Do More Agents Help? Controlled and Protocol-Aligned Evaluation of LLM Agent Workflows
Pith reviewed 2026-06-28 01:40 UTC · model grok-4.3
The pith
Controlled tests show most multi-agent LLM workflows trail single-agent baselines on average accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
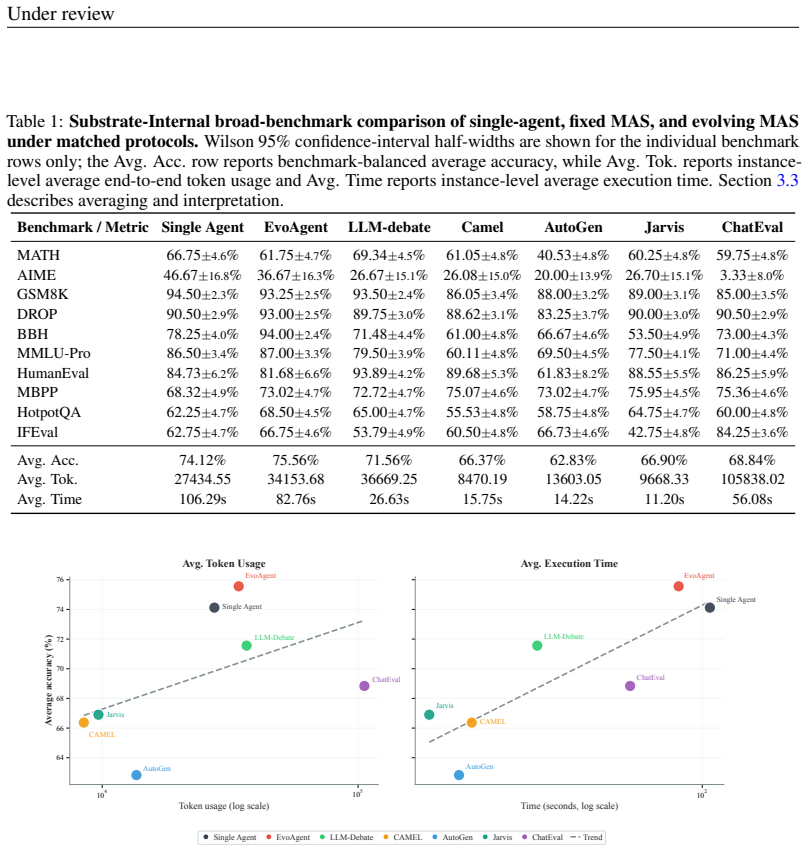
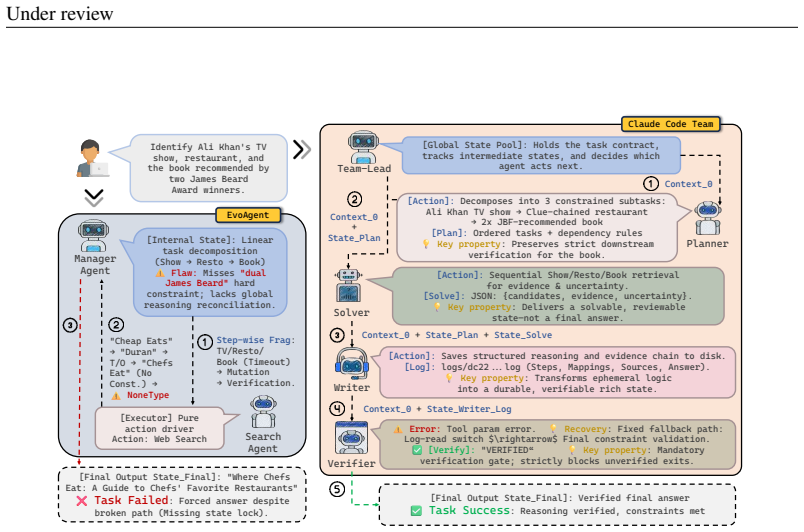
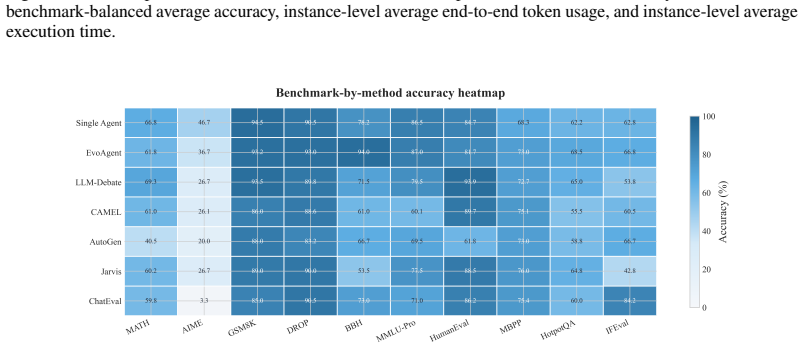
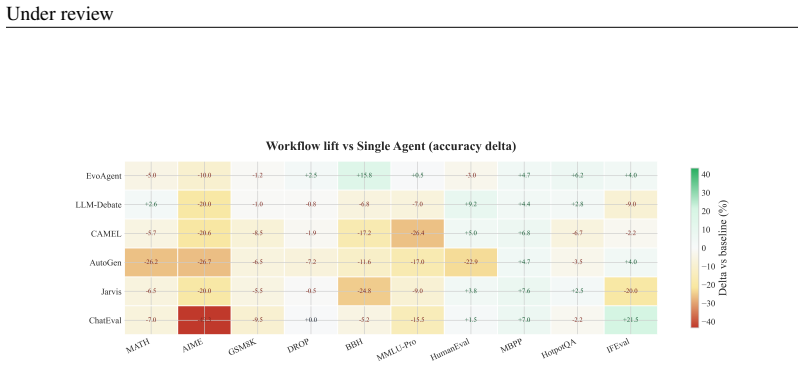
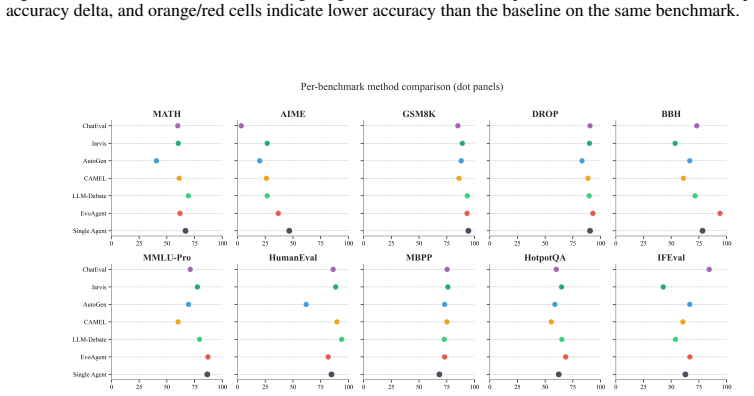
Under standardized implementation conditions, at most one of six tested multi-agent systems exceeds the performance of a matched single-agent system on benchmark-balanced average accuracy, with the others trailing by 2.56-11.29 points and showing inferior accuracy-cost trade-offs. On the protocol-aligned external GAIA snapshot, a Claude-Code-style runtime workflow reaches 66.72 percent overall and 69.23 percent on Level 3, exceeding the strongest fixed multi-agent baseline by more than 20 points.
What carries the argument
BenchAgent, the evaluation framework that normalizes single-agent, fixed multi-agent, and evolving multi-agent workflows under identical execution and logging protocols.
If this is right
- Five of the six multi-agent systems occupy strictly worse accuracy-cost positions than their single-agent anchors.
- EvoAgent is the sole multi-agent system whose accuracy lies inside the statistical guidance interval of the single-agent baseline.
- A runtime-generated workflow can exceed fixed multi-agent performance on the GAIA benchmark under protocol-aligned external conditions.
- Benchmark-balanced average accuracy and cost must both be reported to evaluate whether added agents deliver net benefit.
- Protocol differences between single-agent and multi-agent substrates must be eliminated before attributing performance gaps to agent count.
Where Pith is reading between the lines
- Optimizing a single agent may be a higher-leverage first step than adding more agents for many reasoning and tool-use tasks.
- The results raise the possibility that literature gains attributed to multi-agent designs partly reflect uneven optimization effort rather than the presence of multiple agents.
- Future protocol designs could include explicit single-agent ablation arms as a required control.
- The GAIA result suggests that dynamic, runtime-generated agent graphs warrant separate study from fixed multi-agent topologies.
Load-bearing premise
The single-agent implementations are configured and optimized to the same standard as the multi-agent ones inside the shared BenchAgent protocol.
What would settle it
A replication in which any of the five underperforming multi-agent systems is re-run after its single-agent counterpart receives identical prompt engineering, tool-call budgets, and iteration limits, and the multi-agent system still trails, would be consistent with the claim; the claim would be falsified by the opposite outcome.
Figures





read the original abstract
Does adding more agents help an LLM workflow once compared systems share the same benchmark loader, tool access, answer contract, usage accounting, and trajectory logging? We introduce BenchAgent, an evaluation framework that places single-agent, fixed multi-agent (MAS), and evolving MAS workflows under one normalized execution and logging protocol. BenchAgent evaluates these substrate-internal workflows across ten reasoning, coding, and tool-use benchmarks with GPT-4.1, and separately reports a Protocol-Aligned External (PAE) GAIA study of a runtime-generated workflow. Under SI conditions, at most one of six tested MAS exceeds the matched single-agent anchor on benchmark-balanced average accuracy: EvoAgent lies within the Wilson one-run guidance, while the remaining five trail by 2.56-11.29 points and occupy more expensive accuracy-cost trade-offs. On the PAE GAIA snapshot, a Claude-Code-style runtime workflow reaches 66.72% overall and 69.23% on Level 3, more than 20 points above the strongest non-Claude baseline, Jarvis, a fixed MAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BenchAgent, a normalized evaluation framework that places single-agent, fixed multi-agent (MAS), and evolving MAS workflows under identical benchmark loaders, tool access, answer contracts, usage accounting, and trajectory logging. It reports results across ten reasoning/coding/tool-use benchmarks with GPT-4.1 plus a Protocol-Aligned External (PAE) GAIA snapshot, claiming that under SI conditions at most one of six tested MAS (EvoAgent) matches or exceeds the matched single-agent anchor on benchmark-balanced average accuracy while the other five trail by 2.56–11.29 points and incur higher costs; a Claude-Code-style runtime workflow reaches 66.72% overall on the GAIA snapshot.
Significance. If the single-agent baselines receive equivalent optimization effort, the controlled comparison supplies direct empirical evidence that simply increasing agent count does not improve accuracy and often worsens the accuracy-cost trade-off. The use of Wilson one-run guidance for statistical reference and the explicit protocol normalization are strengths that make the measurements more reproducible than typical ad-hoc MAS evaluations.
major comments (2)
- [§3 (BenchAgent protocol) and §4 (benchmark results)] The central comparative claim (abstract and §4 results) requires that single-agent implementations were tuned to the same hyper-parameter and prompt-engineering standard as the MAS variants inside BenchAgent. The manuscript normalizes loader, tools, logging and accounting but does not report iteration counts, prompt-search effort, or ablation results showing that the single-agent code paths received comparable optimization; without this, the reported 2.56–11.29 point deficits cannot be unambiguously attributed to agent count rather than substrate treatment disparity.
- [Table 2 and associated Wilson guidance paragraph] Table 2 (or equivalent benchmark-balanced average table) reports EvoAgent within Wilson guidance while the other five MAS trail; however, the paper does not provide per-benchmark variance or the exact number of runs underlying the Wilson interval, making it impossible to assess whether the “within guidance” statement for EvoAgent is robust or sensitive to run count.
minor comments (2)
- [§5 (PAE GAIA study)] The GAIA PAE snapshot is described as “runtime-generated” but the exact generation prompt and stopping criteria are not listed; adding them would improve reproducibility.
- [Figure 1] Figure 1 (accuracy-cost scatter) uses different marker styles for single-agent vs MAS but the legend does not explicitly state that all points share the same underlying model (GPT-4.1) and tool set; a one-sentence clarification would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for emphasizing the need for unambiguous attribution in controlled comparisons. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3 (BenchAgent protocol) and §4 (benchmark results)] The central comparative claim (abstract and §4 results) requires that single-agent implementations were tuned to the same hyper-parameter and prompt-engineering standard as the MAS variants inside BenchAgent. The manuscript normalizes loader, tools, logging and accounting but does not report iteration counts, prompt-search effort, or ablation results showing that the single-agent code paths received comparable optimization; without this, the reported 2.56–11.29 point deficits cannot be unambiguously attributed to agent count rather than substrate treatment disparity.
Authors: We agree that explicit documentation of optimization effort strengthens causal attribution. Under BenchAgent, the single-agent baselines use the canonical prompts and hyper-parameters supplied by each benchmark (or their reference implementations), modified only to satisfy the shared loader, tool schema, answer contract, and logging interface. The six MAS variants were ported from their original papers into the identical substrate, with prompt adjustments limited to the same answer format and tool-calling contract; no additional hyper-parameter sweeps or prompt-search loops were performed on either side beyond what was required for protocol compliance. This design choice keeps the comparison focused on the effect of adding agent coordination layers rather than on differential tuning investment. Nevertheless, we acknowledge that the manuscript does not quantify iteration counts or present an ablation of prompt-engineering effort. In the revision we will add a dedicated paragraph in §3 describing the exact adaptation steps taken for single-agent versus MAS prompts and will state that no further optimization was applied to either class. We will also note this as a limitation and suggest that future work could include matched tuning budgets. revision_made = partial revision: partial
-
Referee: [Table 2 and associated Wilson guidance paragraph] Table 2 (or equivalent benchmark-balanced average table) reports EvoAgent within Wilson guidance while the other five MAS trail; however, the paper does not provide per-benchmark variance or the exact number of runs underlying the Wilson interval, making it impossible to assess whether the “within guidance” statement for EvoAgent is robust or sensitive to run count.
Authors: All results reported in the manuscript, including the single-agent anchor and the six MAS systems, were obtained from exactly one run per system per benchmark; the Wilson one-run guidance is therefore computed under n=1 for every entry. The guidance serves as a conservative statistical reference indicating whether an observed difference lies inside the binomial sampling interval expected from a single trial. We will revise the manuscript to (i) state the run count explicitly in the caption of Table 2 and in the Wilson paragraph, (ii) move the full per-benchmark accuracy matrix to an appendix so readers can recompute variances or confidence intervals themselves, and (iii) add a short sensitivity note confirming that the “within guidance” classification for EvoAgent holds under the reported single-run protocol. These changes make the statistical claim fully auditable without altering the experimental design. revision_made = yes revision: yes
Circularity Check
No circularity: direct empirical measurement under controlled protocol
full rationale
The paper reports benchmark accuracy and cost measurements for single-agent and multi-agent workflows executed under the shared BenchAgent protocol. No equations, fitted parameters, derivations, or self-citation chains appear in the provided text. All central claims are stated as observed outcomes on ten benchmarks plus one PAE GAIA snapshot; they do not reduce to prior fitted values or self-referential definitions. The skeptic concern about optimization parity is a methodological question about experimental controls, not a circularity in any derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ten reasoning, coding, and tool-use benchmarks plus GAIA are valid and representative measures for evaluating LLM agent performance.
Reference graph
Works this paper leans on
-
[1]
Building effective agents
Anthropic . Building effective agents. https://www.anthropic.com/engineering/building-effective-agents, 2024. Official engineering post. Accessed: 2026-04-08
2024
-
[2]
Claude code overview
Anthropic . Claude code overview. https://docs.anthropic.com/en/docs/claude-code/overview, 2025 a . Official documentation. Accessed: 2026-03-25
2025
-
[3]
Claude code
Anthropic . Claude code. https://www.anthropic.com/claude-code, 2025 b . Official product page. Accessed: 2026-03-25
2025
-
[4]
Claude code subagents
Anthropic . Claude code subagents. https://docs.anthropic.com/en/docs/claude-code/subagents, 2025 c . Official documentation. Accessed: 2026-03-25
2025
-
[5]
Effective context engineering for ai agents
Anthropic . Effective context engineering for ai agents. https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents, 2025 d . Official engineering post. Accessed: 2026-04-08
2025
-
[6]
How we built our multi-agent research system
Anthropic . How we built our multi-agent research system. https://www.anthropic.com/engineering/built-multi-agent-research-system, 2025 e . Official engineering post. Accessed: 2026-04-08
2025
-
[7]
Pan, Shuyi Yang, Lakshya A
Mert Cemri, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Why do Multi-Agent LLM systems fail?, 2025
2025
-
[10]
CrewAI documentation
CrewAI . CrewAI documentation. https://docs.crewai.com/, 2026. Official documentation. Accessed: 2026-05-16
2026
-
[13]
Harbor: A framework for evaluating and optimizing sandboxed agents and models
Harbor . Harbor: A framework for evaluating and optimizing sandboxed agents and models. https://www.harborframework.com/, 2026. Official project page. Accessed: 2026-05-09
2026
-
[16]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench : Can language models resolve real-world GitHub issues? In The Twelfth International Conference on Learning Representations, 2024
2024
-
[18]
Yubin Kim, Ken Gu, Chanwoo Park, Chunjong Park, Samuel Schmidgall, A. Ali Heydari, Yao Yan, Zhihan Zhang, Yuchen Zhuang, Yun Liu, Mark Malhotra, Paul Pu Liang, Hae Won Park, Yuzhe Yang, Xuhai Xu, Yilun Du, Shwetak Patel, Tim Althoff, Daniel McDuff, and Xin Liu. Towards a science of scaling agent systems, 2025
2025
-
[19]
LangGraph overview
LangChain . LangGraph overview. https://docs.langchain.com/oss/python/langgraph/overview, 2026. Official documentation. Accessed: 2026-05-16
2026
-
[21]
Junyou Li, Qin Zhang, Yangbin Yu, Qiang Fu, and Deheng Ye. More agents is all you need. Transactions on Machine Learning Research, 2024. arXiv:2402.05120
-
[26]
GPT-4.1 model documentation
OpenAI . GPT-4.1 model documentation. https://platform.openai.com/docs/models/gpt-4.1, 2025. Official documentation. Accessed: 2026-05-09
2025
-
[27]
OpenAI . Codex. https://openai.com/codex/, 2026. Official product page. Accessed: 2026-05-09
2026
-
[28]
Opencode documentation
OpenCode . Opencode documentation. https://opencode.ai/docs/, 2026. Official documentation. Accessed: 2026-05-09
2026
-
[30]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \`i , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Edwin B. Wilson. Probable inference, the law of succession, and statistical inference. Journal of the American Statistical Association, 22 0 (158): 0 209--212, 1927. doi:10.1080/01621459.1927.10502953
-
[39]
Multi-agent architecture search via agentic supernet
Guibin Zhang, Luyang Niu, Junfeng Fang, Kun Wang, Lei Bai, and Xiang Wang. Multi-agent architecture search via agentic supernet. In Forty-Second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=imcyVlzpXh
2025
-
[41]
Silo-Bench : A scalable environment for evaluating distributed coordination in Multi-Agent LLM systems, 2026
Yuzhe Zhang, Feiran Liu, Yi Shan, Xinyi Huang, Xin Yang, Yueqi Zhu, Xuxin Cheng, Cao Liu, Ke Zeng, Terry Jingchen Zhang, and Wenyuan Jiang. Silo-Bench : A scalable environment for evaluating distributed coordination in Multi-Agent LLM systems, 2026
2026
-
[43]
2025 , howpublished =
2025
-
[44]
OpenCode Documentation , year =
-
[45]
Harbor: A Framework for Evaluating and Optimizing Sandboxed Agents and Models , year =
-
[46]
2026 , howpublished =
2026
-
[47]
Claude Code , year =
-
[48]
Claude Code Overview , year =
-
[49]
Claude Code Subagents , year =
-
[50]
Building Effective Agents , year =
-
[51]
How We Built Our Multi-Agent Research System , year =
-
[52]
Effective Context Engineering for AI Agents , year =
-
[53]
ReAct: Synergizing Reasoning and Acting in Language Models
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , title =. arXiv preprint arXiv:2210.03629 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Toolformer: Language Models Can Teach Themselves to Use Tools , journal =
Schick, Timo and Dwivedi-Yu, Jane and Dess. Toolformer: Language Models Can Teach Themselves to Use Tools , journal =
-
[55]
WebGPT: Browser-assisted question-answering with human feedback
Nakano, Reiichiro and Hilton, Jacob and Balaji, Suchir and Wu, Jeff and Ouyang, Long and Kim, Christina and Hesse, Christopher and Jain, Shantanu and Kosaraju, Vineet and Saunders, William and Jiang, Xu and Cobbe, Karl and Eloundou, Tyna and Krueger, Gretchen and Button, Kevin and Knight, Matthew and Chess, Benjamin and Schulman, John , title =. arXiv pre...
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , title =. arXiv preprint arXiv:2405.15793 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
Shen, Yongliang and Song, Kaitao and Tan, Xu and Li, Dongsheng and Lu, Weiming and Zhuang, Yueting , title =. arXiv preprint arXiv:2303.17580 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Khattab, Omar and Singhvi, Arnav and Maheshwari, Paridhi and Zhang, Zhiyuan and Santhanam, Keshav and Vardhamanan, Sri and Haq, Saiful and Sharma, Ashutosh and Joshi, Thomas T. and Moazam, Hanna and Miller, Heather and Zaharia, Matei and Potts, Christopher , title =. arXiv preprint arXiv:2310.03714 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Transactions on Machine Learning Research , year =
Li, Junyou and Zhang, Qin and Yu, Yangbin and Fu, Qiang and Ye, Deheng , title =. Transactions on Machine Learning Research , year =
-
[60]
AgentBench: Evaluating LLMs as Agents
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , title =. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
GAIA: a benchmark for General AI Assistants
Mialon, Gr. arXiv preprint arXiv:2311.12983 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
arXiv preprint arXiv:2401.13178 , year =
Ma, Chang and Zhang, Junlei and Zhu, Zhihao and Yang, Cheng and Yang, Yujiu , title =. arXiv preprint arXiv:2401.13178 , year =
-
[63]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , title =. arXiv preprint arXiv:2307.13854 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , title =
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , title =. The Twelfth International Conference on Learning Representations , year =
-
[65]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Qin, Yujia and Liang, Sheng and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , title =. arXiv preprint arXiv:2307.16789 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
Li, Guohao and Hammoud, Hasan Abed Al Kader and Itani, Hani and Khizbullin, Dmitrii and Ghanem, Bernard , title =. arXiv preprint arXiv:2303.17760 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Du, Yilun and Li, Shuang and Torralba, Antonio and Tenenbaum, Joshua B. and Mordatch, Igor , title =. arXiv preprint arXiv:2305.14325 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Chan, Chi-Min and Chen, Weize and Su, Yusheng and Yu, Jianxuan and Xue, Wei and Zhang, Shanghang and Fu, Jie and Liu, Zhiyuan , title =. arXiv preprint arXiv:2308.07201 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Liu, Sicong and Awadallah, Ahmed Hassan and White, Ryen W. and Burger, Doug and Wang, Chi , title =. arXiv preprint arXiv:2308.08155 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Hong, Sirui and Zhuge, Mingchen and Chen, Jonathan and Zheng, Xiawu and Cheng, Yuheng and Wang, Jinlin and Zhang, Ceyao and Wang, Zili and Yau, Steven Ka Shing and Lin, Zijuan and Zhou, Liyang and Ran, Chenyu and Xiao, Lingfeng and Wu, Chenglin and Schmidhuber, J. arXiv preprint arXiv:2308.00352 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
Chen, Weize and Su, Yusheng and Zuo, Jingwei and Yang, Cheng and Yuan, Chenfei and Qian, Chen and Chan, Chi-Min and Qin, Yujia and Lu, Yaxi and Xie, Ruobing and Liu, Zhiyuan and Sun, Maosong and Zhou, Jie , title =. arXiv preprint arXiv:2308.10848 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
arXiv preprint arXiv:2406.14228 , year=
Yuan, Siyu and Chen, Kaitao and Ye, Jiangjie and Qin, Chengwei and Zhang, Deqing and Bi, Wei and Wang, Xiang and He, Xinran , title =. arXiv preprint arXiv:2406.14228 , year =
-
[73]
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Fourney, Adam and Bansal, Gagan and Mozannar, Hussein and Tan, Chenglei and Salinas, Eduardo and Niedtner, Fabian and Proebsting, Geoff and Bass, Dina and Gerrits, Jack and Alber, Jacob and Zhang, Peter and Zhu, Qingyu and Zhang, Chi and Shah, Shital and Zhu, Ran and Al-Hossami, Erfan and Yang, Huan and Ashktorab, Zahra and Matsakis, Nicholas and Awadalla...
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Automated Design of Agentic Systems
Hu, Shengran and Lu, Cong and Clune, Jeff , title =. arXiv preprint arXiv:2408.08435 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
AFlow: Automating Agentic Workflow Generation
Zhang, Jiayi and Lan, Zhaoheng and Hu, Mingkai and Wang, Yuan and Liu, Zhiwei and Zhou, Fei and Yan, Jie and Xu, Jiajun and Qiao, Yu and Li, Pengfei , title =. arXiv preprint arXiv:2410.10762 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
, title =
Wilson, Edwin B. , title =. Journal of the American Statistical Association , volume =. 1927 , publisher =
1927
-
[77]
Pan and Shuyi Yang and Lakshya A
Mert Cemri and Melissa Z. Pan and Shuyi Yang and Lakshya A. Agrawal and Bhavya Chopra and Rishabh Tiwari and Kurt Keutzer and Aditya Parameswaran and Dan Klein and Kannan Ramchandran and Matei Zaharia and Joseph E. Gonzalez and Ion Stoica , title =. 2025 , eprint =
2025
-
[78]
Yubin Kim and Ken Gu and Chanwoo Park and Chunjong Park and Samuel Schmidgall and A. Ali Heydari and Yao Yan and Zhihan Zhang and Yuchen Zhuang and Yun Liu and Mark Malhotra and Paul Pu Liang and Hae Won Park and Yuzhe Yang and Xuhai Xu and Yilun Du and Shwetak Patel and Tim Althoff and Daniel McDuff and Xin Liu , title =. 2025 , eprint =
2025
-
[79]
The Fourteenth International Conference on Learning Representations , year =
Jiawei Xu and Arief Koesdwiady and Sisong Bei and Yan Han and Baixiang Huang and Dakuo Wang and Yutong Chen and Zheshen Wang and Peihao Wang and Pan Li and Ying Ding , title =. The Fourteenth International Conference on Learning Representations , year =. 2601.12307 , archivePrefix =
-
[80]
2026 , eprint =
Yuzhe Zhang and Feiran Liu and Yi Shan and Xinyi Huang and Xin Yang and Yueqi Zhu and Xuxin Cheng and Cao Liu and Ke Zeng and Terry Jingchen Zhang and Wenyuan Jiang , title =. 2026 , eprint =
2026
-
[81]
Forty-Second International Conference on Machine Learning , year =
Guibin Zhang and Luyang Niu and Junfeng Fang and Kun Wang and Lei Bai and Xiang Wang , title =. Forty-Second International Conference on Machine Learning , year =
-
[82]
MASPO: Joint Prompt Optimization for LLM-based Multi-Agent Systems
Zhexuan Wang and Xuebo Liu and Li Wang and Zifei Shan and Yutong Wang and Zhenxi Song and Min Zhang , title =. Forty-Third International Conference on Machine Learning , year =. 2605.06623 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.