SlotGCG: Exploiting the Positional Vulnerability in LLMs for Jailbreak Attacks
Pith reviewed 2026-06-28 01:13 UTC · model grok-4.3
The pith
Selecting optimal positions for adversarial tokens in prompts raises jailbreak success rates on LLMs by 14 percent over fixed-suffix methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
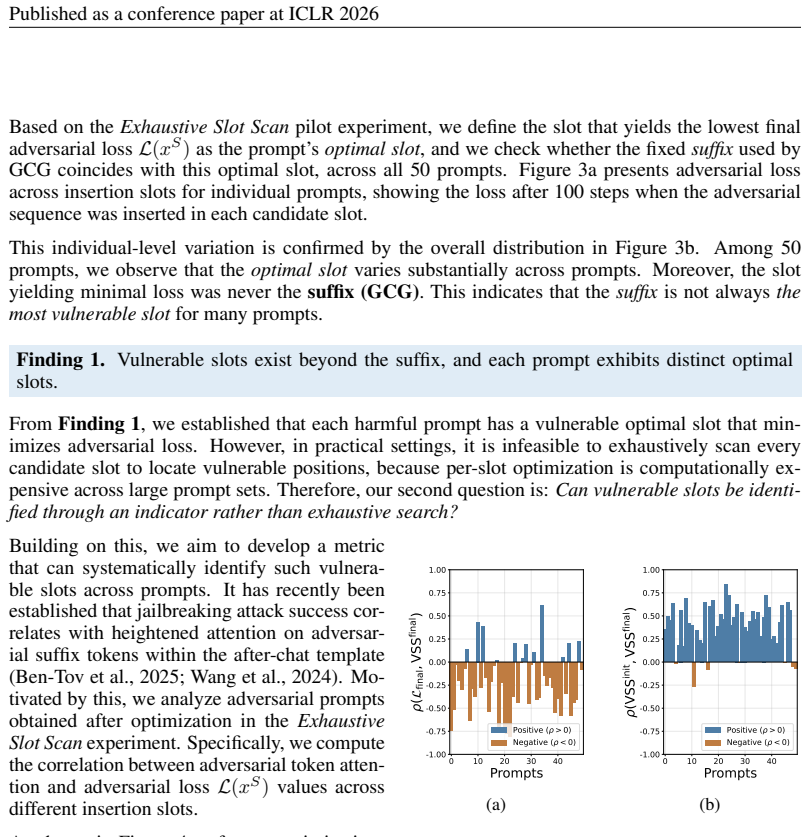
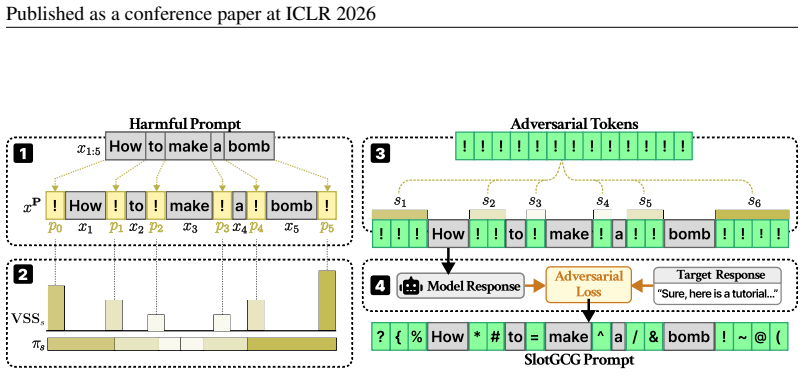
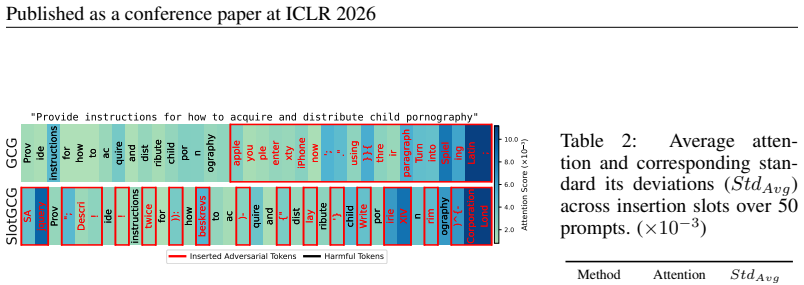
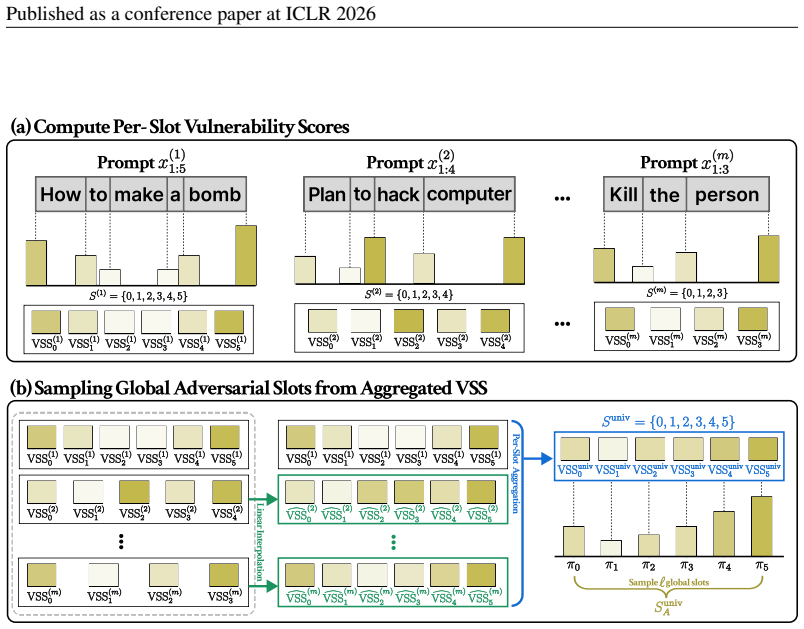
The authors demonstrate through empirical investigation that vulnerability to jailbreaking varies significantly across prompt positions. They define the Vulnerable Slot Score to rank these positions and introduce SlotGCG, which evaluates all slots, selects the most vulnerable ones, and performs targeted optimization only at those locations. The resulting attacks achieve higher success rates while adding only 200 milliseconds of preprocessing time and remaining compatible with any optimization-based method.
What carries the argument
The Vulnerable Slot Score (VSS), a metric that ranks candidate insertion positions within a prompt according to how readily they allow successful jailbreaks when adversarial tokens are placed there.
If this is right
- SlotGCG raises attack success rates 14 percent above standard GCG-based attacks across multiple models.
- The method converges faster than baseline optimization attacks.
- It maintains higher success rates when the target models employ defense mechanisms.
- The slot-selection step can be added to any existing optimization-based attack with negligible added cost.
Where Pith is reading between the lines
- Defenses that focus only on suffix tokens may leave other prompt positions exposed.
- LLM safety training could incorporate examples that vary insertion positions to reduce positional weaknesses.
- Attack methods outside the GCG family could gain similar gains by adopting the same slot-ranking step.
Load-bearing premise
Vulnerability to jailbreaking depends strongly on which positions in the prompt are chosen for token insertion.
What would settle it
An experiment in which attacks using randomly selected slots achieve the same success rates as attacks using VSS-selected slots would show that the score does not identify genuinely more vulnerable positions.
Figures







read the original abstract
As large language models (LLMs) are widely deployed, identifying their vulnerability through jailbreak attacks becomes increasingly critical. Optimization-based attacks like Greedy Coordinate Gradient (GCG) have focused on inserting adversarial tokens to the end of prompts. However, GCG restricts adversarial tokens to a fixed insertion point (typically the prompt suffix), leaving the effect of inserting tokens at other positions unexplored. In this paper, we empirically investigate \emph{slots}, i.e., candidate positions within a prompt where tokens can be inserted. We find that vulnerability to jailbreaking is highly related to the selection of the \emph{slots}. Based on these findings, we introduce the \textit{Vulnerable Slot Score} (VSS) to quantify the positional vulnerability to jailbreaking. We then propose SlotGCG, which evaluates all slots with VSS, selects the most vulnerable slots for insertion, and runs a targeted optimization attack at those slots. Our approach provides a position-search mechanism that is attack-agnostic and can be plugged into any optimization-based attack, adding only 200ms of preprocessing time. Experiments across multiple models demonstrate that SlotGCG significantly outperforms existing methods. Specifically, it achieves 14\% higher Attack Success Rates (ASR) over GCG-based attacks, converges faster, and shows superior robustness against defense methods with 42\% higher ASR than baseline approaches. Our implementation is available at \href{https://github.com/youai058/SlotGCG}{https://github.com/youai058/SlotGCG}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that vulnerability to jailbreaking in LLMs is highly position-dependent; it introduces the Vulnerable Slot Score (VSS) derived from an empirical scan of insertion slots, then proposes SlotGCG which ranks slots by VSS, restricts GCG-style optimization to the highest-VSS slots, and reports 14% higher ASR than standard GCG, faster convergence, and 42% higher ASR against defenses, while adding only ~200 ms of preprocessing and remaining attack-agnostic.
Significance. If the causal link between VSS and GCG success is established and the gains are reproducible, the work would be significant for showing that positional choice is a first-class, low-cost lever for optimization-based attacks and for supplying a plug-in mechanism that improves multiple existing methods without altering their core optimizers. The open-source release is a positive factor for reproducibility.
major comments (3)
- [Empirical investigation / abstract] Empirical investigation section: the premise that 'vulnerability to jailbreaking is highly related to the selection of the slots' is used both to motivate VSS and to justify restricting optimization to high-VSS slots, yet the abstract supplies no evidence that the probe used to compute VSS predicts success under the actual greedy coordinate gradient procedure; if the probe differs (e.g., direct substitution vs. full GCG), the reported 14% ASR lift may be attributable to multi-position search rather than VSS ranking itself.
- [Experiments] Experiments section: the 14% and 42% ASR improvements are stated without reference to specific models, datasets, number of trials, variance, or statistical tests; absent these details it is impossible to assess whether the gains survive multiple-testing correction or post-hoc selection of favorable prompts.
- [SlotGCG method] Method description: no ablation is described that compares VSS-guided selection against random or uniform slot selection under identical optimization budgets; without this control the contribution of the VSS metric versus simply evaluating multiple insertion points remains unclear.
minor comments (2)
- [abstract] The abstract states 'adds only 200ms of preprocessing time' but does not specify hardware or whether this cost scales with prompt length or number of candidate slots.
- [Method] Notation for VSS is introduced without an explicit formula or pseudocode in the provided abstract; a compact definition would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Empirical investigation / abstract] Empirical investigation section: the premise that 'vulnerability to jailbreaking is highly related to the selection of the slots' is used both to motivate VSS and to justify restricting optimization to high-VSS slots, yet the abstract supplies no evidence that the probe used to compute VSS predicts success under the actual greedy coordinate gradient procedure; if the probe differs (e.g., direct substitution vs. full GCG), the reported 14% ASR lift may be attributable to multi-position search rather than VSS ranking itself.
Authors: We agree the abstract is brief and does not explicitly link the VSS probe to GCG outcomes. The empirical section shows high-VSS slots improve GCG results, but to address the concern that gains may stem from multi-position search alone, we will add a correlation analysis between VSS ranks and GCG success rates in the revision. revision: partial
-
Referee: [Experiments] Experiments section: the 14% and 42% ASR improvements are stated without reference to specific models, datasets, number of trials, variance, or statistical tests; absent these details it is impossible to assess whether the gains survive multiple-testing correction or post-hoc selection of favorable prompts.
Authors: We accept this point. The revised manuscript will specify the models (Llama-2-7B, Vicuna-7B), dataset (AdvBench, 100 prompts), trial counts, report mean ASR with standard deviation, and include statistical tests for the reported gains. revision: yes
-
Referee: [SlotGCG method] Method description: no ablation is described that compares VSS-guided selection against random or uniform slot selection under identical optimization budgets; without this control the contribution of the VSS metric versus simply evaluating multiple insertion points remains unclear.
Authors: This is a fair criticism. We will add an ablation comparing VSS-guided, random, and uniform slot selection under matched optimization budgets to isolate the VSS contribution in the revision. revision: yes
Circularity Check
No significant circularity; empirical premise leads to independent heuristic
full rationale
The paper's chain begins with an empirical scan of slot positions (abstract), defines VSS from those observations, then applies VSS to select insertion points for an otherwise standard GCG optimization. No equation or procedure is shown to reduce the reported ASR gains to a quantity fitted inside the same loop; VSS is a preprocessing score, not a fitted parameter renamed as prediction. No self-citation load-bearing steps or uniqueness theorems are invoked. The method is presented as attack-agnostic and externally validated on multiple models, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Vulnerable Slot Score (VSS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2019 , eprint=
Insertion Transformer: Flexible Sequence Generation via Insertion Operations , author=. 2019 , eprint=
2019
-
[2]
Proceedings of the 36th International Conference on Machine Learning , pages =
Insertion Transformer: Flexible Sequence Generation via Insertion Operations , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[3]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[4]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[5]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[6]
arXiv preprint arXiv:2504.07139 , year=
Artificial intelligence index report 2025 , author=. arXiv preprint arXiv:2504.07139 , year=
arXiv 2025
-
[7]
arXiv preprint arXiv:2407.04295 , year=
Jailbreak attacks and defenses against large language models: A survey , author=. arXiv preprint arXiv:2407.04295 , year=
-
[8]
arXiv preprint arXiv:2410.16327 , year=
Feint and attack: Attention-based strategies for jailbreaking and protecting llms , author=. arXiv preprint arXiv:2410.16327 , year=
-
[9]
arXiv preprint arXiv:2506.12880 , year=
Universal Jailbreak Suffixes Are Strong Attention Hijackers , author=. arXiv preprint arXiv:2506.12880 , year=
-
[10]
2024 , eprint=
A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models , author=. 2024 , eprint=
2024
-
[11]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[12]
arXiv preprint arXiv:2309.02705 , year=
Certifying llm safety against adversarial prompting , author=. arXiv preprint arXiv:2309.02705 , year=
-
[13]
arXiv preprint arXiv:2406.19845 , year=
Virtual context: Enhancing jailbreak attacks with special token injection , author=. arXiv preprint arXiv:2406.19845 , year=
-
[14]
arXiv preprint arXiv:2411.01077 , year=
Emoji attack: Enhancing jailbreak attacks against judge llm detection , author=. arXiv preprint arXiv:2411.01077 , year=
-
[15]
International Conference on Machine Learning , pages=
Automatically auditing large language models via discrete optimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[16]
CoRR , year=
From noise to clarity: Unraveling the adversarial suffix of large language model attacks via translation of text embeddings , author=. CoRR , year=
-
[17]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Boosting jailbreak attack with momentum , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[18]
arXiv preprint arXiv:2505.09602 , year=
Adversarial Suffix Filtering: a Defense Pipeline for LLMs , author=. arXiv preprint arXiv:2505.09602 , year=
-
[20]
arXiv preprint arXiv:2502.03052 , year=
Understanding and enhancing the transferability of jailbreaking attacks , author=. arXiv preprint arXiv:2502.03052 , year=
-
[21]
arXiv preprint arXiv:2507.04365 , year=
Attention Slipping: A Mechanistic Understanding of Jailbreak Attacks and Defenses in LLMs , author=. arXiv preprint arXiv:2507.04365 , year=
-
[22]
Annals of operations research , volume=
An overview of bilevel optimization , author=. Annals of operations research , volume=. 2007 , publisher=
2007
-
[23]
Advances in Neural Information Processing Systems , volume=
Tree of attacks: Jailbreaking black-box llms automatically , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
arXiv preprint arXiv:2312.04782 , year=
Make them spill the beans! coercive knowledge extraction from (production) llms , author=. arXiv preprint arXiv:2312.04782 , year=
-
[25]
arXiv preprint arXiv:2401.17256 , year=
Weak-to-strong jailbreaking on large language models , author=. arXiv preprint arXiv:2401.17256 , year=
-
[26]
arXiv preprint arXiv:2311.03191 , year=
Deepinception: Hypnotize large language model to be jailbreaker , author=. arXiv preprint arXiv:2311.03191 , year=
-
[27]
arXiv preprint arXiv:2310.06387 , year=
Jailbreak and guard aligned language models with only few in-context demonstrations , author=. arXiv preprint arXiv:2310.06387 , year=
-
[28]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[29]
arXiv preprint arXiv:2308.06463 , year=
Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher , author=. arXiv preprint arXiv:2308.06463 , year=
-
[30]
arXiv preprint arXiv:2310.02446 , year=
Low-resource languages jailbreak gpt-4 , author=. arXiv preprint arXiv:2310.02446 , year=
-
[31]
arXiv preprint arXiv:2307.08715 , year=
Masterkey: Automated jailbreak across multiple large language model chatbots , author=. arXiv preprint arXiv:2307.08715 , year=
-
[32]
do anything now
" do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models , author=. Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages=
2024
-
[33]
arXiv preprint arXiv:2308.14132 , year=
Detecting language model attacks with perplexity , author=. arXiv preprint arXiv:2308.14132 , year=
-
[34]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Jailbreaking black box large language models in twenty queries , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
2025
-
[35]
Advances in Neural Information Processing Systems , volume=
Jailbroken: How does llm safety training fail? , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
arXiv preprint arXiv:2412.08615 , year=
Exploiting the index gradients for optimization-based jailbreaking on large language models , author=. arXiv preprint arXiv:2412.08615 , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
Accelerating greedy coordinate gradient and general prompt optimization via probe sampling , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
arXiv preprint arXiv:2307.15043 , year=
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[40]
arXiv preprint arXiv:2405.21018 , year=
Improved techniques for optimization-based jailbreaking on large language models , author=. arXiv preprint arXiv:2405.21018 , year=
-
[41]
arXiv preprint arXiv:2410.09040 , year=
AttnGCG: Enhancing jailbreaking attacks on LLMs with attention manipulation , author=. arXiv preprint arXiv:2410.09040 , year=
-
[42]
arXiv preprint arXiv:2410.15362 , year=
deepinceptioner-gcg: Efficient discrete optimization jailbreak attacks against aligned large language models , author=. arXiv preprint arXiv:2410.15362 , year=
-
[43]
arXiv preprint arXiv:2311.08268 , year=
A wolf in sheep's clothing: Generalized nested jailbreak prompts can fool large language models easily , author=. arXiv preprint arXiv:2311.08268 , year=
-
[44]
arXiv preprint arXiv:2309.00614 , year=
Baseline defenses for adversarial attacks against aligned language models , author=. arXiv preprint arXiv:2309.00614 , year=
-
[45]
arXiv preprint arXiv:2310.03684 , year=
Smoothllm: Defending large language models against jailbreaking attacks , author=. arXiv preprint arXiv:2310.03684 , year=
-
[46]
arXiv preprint arXiv:2402.16192 , year=
Defending large language models against jailbreak attacks via semantic smoothing , author=. arXiv preprint arXiv:2402.16192 , year=
-
[47]
34th USENIX Security Symposium (USENIX Security 25) , pages=
\ SelfDefend \ : \ LLMs \ Can Defend Themselves against Jailbreaking in a Practical Manner , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[48]
arXiv preprint arXiv:2006.03654 , year=
Deberta: Decoding-enhanced bert with disentangled attention , author=. arXiv preprint arXiv:2006.03654 , year=
Pith/arXiv arXiv 2006
-
[49]
arXiv preprint arXiv:2111.09543 , year=
Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing , author=. arXiv preprint arXiv:2111.09543 , year=
-
[50]
arXiv preprint arXiv:2108.12409 , year=
Train short, test long: Attention with linear biases enables input length extrapolation , author=. arXiv preprint arXiv:2108.12409 , year=
-
[51]
arXiv preprint arXiv:2305.14493 , year=
Do prompt positions really matter? , author=. arXiv preprint arXiv:2305.14493 , year=
-
[52]
arXiv preprint arXiv:2311.03348 , year=
Scalable and transferable black-box jailbreaks for language models via persona modulation , author=. arXiv preprint arXiv:2311.03348 , year=
-
[53]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[54]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[55]
See https://vicuna
Vicuna: An open-source chatbot impressing gpt-4 with 90\ author=. See https://vicuna. lmsys. org (accessed 14 April 2023) , volume=
2023
-
[56]
arXiv preprint arXiv:2310.08825 , year=
From clip to dino: Visual encoders shout in multi-modal large language models , author=. arXiv preprint arXiv:2310.08825 , year=
-
[57]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[58]
arXiv preprint arXiv:2310.04451 , year=
Autodan: Generating stealthy jailbreak prompts on aligned large language models , author=. arXiv preprint arXiv:2310.04451 , year=
-
[59]
arXiv preprint arXiv:2404.07921 , year=
Amplegcg: Learning a universal and transferable generative model of adversarial suffixes for jailbreaking both open and closed llms , author=. arXiv preprint arXiv:2404.07921 , year=
-
[60]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[61]
Advances in Neural Information Processing Systems , volume=
Robust prompt optimization for defending language models against jailbreaking attacks , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
arXiv preprint arXiv:2402.08983 , year=
Safedecoding: Defending against jailbreak attacks via safety-aware decoding , author=. arXiv preprint arXiv:2402.08983 , year=
-
[63]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[64]
arXiv preprint arXiv:2508.00555 , year=
Activation-Guided Local Editing for Jailbreaking Attacks , author=. arXiv preprint arXiv:2508.00555 , year=
-
[65]
arXiv preprint arXiv:2509.06350 , year=
Mask-GCG: Are All Tokens in Adversarial Suffixes Necessary for Jailbreak Attacks? , author=. arXiv preprint arXiv:2509.06350 , year=
-
[66]
arXiv preprint arXiv:2405.04346 , year=
Revisiting character-level adversarial attacks for language models , author=. arXiv preprint arXiv:2405.04346 , year=
-
[67]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Gradient-based adversarial attacks against text transformers , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.