Enhancing Software Engineering Through Closed-Loop Memory Optimization
Pith reviewed 2026-06-28 00:40 UTC · model grok-4.3
The pith
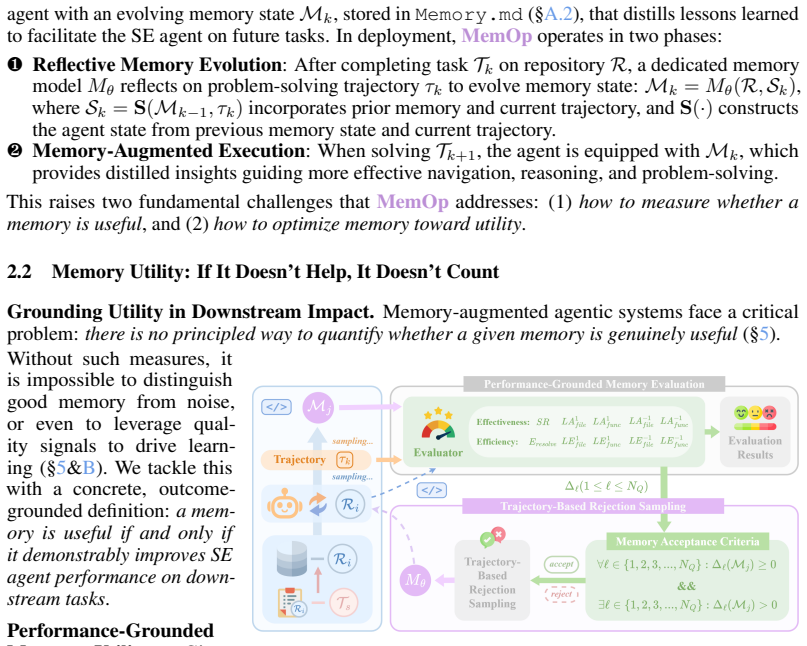
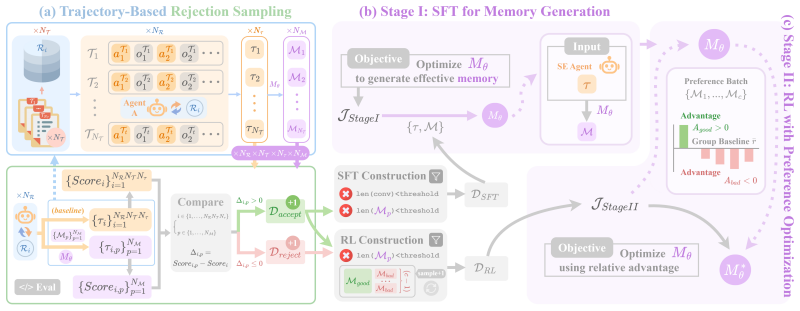
Closed-loop memory framework defines utility from downstream task impact to improve SE agents without labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
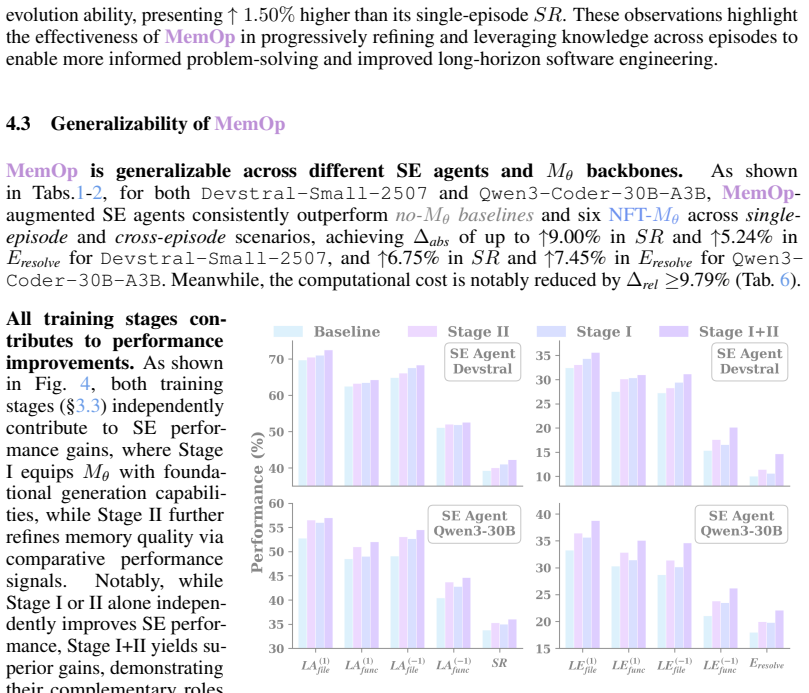
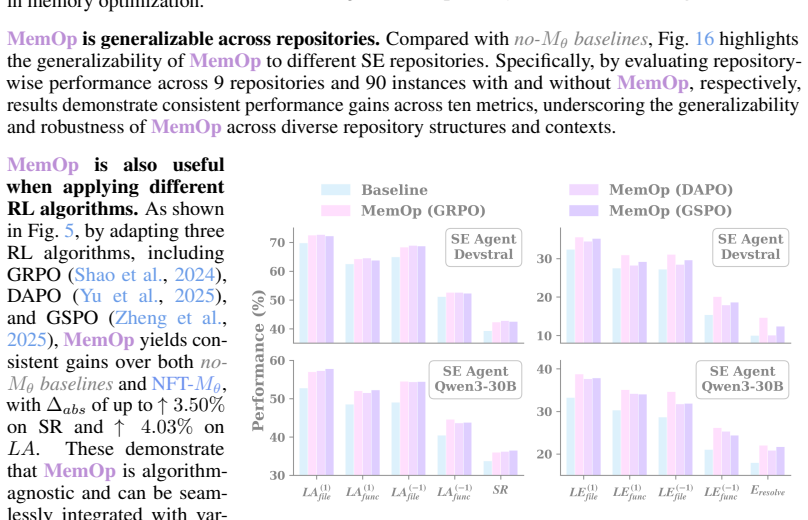
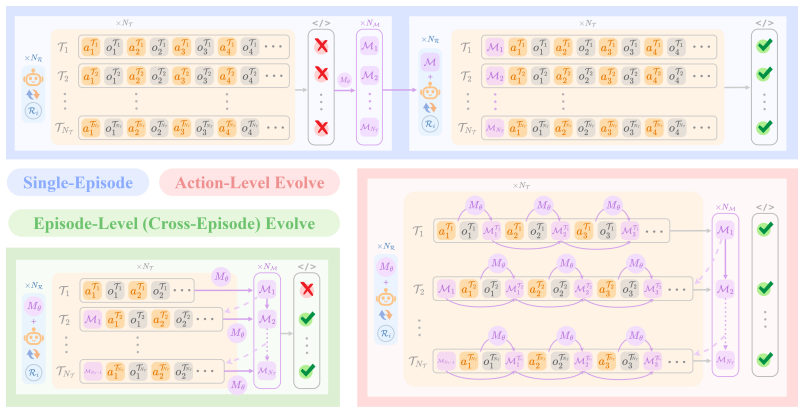
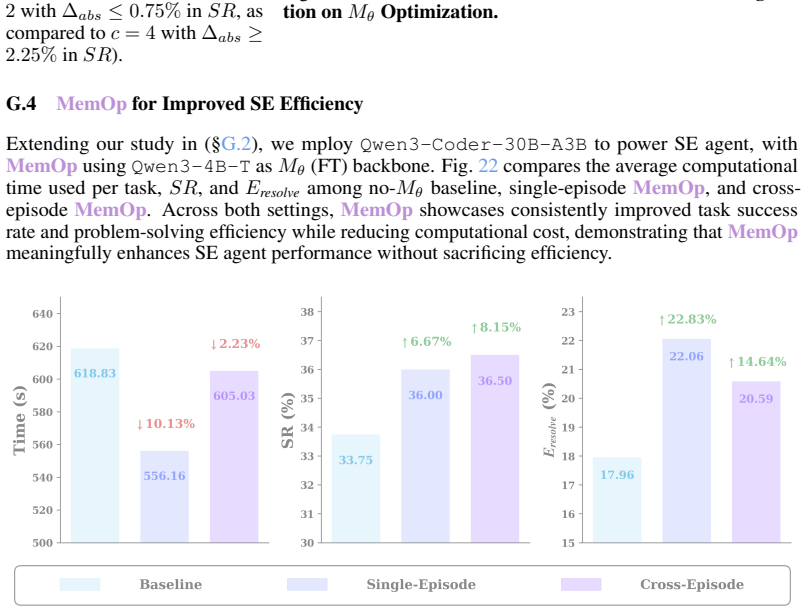
Ours is a closed-loop framework that grounds memory utility in validated downstream impact, establishing it as a task-agnostic evaluation benchmark and annotation-free optimization signal; complementary evaluation on single-episode and cross-episode memory augmentation shows it improves SE agents with absolute gains of up to 5.25% success rate and 4.63% resolve efficiency while reducing computational cost by at least 9.79%.
What carries the argument
Ours, the closed-loop framework that treats validated downstream task impact as the sole definition of memory utility for both evaluation and optimization.
If this is right
- SE agents can retain and reuse experiences across tasks instead of reconstructing context each time.
- Memory selection becomes possible without task-specific annotations or human labels.
- Performance gains appear in both single-task and multi-task memory augmentation settings.
- Computational cost drops while success rate and resolve efficiency rise.
- The same utility signal serves simultaneously as an evaluation metric and an optimization objective.
Where Pith is reading between the lines
- The same downstream-impact definition could be applied to memory management in LLM agents outside software engineering.
- If the utility signal proves stable, it could support iterative refinement of memory stores over many episodes without external supervision.
- Cross-episode augmentation may compound gains over time if early improvements feed into later memory selections.
Load-bearing premise
Memory utility can be defined in a task-agnostic way solely from validated downstream task impact without needing task-specific knowledge or manual labels.
What would settle it
A controlled experiment in which memory selected purely by downstream impact either fails to raise success rate or raises computational cost when applied to a new set of SE tasks or a different base agent.
Figures



















read the original abstract
Large language models (LLMs) have enabled powerful software engineering (SE) agents capable of navigating complex codebases and resolving real-world issues. However, these agents remain fundamentally episodic: they fail to retain, refine, and reuse experiences across tasks, repeatedly reconstructing context from scratch and reproducing similar mistakes. Even with memory support, they offer no remedy for the absence of a principled, task-agnostic \textit{memory utility}, making them difficult to evaluate rigorously or generalize across agents and settings. To tackle these limitations, we introduce \ours, a closed-loop framework for memory augmentation in SE agents. \ours grounds memory utility in \textit{validated downstream impact}, establishing utility as both a task-agnostic \textbf{evaluation benchmark} and an annotation-free \textbf{optimization signal}. Through complementary evaluation on \textit{single-episode} and \textit{cross-episode} memory augmentation, results demonstrate that \ours consistently improves SE agents across settings, achieving absolute gains of up to $\uparrow5.25\%$ in success rate and $\uparrow4.63\%$ in resolve efficiency, while substantially reducing computational cost by $\geq9.79\%$. Our project page: \href{https://xhguo7.github.io/MemOp/}{https://xhguo7.github.io/MemOp/}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces \\\ours, a closed-loop framework for memory augmentation in SE agents. It grounds memory utility in validated downstream task impact, establishing it as both a task-agnostic evaluation benchmark and an annotation-free optimization signal. Complementary evaluations on single-episode and cross-episode memory augmentation are claimed to show consistent improvements, with absolute gains of up to ↑5.25% in success rate, ↑4.63% in resolve efficiency, and ≥9.79% reduction in computational cost.
Significance. If the results hold under proper verification, the closed-loop construction offers a task-agnostic way to optimize and evaluate memory in LLM-based SE agents, addressing their episodic limitations without requiring manual labels or task-specific knowledge. This could improve generalizability across agents and settings.
major comments (2)
- [Abstract] Abstract: The abstract states quantitative improvements (↑5.25% success rate, ↑4.63% resolve efficiency, ≥9.79% cost reduction) but supplies no experimental protocol, baselines, statistical tests, dataset details, or error analysis; the central performance claims cannot be evaluated from the given text.
- [Abstract] The closed-loop design risks circularity if task success is used both to define and to optimize the same memory utility signal; the manuscript must demonstrate that the downstream-impact signal is independent of the optimization loop (see weakest assumption in stress-test note).
minor comments (1)
- The project page link is provided but the manuscript should include a brief summary of what additional materials (code, data) are available there.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states quantitative improvements (↑5.25% success rate, ↑4.63% resolve efficiency, ≥9.79% cost reduction) but supplies no experimental protocol, baselines, statistical tests, dataset details, or error analysis; the central performance claims cannot be evaluated from the given text.
Authors: The abstract is intentionally concise to summarize contributions and results. Full details on the experimental protocol, baselines (standard SE agents and memory-augmented variants), statistical tests, datasets (SE benchmarks used), and error analysis appear in Sections 4 and 5. We will revise the abstract to briefly reference the evaluation settings and primary baselines for improved clarity. revision: yes
-
Referee: [Abstract] The closed-loop design risks circularity if task success is used both to define and to optimize the same memory utility signal; the manuscript must demonstrate that the downstream-impact signal is independent of the optimization loop (see weakest assumption in stress-test note).
Authors: We appreciate the concern about potential circularity. The memory utility is computed from downstream impact on a held-out validation task set that is excluded from the optimization loop; the loop then uses this precomputed signal for memory selection, while final gains are measured on disjoint test tasks. This separation maintains independence. We will add explicit discussion of the separation and address the noted stress-test assumptions in the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper explicitly frames its core contribution as a closed-loop construction that defines memory utility directly from validated downstream task impact and then uses that same impact as both benchmark and optimization signal. This is presented as an intentional design choice rather than a hidden reduction. No equations, fitted parameters, or self-citations are exhibited in the provided text that would make the reported gains (success rate, resolve efficiency, cost reduction) equivalent to the inputs by construction. The empirical outcomes are described as results of applying the framework, and the argument remains self-contained once the closed-loop premise is granted. No load-bearing step reduces to a self-definition or fitted input in the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future , author=. 2025 , eprint=
2025
-
[2]
2025 , eprint=
A Comprehensive Survey on Benchmarks and Solutions in Software Engineering of LLM-Empowered Agentic System , author=. 2025 , eprint=
2025
-
[3]
2026 , url =
Position: Humans are Missing from AI Coding Agent Research , author =. 2026 , url =
2026
-
[4]
2025 , eprint=
OpenHands: An Open Platform for AI Software Developers as Generalist Agents , author=. 2025 , eprint=
2025
-
[5]
ArXiv , year=
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering , author=. ArXiv , year=
-
[6]
2025 , url=
Claude Code , author=. 2025 , url=
2025
-
[7]
Annual Meeting of the Association for Computational Linguistics , year=
CodeAgent: Enhancing Code Generation with Tool-Integrated Agent Systems for Real-World Repo-level Coding Challenges , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[8]
ArXiv , year=
MAGIS: LLM-Based Multi-Agent Framework for GitHub Issue Resolution , author=. ArXiv , year=
-
[9]
arXiv preprint arXiv:2502.06994 , year=
SyncMind: Measuring Agent Out-of-Sync Recovery in Collaborative Software Engineering , author=. arXiv preprint arXiv:2502.06994 , year=
-
[10]
International Conference on Machine Learning , year=
PatchPilot: A Cost-Efficient Software Engineering Agent with Early Attempts on Formal Verification , author=. International Conference on Machine Learning , year=
-
[11]
2025 , url=
GPT Docs , author=. 2025 , url=
2025
-
[12]
2025 , url=
Claude Docs , author=. 2025 , url=
2025
-
[13]
2025 , url=
GPT API Pricing , author=. 2025 , url=
2025
-
[14]
2025 , url=
Claude API Pricing , author=. 2025 , url=
2025
-
[15]
Transactions of the Association for Computational Linguistics , year=
Lost in the Middle: How Language Models Use Long Contexts , author=. Transactions of the Association for Computational Linguistics , year=
-
[16]
ArXiv , year=
BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack , author=. ArXiv , year=
-
[17]
L oo GLE : Can Long-Context Language Models Understand Long Contexts?
Li, Jiaqi and Wang, Mengmeng and Zheng, Zilong and Zhang, Muhan. L oo GLE : Can Long-Context Language Models Understand Long Contexts?. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.859
-
[18]
Efficient Solutions For An Intriguing Failure of LLM s: Long Context Window Does Not Mean LLM s Can Analyze Long Sequences Flawlessly
Hosseini, Peyman and Castro, Ignacio and Ghinassi, Iacopo and Purver, Matthew. Efficient Solutions For An Intriguing Failure of LLM s: Long Context Window Does Not Mean LLM s Can Analyze Long Sequences Flawlessly. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[19]
2025 , eprint=
MemoRAG: Boosting Long Context Processing with Global Memory-Enhanced Retrieval Augmentation , author=. 2025 , eprint=
2025
-
[20]
Lifelong Model Editing with Graph-Based External Memory
Atri, Yash Kumar and Alaa, Ahmed and Hartvigsen, Thomas. Lifelong Model Editing with Graph-Based External Memory. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.690
-
[21]
Kashmira, Savini and Dantanarayana, Jayanaka L. and Brodsky, Joshua and Mahendra, Ashish and Kang, Yiping and Flautner, Krisztian and Tang, Lingjia and Mars, Jason. TOBUG raph: Knowledge Graph-Based Retrieval for Enhanced LLM Performance Beyond RAG. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track. 202...
-
[22]
2024 , eprint=
M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Multiple Partitions , author=. 2024 , eprint=
2024
-
[23]
Chen, Qinwen and Tao, Wenbiao and Zhu, Zhiwei and Xi, Mingfan and Guo, Liangzhong and Wang, Yuan and Wang, Wei and Lan, Yunshi. C om RAG : Retrieval-Augmented Generation with Dynamic Vector Stores for Real-time Community Question Answering in Industry. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Indus...
-
[24]
H - MEM : Hierarchical Memory for High-Efficiency Long-Term Reasoning in LLM Agents
Sun, Haoran and Zeng, Shaoning and Zhang, Bob. H - MEM : Hierarchical Memory for High-Efficiency Long-Term Reasoning in LLM Agents. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 2026. doi:10.18653/v1/2026.eacl-long.15
-
[25]
Lindenbauer, Tobias and Groh, Georg and Schuetze, Hinrich. From Knowledge to Noise: CTIM -Rover and the Pitfalls of Episodic Memory in Software Engineering Agents. Proceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025). 2025. doi:10.18653/v1/2025.realm-1.30
-
[26]
2024 , eprint=
CAMELoT: Towards Large Language Models with Training-Free Consolidated Associative Memory , author=. 2024 , eprint=
2024
-
[27]
2023 , eprint=
MemoryBank: Enhancing Large Language Models with Long-Term Memory , author=. 2023 , eprint=
2023
-
[28]
2025 , eprint=
MemInsight: Autonomous Memory Augmentation for LLM Agents , author=. 2025 , eprint=
2025
-
[29]
2026 , eprint=
Structurally Aligned Subtask-Level Memory for Software Engineering Agents , author=. 2026 , eprint=
2026
-
[30]
2025 , eprint=
SWE-Bench-CL: Continual Learning for Coding Agents , author=. 2025 , eprint=
2025
-
[31]
ArXiv , year=
Compress to Impress: Unleashing the Potential of Compressive Memory in Real-World Long-Term Conversations , author=. ArXiv , year=
-
[32]
ArXiv , year=
Improving Code Localization with Repository Memory , author=. ArXiv , year=
-
[33]
2026 , eprint=
MemGovern: Enhancing Code Agents through Learning from Governed Human Experiences , author=. 2026 , eprint=
2026
-
[34]
Wang, Ye and Xu, Xinrun and Ding, Zhiming. M ind R ef: Mimicking Human Memory for Hierarchical Reference Retrieval with Fine-Grained Location Awareness. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2025. doi:10.18653/v1/2025.acl-short.67
-
[35]
Yoshida, Ryo and Isono, Shinnosuke and Kajikawa, Kohei and Someya, Taiga and Sugimoto, Yushi and Oseki, Yohei. If Attention Serves as a Cognitive Model of Human Memory Retrieval, What is the Plausible Memory Representation?. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/...
-
[36]
Knowledge Graph-Driven Memory Editing with Directional Interventions
Fu, Jinhu and Wang, Kun and Guo, Chongye and Fang, Junfeng and Zhang, Wentao and Su, Sen. Knowledge Graph-Driven Memory Editing with Directional Interventions. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.261
-
[37]
Hu, Mengkang and Chen, Tianxing and Chen, Qiguang and Mu, Yao and Shao, Wenqi and Luo, Ping. H i A gent: Hierarchical Working Memory Management for Solving Long-Horizon Agent Tasks with Large Language Model. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1575
-
[38]
2025 , eprint=
General Agentic Memory Via Deep Research , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
LightMem: Lightweight and Efficient Memory-Augmented Generation , author=. 2025 , eprint=
2025
-
[40]
Towards Lifelong Dialogue Agents via Timeline-based Memory Management
Ong, Kai Tzu-iunn and Kim, Namyoung and Gwak, Minju and Chae, Hyungjoo and Kwon, Taeyoon and Jo, Yohan and Hwang, Seung-won and Lee, Dongha and Yeo, Jinyoung. Towards Lifelong Dialogue Agents via Timeline-based Memory Management. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Hum...
-
[41]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[42]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[43]
2025 , eprint=
Group Sequence Policy Optimization , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[45]
2025 , url=
Devstral Model , author=. 2025 , url=
2025
-
[46]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[47]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[48]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[49]
2025 , url=
Claude 4 Sonnet , author=. 2025 , url=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.