Self-Reflective APIs: Structure Beats Verbosity for AI Agent Recovery
Pith reviewed 2026-06-28 05:06 UTC · model grok-4.3
The pith
Structured recovery suggestions in APIs raise AI agent task completion by 37-40 points over plain English error messages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
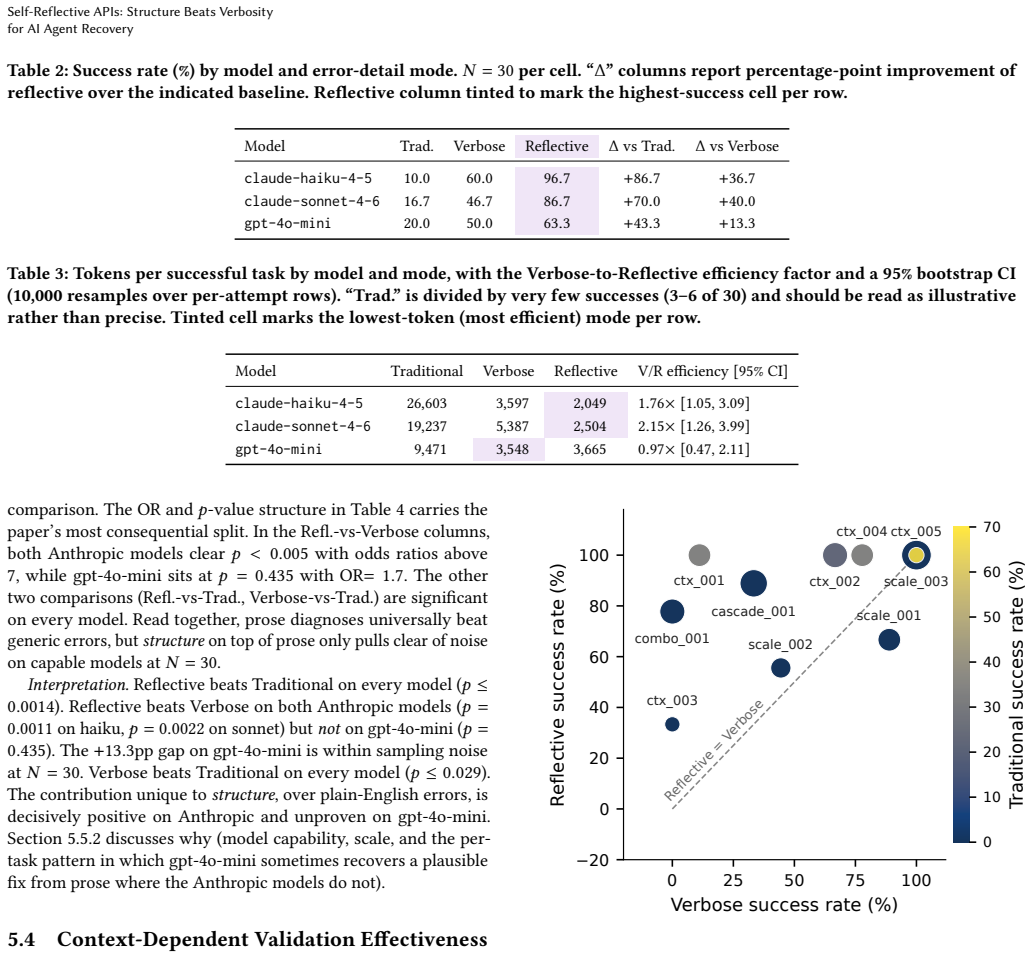
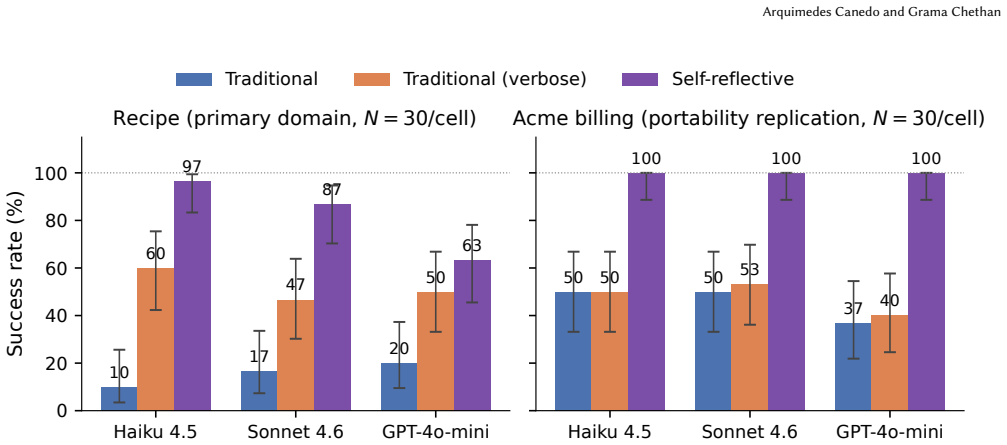
A self-reflective API returns, on validation failure, a machine-readable recovery_feedback.suggestions[] payload sufficient for the agent to repair the request and retry without external reasoning. Structured suggestions lift task-completion rate by +36.7--40.0pp over plain-English diagnoses on Anthropic models at 1.8--2.2× better per-success token efficiency, with the comparison holding only after auditing two undocumented classes of answer leakage.
What carries the argument
recovery_feedback.suggestions[] payload: a machine-readable list of repair instructions returned on validation error that lets the agent fix the call directly.
If this is right
- Agents using structured feedback complete more tasks without additional external reasoning.
- Token cost per successful task drops by a factor of roughly two.
- The advantage appears only after explicit checks for benchmark leakage.
- The pattern replicates across at least two API domains.
Where Pith is reading between the lines
- API designers could adopt a standard recovery payload format so agents treat errors as data rather than text to interpret.
- The approach may reduce reliance on long reasoning chains inside agents when handling routine validation failures.
- Leakage auditing tools released with the work could become routine for any benchmark that measures agent performance on public APIs.
Load-bearing premise
The experimental tasks and leakage audit are sufficient to isolate the effect of structured versus plain-English feedback without residual confounding from model training data or task selection.
What would settle it
A new set of adversarial tasks, after identical leakage auditing, shows no statistically significant difference in completion rates between structured suggestions and plain-English diagnoses on the same models.
Figures

read the original abstract
When an AI agent calls an API and hits a validation error, it needs more than what went wrong -- it needs what to do next. A self-reflective API returns, on validation failure, a machine-readable recovery\_feedback.suggestions[] payload sufficient for the agent to repair the request and retry without external reasoning. On a leak-audited pilot ($N{=}30$ per cell, 3 LLMs, 10 adversarial tasks), structured suggestions lift task-completion rate by $+36.7$--$40.0$pp over plain-English diagnoses on Anthropic models (Fisher's exact $p \le 0.0022$), at $1.8$--$2.2\times$ better per-success token efficiency. The lift is not significant on gpt-4o-mini ($p{=}0.435$); a second-domain replication on a billing API confirms the pattern. The comparison only holds after auditing two undocumented classes of answer leakage in LLM benchmarks. We shipaudit\_prompt\_leakage.py as reusable CI infrastructure. Code and data: https://github.com/arquicanedo/self-reflective-apis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes self-reflective APIs that return a machine-readable recovery_feedback.suggestions[] payload on validation errors, enabling AI agents to repair and retry requests without external reasoning. On a leak-audited pilot (N=30 per cell, 3 LLMs, 10 adversarial tasks), structured suggestions improve task-completion rates by +36.7–40.0pp over plain-English diagnoses on Anthropic models (Fisher's exact p ≤ 0.0022) with 1.8–2.2× better per-success token efficiency; the lift is not significant on gpt-4o-mini (p=0.435). A second-domain replication on a billing API confirms the pattern. The authors release audit_prompt_leakage.py and code/data for reproducibility.
Significance. If the experimental comparison isolates the effect of machine-readable structure from information content, the result would have practical value for API design in agentic LLM systems by reducing recovery overhead. The release of reusable leakage-audit infrastructure and full code/data is a clear strength supporting verification.
major comments (1)
- [Abstract] Abstract: The central claim attributes the +36.7–40.0pp lift to 'structured suggestions' versus 'plain-English diagnoses'. However, the abstract explicitly contrasts recovery_feedback.suggestions[] 'sufficient for the agent to repair' (actionable next steps) with 'plain-English diagnoses (standard error explanations of what went wrong)'. If the plain-English condition omits the recovery suggestions, the observed difference reflects presence of actionable content rather than structure versus equivalent verbosity. This design choice is load-bearing for the title claim 'Structure Beats Verbosity' and for interpreting the efficiency ratios.
minor comments (2)
- [Abstract] The abstract states N=30 per cell but does not report the exact number of trials per model-task combination or whether the same tasks were used across all LLMs.
- [Abstract] The leakage audit is described as covering 'two undocumented classes of answer leakage'; the manuscript should explicitly list those classes and the criteria used to classify them.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting this important distinction in the abstract. We address the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the +36.7–40.0pp lift to 'structured suggestions' versus 'plain-English diagnoses'. However, the abstract explicitly contrasts recovery_feedback.suggestions[] 'sufficient for the agent to repair' (actionable next steps) with 'plain-English diagnoses (standard error explanations of what went wrong)'. If the plain-English condition omits the recovery suggestions, the observed difference reflects presence of actionable content rather than structure versus equivalent verbosity. This design choice is load-bearing for the title claim 'Structure Beats Verbosity' and for interpreting the efficiency ratios.
Authors: We agree that the plain-English baseline uses standard error explanations of what went wrong and does not include explicit recovery suggestions, while the structured condition supplies actionable next steps in machine-readable form. The performance difference therefore reflects both the addition of recovery content and its structured presentation. The core claim of the work is that machine-readable structure enables agents to consume and apply recovery information directly, without external reasoning steps that would otherwise be needed to interpret equivalent natural-language guidance. This is what produces the measured token-efficiency gains. We will revise the abstract to describe the conditions more precisely as 'standard error messages' versus 'structured recovery suggestions' and will add a clarifying sentence in the discussion section explaining that the efficiency advantage arises because structure makes the actionable content directly usable rather than requiring the agent to generate its own repair plan from a diagnosis. We do not believe the title requires change, as the contribution centers on structure enabling concise, machine-actionable recovery versus unstructured English alternatives. revision: yes
Circularity Check
No significant circularity; empirical measurements only
full rationale
The paper reports direct experimental results on task-completion rates and token efficiency from controlled comparisons across LLMs and tasks. No derivation chain, equations, fitted parameters presented as predictions, or self-citation load-bearing steps exist. The leakage audit is a methodological control, not a reduction of the outcome to its inputs. Results are measured outcomes, not constructed by definition or renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://spec.graphql.org/, 2021
GraphQL Foundation.GraphQL Specification. https://spec.graphql.org/, 2021
2021
-
[2]
https://jsonapi.org/, 2023
JSON:API.A Specification for Building APIs in JSON. https://jsonapi.org/, 2023
2023
-
[3]
Nottingham and E
M. Nottingham and E. Wilde.Problem Details for HTTP APIs. RFC 7807, IETF, March 2016
2016
-
[4]
Alvaro et al
P. Alvaro et al. Abstracting the Geniuses Away from Failure Testing.Communi- cations of the ACM, 64(9):58–67, 2021
2021
-
[5]
Binkley et al
D. Binkley et al. API Usage Pattern Recommendation for Software Development. IEEE Transactions on Software Engineering, 45(6):582–598, 2019
2019
-
[6]
Ramaswamy et al.LangChain: Building Applications with LLMs through Com- posability
S. Ramaswamy et al.LangChain: Building Applications with LLMs through Com- posability. https://github.com/langchain-ai/langchain, 2023
2023
-
[7]
Liu.LlamaIndex: A Data Framework for LLM Applications
J. Liu.LlamaIndex: A Data Framework for LLM Applications. https://github.com/ run-llama/llama_index, 2023
2023
-
[8]
Brown et al
T. Brown et al. Language Models are Few-Shot Learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[9]
Wei et al
J. Wei et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.Advances in Neural Information Processing Systems, 35, 2022
2022
-
[10]
Yao et al
S. Yao et al. ReAct: Synergizing Reasoning and Acting in Language Models. International Conference on Learning Representations (ICLR), 2023
2023
-
[11]
Reflexion: Language Agents with Verbal Reinforcement Learning
N. Shinn et al. Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv preprint arXiv:2303.11366, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Schroeder et al
C. Schroeder et al. Self-Healing Systems: A Review.ACM Computing Surveys, 42(2):1–35, 2010
2010
-
[13]
Fielding.Architectural Styles and the Design of Network-based Software Archi- tectures
R. Fielding.Architectural Styles and the Design of Network-based Software Archi- tectures. PhD thesis, University of California, Irvine, 2000
2000
-
[14]
S. Vinoski. RESTful Web Services Development Checklist.IEEE Internet Comput- ing, 12(6):95–96, 2008
2008
-
[15]
Richardson and M
L. Richardson and M. Amundsen.RESTful Web APIs: Services for a Changing World. O’Reilly Media, 2013
2013
-
[16]
Function calling and the Chat Completions API
OpenAI. Function calling and the Chat Completions API. Technical documenta- tion, 2023–2024
2023
-
[17]
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez. Gorilla: Large Language Model Connected with Massive APIs.arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Schick et al
T. Schick et al. Toolformer: Language Models Can Teach Themselves to Use Tools.Advances in Neural Information Processing Systems, 36, 2023. 12
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.