LeanMarathon: Toward Reliable AI Co-Mathematicians through Long-Horizon Lean Autoformalization
Pith reviewed 2026-06-28 05:46 UTC · model grok-4.3
The pith
Reliable AI co-mathematics in Lean requires durable multi-agent harnesses to preserve target fidelity across long developments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
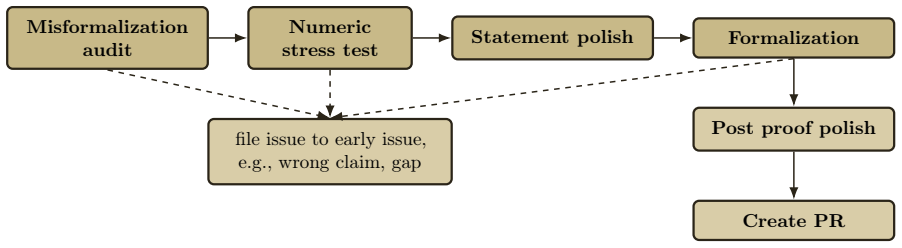
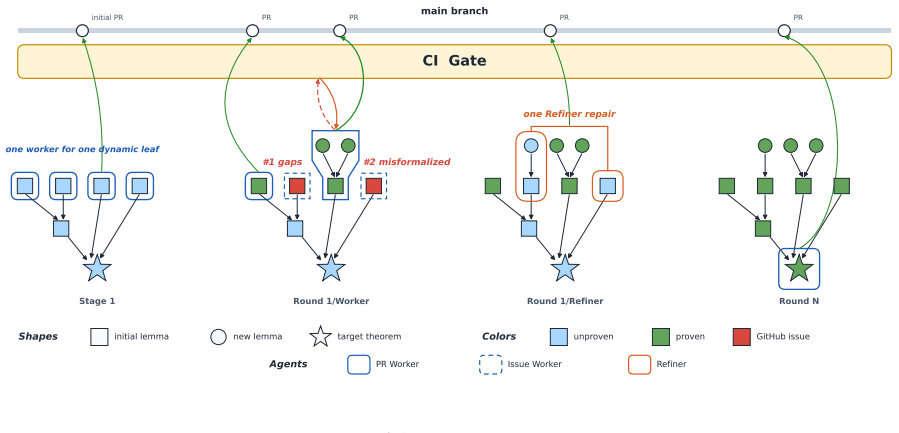
LeanMarathon demonstrates that reliable research-level autoformalization in Lean is achieved by an evolving blueprint maintained through four contract-scoped agents and a two-stage orchestrator. The orchestrator first stabilizes target fidelity via adversarial review, then discharges the proof DAG upward from dynamic leaves in parallel rounds. This converts one brittle multi-hour execution into many local, recoverable transactions. On two source papers spanning four Erdős problems, three autonomous runs formalize all seven targets without sorry, proving 258 lemmas and theorems in total.
What carries the argument
The evolving blueprint, a single Lean file that simultaneously serves as formal proof skeleton, natural-language proof graph, and shared system of record, orchestrated by four contract-scoped agents and a two-stage process that stabilizes fidelity before parallel proof discharge.
If this is right
- Brittle single-run formalizations become sequences of local, recoverable, parallel transactions.
- Target fidelity is preserved through adversarial review before any proof work begins.
- Proof DAGs can be discharged upward from leaves in CI-gated parallel rounds.
- Research papers containing multiple interdependent theorems can be fully formalized without residual sorry placeholders.
Where Pith is reading between the lines
- The same blueprint-plus-orchestrator pattern could be tested on other interactive theorem provers to check whether the coordination benefits transfer beyond Lean.
- Extending the adversarial review stage with automated consistency checks against the original natural-language text might further reduce drift in even longer developments.
- The approach separates the problem of maintaining global structure from the problem of finding individual proofs, suggesting that future gains may come from better orchestration rather than solely stronger individual provers.
Load-bearing premise
The four contract-scoped agents coordinated by the two-stage orchestrator can prevent statement drift, dependency tangling, context decay, and corruption from local repairs during long-horizon developments.
What would settle it
A development run in which the blueprint and agents allow measurable statement drift or an unprovable target to appear despite the described coordination, resulting in at least one sorry or incorrect formalization.
Figures





read the original abstract
Long-horizon autoformalization of research mathematics fails not only at hard lemmas, but at scale: statements drift, dependencies tangle, context decays, and local repairs corrupt distant work. We present LeanMarathon, a multi-agent harness for reliable research-level Lean autoformalization. Its core abstraction is an evolving blueprint: a Lean file that serves simultaneously as formal proof skeleton, natural-language proof graph, and shared system of record. Four contract-scoped agents construct, audit, prove, and repair this blueprint. These agents are coordinated by a two-stage orchestrator that first stabilizes target fidelity through adversarial review and then discharges the proof directed acyclic graph (DAG) from its dynamic leaves upward in parallel CI-gated rounds. LeanMarathon turns one brittle multi-hour run into many local, recoverable, parallel transactions. We evaluate LeanMarathon on two recent research papers spanning four Erd\H{o}s problems (#1051, #1196, #164, #1217). Across three autonomous runs, it formalizes all seven target theorems with no sorry, proving 258 lemmas and theorems. These results show that reliable AI co-mathematics requires not only stronger provers, but durable harnesses that preserve target fidelity across long mathematical developments. The code can be found at https://github.com/YuanheZ/LeanMarathon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents LeanMarathon, a multi-agent system for long-horizon Lean autoformalization. Its core is an evolving blueprint serving as proof skeleton and shared record, with four contract-scoped agents (construct, audit, prove, repair) coordinated by a two-stage orchestrator that stabilizes target fidelity via adversarial review and then discharges the proof DAG in parallel CI-gated rounds. Evaluation on four Erdős problems (#1051, #1196, #164, #1217) from two recent papers yields successful formalization of all seven target theorems (258 lemmas/theorems proved, zero sorry) across three autonomous runs. The code is released at https://github.com/YuanheZ/LeanMarathon.
Significance. If the central attribution holds, the work would establish that system-level harnesses (blueprint + contract agents + two-stage orchestration) can preserve fidelity over long developments where direct LLM/prover application fails. The open release of code is a clear strength supporting reproducibility and further experimentation.
major comments (1)
- [Evaluation] Evaluation section (and abstract): success is reported for the full LeanMarathon system on the four Erdős problems, but no baseline or ablation is provided (e.g., direct application of the base LLM/prover to the same targets, or runs with the two-stage orchestrator or contract-scoped agents disabled). Without such controls it is impossible to attribute the zero-sorry outcomes to prevention of drift/tangling/context decay rather than to problem selection or base-model strength; this directly undercuts the claim that 'reliable AI co-mathematics requires not only stronger provers, but durable harnesses.'
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The concern about missing baselines and ablations is valid and directly impacts the strength of our central claim. We address it point-by-point below and commit to revisions that will incorporate the requested controls.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and abstract): success is reported for the full LeanMarathon system on the four Erdős problems, but no baseline or ablation is provided (e.g., direct application of the base LLM/prover to the same targets, or runs with the two-stage orchestrator or contract-scoped agents disabled). Without such controls it is impossible to attribute the zero-sorry outcomes to prevention of drift/tangling/context decay rather than to problem selection or base-model strength; this directly undercuts the claim that 'reliable AI co-mathematics requires not only stronger provers, but durable harnesses.'
Authors: We agree that the absence of baselines and ablations is a genuine limitation of the current evaluation. The manuscript reports only the performance of the complete system and does not include direct comparisons to the base LLM/prover applied to the same targets or to versions with the orchestrator or contract agents disabled. While the four Erdős problems were selected from recent research papers (where long-horizon formalization has been documented as difficult), this selection alone does not substitute for controlled experiments. In the revised manuscript we will add (i) baseline runs using direct application of the underlying LLM and prover to the seven target theorems and (ii) ablations that disable the two-stage orchestrator and/or the contract-scoped agent structure. These additional results will be reported in the evaluation section and will be used to quantify the contribution of the harness components to the observed zero-sorry outcomes. revision: yes
Circularity Check
No significant circularity; evaluation uses external benchmarks
full rationale
The paper's central results consist of empirical runs of the LeanMarathon system on four external Erdős problems drawn from published papers, reporting formalization of seven theorems and 258 lemmas with zero sorry. No equations, fitted parameters, or self-citations are used to derive the reported outcomes; the evaluation targets are independent of the system's internal design. The claim that durable harnesses are required alongside stronger provers is an interpretive conclusion rather than a derivation that reduces to the inputs by construction. No self-definitional, fitted-prediction, or load-bearing self-citation patterns appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The Lean theorem prover correctly verifies formal proofs when no sorry statements remain
invented entities (3)
-
evolving blueprint
no independent evidence
-
contract-scoped agents
no independent evidence
-
two-stage orchestrator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aristotle: IMO-level Automated Theorem Proving.arXiv preprint arXiv:2510.01346,
Tudor Achim, Alex Best, Alberto Bietti, Kevin Der, Mathïs Fédérico, Sergei Gukov, Daniel Halpern-Leistner, Kirsten Henningsgard, Yury Kudryashov, Alexander Meiburg, et al. Aristotle: IMO-level Automated Theorem Proving.arXiv preprint arXiv:2510.01346,
- [2]
-
[3]
Accessed: 2026-06-01
URLhttps://axiommath.ai/. Accessed: 2026-06-01. Kevin Barreto, Jiwon Kang, Sang-hyun Kim, Vjekoslav Kovač, and Shengtong Zhang. Irrationality of rapidly converging series: a problem of Erdős and Graham,
2026
-
[4]
URLhttps://arxiv.org/abs/2601.21442. Lars Becker, María Inés de Frutos-Fernández, Leo Diedering, Floris van Doorn, Sébastien Gouëzel, Asgar Jamneshan, Evgenia Karunus, Edward van de Meent, Pietro Monticone, Jasper Mulder-Sohn, Jim Portegies, Joris Roos, Michael Rothgang, Rajula Srivastava, James Sundstrom, Jeremy Tan, and Christoph Thiele. A blueprint for...
- [5]
-
[6]
Matthew Bolan, Joachim Breitner, Jose Brox, Nicholas Carlini, Mario Carneiro, Floris van Doorn, Martin Dvořák, Andrés Goens, Aaron Hill, Harald Husum, Hernán Ibarra Mejia, Zoltan A
Accessed 2026-05-30. Matthew Bolan, Joachim Breitner, Jose Brox, Nicholas Carlini, Mario Carneiro, Floris van Doorn, Martin Dvořák, Andrés Goens, Aaron Hill, Harald Husum, Hernán Ibarra Mejia, Zoltan A. Kocsis, Bruno Le Floch, Amir Livne Bar-on, Lorenzo Luccioli, Douglas McNeil, Alex Meiburg, Pietro Monticone, Pace P. Nielsen, Emmanuel Osalotioman Osazuwa...
2026
-
[7]
URLhttps://arxiv.org/abs/2512.07087. Sébastien Bubeck, Christian Coester, Ronen Eldan, Timothy Gowers, Yin Tat Lee, Alexandru Lupsasca, Mehtaab Sawhney, Robert Scherrer, Mark Sellke, Brian K. Spears, Derya Unutmaz, Kevin Weil, Steven Yin, and Nikita Zhivotovskiy. Early science acceleration experiments with GPT-5,
-
[8]
URLhttps: //arxiv.org/abs/2511.16072. Kevin Buzzard et al. The Fermat’s Last Theorem project.https://github.com/ImperialCollegeLondon/ FLT,
-
[9]
Accessed 2026-05-30
Lean 4 formalization project, Imperial College London. Accessed 2026-05-30. Luoxin Chen, Jinming Gu, Liankai Huang, Wenhao Huang, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Kaijing Ma, Cheng Ren, Jiawei Shen, Wenlei Shi, Tong Sun, He Sun, Jiahui Wang, Siran Wang, Zhihong Wang, Chenrui Wei, Shufa Wei, et al. Seed-Prover: Deep and broad...
2026
-
[10]
18 Yaël Dillies, Terence Tao, et al
URLhttps://arxiv.org/abs/2507.23726. 18 Yaël Dillies, Terence Tao, et al. Formalization of the polynomial Freiman-Ruzsa conjecture of Marton. https://github.com/teorth/pfr,
-
[11]
Accessed 2026-05-30
Lean 4 formalization project. Accessed 2026-05-30. Tony Feng, Trieu Trinh, Garrett Bingham, Jiwon Kang, Shengtong Zhang, Sang-hyun Kim, Kevin Barreto, Carl Schildkraut, Junehyuk Jung, Jaehyeon Seo, Carlo Pagano, Yuri Chervonyi, Dawsen Hwang, Kaiying Hou, Sergei Gukov, Cheng-Chiang Tsai, Hyunwoo Choi, Youngbeom Jin, Wei-Yuan Li, Hao-An Wu, Ruey-An Shiu, Yu...
2026
-
[12]
URLhttps://arxiv.org/abs/2601.22401. Cameron Freer. Lean 4 Skills: Theorem proving skill and workflow pack for AI coding agents, October
-
[13]
URLhttps://arxiv.org/abs/2410.10878. Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falkman Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, Olli Järviniemi, Matthew Barnett, Robert Sandler, Matej Vrzala, Jaime Sevilla, Qiuyu Ren, Elizabeth Pratt, Lionel Levine, Grant Barkley, Natalie Stewar...
-
[14]
URLhttps: //arxiv.org/abs/2411.04872. Fabian Gloeckle, Ahmad Rammal, Charles Arnal, Remi Munos, Vivien Cabannes, Gabriel Synnaeve, and Amaury Hayat. Automatic textbook formalization.arXiv preprint arXiv:2604.03071,
-
[15]
URLhttps://arxiv.org/abs/2102.06203. Sidharth Hariharan, Christopher Birkbeck, Seewoo Lee, Ho Kiu Gareth Ma, Bhavik Mehta, Auguste Poiroux, and Maryna Viazovska. A milestone in formalization: The sphere packing problem in dimension 8.arXiv preprint arXiv:2604.23468,
-
[16]
Horv \'a th, Goran Z u z i \'c , Eric Wieser, Aja Huang, Julian Schrittwieser, et al
doi: 10.1038/s41586-025-09833-y. URLhttps://doi.org/10.1038/s41586-025-09833-y. Albert Q. Jiang, Sean Welleck, Jin Peng Zhou, Timothée Lacroix, Jiacheng Liu, Wenda Li, Mateja Jamnik, Guillaume Lample, and Yuhuai Wu. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs. InInternational Conference on Learning Representations (ICLR),
-
[17]
URLhttps: //arxiv.org/abs/2210.12283. Guillaume Lample, Timothée Lacroix, Marie-Anne Lachaux, Aurélien Rodriguez, Amaury Hayat, Thibaut Lavril, Gabriel Ebner, and Xavier Martinet. HyperTree proof search for neural theorem proving. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[18]
Haohan Lin, Zhiqing Sun, Sean Welleck, and Yiming Yang
URLhttps://arxiv.org/abs/2205.11491. Haohan Lin, Zhiqing Sun, Sean Welleck, and Yiming Yang. Lean-STaR: Learning to interleave thinking and proving. InInternational Conference on Learning Representations (ICLR), 2025a. URL https: //arxiv.org/abs/2407.10040. Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui-Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jia...
-
[19]
Math, Inc
Accessed 2026-05-30. Math, Inc. Erdos1196: A Lean formalization of Erdős Problem #1196.https://github.com/math-inc/ Erdos1196,
2026
-
[20]
Accessed 2026-05-30
Formalized by the Gauss autoformalization agent. Accessed 2026-05-30. Alexander Novikov, Ngân V˜ u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli...
2026
-
[21]
URL https://arxiv.org/abs/2506.13131. OpenAI. An OpenAI model has disproved a central conjecture in discrete geometry.https://openai.com/ index/model-disproves-discrete-geometry-conjecture/,
-
[22]
Stanislas Polu and Ilya Sutskever
Accessed 2026-06-01. Stanislas Polu and Ilya Sutskever. Generative language modeling for automated theorem proving,
2026
-
[23]
URL https://arxiv.org/abs/2009.03393. Z. Z. Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, Z. F. Wu, Zhibin Gou, Shirong Ma, Hongxuan Tang, Yuxuan Liu, Wenjun Gao, Daya Guo, and Chong Ruan. DeepSeek-Prover-V2: Advancing formal mathematical reasoning via reinforcement learning for subg...
Pith/arXiv arXiv 2009
-
[24]
URLhttps://arxiv.org/abs/2504.21801. Peter Scholze. Liquid tensor experiment.Experimental Mathematics, 31(2):349–354,
-
[25]
URLhttps://doi.org/10.1080/10586458.2021.1926016
doi: 10.1080/ 10586458.2021.1926016. URLhttps://doi.org/10.1080/10586458.2021.1926016. Sho Sonoda, Kazumi Kasaura, Yuma Mizuno, Kei Tsukamoto, and Naoto Onda. Lean formalization of generalization error bound by rademacher complexity.arXiv preprint arXiv:2503.19605,
-
[26]
URLhttps://doi.org/10.1090/noti3041
doi: 10.1090/noti3041. URLhttps://doi.org/10.1090/noti3041. Terence Tao. The three components of problem solving: proof generation, proof verification, and proof digestion. Mathstodon post,
-
[27]
URLhttps://mathstodon.xyz/@tao/116450581967483825. Accessed: 2026-06-01. Trieu H. Trinh, Yuhuai Wu, Quoc V. Le, He He, and Thang Luong. Solving olympiad geometry without human demonstrations.Nature, 625(7995):476–482,
arXiv 2026
-
[28]
Nature625, 476–482 (2024).https://doi.org/ 10.1038/s41586-023-06747-5
doi: 10.1038/s41586-023-06747-5. URL https://doi.org/10.1038/s41586-023-06747-5. George Tsoukalas, Anton Kovsharov, Sergey Shirobokov, Anja Surina, Moritz Firsching, Gergely Bérczi, Francisco J. R. Ruiz, Arun Suggala, Adam Zsolt Wagner, Eric Wieser, Lei Yu, Aja Huang, Miklós Z. Horváth, Andrew Ferrauiolo, Henryk Michalewski, Codrut Grosu, Thomas Hubert, M...
-
[29]
URLhttps://arxiv.org/abs/2605.22763. Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, ZhenzheYing, ZekaiZhu, JianqiaoLu, HuguesdeSaxcé, etal. Kimina-Proverpreview: Towardslarge formal reasoning models with reinforcement learning,
-
[30]
Zichen Wang, Wanli Ma, Zhenyu Ming, Gong Zhang, Kun Yuan, and Zaiwen Wen
URLhttps://arxiv.org/abs/2504.11354. Zichen Wang, Wanli Ma, Zhenyu Ming, Gong Zhang, Kun Yuan, and Zaiwen Wen. M2f: Automated formalization of mathematical literature at scale.arXiv preprint arXiv:2602.17016,
-
[31]
URLhttps://arxiv.org/abs/2205.12615. 20 Huajian Xin, Z. Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Qihao Zhu, Dejian Yang, Zhibin Gou, Z. F. Wu, Fuli Luo, and Chong Ruan. DeepSeek-Prover-V1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search,
-
[32]
URLhttps://arxiv.org/abs/2408.08152. Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan J. Prenger, and Anima Anandkumar. LeanDojo: Theorem proving with retrieval-augmented language models. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[33]
Huaiyuan Ying, Zijian Wu, Yihan Geng, Jiayu Wang, Dahua Lin, and Kai Chen
URLhttps://arxiv.org/abs/ 2306.15626. Huaiyuan Ying, Zijian Wu, Yihan Geng, Jiayu Wang, Dahua Lin, and Kai Chen. Lean workbook: A large-scale lean problem set formalized from natural language math problems. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[34]
URLhttps://arxiv.org/abs/2406.03847. Shangtong Zhang. Towards formalizing reinforcement learning theory.arXiv preprint arXiv:2511.03618,
-
[35]
Lee, Chenlei Leng, and Fanghui Liu
Yuanhe Zhang, Ilja Kuzborskij, Jason D. Lee, Chenlei Leng, and Fanghui Liu. DAG-Math: Graph-of-Thought Guided Mathematical Reasoning in LLMs. InInternational Conference on Learning Representations (ICLR), 2026a. URLhttps://arxiv.org/abs/2510.19842. Yuanhe Zhang, Jason D Lee, and Fanghui Liu. AI4SLT: Empirical Processes in Lean 4 for Formal Statistical Lea...
-
[36]
21 Contents 1 Introduction 1 1.1 Contributions
URLhttps://arxiv.org/abs/2601.22554. 21 Contents 1 Introduction 1 1.1 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 2 Harness Infrastructure 5 2.1 The Blueprint as the System of Record . ....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.