Imbuing Large Language Models with Bidirectional Logic for Robust Chain Repair
Pith reviewed 2026-06-28 05:44 UTC · model grok-4.3
The pith
TRI endows decoder-only LLMs with goal-conditioned infilling to repair erroneous segments in reasoning chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
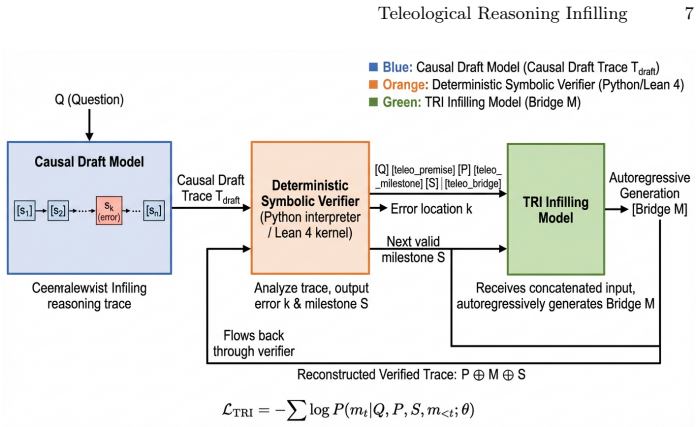
By training on Prefix-Suffix-Middle sequences extracted from verified (P, S, M) triples and optimizing with a deterministic symbolic verifier as the sole reward signal, decoder-only transformers acquire the ability to synthesize logically sound bridges that connect a verified premise to a verified milestone, allowing surgical correction of reasoning chains without full regeneration.
What carries the argument
Prefix-Suffix-Middle (PSM) sequence rearrangement with three non-overlapping sentinel tokens that lets the middle infill attend to both the verified prefix and the verified suffix inside a standard causal self-attention stack.
If this is right
- Only the damaged segment is regenerated while verified sections remain untouched.
- Token consumption per problem drops by 31.2 percent on the tested benchmarks.
- No LLM judge is required because the symbolic verifier supplies the sole reward signal.
- State-of-the-art results are reported across all three evaluated benchmarks.
Where Pith is reading between the lines
- The same PSM rearrangement could be tested on non-mathematical domains if reliable external verifiers for those domains become available.
- The method might be combined with other inference-time techniques such as self-consistency or tree search to further reduce error rates.
- Extending the two-stage training to additional formal systems beyond Lean 4 and Python could broaden applicability.
Load-bearing premise
A deterministic symbolic verifier can always locate every error and confirm that the generated bridge is sound without introducing new mistakes or false negatives.
What would settle it
A concrete counter-example in which an infilled bridge passes the Lean 4 or Python verifier yet produces an incorrect final answer, or in which the verifier fails to flag a genuine error in the original chain.
Figures

read the original abstract
Autoregressive chain-of-thought (CoT) reasoning in large language models (LLMs) is fundamentally forward-directed: each step conditions only on prior tokens. This unidirectional inductive bias renders even capable models susceptible to error snowballing, wherein a single logical or arithmetic mistake in an early step irreversibly corrupts the entire reasoning chain. We introduce Teleological Reasoning Infilling (\TRI{}), a training framework that endows decoder-only transformers with a native \emph{goal-conditioned bridging} capability. The key insight is to reframe erroneous reasoning segments as fill-in-the-middle (FIM) tasks: given a verified prefix premise $P$, a verified downstream milestone $S$, and the original query $Q$, the model must synthesise the logical bridge $M$ that connects $P$ to $S$ rigorously and completely. To achieve this with standard causal architectures, we introduce a Prefix-Suffix-Middle (PSM) sequence rearrangement with three non-overlapping sentinel tokens, enabling $M$ to attend to both $P$ and $S$ without any structural modification to the self-attention mechanism. Training proceeds in two stages: (i) Supervised Fine-Tuning (SFT) on symbolically verified $(P, S, M)$ triples extracted from formal mathematics corpora, and (ii) Direct Preference Optimisation (DPO) with a deterministic symbolic verifier (Lean 4 / Python) as the sole reward oracle, eliminating LLM-judge sycophancy. At inference, TRI operates as a surgical repair module within a dual-system loop: a causal draft model generates an initial trace, the verifier pinpoints failures, and TRI infills only the damaged segment, leaving verified sections intact. Comprehensive experiments on three benchmarks demonstrate that TRI achieves state-of-the-art performance across all tasks, while reducing per-problem token expenditure by 31.2%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Teleological Reasoning Infilling (TRI), a framework that trains decoder-only LLMs to perform goal-conditioned infilling for repairing errors in autoregressive chain-of-thought reasoning. By rearranging sequences into Prefix-Suffix-Middle format with sentinel tokens, the model learns to generate logical bridges M between verified premise P and milestone S. Training uses SFT on verified (P,S,M) triples from formal corpora followed by DPO using a symbolic verifier (Lean 4/Python) as reward oracle. At inference, a dual-system loop uses the verifier to detect failures and TRI to infill only damaged segments. The paper reports SOTA results on three benchmarks with 31.2% reduction in token expenditure.
Significance. If the results hold, the work offers a promising direction for mitigating error propagation in LLM reasoning by leveraging bidirectional context without architectural changes. The use of an external deterministic verifier for both reward and detection is a strength, as it avoids circular LLM-based judgments. This could have implications for reliable automated theorem proving and multi-step reasoning tasks. The parameter-free nature of the verifier-based training is also noteworthy.
major comments (2)
- [Abstract] Abstract: The abstract asserts SOTA performance across all tasks and a 31.2% token reduction, but provides no information on the three benchmarks, comparison baselines, statistical tests, or verification that gains survive verifier limitations, undermining the ability to assess the central claims.
- [Inference-time repair description] Inference-time repair description: The claim that the verifier 'pinpoints failures' and confirms the infilled bridge is 'logically sound' is load-bearing for the dual-system loop and token savings; however, no measurements of verifier recall, false-negative rates on test distributions, or handling of non-formalizable CoT errors are reported, leaving the robustness of the repair mechanism unverified.
minor comments (1)
- [Methods] The PSM sequence rearrangement is described but the exact placement of sentinel tokens and how they interact with the causal mask could be clarified with an example sequence.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for improving the clarity and robustness of our claims. Below, we provide point-by-point responses to the major comments and outline the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts SOTA performance across all tasks and a 31.2% token reduction, but provides no information on the three benchmarks, comparison baselines, statistical tests, or verification that gains survive verifier limitations, undermining the ability to assess the central claims.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to evaluate the central claims. In the revised manuscript we will expand the abstract to name the three benchmarks, identify the primary baselines, reference the statistical tests used to establish significance, and note how the reported gains remain consistent under the documented constraints of the symbolic verifier. revision: yes
-
Referee: [Inference-time repair description] Inference-time repair description: The claim that the verifier 'pinpoints failures' and confirms the infilled bridge is 'logically sound' is load-bearing for the dual-system loop and token savings; however, no measurements of verifier recall, false-negative rates on test distributions, or handling of non-formalizable CoT errors are reported, leaving the robustness of the repair mechanism unverified.
Authors: The referee correctly notes the absence of explicit verifier performance metrics. While the verifier is deterministic on formalizable statements, we did not report recall or false-negative rates on the test distributions nor a systematic treatment of non-formalizable CoT errors. We will add a new subsection that discusses the verifier's scope and limitations, incorporates any empirical observations already available from our experiments, and clarifies how non-formalizable errors are currently handled or flagged. revision: partial
Circularity Check
No significant circularity; external verifier supplies independent signal
full rationale
The TRI framework's core training and inference loop uses a deterministic symbolic verifier (Lean 4 / Python) as the sole reward oracle for DPO and as the failure detector for segment isolation. This verifier operates outside the LLM and is not derived from or fitted to the model's own outputs, satisfying the criterion for independent evidence. No equations, self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the manuscript text. The SOTA performance and token-reduction claims rest on external benchmark experiments rather than any internal reduction of the target result to its own inputs by construction. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decoder-only transformers with causal attention can still attend bidirectionally to non-overlapping prefix and suffix segments when special sentinel tokens are inserted.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint (2022)
Bavarian, M., Jun, H., Tezak, N., Schulman, J., McLeavey, C., Tworek, J., Chen, M.: Efficient training of language models to fill in the middle. arXiv preprint (2022)
2022
-
[2]
AAAI38(2024), https://arxiv.org/abs/2308.09687
Besta, M., Blach, N., Kubicek, A., Gerstenberger, R., Podstawski, M., Gianinazzi, L., Gajda, J., Lehmann, T., Niewiadomski, H., Nyczyk, P., Hoefler, T.: Graph of thoughts: Solving elaborate problems with large language models. AAAI38(2024), https://arxiv.org/abs/2308.09687
arXiv 2024
-
[3]
arXiv preprint (2021)
Chen, M., Tworek, J., others.: Evaluating large language models trained on code. arXiv preprint (2021)
2021
-
[4]
Dao,T.,Fu,D.Y.,Ermon,S.,Rudra,A.,Ré,C.:FlashAttention:Fastandmemory- efficient exact attention with IO-awareness. NeurIPS35(2022),https://arxiv. org/abs/2205.14135
Pith/arXiv arXiv 2022
-
[5]
arXiv preprint (2025)
DeepSeek-AI: DeepSeek-R1: Incentivizing reasoning capability in LLMs via rein- forcement learning. arXiv preprint (2025)
2025
-
[6]
arXiv preprint (2024)
Dubey, A., Jauhri, A., Pandey, A., et al.: The Llama 3 herd of models. arXiv preprint (2024)
2024
-
[7]
arXiv preprint (2025)
Hammoud, H.A.A.K., Itani, H., Ghanem, B.: Beyond the last answer: Your rea- soning trace uncovers more than you think. arXiv preprint (2025)
2025
-
[8]
arXiv preprint (2023)
Hao, S., Gu, Y., Ma, H., Hong, J., Wang, Z., Wang, D.Z., Hu, Z.: Reasoning with language model is planning with world model. arXiv preprint (2023)
2023
-
[9]
NeurIPS34(2021),https://arxiv.org/abs/2103.03874
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the MATH dataset. NeurIPS34(2021),https://arxiv.org/abs/2103.03874
Pith/arXiv arXiv 2021
-
[10]
arXiv preprint (2024)
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., et al.: OpenAI o1 technical report. arXiv preprint (2024)
2024
-
[11]
arXiv preprint (2024)
Kamoi, R., Zhang, Y., Zhang, N., Han, J., Zhang, R.: LLMs cannot find reasoning errors, but can correct them given the error location. arXiv preprint (2024)
2024
-
[12]
NeurIPS35, 22199–22213 (2022),https://arxiv.org/ abs/2205.11916
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. NeurIPS35, 22199–22213 (2022),https://arxiv.org/ abs/2205.11916
Pith/arXiv arXiv 2022
-
[13]
arXiv preprint (2024)
Kumar, A., Zhuang, V., Agarwal, R., Su, Y., Welling, M., Flennerhag, S., et al.: Training language models to self-correct via reinforcement learning. arXiv preprint (2024)
2024
-
[14]
ICLR (2024), https://arxiv.org/abs/2305.20050
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., Cobbe, K.: Let’s verify step by step. ICLR (2024), https://arxiv.org/abs/2305.20050
Pith/arXiv arXiv 2024
-
[15]
ICLR (2019), https://arxiv.org/abs/1711.05101
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. ICLR (2019), https://arxiv.org/abs/1711.05101
Pith/arXiv arXiv 2019
-
[16]
NeurIPS 35, 27730–27744 (2022),https://arxiv.org/abs/2203.02155 16 Z
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P.F., Leike, J., Lowe, R.: Training language models to follow instructions with human feedback. NeurIPS 35, 27730–27744 (2022),https://arx...
Pith/arXiv arXiv 2022
-
[17]
Springer (2024).https://doi.org/10.1007/ 978-3-031-38971-9_847-1
Perasso, G.: Teleological Reasoning. Springer (2024).https://doi.org/10.1007/ 978-3-031-38971-9_847-1
2024
-
[18]
Journal of Machine Learning Research22(75), 1–35 (2021),https://jmlr.org/papers/v22/ 20-302.html
Pérez, J., Barceló, P., Marinkovic, J.: Attention is Turing-Complete. Journal of Machine Learning Research22(75), 1–35 (2021),https://jmlr.org/papers/v22/ 20-302.html
2021
-
[19]
NeurIPS 36(2023),https://arxiv.org/abs/2305.18290
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. NeurIPS 36(2023),https://arxiv.org/abs/2305.18290
Pith/arXiv arXiv 2023
-
[20]
Sang, Y.: AutoCrit: A meta-reasoning framework for self-critique and iterative error correction in LLM chains-of-thought (2025).https://doi.org/10.1109/ icmlca66850.2025.11336788
arXiv 2025
-
[21]
arXiv preprint (2024)
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y.K., Wu, Y., Guo, D.: DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint (2024)
2024
-
[22]
arXiv preprint (2024)
Snell, C., Lee, J., Xu, K., Kumar, A.: Scaling LLM test-time compute optimally can be more effective than scaling model parameters. arXiv preprint (2024)
2024
-
[23]
arXiv preprint (2024)
Team, Q.: Qwen2.5: A party of foundation models. arXiv preprint (2024)
2024
-
[24]
Trinh, T.H., Wu, Y., Le, Q.V., He, H., Luong, T.: Solving olympiad geometry without human demonstrations. Nature625, 476–482 (2024).https://doi.org/ 10.1038/s41586-023-06747-5
-
[25]
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. NeurIPS30(2017),https://arxiv. org/abs/1706.03762
Pith/arXiv arXiv 2017
-
[26]
ICLR (2023),https://arxiv.org/abs/2203.11171
Wang, X., Wei, J., Schuurmans, D., Le, Q.V., Chi, E.H., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. ICLR (2023),https://arxiv.org/abs/2203.11171
Pith/arXiv arXiv 2023
-
[27]
NeurIPS35, 24824–24837 (2022),https://arxiv.org/abs/2201.11903
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E.H., Le, Q.V., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models. NeurIPS35, 24824–24837 (2022),https://arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2022
-
[28]
5-stepprover: Advancing automated theorem proving via critic-guided search
Wu, Z., Huang, S., Zhou, Z., Ying, H., Yuan, Z., Zhang, W., Lin, D., Chen, K.: Internlm2. 5-stepprover: Advancing automated theorem proving via critic-guided search. arXiv preprint arXiv:2410.15700 (2024)
arXiv 2024
-
[29]
arXiv preprint (2025)
Xu, H., Yan, Y., Shen, Y., Zhang, W., Hou, G., Jiang, S.: Mind the gap: Bridging thought leap for improved chain-of-thought tuning. arXiv preprint (2025)
2025
-
[30]
arXiv preprint (2025)
Xu, Y., Zheng, Y., Sun, S., Huang, S., Dong, B., Zhu, H., Huang, R., Yu, G., Xu, H., Wu, J.: Reason from future: Reverse thought chain enhances LLM reasoning. arXiv preprint (2025)
2025
-
[31]
In: ICLR (2025),https: //openreview.net/forum?id=14i2wzPPfn
Yan, Y., Luo, C., et al.: MathFimer: Enhancing mathematical reasoning by ex- panding reasoning steps through fill-in-the-middle task. In: ICLR (2025),https: //openreview.net/forum?id=14i2wzPPfn
2025
-
[32]
NeurIPS 36(2023),https://arxiv.org/abs/2305.10601
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T.L., Cao, Y., Narasimhan, K.: Tree of thoughts: Deliberate problem solving with large language models. NeurIPS 36(2023),https://arxiv.org/abs/2305.10601
Pith/arXiv arXiv 2023
-
[33]
arXiv preprint (2024)
Ying,H.,Li,Z.,He,Y.,etal.:LeanWorkbook:AlargeLeanproblemsetformalized from natural language math problems. arXiv preprint (2024)
2024
-
[34]
Yun, C., Bhojanapalli, S., Rawat, A.S., Reddi, S.J., Kumar, S.: Are transform- ers universal approximators of sequence-to-sequence functions? In: ICLR (2020), https://arxiv.org/abs/1912.10077
arXiv 2020
-
[35]
Gap span≤1step
Zhang, T., et al.: Achieving >97% on GSM8K: Deeply understanding the problems makes LLMs better solvers for math word problems. arXiv preprint (2024) Teleological Reasoning Infilling 17 A Theoretical Analysis This appendix provides formal theoretical analysis of theTRIframework. We prove the centralTopological Consistencyproperty of the PSM training ob- j...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.