ZERO-APT: A Closed-Loop Adversarial Framework for LLM-Driven Automated Penetration Testing under Intelligent Defense
Pith reviewed 2026-06-28 01:24 UTC · model grok-4.3
The pith
ZERO-APT places an LLM attacker in a closed loop against a live LLM defender that processes real telemetry, while architectural rules enforce attack-chain consistency and a judge produces traceable reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
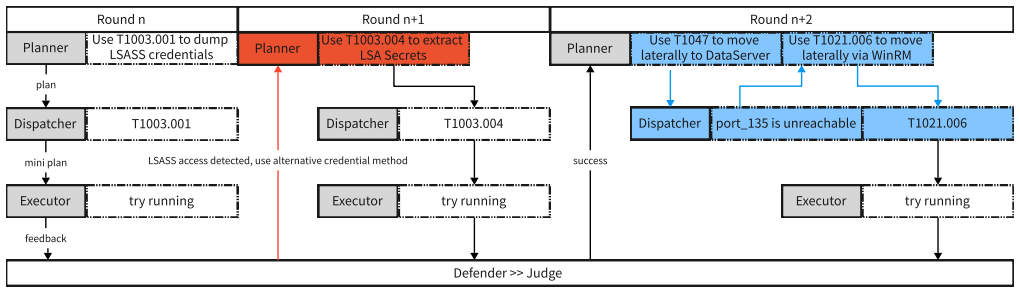
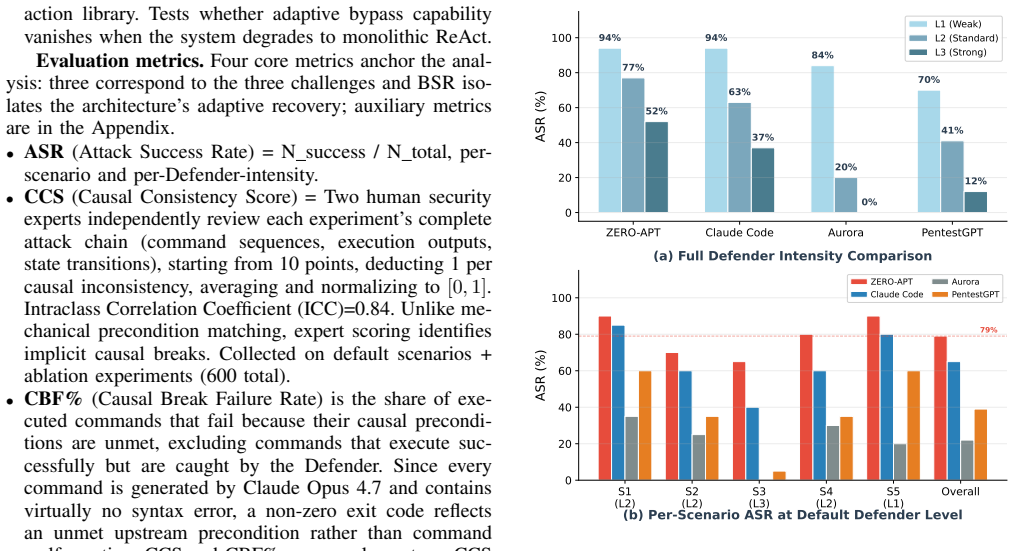
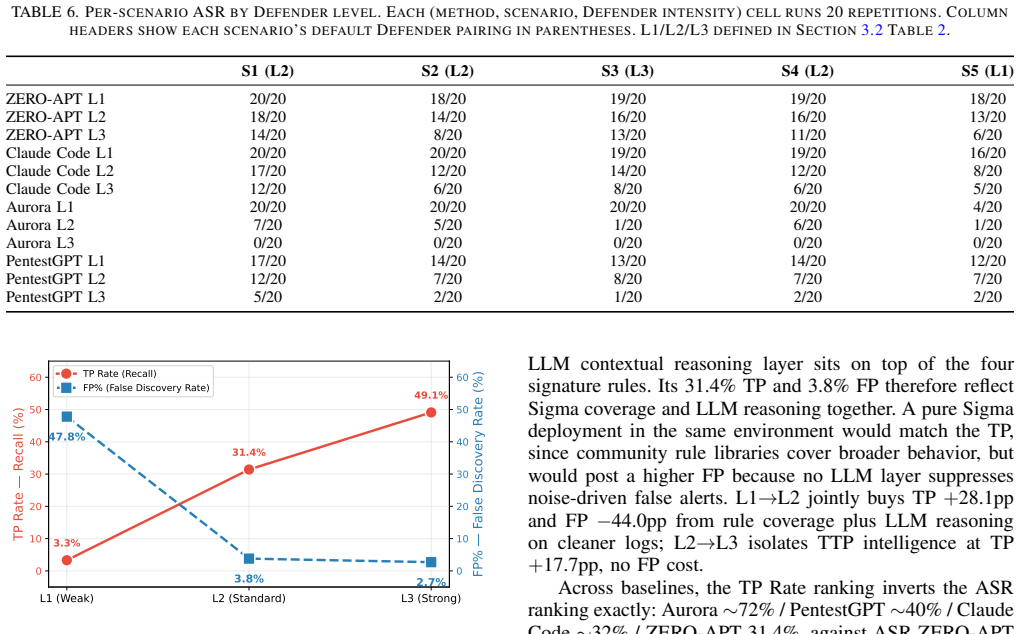
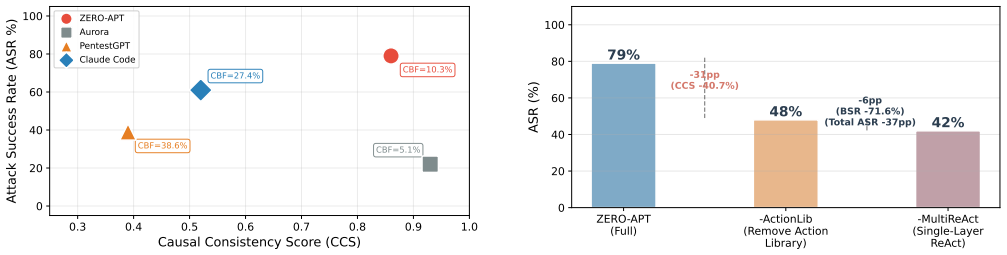
ZERO-APT is a turn-based attacker-defender-judge framework that embeds a configurable LLM defender consuming Sysmon telemetry to create a live opponent, shifts causal consistency from LLM reasoning into three architectural mechanisms (planning-execution separation, multi-dimensional ReAct feedback, and hard-constraint-filtered action library), and uses a dedicated judge to maintain state and emit structured CTI reports that render every decision traceable. In evaluations on a Windows Server 2022 post-exploitation setup the framework records 79% attack success rate and 0.860 causal consistency score together with end-to-end auditability.
What carries the argument
The turn-based attacker-defender-judge architecture whose three mechanisms move causal consistency from unstable LLM reasoning into enforced system design: planning-execution separation, multi-dimensional ReAct feedback, and hard-constraint-filtered action library.
If this is right
- Penetration testing agents can be evaluated against responsive, intelligent defenses instead of passive targets.
- Causal consistency of attack chains becomes a property of the system architecture rather than prompt quality alone.
- Every agent decision is recorded in structured CTI reports that a human analyst can review after the fact.
- The released benchmark supplies a standardized way to compare future agents under adversarial defense conditions.
- Defender configuration options allow controlled testing against different strengths of intelligent response.
Where Pith is reading between the lines
- The same closed-loop structure could be applied to other sequential decision tasks where one LLM agent must operate against another that can detect and block its moves.
- Auditability through judge-generated reports may make LLM agents more acceptable in settings that require human oversight or regulatory review.
- If the mechanisms hold across domains, they could reduce reliance on prompt engineering for reliable long-horizon behavior in adversarial environments.
- Adding a human review step at the judge layer would test whether the current traceability already meets practical operational needs.
Load-bearing premise
The three mechanisms of planning-execution separation, multi-dimensional ReAct feedback, and hard-constraint action filtering are together sufficient to enforce causal consistency even when the underlying LLM reasoning remains unreliable.
What would settle it
An experiment in which an attacker built with the three mechanisms still produces frequent causal breaks (such as attempting an action that contradicts an earlier confirmed step) while facing an active defender.
Figures

read the original abstract
LLM-driven automated penetration testing agents are typically evaluated against static targets that neither detect nor respond to attacks, so their behavior under intelligent defense remains untested. The causal consistency of multi-step attack chains likewise hinges on unstable LLM reasoning, and agent decisions remain opaque to human analysts. These three shortcomings, in realism, consistency, and auditability, are usually patched in isolation. We present ZERO-APT, a turn-based attacker-defender-judge framework that addresses them within a single architecture. For realism, ZERO-APT embeds a configurable LLM Defender that consumes Sysmon telemetry and detects attacks in real time, exposing the attacker to a live opponent rather than a passive target. For consistency, three architectural mechanisms move causal consistency from unstable LLM reasoning into enforced system architecture: separation of planning from execution, multi-dimensional ReAct feedback, and a hard-constraint-filtered action library. For auditability, a dedicated Judge agent adjudicates each round, maintains global state, and emits structured post-hoc CTI reports that make every decision traceable. We evaluate a Windows Server 2022 post-exploitation prototype across five scenarios with three Defender configurations. ZERO-APT reaches 79\% attack success rate (Aurora 22\%, PentestGPT 39\%), a Causal Consistency Score of 0.860 (Aurora 0.930, Claude Code 0.520), and end-to-end decision auditability through structured CTI reports. We release the benchmark to support evaluation of penetration agents under intelligent defense.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ZERO-APT, a closed-loop turn-based attacker-defender-judge framework for evaluating LLM-driven automated penetration testing agents against intelligent defenses. It claims to address realism via an LLM Defender consuming Sysmon telemetry, causal consistency via three architectural mechanisms (planning-execution separation, multi-dimensional ReAct feedback, hard-constraint-filtered action library), and auditability via a Judge agent producing structured CTI reports. On a Windows Server 2022 post-exploitation prototype across five scenarios, it reports 79% attack success rate (Aurora 22%, PentestGPT 39%), Causal Consistency Score 0.860 (Aurora 0.930, Claude Code 0.520), and end-to-end decision traceability, while releasing the benchmark.
Significance. If the empirical results hold under scrutiny, the work supplies a needed benchmark for testing penetration agents against responsive defenses rather than static targets, and the benchmark release supports reproducibility. The integration of defender and judge components into a single architecture could inform designs for more robust LLM security agents, provided the claimed architectural contributions to consistency are isolated.
major comments (1)
- [Evaluation/Results] Evaluation/Results section: The central claim attributes the Causal Consistency Score of 0.860 to the three architectural mechanisms enforcing consistency at the system level. However, only aggregate scores for the full system are reported across the five scenarios; no ablation studies, component-wise measurements, or comparisons to variants with individual mechanisms disabled are provided. This leaves open whether the score derives from the base LLM, prompt engineering, or scenario selection rather than the claimed architectural enforcement.
minor comments (1)
- [Abstract] Abstract and methods: Details on computation of the Causal Consistency Score, selection criteria for the five scenarios, exact baseline implementations, and any error bars or statistical tests are not summarized, complicating verification of the reported performance deltas.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below and commit to revisions that directly respond to the concern raised.
read point-by-point responses
-
Referee: [Evaluation/Results] Evaluation/Results section: The central claim attributes the Causal Consistency Score of 0.860 to the three architectural mechanisms enforcing consistency at the system level. However, only aggregate scores for the full system are reported across the five scenarios; no ablation studies, component-wise measurements, or comparisons to variants with individual mechanisms disabled are provided. This leaves open whether the score derives from the base LLM, prompt engineering, or scenario selection rather than the claimed architectural enforcement.
Authors: We acknowledge that the Evaluation section reports only aggregate results for the complete ZERO-APT system and does not include ablation studies that disable the individual mechanisms (planning-execution separation, multi-dimensional ReAct feedback, and hard-constraint-filtered action library). The comparisons to Aurora and PentestGPT establish overall performance differences but do not isolate the contribution of each architectural component within our framework. We agree that this leaves the attribution of the 0.860 score open to alternative explanations such as base LLM capabilities or prompt design. In the revised manuscript we will add ablation experiments that systematically disable each mechanism in turn and report the resulting Causal Consistency Scores across the five scenarios, thereby providing direct empirical evidence for the claimed system-level enforcement. revision: yes
Circularity Check
No significant circularity; empirical results independent of internal definitions
full rationale
The paper describes a system architecture and reports aggregate empirical metrics (79% ASR, 0.860 CCS) against external baselines (Aurora, PentestGPT) across five scenarios. No equations, fitted parameters, or derivations are present that reduce any claimed result to its own inputs by construction. The three mechanisms are presented as design choices whose contribution is asserted but not isolated via ablations; however, this is a verification gap rather than circularity. No self-citations are invoked as load-bearing uniqueness theorems, and the Causal Consistency Score is not defined in terms of the mechanisms themselves. The evaluation is self-contained against external comparators.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The LLM defender can effectively detect attacks using Sysmon telemetry in real time
invented entities (1)
-
Judge agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Automated penetration testing: For- malization and realization,
C. Skandylas and M. Asplund, “Automated penetration testing: For- malization and realization,”Computers & Security, vol. 155, 2025
2025
-
[2]
Large language models for cyber security: A systematic literature review,
H. Xu, S. Wang, N. Li, K. Wang, Y . Zhao, K. Chen, T. Yu, Y . Liu, and H. Wang, “Large language models for cyber security: A systematic literature review,”ACM Transactions on Software Engineering and Methodology (TOSEM), 2024, online AM: September 29, 2025
2024
-
[3]
Getting pwn’d by AI: Penetration testing with large language models,
A. Happe and J. Cito, “Getting pwn’d by AI: Penetration testing with large language models,” inProc. ACM ESEC/FSE, 2023, pp. 2082– 2086
2023
-
[4]
SoK: On the offensive potential of AI,
S. L. Schr ¨oer, G. Apruzzese, S. Human, P. Laskov, H. S. Anderson, E. W. N. Bernroider, A. Fass, B. Nassi, V . Rimmer, F. Roli, S. Salam, A. Shen, A. Sunyaev, T. Wadhwa-Brown, I. Wagner, and G. Wang, “SoK: On the offensive potential of AI,” inProc. IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), 2025, pp. 247–280
2025
-
[5]
ChainReactor: Automated privilege es- calation chain discovery via AI planning,
G. De Pasquale, I. Grishchenko, R. Iesari, G. Pizarro, L. Cavallaro, C. Kruegel, and G. Vigna, “ChainReactor: Automated privilege es- calation chain discovery via AI planning,” inProc. USENIX Security Symposium, 2024, pp. 5913–5929
2024
-
[6]
L. Wang, Z. Li, Y . Jiang, Z. Wang, Z. Guo, J. Wang, Y . Wei, X. Shen, W. Ruan, and Y . Chen, “From sands to mansions: Actionable, cus- tomizable and causality-preserving cyberattack emulation with LLM- powered symbolic planning,” inProc. Applied Cryptography and Network Security (ACNS), 2026, arXiv:2407.16928
-
[7]
I. K. Tung, S. Y . Xiang, A. Chien, L. Wenkai, and L. Zheng, “AEGIS: White-box attack path generation using LLMs and training effec- tiveness evaluation for large-scale cyber defence exercises,”arXiv preprint arXiv:2601.22720, 2026
-
[8]
Automated penetration testing using deep reinforcement learning,
Z. Hu, R. Beuran, and Y . Tan, “Automated penetration testing using deep reinforcement learning,” inProc. IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), 2020, pp. 2–10
2020
-
[9]
A hierarchical deep reinforcement learning model with expert prior knowledge for intelligent penetration testing,
Q. Li, M. Zhang, Y . Shen, R. Wang, M. Hu, Y . Li, and H. Hao, “A hierarchical deep reinforcement learning model with expert prior knowledge for intelligent penetration testing,”Computers & Security, vol. 132, 2023
2023
-
[10]
PentestGPT: Evaluating and har- nessing large language models for automated penetration testing,
G. Deng, Y . Liu, V . Mayoral-Vilches, P. Liu, Y . Li, Y . Xu, T. Zhang, Y . Liu, M. Pinzger, and S. Rass, “PentestGPT: Evaluating and har- nessing large language models for automated penetration testing,” in Proc. USENIX Security Symposium, 2024, pp. 847–864
2024
-
[11]
PentestAgent: Incorporating LLM agents to automated penetration testing,
X. Shen, L. Wang, Z. Li, Y . Chen, W. Zhao, D. Sun, J. Wang, and W. Ruan, “PentestAgent: Incorporating LLM agents to automated penetration testing,” inProc. ACM AsiaCCS, 2025, pp. 375–391
2025
-
[12]
AutoAttacker: A large language model guided system to implement automatic cyber-attacks,
J. Xu, J. W. Stokes, G. McDonald, X. Bai, D. Marshall, S. Wang, A. Swaminathan, and Z. Li, “AutoAttacker: A large language model guided system to implement automatic cyber-attacks,”arXiv preprint arXiv:2403.01038, 2024
-
[13]
Chasing shadows: Pitfalls in LLM security research,
J. Evertz, N. Risse, N. Neuer, A. M ¨uller, P. Normann, G. Sapia, S. Gupta, D. Pape, S. Shaw, D. Srivastav, C. Wressnegger, E. Quiring, T. Eisenhofer, D. Arp, and L. Sch ¨onherr, “Chasing shadows: Pitfalls in LLM security research,” inProc. NDSS, 2026
2026
-
[14]
RapidPen: Fully automated IP-to-Shell penetration test- ing with LLM-based agents,
S. Nakatani, “RapidPen: Fully automated IP-to-Shell penetration test- ing with LLM-based agents,”arXiv preprint arXiv:2502.16730, 2025
-
[15]
Autonomous dis- covery of cyber attack paths with complex causal relationships among optional actions,
S. Li, R. Huang, W. Han, X. Wu, S. Li, and Z. Tian, “Autonomous dis- covery of cyber attack paths with complex causal relationships among optional actions,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, pp. 17 952–17 966, 2025
2025
-
[16]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting,
M. Turpin, J. Michael, E. Perez, and S. R. Bowman, “Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting,” inProc. Advances in Neural Infor- mation Processing Systems (NeurIPS), 2023
2023
-
[17]
Reasoning Models Don't Always Say What They Think
Anthropic, “Reasoning models don’t always say what they think,” Tech. Rep., Apr. 2025, arXiv:2505.05410. [Online]. Available: https://assets.anthropic.com/m/71876fabef0f0ed4/original/ reasoning models paper.pdf
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Elastic stack (ELK),
Elastic, “Elastic stack (ELK),” https://www.elastic.co/elastic-stack, 2025
2025
-
[19]
Log-based anomaly detection without log parsing,
V .-H. Le and H. Zhang, “Log-based anomaly detection without log parsing,” inProc. IEEE/ACM International Conference on Automated Software Engineering (ASE), 2021, pp. 492–504
2021
-
[20]
LLMeLog: An approach for anomaly detection based on LLM-enriched log events,
M. He, T. Jia, C. Duan, H. Cai, Y . Li, and G. Huang, “LLMeLog: An approach for anomaly detection based on LLM-enriched log events,” inProc. IEEE International Symposium on Software Reliability En- gineering (ISSRE), 2024, pp. 132–143
2024
-
[21]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in Proc. ICLR, 2023
2023
-
[22]
Do models really learn to follow in- structions? An empirical study of instruction tuning,
P.-N. Kung and N. Peng, “Do models really learn to follow in- structions? An empirical study of instruction tuning,” inProc. ACL (Volume 2: Short Papers), 2023, pp. 1317–1328
2023
-
[23]
Atomic red team,
Red Canary, “Atomic red team,” https://github.com/redcanaryco/ atomic-red-team, 2025
2025
-
[24]
STIX 2.0: Structured threat information expression,
OASIS, “STIX 2.0: Structured threat information expression,” https: //oasis-open.github.io/cti-documentation/stix/intro.html, 2021
2021
-
[25]
POIROT: Aligning attack behavior with kernel audit records for cyber threat hunting,
S. M. Milajerdi, B. Eshete, R. Gjomemo, and V . N. Venkatakrishnan, “POIROT: Aligning attack behavior with kernel audit records for cyber threat hunting,” inProc. ACM Conference on Computer and Communications Security (CCS), 2019, pp. 1813–1830
2019
-
[26]
CRUcialG: Reconstruct integrated attack scenario graphs by cyber threat intelligence reports,
W. Cheng, T. Zhu, T. Chen, Q. Yuan, J. Ying, H. Li, C. Xiong, M. Li, M. Lv, and Y . Chen, “CRUcialG: Reconstruct integrated attack scenario graphs by cyber threat intelligence reports,”IEEE Transactions on Dependable and Secure Computing (TDSC), vol. 22, pp. 6345–6360, 2025, arXiv:2410.11209
-
[27]
MEGR-APT: A memory-efficient APT hunting system based on attack representation learning,
A. Aly, S. Iqbal, A. Youssef, and E. Mansour, “MEGR-APT: A memory-efficient APT hunting system based on attack representation learning,”IEEE Transactions on Information Forensics and Security (TIFS), vol. 19, pp. 5257–5271, 2024
2024
-
[28]
Metasploitable 3,
Rapid7, “Metasploitable 3,” https://github.com/rapid7/ metasploitable3, 2016
2016
-
[29]
Claude code: Agentic coding tool,
Anthropic, “Claude code: Agentic coding tool,” https://github.com/ anthropics/claude-code, 2025
2025
-
[30]
Cybersecurity AI: The dangerous gap between automation and autonomy,
V . Mayoral-Vilches, “Cybersecurity AI: The dangerous gap between automation and autonomy,”arXiv preprint arXiv:2506.23592, 2025
-
[31]
DynPen: Automated penetration testing in dynamic net- work scenarios using deep reinforcement learning,
Q. Li, R. Wang, D. Li, F. Shi, M. Zhang, A. Chattopadhyay, Y . Shen, and Y . Li, “DynPen: Automated penetration testing in dynamic net- work scenarios using deep reinforcement learning,”IEEE Transac- tions on Information Forensics and Security (TIFS), vol. 19, pp. 8966– 8981, 2024
2024
-
[32]
Knowledge-informed auto-penetration test- ing based on reinforcement learning with reward machine,
Y . Li, H. Dai, and J. Yan, “Knowledge-informed auto-penetration test- ing based on reinforcement learning with reward machine,” inProc. IEEE International Joint Conference on Neural Networks (IJCNN), 2024, arXiv:2405.15908
-
[33]
Leveraging deep re- inforcement learning for cyber-attack paths prediction: Formulation, generalization, and evaluation,
F. Terranova, A. Lahmadi, and I. Chrisment, “Leveraging deep re- inforcement learning for cyber-attack paths prediction: Formulation, generalization, and evaluation,” inProc. International Symposium on Recent Advances in Intrusion Detection (RAID), 2024, pp. 1–16
2024
-
[34]
N. Becker, D. Reti, E. V . Ntagiou, M. Wallum, and H. D. Schot- ten, “Evaluation of reinforcement learning for autonomous pene- tration testing using A3C, q-learning and DQN,”arXiv preprint arXiv:2407.15656, 2024
-
[35]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess`ı, R. Raileanu, M. Lomeli, L. Zettle- moyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inProc. NeurIPS, 2023
2023
-
[36]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inProc. Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[37]
PwnGPT: Automatic exploit generation based on large language models,
W. Peng, L. Ye, X. Du, H. Zhang, D. Zhan, Y . Zhang, Y . Guo, and C. Zhang, “PwnGPT: Automatic exploit generation based on large language models,” inProc. Annual Meeting of the Association for Computational Linguistics (ACL), 2025, pp. 11 481–11 494
2025
-
[38]
Teams of LLM agents can exploit zero-day vulnerabilities,
R. Fang, R. Bindu, A. Gupta, Q. Zhan, and D. Kang, “Teams of LLM agents can exploit zero-day vulnerabilities,”arXiv preprint arXiv:2406.01637, 2024
-
[39]
VulnBot: Au- tonomous penetration testing for a multi-agent collaborative frame- work,
H. Kong, D. Hu, J. Ge, L. Li, T. Li, and B. Wu, “VulnBot: Au- tonomous penetration testing for a multi-agent collaborative frame- work,”arXiv preprint arXiv:2501.13411, 2025
-
[40]
HackSynth: LLM agent and evaluation framework for autonomous penetration testing,
L. Muzsai, D. Imolai, and A. Luk ´acs, “HackSynth: LLM agent and evaluation framework for autonomous penetration testing,”arXiv preprint arXiv:2412.01778, 2024
-
[41]
Toward un- derstanding in-context vs. in-weight learning,
B. Chan, X. Chen, A. Gy ¨orgy, and D. Schuurmans, “Toward un- derstanding in-context vs. in-weight learning,” inProc. ICLR, 2025, arXiv:2410.23042
-
[42]
M. Tantakoun, C. Muise, and X. Zhu, “LLMs as planning formalizers: A survey for leveraging large language models to construct automated planning models,” inFindings of ACL, 2025, pp. 25 167–25 188, arXiv:2503.18971
-
[43]
Y . Feng and K. Sakurai, “Network intrusion detection: Evolution from conventional approaches to LLM collaboration and emerging risks,” arXiv preprint arXiv:2510.23313, 2025
-
[44]
Log-based anomaly detection with deep learning: How far are we?
V .-H. Le and H. Zhang, “Log-based anomaly detection with deep learning: How far are we?” inProc. ACM/IEEE International Con- ference on Software Engineering (ICSE), 2022, pp. 1356–1367
2022
-
[45]
LogLLM: Log-based anomaly detection using large language models,
W. Guan, J. Cao, S. Qian, and J. Gao, “LogLLM: Log-based anomaly detection using large language models,”arXiv preprint arXiv:2411.08561, 2024
-
[46]
MuSAR: Multi-step attack reconstruction from lightweight security logs via event-level semantic association in multi-host environments,
Y . Liu, Z. Xu, Z. Luo, J. Shang, S. Zhang, H. Zhang, and T. Liu, “MuSAR: Multi-step attack reconstruction from lightweight security logs via event-level semantic association in multi-host environments,” inProc. International Symposium on Research in Attacks, Intrusions and Defenses (RAID), 2025, pp. 329–348
2025
-
[47]
CORTEX: Collaborative LLM agents for high-stakes alert triage,
B. Wei, Y . S. Tay, H. Liu, J. Pan, K. Luo, Z. Zhu, and C. Jordan, “CORTEX: Collaborative LLM agents for high-stakes alert triage,” arXiv preprint arXiv:2510.00311, 2025
-
[48]
SoK: History is a vast early warning system: Auditing the provenance of system intrusions,
M. A. Inam, Y . Chen, A. Goyal, J. Liu, J. Mink, N. Michael, S. Gaur, A. Bates, and W. U. Hassan, “SoK: History is a vast early warning system: Auditing the provenance of system intrusions,” inProc. IEEE Symposium on Security and Privacy (S&P), 2023, pp. 2620–2638
2023
-
[49]
PROGRAPHER: An anomaly detection system based on provenance graph embedding,
F. Yang, J. Xu, C. Xiong, Z. Li, and K. Zhang, “PROGRAPHER: An anomaly detection system based on provenance graph embedding,” inProc. USENIX Security Symposium, 2023, pp. 4355–4372
2023
-
[50]
Hierarchical multi-agent reinforcement learning for cyber network defense,
A. V . Singh, E. Rathbun, E. Graham, L. Oakley, S. Boboila, A. Oprea, and P. Chin, “Hierarchical multi-agent reinforcement learning for cyber network defense,”arXiv preprint arXiv:2410.17351, 2024
-
[51]
A method of network attack-defense game and collaborative defense decision- making based on hierarchical multi-agent reinforcement learning,
Y . Tang, J. Sun, H. Wang, J. Deng, L. Tong, and W. Xu, “A method of network attack-defense game and collaborative defense decision- making based on hierarchical multi-agent reinforcement learning,” Computers & Security, vol. 142, 2024
2024
-
[52]
T. Xu, Z. Wen, X. Zhao, J. Wang, Y . Li, and C. Liu, “L2M-AID: Autonomous cyber-physical defense by fusing semantic reasoning of large language models with multi-agent reinforcement learning,” arXiv preprint arXiv:2510.07363, 2025, submitted to IEEE TrustCom 2025
-
[53]
When LLMs meet cybersecurity: A systematic literature review,
J. Zhang, H. Bu, H. Wen, Y . Liu, H. Fei, R. Xi, L. Li, Y . Yang, H. Zhu, and D. Meng, “When LLMs meet cybersecurity: A systematic literature review,”Cybersecurity, vol. 8, pp. 1–41, 2025
2025
-
[54]
Sysmon: System monitor,
Microsoft, “Sysmon: System monitor,” https://learn.microsoft.com/ en-us/sysinternals/downloads/sysmon, 2025
2025
-
[55]
MITRE ATT&CK framework,
MITRE, “MITRE ATT&CK framework,” https://attack.mitre.org/, 2025
2025
-
[56]
Benchmarking practices in LLM-driven offensive security: Testbeds, metrics, and experiment design,
A. Happe and J. Cito, “Benchmarking practices in LLM-driven offensive security: Testbeds, metrics, and experiment design,”arXiv preprint arXiv:2504.10112, 2025
-
[57]
Towards automated penetration testing: Introducing LLM benchmark, analysis, and im- provements,
I. Isozaki, M. Shrestha, R. Console, and E. Kim, “Towards automated penetration testing: Introducing LLM benchmark, analysis, and im- provements,” inAdjunct Proc. ACM Conference on User Modeling, Adaptation and Personalization (UMAP), 2025, pp. 404–419
2025
-
[58]
Controller makes pentesting better: An improved multi-agent au- tomated penetration testing framework,
X. Geng, N. An, B. Xu, X. Yang, B. Jiang, B. Liu, and J. Liu, “Controller makes pentesting better: An improved multi-agent au- tomated penetration testing framework,” inProc. IEEE International Conference on Trust, Security and Privacy in Computing and Com- munications (TrustCom), 2025
2025
-
[59]
HackTheBox penetration testing platform,
Hack The Box, “HackTheBox penetration testing platform,” https: //www.hackthebox.com/, 2025
2025
-
[60]
VulnHub vulnerable machines platform,
VulnHub, “VulnHub vulnerable machines platform,” https://www. vulnhub.com/, 2025
2025
-
[61]
NYU CTF Bench: A scalable open-source benchmark dataset for evaluating LLMs in offensive security,
M. Shao, S. Jancheska, M. Udeshi, B. Dolan-Gavitt, H. Xi, K. Mil- ner, B. Chen, M. Yin, S. Garg, P. Krishnamurthy, F. Khorrami, R. Karri, and M. Shafique, “NYU CTF Bench: A scalable open-source benchmark dataset for evaluating LLMs in offensive security,” in Proc. Advances in Neural Information Processing Systems (NeurIPS), Datasets & Benchmarks Track, vo...
2024
-
[62]
Pen- testEval: Benchmarking LLM-based penetration testing with modular and stage-level design,
R. Yang, M. Cheng, G. Deng, T. Zhang, J. Wang, and X. Xie, “Pen- testEval: Benchmarking LLM-based penetration testing with modular and stage-level design,”arXiv preprint arXiv:2512.14233, 2025
-
[63]
AutoPenBench: A vulnerability testing benchmark for generative agents,
L. Gioacchini, A. Delsanto, I. Drago, M. Mellia, G. Siracusano, and R. Bifulco, “AutoPenBench: A vulnerability testing benchmark for generative agents,” inProc. Conference on Empirical Methods in Natural Language Processing (EMNLP), Industry Track, 2025, pp. 1615–1624
2025
-
[64]
CVE-Bench: A benchmark for AI agents’ ability to exploit real-world web application vulnerabilities,
Y . Zhu, A. Kellermann, D. Bowman, P. Li, A. Gupta, A. Danda, R. Fang, C. Jensen, E. Ihli, J. Benn, J. Geronimo, A. Dhir, S. Rao, K. Yu, T. Stone, and D. Kang, “CVE-Bench: A benchmark for AI agents’ ability to exploit real-world web application vulnerabilities,” inProc. ICML (Spotlight), 2025, arXiv:2503.17332
-
[65]
The claude 4 model family,
Anthropic, “The claude 4 model family,” https://www.anthropic.com/ claude, 2025
2025
-
[66]
PentestGPT: Automated penetration testing agentic framework,
GreyDGL, “PentestGPT: Automated penetration testing agentic framework,” https://github.com/GreyDGL/PentestGPT, 2025
2025
-
[67]
You cannot escape me: Detecting evasions of SIEM rules in enterprise networks,
R. Uetz, M. Herzog, L. Hackl ¨ander, S. Schwarz, and M. Henze, “You cannot escape me: Detecting evasions of SIEM rules in enterprise networks,”arXiv preprint arXiv:2311.10197, 2023
-
[68]
The use of ranks to avoid the assumption of normality implicit in the analysis of variance,
M. Friedman, “The use of ranks to avoid the assumption of normality implicit in the analysis of variance,”Journal of the American Statis- tical Association, vol. 32, no. 200, pp. 675–701, 1937
1937
-
[69]
Cloak, honey, trap: Proactive defenses against LLM agents,
D. Ayzenshteyn, R. Weiss, and Y . Mirsky, “Cloak, honey, trap: Proactive defenses against LLM agents,” inProc. USENIX Security Symposium, 2025
2025
-
[70]
Can LLMs hack enterprise networks? Au- tonomous assumed breach penetration-testing active directory net- works,
A. Happe and J. Cito, “Can LLMs hack enterprise networks? Au- tonomous assumed breach penetration-testing active directory net- works,”ACM Transactions on Software Engineering and Method- ology (TOSEM), 2025
2025
-
[71]
Contingency tables involving small numbers and theχ 2 test,
F. Yates, “Contingency tables involving small numbers and theχ 2 test,”Supplement to the Journal of the Royal Statistical Society, vol. 1, no. 2, pp. 217–235, 1934
1934
-
[72]
The generalization of Student’s problem when several different population variances are involved,
B. L. Welch, “The generalization of Student’s problem when several different population variances are involved,”Biometrika, vol. 34, no. 1-2, pp. 28–35, 1947
1947
-
[73]
Individual comparisons by ranking methods,
F. Wilcoxon, “Individual comparisons by ranking methods,”Biomet- rics Bulletin, vol. 1, no. 6, pp. 80–83, 1945
1945
-
[74]
Ordered hypotheses for multiple treatments: A sig- nificance test for linear ranks,
E. B. Page, “Ordered hypotheses for multiple treatments: A sig- nificance test for linear ranks,”Journal of the American Statistical Association, vol. 58, no. 301, pp. 216–230, 1963. Appendix A. Evaluation Metrics Definition We use 13 evaluation metrics organized across three categories. The four core metrics—ASR, CCS, CBF%, and TABLE 9. COMPLETE METRIC D...
1963
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.