NLLog: Lightweight, Explainable SOC Anomaly Detection via Log-to-Language Rewriting
Pith reviewed 2026-06-28 05:33 UTC · model grok-4.3
The pith
NLLog rewrites log templates into natural-language sentences for accurate anomaly detection and explanations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
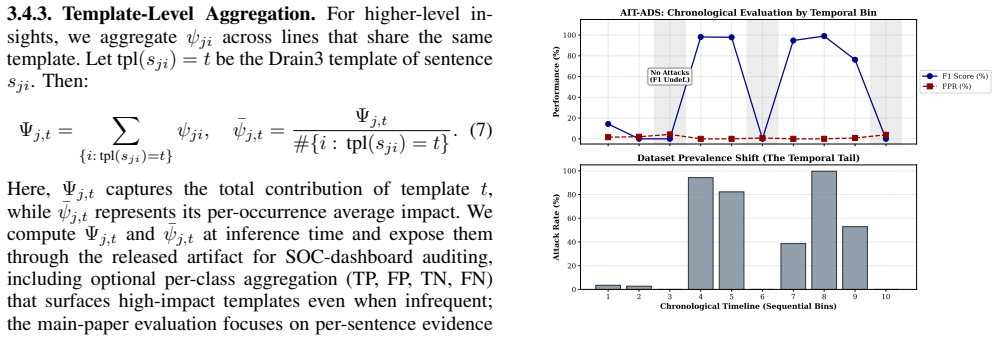
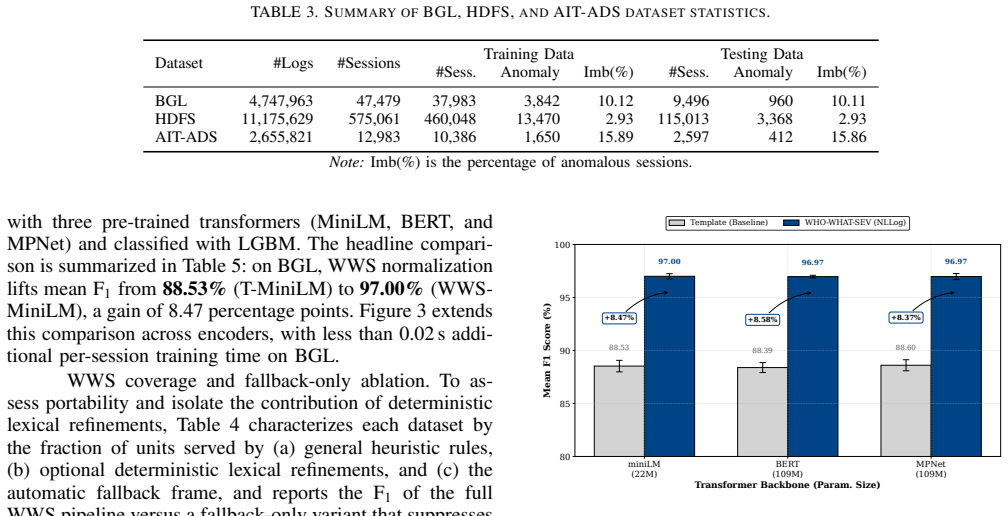
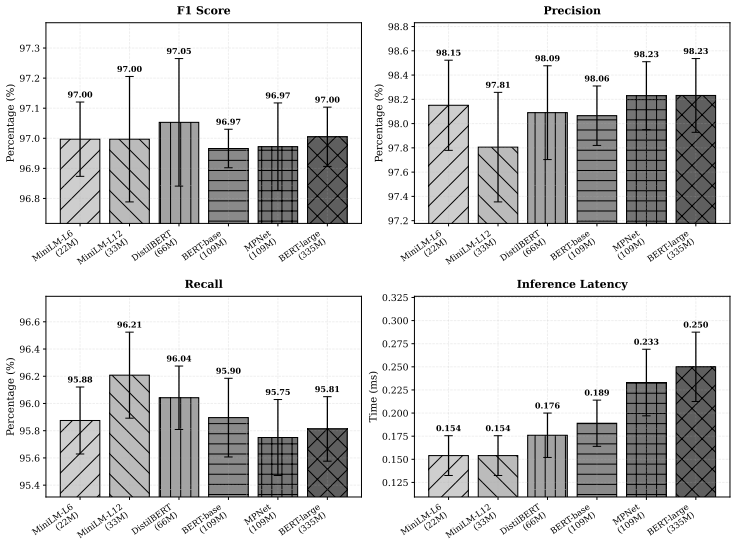
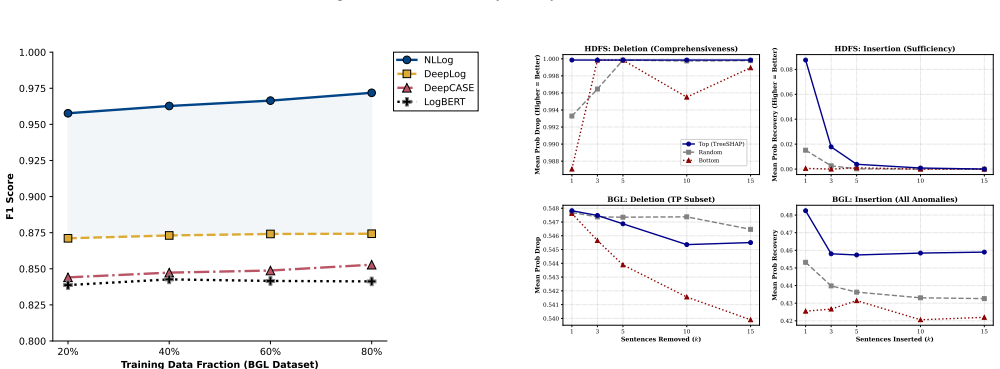
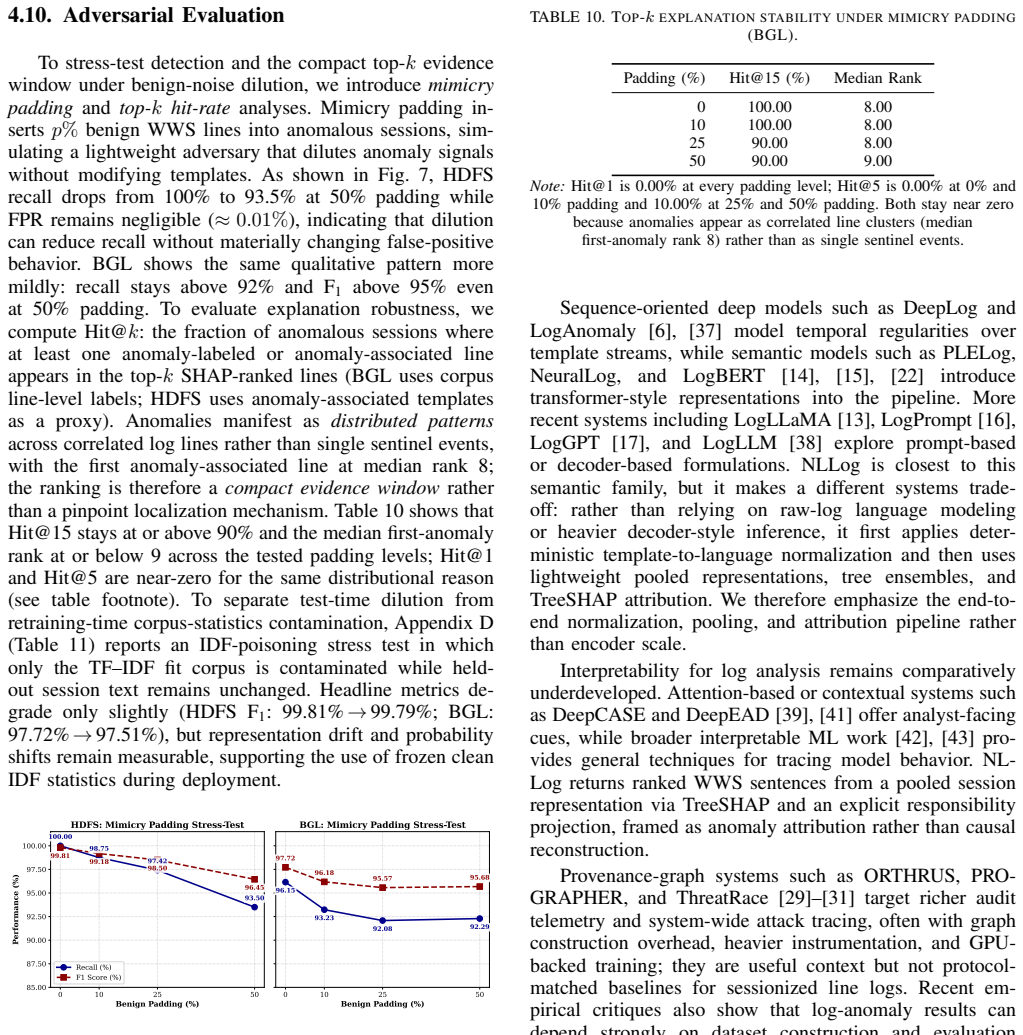
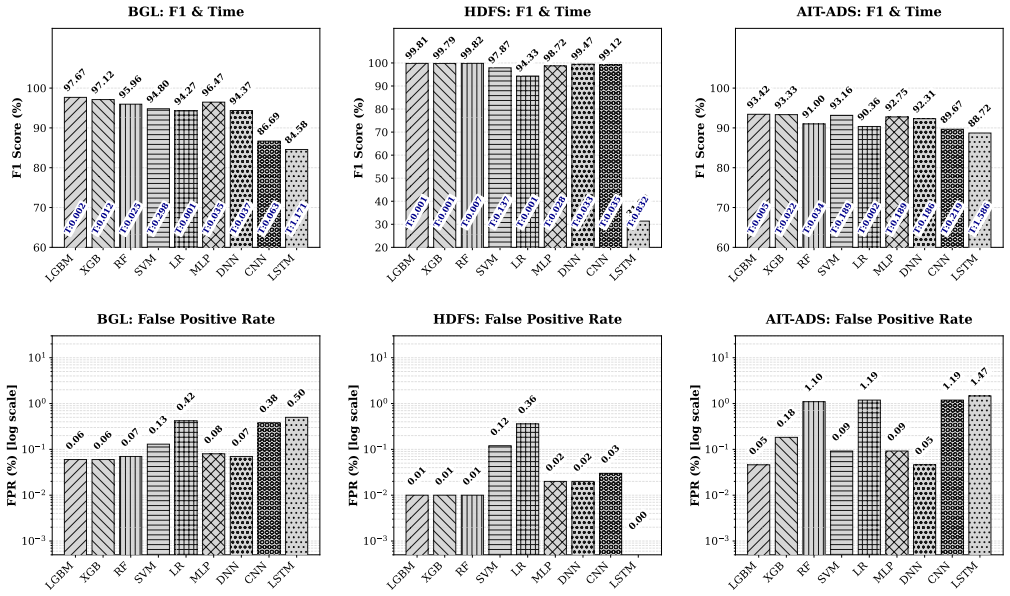
NLLog deterministically rewrites parsed templates into WHO-WHAT-SEVERITY sentences, pools them with TF-IDF weighting, classifies sessions with tree ensembles, and back-projects evidence with TreeSHAP for analyst review. On HDFS and BGL corpora it exceeds two reproduced matched-protocol baselines; across HDFS, BGL, and the AIT Alert Data Set it sustains low false-positive rates with commodity-hardware latency suitable for security operations center triage. Coverage, sparse-versus-dense, faithfulness, and adversarial ablations show that fallback sufficiency is corpus-dependent, that an enrollment-time coverage check can surface refinement requirements before deployment, and that an auditable d
What carries the argument
The deterministic rewrite of parsed log templates into WHO-WHAT-SEVERITY natural-language sentences that serves as the input representation for TF-IDF pooling and tree-ensemble classification.
If this is right
- An enrollment-time coverage check can identify when the rewrite needs refinement before a system is deployed.
- Adversarial ablations indicate the representation layer remains usable even under targeted perturbations.
- The method delivers explainable outputs via TreeSHAP attributions that map directly back to the rewritten sentences.
- Commodity-hardware latency supports triage workflows in live security operations centers.
Where Pith is reading between the lines
- The same sentence-rewrite step could be tested on non-security event logs such as application performance traces to see whether the representation transfers.
- If the rewrite proves stable across streaming inputs, it could support continuous rather than session-based detection.
- Connecting the coverage check to automated template refinement might reduce manual maintenance of log parsers over time.
Load-bearing premise
The rewrite of log templates into natural-language sentences keeps enough detail from the original logs to support accurate anomaly classification without losing critical signals.
What would settle it
A controlled test on a log corpus where the rewrite step removes a distinguishing anomaly cue that the original templates contain, causing NLLog performance to fall below the reproduced baselines.
Figures




read the original abstract
System-generated logs underpin security monitoring, yet their rigid template-based format hinders both automated analysis and human comprehension. We present NLLog (Natural-Language Log), a lightweight pipeline that deterministically rewrites parsed templates into WHO-WHAT-SEVERITY sentences, pools them with term-frequency-inverse-document-frequency weighting, classifies sessions with tree ensembles, and back-projects evidence with TreeSHAP for analyst review. On Hadoop Distributed File System (HDFS) and Blue Gene/L (BGL) corpora, NLLog exceeds two reproduced matched-protocol baselines; across HDFS, BGL, and the AIT Alert Data Set, it sustains low false-positive rates with commodity-hardware latency suitable for security operations center triage. Coverage, sparse-versus-dense, faithfulness, and adversarial ablations show that fallback sufficiency is corpus-dependent, that an enrollment-time coverage check can surface refinement requirements before deployment, and that an auditable deterministic rewrite combined with lightweight dense encoding provides a measurable representation layer for log-anomaly detection and triage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NLLog, a lightweight pipeline for SOC log anomaly detection that parses templates, deterministically rewrites them into WHO-WHAT-SEVERITY natural-language sentences, applies TF-IDF pooling, classifies with tree ensembles, and back-projects explanations via TreeSHAP. It claims to exceed two reproduced matched-protocol baselines on HDFS and BGL corpora, sustain low false-positive rates across HDFS, BGL, and AIT datasets with commodity-hardware latency, and supports these via coverage, sparse-versus-dense, faithfulness, and adversarial ablations showing corpus-dependent fallback sufficiency and the value of an enrollment-time coverage check.
Significance. If the empirical claims hold, the work provides a practical, explainable representation layer for log-based anomaly detection that balances automation with analyst review, potentially aiding SOC triage without heavy compute. The explicit ablations and emphasis on deterministic rewrite are strengths that allow falsifiable assessment of the representation choice.
major comments (2)
- [Abstract] Abstract (pipeline and results paragraphs): The central claim of outperformance and low FP rates rests on the rewrite step preserving distinguishing anomaly signals, yet the faithfulness ablations are described only at high level without an explicit preservation metric (e.g., mutual information between original template features and rewritten sentences, or an ablation replacing the rewrite with raw template tokens) on the exact HDFS/BGL splits used for the headline numbers.
- [Abstract] Abstract (results paragraph): Reported gains over reproduced baselines and low false-positive rates are stated without error bars, exact train/test splits, or statistical significance tests, which leaves open the possibility that post-hoc choices or variance could affect the cross-dataset claims.
minor comments (2)
- The description of fallback sufficiency being 'corpus-dependent' would benefit from a table or figure quantifying coverage percentages per dataset.
- Consider clarifying in the methods whether the WHO-WHAT-SEVERITY mapping is fully deterministic with no tunable thresholds or learned components.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating planned revisions to improve clarity and rigor without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (pipeline and results paragraphs): The central claim of outperformance and low FP rates rests on the rewrite step preserving distinguishing anomaly signals, yet the faithfulness ablations are described only at high level without an explicit preservation metric (e.g., mutual information between original template features and rewritten sentences, or an ablation replacing the rewrite with raw template tokens) on the exact HDFS/BGL splits used for the headline numbers.
Authors: We agree that the faithfulness section would be strengthened by an explicit preservation metric computed on the precise HDFS/BGL splits. The existing faithfulness ablation demonstrates that the deterministic rewrite maintains anomaly signals through downstream performance, but we will add mutual information between original template features and rewritten sentences plus a raw-token ablation on those exact splits in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract (results paragraph): Reported gains over reproduced baselines and low false-positive rates are stated without error bars, exact train/test splits, or statistical significance tests, which leaves open the possibility that post-hoc choices or variance could affect the cross-dataset claims.
Authors: The comment is correct; the abstract and results would benefit from greater statistical transparency. We will revise to report error bars from repeated runs, state the exact train/test splits, and include statistical significance tests for the headline comparisons on HDFS and BGL. revision: yes
Circularity Check
No significant circularity; empirical pipeline with external benchmarks and ablations
full rationale
The paper describes a deterministic rewrite pipeline followed by TF-IDF pooling, tree-ensemble classification, and TreeSHAP explanation, evaluated on public corpora (HDFS, BGL, AIT) against reproduced baselines with multiple ablations (coverage, faithfulness, adversarial). No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the provided text. Performance claims rest on external data splits and direct comparisons rather than reducing to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The base-rate fallacy and the difficulty of intrusion detection,
S. Axelsson, “The base-rate fallacy and the difficulty of intrusion detection,”ACM Transactions on Information and System Security, vol. 3, no. 3, pp. 186–205, 2000
2000
-
[2]
Outside the closed world: On using ma- chine learning for network intrusion detection,
R. Sommer and V . Paxson, “Outside the closed world: On using ma- chine learning for network intrusion detection,” inIEEE Symposium on Security and Privacy. IEEE, 2010, pp. 305–316
2010
-
[3]
A survey on intrusion detection systems and techniques,
S. Sharma, B. B. Gupta, and K. Ali, “A survey on intrusion detection systems and techniques,”Journal of Network and Computer Appli- cations, vol. 181, p. 103082, 2021
2021
-
[4]
Drain: An online log parsing approach with fixed depth tree,
P. He, J. Zhu, Z. Zheng, and M. R. Lyu, “Drain: An online log parsing approach with fixed depth tree,” inIEEE International Conference on Web Services (ICWS). IEEE, 2017, pp. 33–40
2017
-
[5]
Experience report: System log analysis for anomaly detection,
S. He, J. Zhu, P. He, and M. R. Lyu, “Experience report: System log analysis for anomaly detection,” inIEEE 27th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2016, pp. 207–218
2016
-
[6]
Deeplog: Anomaly detection and diagnosis from system logs through deep learning,
M. Du, F. Li, G. Zheng, and V . Srikumar, “Deeplog: Anomaly detection and diagnosis from system logs through deep learning,” inProceedings of the ACM SIGSAC Conference on Computer and Communications Security. ACM, 2017, pp. 1285–1298
2017
-
[7]
A survey on log anomaly detection,
J. Zhu, S. He, and J. Liu, “A survey on log anomaly detection,” Journal of Systems and Software, vol. 193, p. 111477, 2022
2022
-
[8]
Mining invariants from console logs for system problem detection,
J.-G. Lou, Q. Fu, S. Yang, Y . Xu, and J. Li, “Mining invariants from console logs for system problem detection,” inProceedings of the USENIX Annual Technical Conference. USENIX Association, 2010, pp. 1–14
2010
-
[9]
A survey on log analysis for anomaly detection,
W. Meng, Y . Liu, and Q. Zhu, “A survey on log analysis for anomaly detection,”Computers & Security, vol. 97, p. 101945, 2020
2020
-
[10]
Robust log-based anomaly detection on unstable log data,
X. Zhang, Y . Xu, Q. Lin, B. Qiao, H. Zhang, Y . Dang, C. Xie, X. Yang, Q. Cheng, Z. Li, J. Chen, and D. He, “Robust log-based anomaly detection on unstable log data,” inProceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis. ACM, 2019, pp. 807–810
2019
-
[11]
S. Nedelkoski, J. Bogatinovski, A. Acker, J. Cardoso, and O. Kao, “Self-supervised log parsing,”arXiv preprint arXiv:2003.07905, 2020
-
[12]
Deep learning for anomaly detection: A review,
G. Pang, C. Shen, L. Cao, and A. v. d. Hengel, “Deep learning for anomaly detection: A review,”ACM Computing Surveys, vol. 54, no. 2, pp. 1–38, 2021
2021
-
[13]
LogLLaMA: Transformer-based log anomaly detection with LLaMA,
Z. Yang and I. G. Harris, “Logllama: Transformer-based log anomaly detection with llama,” 2025. [Online]. Available: https://arxiv.org/abs/2503.14849
-
[14]
Semi-supervised log-based anomaly detection via prob- abilistic label estimation,
L. Yang, J. Chen, Z. Wang, W. Wang, J. Jiang, X. Dong, and W. Zhang, “Semi-supervised log-based anomaly detection via prob- abilistic label estimation,” in2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 2021, pp. 1448– 1460
2021
-
[15]
Log-based anomaly detection without log parsing,
V .-H. Le and H. Zhang, “Log-based anomaly detection without log parsing,” in2021 36th IEEE/ACM International Conference on Au- tomated Software Engineering (ASE). IEEE, 2021, pp. 492–504
2021
-
[16]
Logprompt: Prompt engineering towards zero-shot and interpretable log analy- sis,
Y . Liu, S. Tao, W. Meng, F. Yao, X. Zhao, and H. Yang, “Logprompt: Prompt engineering towards zero-shot and interpretable log analy- sis,” in2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), 2024, pp. 364–365
2024
-
[17]
Loggpt: Log anomaly detection via gpt,
X. Han, S. Yuan, and M. Trabelsi, “Loggpt: Log anomaly detection via gpt,” in2023 IEEE International Conference on Big Data (Big- Data), 2023, pp. 1117–1122
2023
-
[18]
Bert: Pre- training of deep bidirectional transformers for language understand- ing,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre- training of deep bidirectional transformers for language understand- ing,” inProceedings of NAACL-HLT, 2019, pp. 4171–4186
2019
-
[19]
Minilm: Deep self-attention distillation for task-agnostic compression of pre- trained transformers,
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou, “Minilm: Deep self-attention distillation for task-agnostic compression of pre- trained transformers,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020, pp. 5776–5788
2020
-
[20]
Log-based anomaly detection with deep learning: how far are we?
V .-H. Le and H. Zhang, “Log-based anomaly detection with deep learning: how far are we?”Journal of Systems and Software, vol. 188, p. 111300, 2022
2022
-
[21]
Semi-supervised log anomaly detection through semantic context extraction,
X. Yang, P. Chen, Z. He, Y . Gao, J. Liu, B. Qiao, Y . Dang, and Q. Lin, “Semi-supervised log anomaly detection through semantic context extraction,” inProceedings of the International Conference on Software Engineering (ICSE). IEEE, 2021, pp. 1176–1187
2021
-
[22]
Logbert: Log anomaly detection via bert,
H. Guo, S. Yuan, and X. Wu, “Logbert: Log anomaly detection via bert,” inProceedings of the International Joint Conference on Neural Networks (IJCNN). IEEE, 2021, pp. 1–8
2021
-
[23]
Term-weighting approaches in automatic text retrieval,
G. Salton and C. Buckley, “Term-weighting approaches in automatic text retrieval,”Information processing & management, vol. 24, no. 5, pp. 513–523, 1988
1988
-
[24]
Detecting large-scale system problems by mining console logs,
W. Xu, L. Huang, A. Fox, D. Patterson, and M. I. Jordan, “Detecting large-scale system problems by mining console logs,” inProceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, ser. SOSP ’09. New York, NY , USA: Association for Computing Machinery, 2009, pp. 117–132. [Online]. Available: https://doi.org/10.1145/1629575.1629587
-
[25]
Loghub: A large collection of system log datasets for ai-driven log analytics,
J. Zhu, S. He, P. He, J. Liu, and M. R. Lyu, “Loghub: A large collection of system log datasets for ai-driven log analytics,” 2023. [Online]. Available: https://arxiv.org/abs/2008.06448
-
[26]
What supercomputers say: A study of five system logs,
A. Oliner and J. Stearley, “What supercomputers say: A study of five system logs,” in37th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN’07), 2007, pp. 575–584
2007
-
[27]
Introducing a new alert data set for multi-step attack analysis,
M. Landauer, F. Skopik, and M. Wurzenberger, “Introducing a new alert data set for multi-step attack analysis,” in Proceedings of the 17th Cyber Security Experimentation and Test Workshop, ser. CSET ’24. New York, NY , USA: Association for Computing Machinery, 2024, pp. 41–53. [Online]. Available: https://doi.org/10.1145/3675741.3675748
-
[28]
Maintainable log datasets for evaluation of intrusion detection systems,
M. Landauer, F. Skopik, M. Frank, W. Hotwagner, M. Wurzenberger, and A. Rauber, “Maintainable log datasets for evaluation of intrusion detection systems,”IEEE Transactions on Dependable and Secure Computing, vol. 20, no. 4, pp. 3466–3482, 2023
2023
-
[29]
Orthrus: achieving high quality of attribu- tion in provenance-based intrusion detection systems,
B. Jiang, T. Bilot, N. El Madhoun, K. Al Agha, A. Zouaoui, S. Iqbal, X. Han, and T. Pasquier, “Orthrus: achieving high quality of attribu- tion in provenance-based intrusion detection systems,” inProceedings of the 34th USENIX Conference on Security Symposium, ser. SEC ’25. USA: USENIX Association, 2025
2025
-
[30]
PROGRAPHER: An anomaly detection system based on provenance graph embedding,
F. Yang, J. Xu, C. Xiong, Z. Li, and K. Zhang, “PROGRAPHER: An anomaly detection system based on provenance graph embedding,” in Proceedings of the 32nd USENIX Conference on Security Symposium, ser. SEC ’23. USA: USENIX Association, 2023
2023
-
[31]
Threatrace: Detecting and tracing host-based threats in node level through provenance graph learning,
S. Wang, Z. Wang, T. Zhou, H. Sun, X. Yin, D. Han, H. Zhang, X. Shi, and J. Yang, “Threatrace: Detecting and tracing host-based threats in node level through provenance graph learning,”IEEE Transactions on Information Forensics and Security, vol. 17, pp. 3972–3987, 2022
2022
-
[32]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” 2019. [Online]. Available: https://arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[33]
Random forests,
L. Breiman, “Random forests,”Mach. Learn., vol. 45, no. 1, pp. 5–32, Oct. 2001
2001
-
[34]
Xgboost: A scalable tree boosting system,
T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’16. New York, NY , USA: Association for Computing Machinery, 2016, pp. 785–794
2016
-
[35]
Lightgbm: a highly efficient gradient boosting decision tree,
G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y . Liu, “Lightgbm: a highly efficient gradient boosting decision tree,” inProceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Red Hook, NY , USA: Curran Associates Inc., 2017, pp. 3149–3157
2017
-
[36]
From local explanations to global understanding with explainable ai for trees,
S. M. Lundberg, G. Erion, H. Chen, A. DeGrave, J. M. Prutkin, B. Nair, R. Katz, J. Himmelfarb, N. Bansal, and S.-I. Lee, “From local explanations to global understanding with explainable ai for trees,”Nature machine intelligence, vol. 2, no. 1, pp. 56–67, 2020
2020
-
[37]
Loganomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs,
W. Meng, Y . Liu, Y . Zhu, S. Zhang, D. Pei, Y . Liu, Y . Chen, R. Zhang, S. Tao, P. Sun, and R. Zhou, “Loganomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs,” in Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI), 2019, pp. 4739–4745
2019
-
[38]
Logllm: Log- based anomaly detection using large language models,
W. Guan, J. Cao, S. Qian, J. Gao, and C. Ouyang, “Logllm: Log- based anomaly detection using large language models,”arXiv preprint arXiv:2411.08561, 2024
-
[39]
Deepcase: Semi-supervised contextual analysis of security events,
T. van Ede, H. Aghakhani, N. Spahn, R. Bortolameotti, M. Cova, A. Continella, M. van Steen, A. Peter, C. Kruegel, and G. Vigna, “Deepcase: Semi-supervised contextual analysis of security events,” inProceedings of the IEEE Symposium on Security and Privacy (SP). IEEE, 2022
2022
-
[40]
Log clustering based problem identification for online service systems,
Q. Lin, H. Zhang, J.-G. Lou, Y . Zhang, and X. Chen, “Log clustering based problem identification for online service systems,” inProceed- ings of the 38th International Conference on Software Engineering (ICSE). ACM, 2016, pp. 102–111
2016
-
[41]
Deepead: Explainable anomaly detection from system logs,
X. Wang, K. J. Kim, Y . Wang, T. Koike-Akino, and K. Parsons, “Deepead: Explainable anomaly detection from system logs,” inICC 2023 - IEEE International Conference on Communications, 2023, pp. 771–776
2023
-
[42]
This looks like that: deep learning for interpretable image recognition,
C. Chen, O. Li, D. Tao, A. Barnett, C. Rudin, and J. K. Su, “This looks like that: deep learning for interpretable image recognition,” Advances in neural information processing systems, vol. 32, 2019
2019
-
[43]
Understanding black-box predictions via influence functions,
P. W. Koh and P. Liang, “Understanding black-box predictions via influence functions,” inProceedings of the 34th International Con- ference on Machine Learning - Volume 70, ser. ICML’17. JMLR.org, 2017, pp. 1885–1894
2017
-
[44]
A comprehensive study of machine learning techniques for log-based anomaly detection,
S. Ali, C. Boufaied, D. Bianculli, P. Branco, and L. Briand, “A comprehensive study of machine learning techniques for log-based anomaly detection,”Empirical Software Engineering, vol. 30, no. 5, p. 129, 2025. Appendix A. Canonicalization and Template Determination NLLog applies a fixed sequence of regular-expression substitutions, following prior log-ana...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.