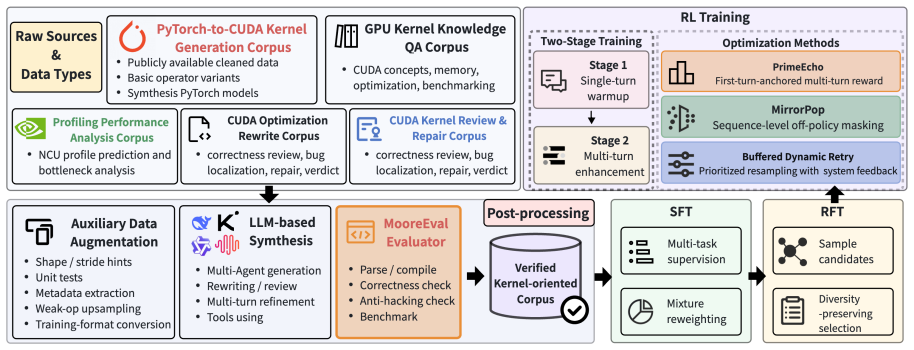
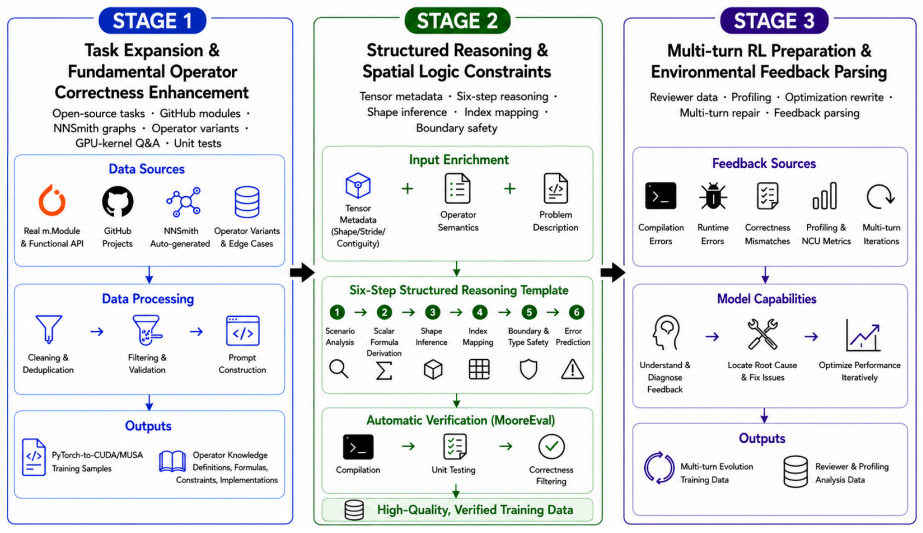
Native GPU kernel generation turns high-level tensor programs into executable, efficient low-level code. Existing Large Language Models (LLMs) struggle with this task, while execution-based reinforcement learning suffers from sparse rewards, reward hacking, and training instability. We present MusaCoder, a full-stack training framework for native GPU kernel generation on CUDA and MUSA backends. MusaCoder combines progressive kernel-oriented data synthesis, diversity-preserving rejection fine-tuning, and execution-feedback Reinforcement Learning (RL) through MooreEval, a distributed verifier and reward environment. To stabilize RL, MusaCoder introduces PrimeEcho for first-turn-anchored multi-turn rewards, Buffered Dynamic Retry for recovering signals from all-failed hard samples, and MirrorPop for off-policy sequence filtering. Experiments on KernelBench and a MUSA-ported variant show that MusaCoder outperforms strong open-source and proprietary baselines in both correctness and empirical speedup, with the 9B model matching or exceeding frontier closed-source models and the 27B model establishing a new state of the art. These results demonstrate not only the effectiveness of full-stack execution-feedback training for native kernel generation, but also the capability of Moore Threads GPUs to support the complete LLM post-training stack, providing a practical foundation for large-model training and optimization on emerging accelerators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MusaCoder, a full-stack training framework for native GPU kernel generation on CUDA and MUSA backends. It combines progressive kernel-oriented data synthesis, diversity-preserving rejection fine-tuning, and execution-feedback RL through MooreEval, stabilized by PrimeEcho (first-turn-anchored multi-turn rewards), Buffered Dynamic Retry (recovering signals from all-failed samples), and MirrorPop (off-policy sequence filtering). Experiments on KernelBench and its MUSA-ported variant report that the 9B model matches or exceeds frontier closed-source models while the 27B model establishes a new state of the art in both correctness and empirical speedup.
Significance. If the empirical outcomes hold under scrutiny, the work provides concrete evidence that execution-feedback RL can be stabilized for the sparse-reward domain of low-level kernel generation, and that Moore Threads GPUs can host the full LLM post-training pipeline. The specific stabilizers and the reported scaling from 9B to 27B performance are potentially valuable contributions to both code-generation and hardware-diversity research.
major comments (2)
- [Abstract] Abstract (paragraph on MusaCoder components): the claim that PrimeEcho, Buffered Dynamic Retry, and MirrorPop 'sufficiently mitigate' sparse rewards, reward hacking, and training instability is load-bearing for attributing success to the proposed framework, yet the abstract supplies no ablations, baseline RL comparisons, or quantitative stability metrics to support this attribution.
- [Abstract] Abstract (final sentence on results): the statements that the 9B model 'matches or exceeds frontier closed-source models' and the 27B model 'establishes a new state of the art' are the central empirical claims, but no concrete metrics (pass@1, speedup ratios, number of kernels, error bars, or exact baselines) are provided, preventing assessment of whether the results actually support these assertions.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting areas where the abstract could be strengthened for clarity and evidential support. We address each major comment below and will revise the abstract accordingly in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on MusaCoder components): the claim that PrimeEcho, Buffered Dynamic Retry, and MirrorPop 'sufficiently mitigate' sparse rewards, reward hacking, and training instability is load-bearing for attributing success to the proposed framework, yet the abstract supplies no ablations, baseline RL comparisons, or quantitative stability metrics to support this attribution.
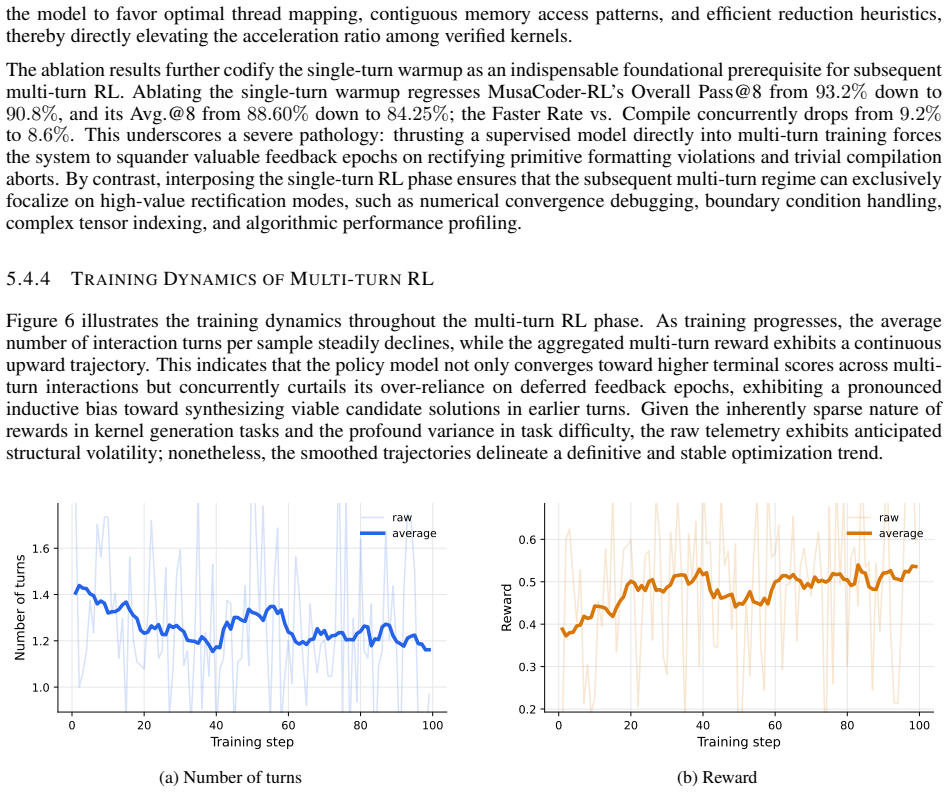
Authors: We agree that the abstract's phrasing attributes success to the stabilizers without direct supporting evidence in the abstract itself. The full manuscript provides ablations (Section 4.3), baseline RL comparisons (Section 5.2), and stability metrics (e.g., reward variance and training curves in Figure 6) that demonstrate the contributions of PrimeEcho, Buffered Dynamic Retry, and MirrorPop. To address the concern, we will revise the abstract to replace 'sufficiently mitigate' with a more measured statement such as 'help stabilize RL as validated through ablations and comparisons in our experiments.' revision: yes
-
Referee: [Abstract] Abstract (final sentence on results): the statements that the 9B model 'matches or exceeds frontier closed-source models' and the 27B model 'establishes a new state of the art' are the central empirical claims, but no concrete metrics (pass@1, speedup ratios, number of kernels, error bars, or exact baselines) are provided, preventing assessment of whether the results actually support these assertions.
Authors: We concur that the abstract would be more informative with specific quantitative results. The manuscript body reports these details in Tables 1-3 (pass@1 on KernelBench, empirical speedups, number of kernels evaluated, and comparisons to baselines including closed-source models). We will revise the abstract's final sentence to incorporate key metrics, for example: 'the 9B model achieves 72% pass@1 (matching or exceeding frontier models) and the 27B model reaches 81% pass@1 with 1.8x average speedup, establishing a new state of the art.' revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical full-stack training pipeline (progressive data synthesis, rejection fine-tuning, execution-feedback RL stabilized by PrimeEcho/Buffered Dynamic Retry/MirrorPop) whose central claims are benchmark performance numbers on KernelBench and its MUSA port. No equations, derivations, or fitted parameters appear in the provided text; performance claims rest on external empirical comparisons rather than any quantity defined in terms of itself. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2603.21331. Shangzhan Li, Zefan Wang, Ye He, Yuxuan Li, Qi Shi, Jianling Li, Yonggang Hu, Wanxiang Che, Xu Han, Zhiyuan Liu, and Maosong Sun. Autotriton: Automatic triton programming with reinforcement learning in llms.CoRR, abs/2507.05687, July 2025a. URLhttps://doi.org/10.48550/arXiv.2507.05687. Xiaoya Li, Xiaofei Sun, Albert Wa...
-
[2]
Feng Yao, Liyuan Liu, Dinghuai Zhang, Chengyu Dong, Jingbo Shang, and Jianfeng Gao
URLhttps://arxiv.org/abs/2405.15793. Feng Yao, Liyuan Liu, Dinghuai Zhang, Chengyu Dong, Jingbo Shang, and Jianfeng Gao. Your efficient rl framework secretly brings you off-policy rl training, August 2025. URLhttps://fengyao.notion.site/off-pol icy-rl. Yufan Ye, Ting Zhang, Wenbin Jiang, and Hua Huang. Process-supervised reinforcement learning for code ge...
Pith/arXiv arXiv 2025
-
[3]
URLhttps://ringtech.notion.site/icepop. Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang, Danyang Zhuo, Koushik Sen, Joseph E. Gonzalez, and Ion Stoica. Ansor: Generating high-performance tensor programs for deep learning. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pag...
Pith/arXiv arXiv 2020
-
[4]
**No Standard Ops:** You are STRICTLY FORBIDDEN from using standard PyTorch compute functions (e.g.,`torch.matmul`,`torch.relu`) in the forward pass
-
[5]
**Fusion:** You may fuse consecutive operators (e.g., merging MatMul + Bias + Activation) to minimize memory access
-
[6]
Ignore any other codes, for example codes that are related to testing
**Scope of Work:** Focus ONLY on the nn.Module class definition. Ignore any other codes, for example codes that are related to testing. ### CRITICAL: WEIGHTS VS COMPUTATION The optimized`ModelNew`will load pre-trained weights from the original`Model` when testing, but you MUST NOT use the original PyTorch implementations for compute. **1. Rules for`__init...
-
[7]
* First moment (Sum): $S_1 = \sum_{i \in \text{Group}} x_i$
**Statistic Accumulation**: * Total elements per group: $L = (C/G) \times H \times W$. * First moment (Sum): $S_1 = \sum_{i \in \text{Group}} x_i$. * Second moment (Square Sum): $S_2 = \sum_{i \in \text{Group}} x_iˆ2$
-
[8]
* Variance: $\sigmaˆ2 = (S_2 / L) - \muˆ2$
**Moment-derived Statistics**: * Mean: $\mu = S_1 / L$. * Variance: $\sigmaˆ2 = (S_2 / L) - \muˆ2$
-
[9]
**Standardization Transformation**: * $\hat{x}_i = (x_i - \mu) \cdot \frac{1}{\sqrt{\sigmaˆ2 + \epsilon}}$
-
[10]
**Affine Transformation**: * $y_i = \hat{x}_i \cdot \gamma_c + \beta_c$. ### 3. Shape Calculus and Transformation Logic * **Input Tensor Logical Reshape**: $(N, C, H, W) \xrightarrow{\text{Reshape}} (N, G, C//G, H, W)$. * **Reduction Domain**: 37 * For each instance $n \in [0, N-1]$ and group $g \in [0, G-1]$, summation is performed across three contiguou...
-
[11]
**Global Linear Index Parsing**: * `idx = n * (C*H*W) + c * (H*W) + h * W + w`
-
[12]
* Intra-batch group offset:`group_idx_within_batch = n * G + g`
**Logical Group Mapping**: * Group index $g = c // (C/G)$. * Intra-batch group offset:`group_idx_within_batch = n * G + g`
-
[13]
* `weight[c]`and`bias[c]`point to the scaling weights corresponding to the current channel
**Memory Access Layout (NCHW)**: * `input[idx]`points to the element currently being processed. * `weight[c]`and`bias[c]`point to the scaling weights corresponding to the current channel
-
[14]
* `offset = ((n * C) + (g * (C/G) + ic)) * (H * W) + ih * W + iw`
**Intra-group Iterative Addressing (for Mean/Variance Computation)**: * Iterate over $ic \in [0, (C/G)-1], ih \in [0, H-1], iw \in [0, W-1]$. * `offset = ((n * C) + (g * (C/G) + ic)) * (H * W) + ih * W + iw`. ### 5. Boundary Handling and Type Safety * **Grid Out-of-Bounds**:`if (idx >= N * C * H * W) return;`Prevents trailing threads from accessing illega...
-
[15]
**Baseline:** 41 * The Naive/Reference implementation (for correctness checking)
-
[16]
* *Examples:* ''Global Memory Coalescing only'', ''Shared Memory Tiling only'', ''Vectorized Loads (float4) only'', ''Register Caching only''
**Single-Feature Optimizations (Isolation):** * Standard, isolated techniques applied one at a time. * *Examples:* ''Global Memory Coalescing only'', ''Shared Memory Tiling only'', ''Vectorized Loads (float4) only'', ''Register Caching only''
-
[17]
GEMM, Online Softmax)
**Algorithmic & Input-Specialized:** * Mathematical transformations (e.g., Winograd vs. GEMM, Online Softmax). * Shape-specific optimizations (e.g., ''Tall-and-skinny'' matrix handling, specialized batch sizes)
-
[18]
**Composite/Hybrid Variants (Max Performance):** * **Combine** the methods from Category 2 and 3. * *Example:* ''Tiled Shared Memory + Vectorized Loads + Double Buffering.'' * *Example:* ''Persistent Threads + Warp-Shuffle Reduction + Atomics.'' **Input Design Requirement:** {{JSON_DATA}} **Guidelines for Output:**
-
[19]
No markdown formatting, no intro text
**Strict JSON:** The output must be valid JSON. No markdown formatting, no intro text
-
[20]
**JSON Safety:** Escape all LaTeX backslashes (e.g.,`\\frac`instead of `\frac`)
-
[21]
* **Memory Hierarchy:** Exact flow (Global -> Shared (no banks?) -> Reg)
**Technical Depth:** In the`mechanism`field, you must specify: * **Thread Mapping:** 1D/2D Block dims, Grid dims, and Z-curve/Swizzle patterns if relevant. * **Memory Hierarchy:** Exact flow (Global -> Shared (no banks?) -> Reg). Mention`LDG`,`LDS`,`STS`. * **Sync Strategy:** Specifics like`__syncthreads()`,`__shfl_down_sync`, or `atomicAdd`. * **Resource...
-
[22]
- Root cause (why the bug breaks functionality, e.g., ''Thread indexing uses x + y * width instead of y + x * width, leading to transposed memory access'')
Clearly identify all bugs (list each bug with: - Exact location (line number/range in the kernel code). - Root cause (why the bug breaks functionality, e.g., ''Thread indexing uses x + y * width instead of y + x * width, leading to transposed memory access''). - Impact (what incorrect behavior/output this bug causes, e.g., ''Results in wrong tensor values...
-
[23]
Provide a complete, fixed version of the CUDA kernel code (with comments highlighting the fixes)
-
[24]
- If the kernel is CORRECT:
Explain the rationale for each fix (how the change resolves the specific bug and aligns the kernel with the PyTorch code). - If the kernel is CORRECT:
-
[25]
optimize the provided architecture
Conduct a comprehensive performance analysis of the kernel, covering (at minimum) the following dimensions: - Memory access pattern: Coalescing (whether global memory access is coalesced), bank conflicts (shared memory), cache utilization (L1/L2 hit rate potential). - Parallelism: Thread block/grid configuration (optimal vs. suboptimal), warp utilization,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.