ADK Arena: Evaluating Agent Development Kits via LLM-as-a-Developer
Pith reviewed 2026-06-28 00:51 UTC · model grok-4.3
The pith
Holding the developer fixed as an LLM coding agent turns ADK framework choice into a measurable proxy for API usability and agent performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By holding the developer constant and varying only the framework, generation effort becomes a quantitative proxy for API usability and the resulting agents provide a controlled measure of framework effectiveness. Evaluating 204 agent-benchmark pairs across 51 frameworks finds generation succeeds for 57 percent of runs with 5.6 times cost variation, no single framework dominates, and genuine framework usage stays in a narrow 28-40 percent band regardless of information source.
What carries the argument
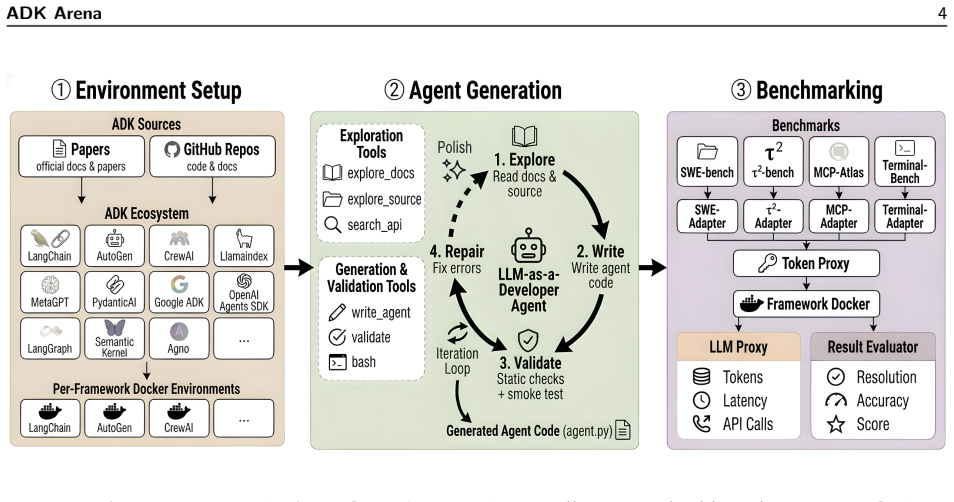
LLM-as-a-Developer methodology: an LLM coding agent that learns each ADK API from documentation and iteratively repairs generated code in a validate-and-feedback loop until tests pass.
If this is right
- Framework effectiveness can be ranked by a combination of generation cost and benchmark resolution rate.
- Best single-benchmark agents from some ADKs resolve up to 80 percent of tasks and can outperform general frontier coding agents at lower cost.
- Median frameworks resolve only 32 percent of tasks, showing wide variation in practical utility.
- Documentation, source code, and parametric knowledge act as largely substitutable inputs rather than any one being required.
Where Pith is reading between the lines
- The method could be reused to track how framework updates change usability over time without recruiting human testers.
- If the proxy holds, teams choosing an ADK could run a short LLM evaluation on their target benchmarks before committing.
- The narrow band of framework usage across information sources suggests effort to improve documentation may yield smaller gains than improving core API design.
- Extending the arena to non-Python frameworks or additional benchmarks would test whether the substitutability finding generalizes.
Load-bearing premise
The LLM coding agent serves as a fair and unbiased proxy for human developers when learning and using each framework's API from documentation.
What would settle it
Human developers building the same agents with the same frameworks produce different relative success rates or cost rankings than the LLM results.
Figures


read the original abstract
The rapid proliferation of Agent Development Kits (ADKs), SDK-level frameworks for building LLM-powered autonomous agents, has outpaced any empirical understanding of how framework choice affects agent performance. We propose \textbf{LLM-as-a-Developer}, a methodology that replaces human developers with an LLM coding agent that learns each framework's API from documentation, writes agent code, and iteratively repairs it through a validate-and-feedback loop until tests pass. By holding the developer constant and varying only the framework, generation effort becomes a quantitative proxy for API usability and the resulting agents provide a controlled measure of framework effectiveness. We implement this in \textbf{ADK Arena}, a fully automated pipeline with per-framework Docker isolation, a three-level validation pipeline, and benchmark adapters for SWE-bench, $\tau^2$-bench, Terminal-Bench, and MCP-Atlas. Evaluating all 51 popular Python ADK frameworks (204 agent--benchmark pairs), we find that: (1)~generation succeeds for 57\% of runs, and its cost varies 5.6$\times$ across frameworks (\$0.6 to \$3.4 per agent), a quantitative proxy for API complexity, though cost alone does not predict success; (2)~no single framework dominates: the best single-benchmark ADK agents resolve up to 80\% of tasks and can even \emph{beat} general-purpose frontier coding agents at a fraction of the cost, yet the median framework resolves only 32\%; (3)~across information-source ablations, genuine framework usage stays within a narrow 28--40\% band (highest with raw source access and still 33\% with no reference material at all), indicating that documentation, source code, and parametric knowledge are largely substitutable rather than any one being a hard bottleneck.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the LLM-as-a-Developer methodology, implemented in ADK Arena, to evaluate 51 Python ADK frameworks by having an LLM coding agent learn APIs from documentation, generate agent code, and iteratively repair it via a validate-and-feedback loop. Holding the developer constant, it treats generation effort and success as proxies for API usability and framework effectiveness, reporting 57% overall success across 204 agent-benchmark pairs on SWE-bench, τ²-bench, Terminal-Bench, and MCP-Atlas; 5.6× cost variation ($0.6–$3.4); no dominant framework (best reaches 80%, median 32%); and substitutability of information sources (framework usage 28–40% across ablations).
Significance. If the LLM proxy assumption holds, the work supplies the first large-scale, controlled empirical comparison of ADK frameworks, demonstrating substantial variability in usability and effectiveness while showing that documentation, source, and parametric knowledge are largely interchangeable. The automated pipeline and benchmark adapters could become a reusable evaluation harness for the rapidly growing ADK ecosystem.
major comments (2)
- [§3 (Methodology)] §3 (Methodology) and Abstract: The central claim that generation effort and success rates serve as a quantitative proxy for API usability and framework effectiveness rests on the untested assumption that LLM behavior (prompted from docs with validate-and-repair) tracks human developer learning curves and error patterns. No human baseline comparison or correlation study is reported, so LLM-specific factors such as training-data overlap or tolerance for verbose traces could drive the observed 57% success and 5.6× cost range rather than framework properties.
- [Abstract and §5 (Results)] Abstract and §5 (Results): Concrete performance numbers (57% success, 5.6× cost range, 28–40% usage band, up to 80% task resolution) are presented without reported error bars, exact definitions of the three-level validation pipeline, or details on how post-hoc framework exclusions were handled, undermining assessment of statistical robustness and reproducibility of the substitutability and non-dominance claims.
minor comments (2)
- [§5 (Results)] The abstract states that cost alone does not predict success, but no scatter plot or correlation coefficient is referenced in the results section to support this observation.
- Docker isolation and benchmark adapters are mentioned but lack a high-level architecture diagram or pseudocode for the validate-and-repair loop, which would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, agreeing where clarifications are needed and defending the methodology's design where appropriate. Revisions will focus on improving reproducibility and acknowledging limitations.
read point-by-point responses
-
Referee: [§3 (Methodology)] §3 (Methodology) and Abstract: The central claim that generation effort and success rates serve as a quantitative proxy for API usability and framework effectiveness rests on the untested assumption that LLM behavior (prompted from docs with validate-and-repair) tracks human developer learning curves and error patterns. No human baseline comparison or correlation study is reported, so LLM-specific factors such as training-data overlap or tolerance for verbose traces could drive the observed 57% success and 5.6× cost range rather than framework properties.
Authors: We acknowledge that the LLM-as-a-Developer methodology relies on an assumption that LLM coding behavior provides a useful proxy for relative framework usability. The design intentionally holds the 'developer' constant (same LLM, same prompting strategy) to isolate framework effects, which would be infeasible with variable human developers at this scale. While LLM-specific factors could influence absolute values, relative rankings and cost variations across frameworks should still reflect API differences. We will add an explicit limitations paragraph in the discussion section noting the lack of human correlation data and calling for future work. No change to the core claims or results is warranted, as the proxy enables the first large-scale controlled comparison. revision: partial
-
Referee: [Abstract and §5 (Results)] Abstract and §5 (Results): Concrete performance numbers (57% success, 5.6× cost range, 28–40% usage band, up to 80% task resolution) are presented without reported error bars, exact definitions of the three-level validation pipeline, or details on how post-hoc framework exclusions were handled, undermining assessment of statistical robustness and reproducibility of the substitutability and non-dominance claims.
Authors: We agree these details are essential for reproducibility. In the revised manuscript we will: (1) add error bars (standard error across runs) to all aggregate metrics in the abstract, §5, and figures; (2) expand §3 with a precise description and pseudocode of the three-level validation pipeline (syntax check, unit tests, benchmark execution); (3) clarify post-hoc exclusions, including the exact number of frameworks removed, the criteria (e.g., installation failures, API incompatibilities), and sensitivity analysis showing results are robust to their inclusion. These changes will directly address concerns about statistical robustness. revision: yes
- Conducting a human baseline comparison or correlation study to validate the LLM proxy assumption, which would require new large-scale experiments outside the current scope.
Circularity Check
No circularity: empirical evaluation is self-contained against external benchmarks
full rationale
The paper defines an experimental methodology (LLM-as-a-Developer) that runs an LLM coding agent on each framework's documentation to produce agents, then measures generation cost, success rate, and benchmark performance directly. No equations, fitted parameters, or derivations appear in the abstract or described pipeline; generation effort is observed output, not a prediction derived from itself. The claim that effort proxies usability follows from the controlled experimental design (developer held constant) rather than reducing to a self-referential fit or self-citation. Information-source ablations report observed usage rates (28-40%) without invoking prior author work as a uniqueness theorem. The evaluation uses external benchmarks (SWE-bench, etc.) and reports raw statistics, making the central results independent of any internal loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM coding agent that learns from documentation and repairs via validate-and-feedback is a valid constant proxy for measuring framework API usability and effectiveness.
Reference graph
Works this paper leans on
-
[1]
Chaithanya Bandi, Ben Hertzberg, Geobio Boo, Tejas Polakam, Jeff Da, Sami Hassaan, Manasi Sharma, Andrew Park, Ernesto Hernandez, Dan Rambado, Ivan Salazar, Rafael Cruz, Chetan Rane, Ben Levin, Brad Kenstler, and Bing Liu. MCP-Atlas: A large-scale benchmark for tool-use competency with real MCP servers.arXiv preprint arXiv:2602.00933,
-
[2]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901,
1901
-
[3]
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pond´e de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
-
[4]
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. AgentVerse: Facilitating multi-agent collaboration and exploring emergent behaviors.arXiv preprint arXiv:2308.10848,
-
[5]
Mohammed Mehedi Hasan, Hao Li, Emad Fallahzadeh, Gopi Krishnan Rajbahadur, Bram Adams, and Ahmed E. Hassan. An empirical study of testing practices in open source AI agent frameworks and agentic applications.arXiv preprint arXiv:2509.19185,
-
[6]
MetaGPT: Meta programming for a multi-agent collaborative framework.arXiv preprint arXiv:2308.00352,
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. MetaGPT: Meta programming for a multi-agent collaborative framework.arXiv preprint arXiv:2308.00352,
-
[7]
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for “mind” exploration of large language model society.Advances in Neural Information Processing Systems, 36, 2023a. Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Ak...
-
[8]
Daniel Liu, Krishna Upadhyay, Vinaik Chhetri, A.B. Siddique, and Umar Farooq. A large-scale study on the development and issues of multi-agent AI systems.arXiv preprint arXiv:2601.07136,
-
[9]
AgentBench: Evaluating LLMs as agents.arXiv preprint arXiv:2308.03688,
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. AgentBench: Evaluating LLMs as agents.arXiv preprint arXiv:2308.03688,
-
[10]
Merrill, Nicholas Carlini, Alexander G
Mike A. Merrill, Nicholas Carlini, Alexander G. Shaw, Ludwig Schmidt, et al. Terminal-Bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868,
-
[11]
GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983,
Gr´egoire Mialon, Cl´ementine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983,
-
[12]
GPT-4 technical report.arXiv preprint arXiv:2303.08774,
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
-
[13]
Abdelghny Orogat, Ana Rostam, and Essam Mansour. Understanding multi-agent LLM frameworks: A unified benchmark and experimental analysis.arXiv preprint arXiv:2602.03128,
-
[14]
Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334,
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334,
-
[15]
ChatDev: Communicative agents for software development.arXiv preprint arXiv:2307.07924,
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. ChatDev: Communicative agents for software development.arXiv preprint arXiv:2307.07924,
-
[16]
ADK Arena 15 Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIs.arXiv preprint arXiv:2307.16789,
-
[17]
Code Llama: Open foundation models for code.arXiv preprint arXiv:2308.12950,
Baptiste Rozi`ere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code Llama: Open foundation models for code.arXiv preprint arXiv:2308.12950,
-
[18]
LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
-
[19]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6), 2024a
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6), 2024a. Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better LLM ag...
-
[20]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. AutoGen: Enabling next-gen LLM applications via multi-agent conversation.arXiv preprint arXiv:2308.08155,
-
[21]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering.arXiv preprint arXiv:2405.15793,
-
[22]
ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
-
[23]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent- user interaction in real-world domains.arXiv preprint arXiv:2406.12045,
-
[24]
A Ecosystem Analysis Beyond evaluating what ADK frameworksdoon benchmarks, we examine how theyrelateto each other and to the broader developer community
Hard dependency (6) Code-only import (40) Declared-only (8) Figure 3: Inter-ADK dependency network. A Ecosystem Analysis Beyond evaluating what ADK frameworksdoon benchmarks, we examine how theyrelateto each other and to the broader developer community. We analyze inter-framework dependencies (§A.1), which reveal supply-chain risks and hidden coupling, an...
2019
-
[25]
We extract dependency relationships from both package metadata (pyproject.toml, setup.py, requirements.txt) and source code imports across all 51 repositories
and hidden coupling invisible to package managers (Liu et al., 2022). We extract dependency relationships from both package metadata (pyproject.toml, setup.py, requirements.txt) and source code imports across all 51 repositories. An edge from frameworkAto frameworkBis classified into three categories (test and example imports are markedoptionaland exclude...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.