Geographic Bias and Diversity in AI Evaluation
Pith reviewed 2026-07-01 08:42 UTC · model grok-4.3
The pith
Generative AI tends to over-proportionally favor prototypical places called defaults.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors state that geographic biases in AI include representation bias in training data, regional disparities in factual recall, and the tendency of generative AI to over-proportionally favor prototypical places (called defaults). They show that recent studies address the latter by evaluating geographic diversity across cognitive levels, parameter settings, and output modalities.
What carries the argument
The notion of defaults—prototypical places that generative models select disproportionately—together with evaluation methods that vary cognitive levels, parameter settings, and output modalities to test for geographic diversity.
If this is right
- AI systems used for biodiversity or disaster mitigation may systematically under-represent or distort non-default locations.
- Benchmarks for geographic unbiasedness must incorporate tests across multiple cognitive levels and output modalities.
- Training data imbalances directly contribute to factual recall gaps and default favoritism in model outputs.
- Parameter changes and modality shifts can be used as levers to increase measured geographic diversity.
Where Pith is reading between the lines
- Developers could run controlled prompts on underrepresented regions to measure the strength of default bias in specific models.
- Audits for AI deployed in global decision systems might require explicit geographic coverage metrics.
- Altering the spatial distribution of training examples could reduce default favoritism without changing model architecture.
Load-bearing premise
The body of literature reviewed provides a comprehensive and representative picture of geographic bias issues across pre-generative and generative AI periods.
What would settle it
An empirical test in which generative models, when prompted across many regions and modalities with controlled parameters, produce outputs whose geographic distribution matches real-world population or feature distributions at rates statistically indistinguishable from chance.
Figures


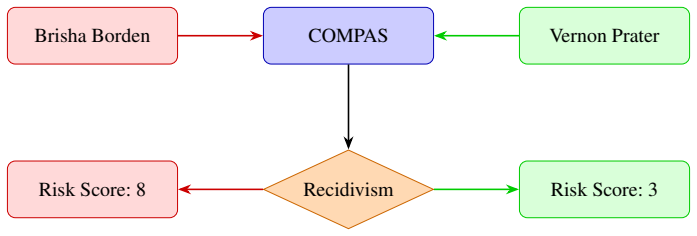
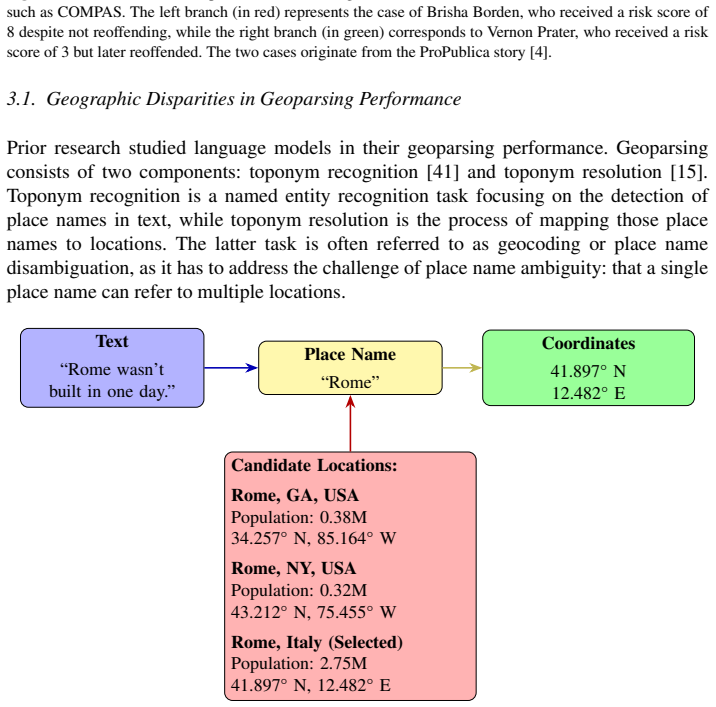




read the original abstract
Among the many challenges hindering the responsible development and deployment of AI, arguably none has faced more intense scrutiny than bias in its various forms. This underscores the widespread concerns across AI researchers that model outputs, e.g., from generative AI, may encode structural distributional imbalances (stemming from training data or model design) that may amplify social inequality or introduce systemic distortions across application domains ranging from biodiversity to disaster mitigation. Yet, relatively little work has investigated the geographical nature of bias or developed measurable benchmarks for what it means for (generative) AI to be unbiased. In this chapter, we investigate this issue through a literature review. As foundation models are reshaping the landscape of bias research, we examine work spanning both the pre-generative AI and generative AI periods. First, we identify a range of geographic biases. These biases span from representation bias in the training data and regional disparities in the factual recall of language models to the tendency of generative AI to over-proportionally favor prototypical places (called defaults). Then, we showcase how recent studies address the latter bias by evaluating geographic diversity in the outputs of generative AI across various cognitive levels, parameter settings, and output modalities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a literature review on geographic bias in AI, spanning pre-generative and generative periods. It identifies biases including representation bias in training data, regional disparities in factual recall by language models, and generative AI's tendency to over-favor prototypical places (termed 'defaults'). It further claims that recent studies evaluate geographic diversity in generative AI outputs across cognitive levels, parameter settings, and output modalities.
Significance. If the reviewed literature is comprehensive and representative, the work would usefully synthesize an under-examined dimension of AI bias and could inform benchmark development for geographic fairness. The absence of any methodological details, however, prevents assessment of whether the synthesis accurately reflects the state of the field.
major comments (2)
- [Abstract] Abstract: The description of the literature review provides no details on search methodology, databases, keywords, inclusion/exclusion criteria, or time spans covered. This is load-bearing for the central claims, which rest entirely on the representativeness of the selected studies (as the skeptic note correctly identifies).
- [Abstract] Abstract: The claim that 'generative AI tends to over-proportionally favor prototypical places' and that 'recent studies evaluate geographic diversity across cognitive levels, parameter settings, and output modalities' is presented as a synthesis result, yet no quantitative information (number of studies per category, explicit selection criteria) is supplied to allow verification or to rule out systematic omission of counter-examples or non-English work.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our literature review. The comments correctly identify a lack of methodological transparency that weakens the manuscript's claims about representativeness. We will revise to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: The description of the literature review provides no details on search methodology, databases, keywords, inclusion/exclusion criteria, or time spans covered. This is load-bearing for the central claims, which rest entirely on the representativeness of the selected studies (as the skeptic note correctly identifies).
Authors: We agree the current abstract and text omit these details, which is a substantive weakness. In revision we will add a dedicated 'Methods' subsection describing the search strategy (databases: Google Scholar, arXiv, ACM; keywords: geographic bias, spatial bias in AI, generative defaults; time span: 2015–2024; inclusion: English-language peer-reviewed and preprint works explicitly addressing geographic dimensions of bias; exclusion: purely technical papers without bias analysis). The abstract will be updated to reference this section. revision: yes
-
Referee: [Abstract] Abstract: The claim that 'generative AI tends to over-proportionally favor prototypical places' and that 'recent studies evaluate geographic diversity across cognitive levels, parameter settings, and output modalities' is presented as a synthesis result, yet no quantitative information (number of studies per category, explicit selection criteria) is supplied to allow verification or to rule out systematic omission of counter-examples or non-English work.
Authors: The manuscript is a narrative rather than systematic review, so quantitative tallies were not originally provided. We will revise by inserting a summary table or paragraph stating the number of studies per bias category and per evaluation dimension, restating the explicit selection criteria, and adding an explicit limitation note on the exclusion of non-English literature. This will make the synthesis claims verifiable without altering their substance. revision: yes
Circularity Check
No circularity: descriptive literature survey with no derivations or self-referential reductions
full rationale
The paper is explicitly a literature review synthesizing prior work on geographic bias in AI across pre-generative and generative periods. It contains no equations, fitted parameters, predictions, or derivation chains. All claims about biases and evaluation studies are presented as summaries of external literature rather than internally derived results. The representativeness of the cited body is an external assumption about coverage, not a reduction of the paper's own logic to its inputs by construction. No self-citation load-bearing steps or other enumerated patterns are present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A learning algorithm for boltzmann machines.Cognitive science, 9(1):147–169, 1985
David H Ackley, Geoffrey E Hinton, and Terrence J Sejnowski. A learning algorithm for boltzmann machines.Cognitive science, 9(1):147–169, 1985
1985
-
[2]
Equal credit opportunity act.Women in the American Political System: An Encyclopedia of Women as Voters, Candidates, and Office Holders, 2:129, 2018
Equal Credit Opportunity Act. Equal credit opportunity act.Women in the American Political System: An Encyclopedia of Women as Voters, Candidates, and Office Holders, 2:129, 2018
2018
-
[3]
Fair housing act.Home Mortgage Disclosure Act, and Community, 1968
Fair Housing Act. Fair housing act.Home Mortgage Disclosure Act, and Community, 1968
1968
-
[4]
Machine bias: Risk assessments in criminal sentencing.ProPublica, May 23, 2016
Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner. Machine bias: Risk assessments in criminal sentencing.ProPublica, May 23, 2016. URL:https://www.propublica.org/article/ machine-bias-risk-assessments-in-criminal-sentencing
2016
-
[5]
What is special about spatial data?: alternative perspectives on spatial data analysis.Technical paper/National Center for Geographic Information and Analysis (89-4), 1989
L Anselin. What is special about spatial data?: alternative perspectives on spatial data analysis.Technical paper/National Center for Geographic Information and Analysis (89-4), 1989
1989
-
[6]
Man is to computer programmer as woman is to homemaker? debiasing word embeddings.Advances in neural information processing systems, 29, 2016
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. Man is to computer programmer as woman is to homemaker? debiasing word embeddings.Advances in neural information processing systems, 29, 2016
2016
-
[7]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[9]
Fairness under unawareness: Assessing disparity when protected class is unobserved
Jiahao Chen, Nathan Kallus, Xiaojie Mao, Geoffry Svacha, and Madeleine Udell. Fairness under unawareness: Assessing disparity when protected class is unobserved. InProceedings of the conference on fairness, accountability, and transparency, pages 339–348, 2019
2019
-
[10]
The openshaw effect.International Journal of Geographical Information Science, 36(9):1697–1698, 2022
Michael F Goodchild. The openshaw effect.International Journal of Geographical Information Science, 36(9):1697–1698, 2022
2022
-
[11]
Replication across space and time must be weak in the social and environmental sciences.Proceedings of the National Academy of Sciences, 118(35):e2015759118, 2021
Michael F Goodchild and Wenwen Li. Replication across space and time must be weak in the social and environmental sciences.Proceedings of the National Academy of Sciences, 118(35):e2015759118, 2021
2021
-
[12]
Diversity and evenness: a unifying notation and its consequences.Ecology, 54(2):427–432, 1973
Mark O Hill. Diversity and evenness: a unifying notation and its consequences.Ecology, 54(2):427–432, 1973
1973
-
[13]
Whose truth? pluralistic geo-alignment for (agentic) ai
Krzysztof Janowicz, Zilong Liu, Gengchen Mai, Zhangyu Wang, Ivan Majic, Alexandra Fortacz, Grant McKenzie, and Song Gao. Whose truth? pluralistic geo-alignment for (agentic) ai. InProceedings of the 33rd ACM International Conference on Advances in Geographic Information Systems, pages 799–803, 2025
2025
-
[14]
Entropy and diversity.Oikos, 113(2):363–375, 2006
Lou Jost. Entropy and diversity.Oikos, 113(2):363–375, 2006
2006
-
[15]
Things and strings: improving place name disambiguation from short texts by combining entity co-occurrence with topic modeling
Yiting Ju, Benjamin Adams, Krzysztof Janowicz, Yingjie Hu, Bo Yan, and Grant McKenzie. Things and strings: improving place name disambiguation from short texts by combining entity co-occurrence with topic modeling. InEuropean Knowledge Acquisition Workshop, pages 353–367. Springer, 2016
2016
-
[16]
Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
2012
-
[17]
Bringing spatial interaction measures into multi-criteria assessment of redistricting plans using interactive web mapping
Jacob Kruse, Song Gao, Yuhan Ji, Daniel P Szabo, and Kenneth R Mayer. Bringing spatial interaction measures into multi-criteria assessment of redistricting plans using interactive web mapping. Cartography and Geographic Information Science, 51(4):513–532, 2024
2024
-
[18]
Measuring diversity: the importance of species similarity
Tom Leinster and Christina A Cobbold. Measuring diversity: the importance of species similarity. Ecology, 93(3):477–489, 2012
2012
-
[19]
Geoparsing: Solved or biased? an evaluation of geographic biases in geoparsing.AGILE: GIScience Series, 3:9, 2022
Zilong Liu, Krzysztof Janowicz, Ling Cai, Rui Zhu, Gengchen Mai, and Meilin Shi. Geoparsing: Solved or biased? an evaluation of geographic biases in geoparsing.AGILE: GIScience Series, 3:9, 2022
2022
-
[20]
Assessing the geographic diversity of ai’s platial representations in image generation
Zilong Liu, Krzysztof Janowicz, and Mina Karimi. Assessing the geographic diversity of ai’s platial representations in image generation. InAGILE: GIScience Series, 2026. Accepted for publication
2026
-
[21]
Golden gate bridge, as always? eliciting prototypical places from autoregressive large language models via category production.Transactions in GIS
Zilong Liu, Krzysztof Janowicz, Mina Karimi, Meilin Shi, Ivan Majic, and Alexandra Fortacz. Golden gate bridge, as always? eliciting prototypical places from autoregressive large language models via category production.Transactions in GIS. Accepted for publication
-
[22]
Operationalizing geographic diversity for the evaluation of ai-generated content
Zilong Liu, Krzysztof Janowicz, Ivan Majic, Meilin Shi, Alexandra Fortacz, Mina Karimi, Gengchen Mai, and Kitty Currier. Operationalizing geographic diversity for the evaluation of ai-generated content. Transactions in GIS, 29(3):e70057, 2025
2025
-
[23]
On the opportunities and challenges of foundation models for geoai (vision paper).ACM Transactions on Spatial Algorithms and Systems, 10(2):1–46, 2024
Gengchen Mai, Weiming Huang, Jin Sun, Suhang Song, Deepak Mishra, Ninghao Liu, Song Gao, Tianming Liu, Gao Cong, Yingjie Hu, et al. On the opportunities and challenges of foundation models for geoai (vision paper).ACM Transactions on Spatial Algorithms and Systems, 10(2):1–46, 2024
2024
-
[24]
Large language models are geographically biased
Rohin Manvi, Samar Khanna, Marshall Burke, David Lobell, and Stefano Ermon. Large language models are geographically biased. InProceedings of the 41st International Conference on Machine Learning, pages 34654–34669, 2024
2024
-
[25]
Geollm: Extracting geospatial knowledge from large language models
Rohin Manvi, Samar Khanna, Gengchen Mai, Marshall Burke, David B Lobell, and Stefano Ermon. Geollm: Extracting geospatial knowledge from large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[26]
A survey on bias and fairness in machine learning.ACM computing surveys (CSUR), 54(6):1–35, 2021
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. A survey on bias and fairness in machine learning.ACM computing surveys (CSUR), 54(6):1–35, 2021
2021
-
[27]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov. Efficient estimation of word representations in vector space.arXiv preprint arXiv:1301.3781, 3781, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
Distributed representations of words and phrases and their compositionality.Advances in neural information processing systems, 26, 2013
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality.Advances in neural information processing systems, 26, 2013
2013
-
[29]
Worldbench: Quantifying geographic disparities in llm factual recall
Mazda Moayeri, Elham Tabassi, and Soheil Feizi. Worldbench: Quantifying geographic disparities in llm factual recall. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 1211–1228, 2024
2024
-
[30]
Notes on continuous stochastic phenomena.Biometrika, 37(1/2):17–23, 1950
Patrick AP Moran. Notes on continuous stochastic phenomena.Biometrika, 37(1/2):17–23, 1950
1950
-
[31]
Social biases through the text-to-image generation lens
Ranjita Naik and Besmira Nushi. Social biases through the text-to-image generation lens. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, pages 786–808, 2023
2023
-
[32]
The modifiable areal unit problem.Concepts and techniques in modern geography, 1984
Stan Openshaw. The modifiable areal unit problem.Concepts and techniques in modern geography, 1984
1984
-
[33]
Fabio Petroni, Tim Rockt ¨aschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. Language models as knowledge bases? InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2463–2473, 2019
2019
-
[34]
Ai’s regimes of representation: A community-centered study of text-to-image models in south asia
Rida Qadri, Renee Shelby, Cynthia L Bennett, and Remi Denton. Ai’s regimes of representation: A community-centered study of text-to-image models in south asia. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pages 506–517, 2023
2023
-
[35]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115:211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115:211–252, 2015
2015
-
[36]
Shreya Shankar, Yoni Halpern, Eric Breck, James Atwood, Jimbo Wilson, and D Sculley. No classification without representation: Assessing geodiversity issues in open data sets for the developing world.arXiv preprint arXiv:1711.08536, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
A mathematical theory of communication.ACM SIGMOBILE mobile computing and communications review, 5(1):3–55, 2001
Claude Elwood Shannon. A mathematical theory of communication.ACM SIGMOBILE mobile computing and communications review, 5(1):3–55, 2001
2001
-
[38]
Measurement of diversity.Nature, 163, 1949
EH Simpson. Measurement of diversity.Nature, 163, 1949
1949
-
[39]
A Roadmap to Pluralistic Alignment
Taylor Sorensen, Jared Moore, Jillian Fisher, Mitchell Gordon, Niloofar Mireshghallah, Christo- pher Michael Rytting, Andre Ye, Liwei Jiang, Ximing Lu, Nouha Dziri, et al. A roadmap to pluralistic alignment.arXiv preprint arXiv:2402.05070, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
A framework for understanding sources of harm throughout the machine learning life cycle
Harini Suresh and John Guttag. A framework for understanding sources of harm throughout the machine learning life cycle. InProceedings of the 1st ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization, pages 1–9, 2021
2021
-
[41]
Jimin Wang, Yingjie Hu, and Kenneth Joseph. Neurotpr: A neuro-net toponym recognition model for extracting locations from social media messages.Transactions in GIS, 24(3):719–735, 2020.doi: 10.1111/tgis.12627
-
[42]
Torchspatial: A location encoding framework and benchmark for spatial representation learning
Nemin Wu, Qian Cao, Zhangyu Wang, Zeping Liu, Yanlin Qi, Jielu Zhang, Joshua Ni, Xiaobai Yao, Hongxu Ma, Lan Mu, Stefano Ermon, Tanuja Ganu, Akshay Nambi, Ni Lao, and Gengchen Mai. Torchspatial: A location encoding framework and benchmark for spatial representation learning. Advances in Neural Information Processing Systems, 37:81437–81460, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.