SoCRATES: Towards Reliable Automated Evaluation of Proactive LLM Mediation across Domains and Socio-cognitive Variations
Pith reviewed 2026-06-28 02:10 UTC · model grok-4.3
The pith
Even the strongest LLM mediators close only about a third of the unmediated consensus gap across diverse realistic testbeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
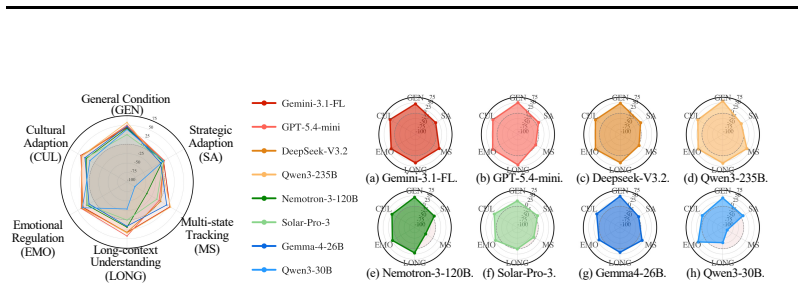
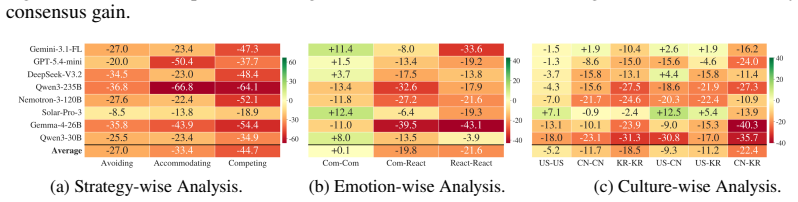
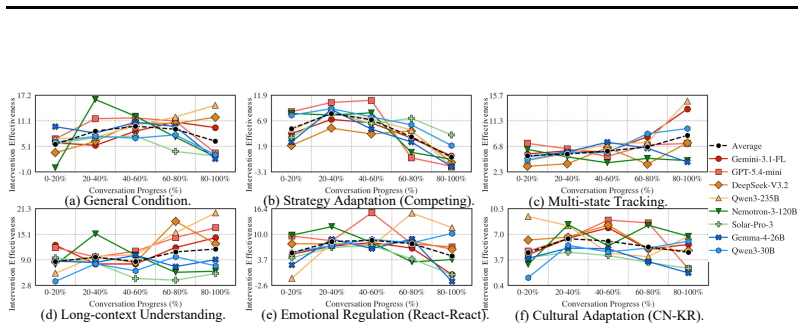
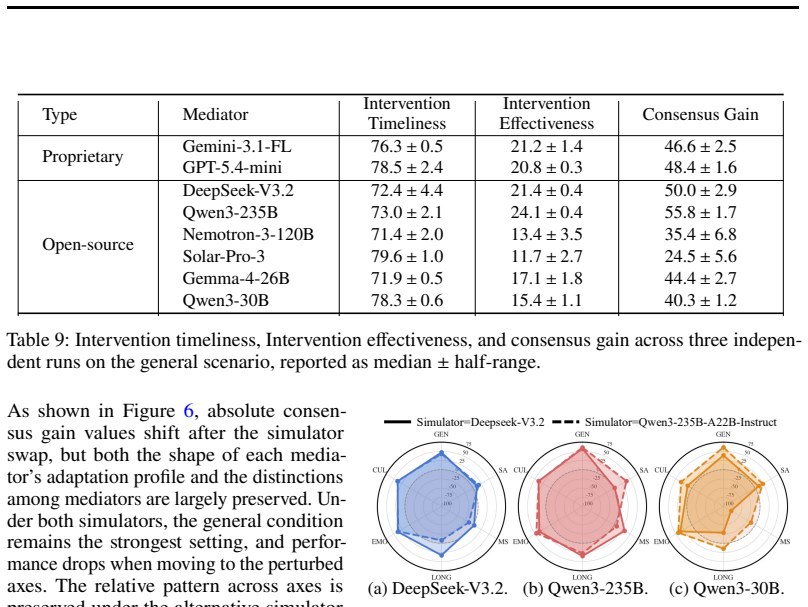
SoCRATES constructs scenarios from real conflicts through an agentic pipeline across eight domains, probes five socio-cognitive adaptation axes (strategic posture, party composition, history length, emotional reactivity, and cultural identity), and scores each topic only on the turns that advance it via a topic-localized evaluator that reaches 0.82 alignment with human experts. Benchmarking eight frontier LLMs shows that even the strongest mediator closes only about a third of the unmediated consensus gap under diverse and realistic testbeds, with performance varying sharply by socio-cognitive axis.
What carries the argument
The SoCRATES benchmark, which generates multi-domain scenarios from real conflicts via an agentic pipeline, applies probes across five socio-cognitive axes, and uses topic-localized evaluation to isolate mediation quality.
Load-bearing premise
The agentic pipeline produces scenarios that faithfully represent real-world conflicts and the topic-localized evaluator with 0.82 human alignment accurately captures mediation quality without introducing new biases.
What would settle it
Running human participants through the same generated scenarios with the tested LLMs as mediators and measuring the actual fraction of consensus gap closed compared to the benchmark scores.
Figures



read the original abstract
Evaluating LLM mediators remains challenging, as mediation unfolds as a real-time trajectory shaped by disputants' shifting emotions, intentions, and context. Existing testbeds rely on a few expert-authored domains, vary mainly strategic posture, and score every turn against every topic, introducing off-topic noise. We introduce SoCRATES, a benchmark for evaluating proactive LLM mediators in realistic, multi-domain testbeds. It constructs scenarios from real conflicts through an agentic pipeline across eight domains, probes five socio-cognitive adaptation axes (strategic posture, party composition, history length, emotional reactivity, and cultural identity), and scores each topic only on the turns that advance it via a topic-localized evaluator. The evaluator reaches 0.82 alignment with human experts, more than doubling a per-turn baseline. Benchmarking eight frontier LLMs, we find that even the strongest mediator closes only about a third of the unmediated consensus gap under diverse and realistic testbeds, with performance varying sharply by socio-cognitive axis, highlighting that progress lies in social adaptation to diverse conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SoCRATES, a benchmark for evaluating proactive LLM mediators across realistic multi-domain scenarios. It builds scenarios from real conflicts via an agentic pipeline spanning eight domains, probes five socio-cognitive axes (strategic posture, party composition, history length, emotional reactivity, cultural identity), and introduces a topic-localized evaluator that scores only relevant turns and reaches 0.82 alignment with human experts (more than double a per-turn baseline). Benchmarking eight frontier LLMs shows that even the strongest mediator closes only about one-third of the unmediated consensus gap, with sharp variation by socio-cognitive axis.
Significance. If the benchmark construction and evaluator hold, the work supplies a more realistic, multi-axis testbed than prior expert-authored single-domain setups and supplies falsifiable predictions about LLM mediator limitations under socio-cognitive variation. The agentic pipeline from real conflicts and the topic-localized scoring are concrete strengths that could support reproducible follow-on studies.
major comments (2)
- [Abstract] Abstract: the claim that the topic-localized evaluator reaches 0.82 human alignment (more than doubling the per-turn baseline) supplies no details on the number of experts, annotation protocol, inter-rater reliability, or statistical controls. This measurement is load-bearing for the reliability of the gap-closure metric and the headline result.
- [Abstract] Abstract / benchmark construction: no quantitative evidence is supplied that the agentic pipeline preserves the statistical structure of real disputes on the five probed socio-cognitive axes. Without such validation the claim that the testbeds are 'diverse and realistic' remains unanchored and directly affects the interpretation of the one-third gap-closure finding.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript to strengthen the presentation of the evaluator validation and benchmark construction.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the topic-localized evaluator reaches 0.82 human alignment (more than doubling the per-turn baseline) supplies no details on the number of experts, annotation protocol, inter-rater reliability, or statistical controls. This measurement is load-bearing for the reliability of the gap-closure metric and the headline result.
Authors: We agree that the abstract would benefit from additional details on this key measurement. In the revised version we will expand the abstract to briefly report the number of experts, a summary of the annotation protocol, the inter-rater reliability statistic, and the statistical controls employed. These elements are already documented in the main text; we will ensure they are also visible at the abstract level given the centrality of the 0.82 alignment figure to the gap-closure results. revision: yes
-
Referee: [Abstract] Abstract / benchmark construction: no quantitative evidence is supplied that the agentic pipeline preserves the statistical structure of real disputes on the five probed socio-cognitive axes. Without such validation the claim that the testbeds are 'diverse and realistic' remains unanchored and directly affects the interpretation of the one-third gap-closure finding.
Authors: We acknowledge that the manuscript does not currently supply quantitative comparisons (e.g., distributional statistics on the five socio-cognitive axes) between the generated scenarios and the original real-world disputes. The agentic pipeline is designed to instantiate the axes from real conflict sources, but explicit validation of statistical fidelity is absent. In revision we will add such quantitative evidence where feasible or, if data limitations prevent it, qualify the 'diverse and realistic' phrasing and discuss implications for interpreting the one-third gap-closure result. revision: yes
Circularity Check
No circularity: benchmark construction with empirical evaluation only
full rationale
The paper constructs a benchmark (SoCRATES) via an agentic pipeline from real conflicts, defines five socio-cognitive axes, and reports an empirical evaluator alignment of 0.82 with humans plus LLM performance metrics (e.g., closing ~1/3 of consensus gap). No equations, fitted parameters, or predictions are described that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The work is self-contained as an empirical comparison; the 0.82 figure is a reported correlation, not a self-referential derivation. This matches the default non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aakshita Chandiramani, Aaron Blakeman, Abdullahi Olaoye, Abhibha Gupta, Abhilash Somasamu- dramath, Abhinav Khattar, Adeola Adesoba, Adi Renduchintala, Adil Asif, Aditya Agrawal, et al. Nemotron 3 super: Open, efficient mixture-of-experts hybrid mamba-transformer model for agentic reasoning.arXiv preprint arXiv:2604.12374,
-
[2]
Jeonghwan Choi, Jibin Hwang, Gyeonghun Sun, Minjeong Ban, Taewon Yun, Hyeonjae Cheon, and Hwanjun Song. What makes a sale? rethinking end-to-end seller–buyer retail dynamics with llm agents.arXiv preprint arXiv:2604.04468,
-
[3]
Jasper Dekoninck, Nikola Jovanović, Tim Gehrunger, Kári Rögnvalddson, Ivo Petrov, Chenhao Sun, and Martin Vechev. Beyond benchmarks: Matharena as an evaluation platform for mathematics with llms.arXiv preprint arXiv:2605.00674,
-
[4]
Deepseek-v3.2:Pushingthefrontierofopenlargelanguage models.arXiv preprint arXiv:2512.02556, 2025a
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang,ChaofanLin,ChenDong,etal. Deepseek-v3.2:Pushingthefrontierofopenlargelanguage models.arXiv preprint arXiv:2512.02556, 2025a. Xingyu Bruce Liu, Shitao Fang, Weiyan Shi, Chien-Sheng Wu, Takeo Igarashi, and Xiang’Anthony’ Chen. Proactive conversational agents wit...
-
[5]
Agreement tracking for multi-issue negotiation dialogues.arXiv preprint arXiv:2307.06524,
Amogh Mannekote, Bonnie J Dorr, and Kristy Elizabeth Boyer. Agreement tracking for multi-issue negotiation dialogues.arXiv preprint arXiv:2307.06524,
-
[6]
Emotionally- aware agents for dispute resolution.arXiv preprint arXiv:2509.04465,
Sushrita Rakshit, James Hale, Kushal Chawla, Jeanne M Brett, and Jonathan Gratch. Emotionally- aware agents for dispute resolution.arXiv preprint arXiv:2509.04465,
-
[7]
Robots in the middle: Evaluating llms in dispute resolution.arXiv preprint arXiv:2410.07053,
Jinzhe Tan, Hannes Westermann, Nikhil Reddy Pottanigari, Jaromír Šavelka, Sébastien Meeùs, Mia Godet, and Karim Benyekhlef. Robots in the middle: Evaluating llms in dispute resolution.arXiv preprint arXiv:2410.07053,
-
[8]
Michelle Vaccaro, Michael Caosun, Harang Ju, Sinan Aral, and Jared R Curhan. Advancing ai negotiations: A large-scale autonomous negotiation competition.arXiv preprint arXiv:2503.06416,
-
[9]
Social-r1: Towards human-like social reasoning in llms.arXiv preprint arXiv:2603.09249,
Jincenzi Wu, Yuxuan Lei, Jianxun Lian, Yitian Huang, Lexin Zhou, Haotian Li, Xing Xie, and Helen Meng. Social-r1: Towards human-like social reasoning in llms.arXiv preprint arXiv:2603.09249,
-
[10]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
An Yang et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[11]
13 Type Model Model Checkpoint Source Reference Open-source Gemma4-26B-A4B-itgoogle/gemma-4-26B-A4B-itHuggingFace Google DeepMind (2026c) Qwen3-30B-A3B-InstructQwen/Qwen3-30B-A3B-Instruct-2507 HuggingFace Yang et al. (2025) Solar-Pro-3solar-pro3-260323Upstage Upstage AI (2026) Nemotron-3-Super -120B-A12B nvidia/NVIDIA-Nemotron-3 -Super-120B-A12B-BF16 Hugg...
2025
-
[12]
This expands the background to roughly five times its default length
prepends four dated narrative entries extracted from the seed’s event sequence, with the original background appended unchanged as the final state. This expands the background to roughly five times its default length. EmotionControl.Weappendafixedreactivenesstemplateparameterizedby 𝑟∈ [0, 1] totheparty profile, contrasting volatile/escalating behavior at𝑟...
2010
-
[13]
Workers Federation
emits a single utterance, which is inserted before the next party speaks. H Additional Analysis H.1 Intervention Analysis Type Mediator IF (%) FI (%) Prop. Gemini-3.1-FL 22.6 32.3 GPT-5.4-mini 22.6 31.0 Open Source DeepSeek-V3.2 16.1 42.8 Qwen3-235B 20.8 39.5 Nemotron-3-120B 14.6 45.6 Solar-Pro-3 32.3 26.9 Gemma-4-26B 16.4 37.3 Qwen3-30B 31.1 25.3 Table 7...
2016
-
[14]
Downtown Transformation
Blue marks elements that carry over to the recast under fictional names. 21 Title DowntownGeneralWind-Down:Regulator–ProviderBargainingOverAccess, Capacity, and Accountability Background A private nonprofit system, Regional Health Network (RHN), operates Down- townGeneralHospital(DGH)intheRiverDistrictofEastboroughCity.RHN reportssustainedoperatinglosseso...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.