Recognition: unknown
MASPO: Joint Prompt Optimization for LLM-based Multi-Agent Systems
Pith reviewed 2026-05-08 09:37 UTC · model grok-4.3
The pith
MASPO jointly optimizes prompts across LLM agents by scoring each one on how much it helps later agents succeed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MASPO is a framework that automatically and iteratively refines prompts across an entire multi-agent system. Its central mechanism evaluates each prompt not by isolated correctness but by the downstream success it produces for successor agents. This joint evaluation connects local prompt quality to global task outcomes without requiring ground-truth labels. The framework further employs data-driven evolutionary beam search to explore the high-dimensional prompt space efficiently.
What carries the argument
Joint evaluation mechanism that measures a prompt's value by the improvement it creates in the success rate of agents that receive its output.
If this is right
- MASPO delivers an average accuracy improvement of 2.9 points over prior prompt optimization methods across six diverse tasks.
- Optimization requires no ground-truth labels for the final task outcome.
- Data-driven evolutionary beam search allows practical search through the large space of possible prompts.
- The method applies to any multi-agent workflow where agents pass information sequentially.
Where Pith is reading between the lines
- The same downstream-success scoring could be applied to longer agent chains where misalignment grows more severe.
- It opens the possibility of treating prompt design as an automated system-level search problem rather than expert manual work.
- The approach may transfer to non-LLM multi-agent planners if a comparable downstream success signal can be defined.
Load-bearing premise
Scoring prompts only by their effect on later agents' success accurately reflects the quality of the whole system rather than creating new biases.
What would settle it
Run the same tasks with an added direct end-to-end accuracy metric and show that prompts chosen for high downstream scores produce lower final accuracy than prompts chosen by conventional local evaluation.
Figures

read the original abstract
Large language model (LLM)-based Multi-agent systems (MAS) have shown promise in tackling complex collaborative tasks, where agents are typically orchestrated via role-specific prompts. While the quality of these prompts is pivotal, jointly optimizing them across interacting agents remains a non-trivial challenge, primarily due to the misalignment between local agent objectives and holistic system goals. To address this, we introduce MASPO, a novel framework designed to automatically and iteratively refine prompts across the entire system. A core innovation of MASPO is its joint evaluation mechanism, which assesses prompts not merely by their local validity, but by their capacity to facilitate downstream success for successor agents. This effectively bridges the gap between local interactions and global outcomes without relying on ground-truth labels. Furthermore, MASPO employs a data-driven evolutionary beam search to efficiently navigate the high-dimensional prompt space. Extensive empirical evaluations across 6 diverse tasks demonstrate that MASPO consistently outperforms state-of-the-art prompt optimization methods, achieving an average accuracy improvement of 2.9. We release our code at https://github.com/wangzx1219/MASPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MASPO, a framework for joint prompt optimization in LLM-based multi-agent systems. It features a joint evaluation mechanism that scores prompts by their ability to enable downstream success for successor agents (without ground-truth labels) and uses data-driven evolutionary beam search to navigate the prompt space. The central claim is that MASPO consistently outperforms state-of-the-art prompt optimization methods, delivering an average accuracy improvement of 2.9% across 6 diverse tasks.
Significance. If the results hold under rigorous validation, the work could meaningfully advance prompt engineering for collaborative LLM agents by addressing local-global objective misalignment. The public code release is a clear strength that aids reproducibility.
major comments (3)
- [Abstract] Abstract: The claim of a 2.9% 'accuracy improvement' is presented together with the assertion that the method operates 'without relying on ground-truth labels.' Standard accuracy requires ground-truth; the manuscript must explicitly define and justify how accuracy is computed in this label-free regime, as this directly underpins the performance claim.
- [Abstract] Abstract / Experimental Evaluation: The abstract asserts consistent outperformance and a 2.9% gain but supplies no information on baselines, the concrete mechanism for quantifying 'successful' downstream outputs (LLM-as-judge prompt, heuristic, etc.), ablation studies, statistical tests, or variance across runs. These details are load-bearing for attributing gains to MASPO rather than evaluation artifacts.
- [Method (presumed §3)] Method (presumed §3): The joint evaluation scores prompts solely by successor-agent success without ground-truth. Without a precise description of the success metric and evidence that it correlates with true task correctness (rather than optimizing for metric-specific biases), the reported improvements cannot be confidently linked to better prompts.
minor comments (1)
- [Abstract] Abstract: The phrase 'extensive empirical evaluations across 6 diverse tasks' would benefit from naming the task domains or providing one-sentence characterizations to give readers immediate context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on MASPO. We address each major comment below with clarifications and commitments to revisions that strengthen the presentation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of a 2.9% 'accuracy improvement' is presented together with the assertion that the method operates 'without relying on ground-truth labels.' Standard accuracy requires ground-truth; the manuscript must explicitly define and justify how accuracy is computed in this label-free regime, as this directly underpins the performance claim.
Authors: We agree the distinction requires explicit wording. The reported accuracy is the standard downstream task accuracy computed on held-out test sets that contain ground-truth labels; this is used exclusively for final benchmarking. The phrase 'without relying on ground-truth labels' applies only to the joint evaluation mechanism inside the optimization loop, which scores prompts by successor-agent success rather than direct label comparison. We will revise the abstract to state this separation clearly and briefly justify why the label-free joint metric is still a valid proxy for prompt quality. revision: yes
-
Referee: [Abstract] Abstract / Experimental Evaluation: The abstract asserts consistent outperformance and a 2.9% gain but supplies no information on baselines, the concrete mechanism for quantifying 'successful' downstream outputs (LLM-as-judge prompt, heuristic, etc.), ablation studies, statistical tests, or variance across runs. These details are load-bearing for attributing gains to MASPO rather than evaluation artifacts.
Authors: The abstract is space-constrained and therefore summarizes the headline result. All requested information appears in the body: baselines are enumerated in Section 4.1, the LLM-as-judge success metric (including the exact judge prompt) is defined in Section 3.2 and Appendix B, ablations occupy Section 4.3, statistical significance via paired t-tests is reported alongside the tables, and variance is shown as mean ± standard deviation over five independent runs. To address the referee's concern directly, we will insert one additional sentence in the abstract that names the primary baselines and notes that full experimental protocols, ablations, and statistical details are provided in the paper. revision: partial
-
Referee: [Method (presumed §3)] Method (presumed §3): The joint evaluation scores prompts solely by successor-agent success without ground-truth. Without a precise description of the success metric and evidence that it correlates with true task correctness (rather than optimizing for metric-specific biases), the reported improvements cannot be confidently linked to better prompts.
Authors: Section 3.2 already supplies the precise definition of the success metric: a composite of format compliance and semantic consistency judged by an LLM without access to ground-truth labels. We acknowledge that an explicit correlation study would further strengthen the claim. We will therefore add a short validation subsection (or appendix entry) that reports the Pearson correlation between the joint success scores and ground-truth task accuracy on a held-out validation split, demonstrating that the metric is a reliable proxy and not merely optimizing for judge-specific artifacts. revision: yes
Circularity Check
No circularity: purely empirical claims without derivations or self-referential reductions
full rationale
The paper presents MASPO as an empirical framework using joint evaluation and evolutionary beam search, with all central claims (e.g., 2.9 average accuracy improvement) resting on experimental comparisons across 6 tasks rather than any derivation chain. No equations, first-principles results, fitted parameters renamed as predictions, or self-citations invoked as uniqueness theorems appear in the provided text. The joint evaluation is described procedurally as a methodological innovation to link local prompts to downstream success without ground-truth labels, but this choice does not reduce to its own inputs by construction or smuggle in an ansatz. The work is self-contained against external benchmarks via direct comparisons, consistent with the default expectation of no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
URL https://aclanthology.org/2024. findings-emnlp.623/. Chen, W., You, Z., Li, R., Guan, Y ., Qian, C., Zhao, C., Yang, C., Xie, R., Liu, Z., and Sun, M. Internet of agents: Weaving a web of heterogeneous agents for collabora- tive intelligence. InThe Thirteenth International Confer- ence on Learning Representations, ICLR 2025, Singapore, April 24-28, 202...
-
[3]
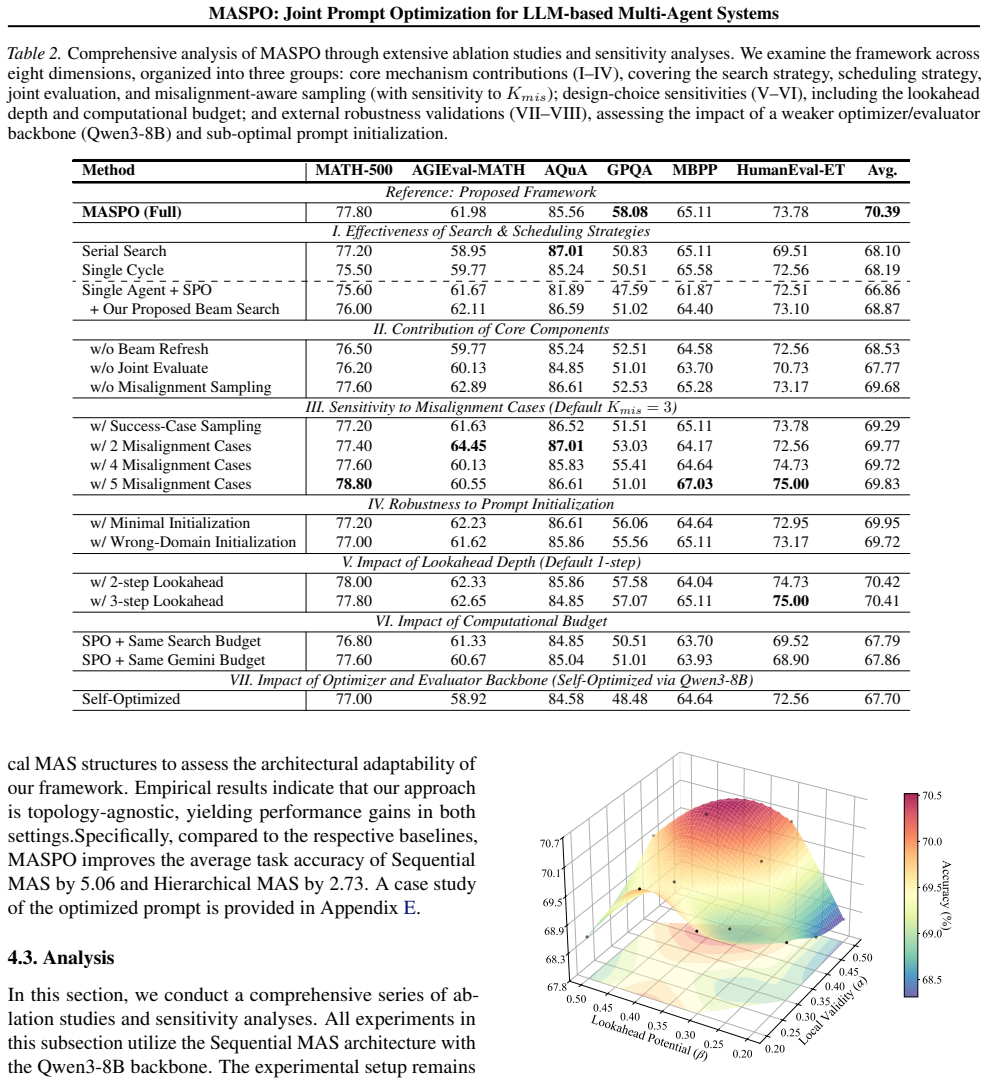
URL https://aclanthology.org/2024. emnlp-main.226/. Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.ArXiv preprint, abs/2507.06261, 2025. URL...
work page internal anchor Pith review arXiv 2024
-
[4]
Codescore: Evaluating code generation by learning code execution,
ISSN 1049-331X. doi: 10.1145/3695991. URL https://doi.org/10.1145/3695991. Du, Y ., Li, S., Torralba, A., Tenenbaum, J. B., and Mor- datch, I. Improving factuality and reasoning in lan- guage models through multiagent debate. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net,
-
[5]
23 COUNCILMODE: A HETEROGENEOUSMULTI-AGENTCONSENSUSFRAMEWORKTECHNICALREPORT Thomas G Dietterich
URL https://openreview.net/forum? id=zj7YuTE4t8. Fernando, C., Banarse, D., Michalewski, H., Osindero, S., and Rockt ¨aschel, T. Promptbreeder: Self-referential self-improvement via prompt evolution. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024a. URL https://openreview.net/f...
-
[6]
URL https://aclanthology.org/2024. findings-emnlp.427/. Li, Z., Ji, Q., Ling, X., and Liu, Q. A comprehensive review of multi-agent reinforcement learning in video games. IEEE Transactions on Games, 2025. URL https:// arxiv.org/abs/2509.03682. Liang, T., He, Z., Jiao, W., Wang, X., Wang, Y ., Wang, R., Yang, Y ., Shi, S., and Tu, Z. Encouraging divergent ...
-
[7]
URL https://aclanthology.org/2024. emnlp-main.992/. Lin, X., Dai, Z., Verma, A., Ng, S.-K., Jaillet, P., and Low, B. K. H. Prompt optimization with human feedback. ArXiv preprint, abs/2405.17346, 2024. URL https: //arxiv.org/abs/2405.17346. Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 te...
-
[10]
Ju, C., Shi, W., Liu, C., Ji, J., Zhang, J., Zhang, R., Xu, J., Yang, Y ., Han, S., and Guo, Y
URL https://aclanthology.org/2025. findings-emnlp.636/. Wang, J., Wang, J., Athiwaratkun, B., Zhang, C., and Zou, J. Mixture-of-agents enhances large language model ca- pabilities. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025a. URL https: //openreview.net/forum?id=h0Zf...
-
[11]
URL https://openreview.net/forum? id=1PL1NIMMrw. Wang, X., Li, C., Wang, Z., Bai, F., Luo, H., Zhang, J., Jojic, N., Xing, E. P., and Hu, Z. Promptagent: Strategic plan- ning with language models enables expert-level prompt optimization. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenRev...
-
[12]
URL https://openreview.net/forum? id=BAakY1hNKS. Xiang, J., Zhang, J., Yu, Z., Liang, X., Teng, F., Tu, J., Ren, F., Tang, X., Hong, S., Wu, C., and Luo, Y . Self- supervised prompt optimization. In Christodoulopou- los, C., Chakraborty, T., Rose, C., and Peng, V . (eds.), Findings of the Association for Computational Linguis- tics: EMNLP 2025, pp. 9017–9...
-
[13]
arXiv preprint arXiv:2502.14321 , year =
URL https://aclanthology.org/2025. findings-emnlp.479/. Yan, B., Zhou, Z., Zhang, L., Zhang, L., Zhou, Z., Miao, D., Li, Z., Li, C., and Zhang, X. Beyond self-talk: A communication-centric survey of llm-based multi-agent systems.ArXiv preprint, abs/2502.14321, 2025. URL https://arxiv.org/abs/2502.14321. Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zhen...
-
[14]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
URL https://openreview.net/forum? id=WE_vluYUL-X. Ye, H., Gao, Z., Ma, M., Wang, Q., Fu, Y ., Chung, M.-Y ., Lin, Y ., Liu, Z., Zhang, J., Zhuo, D., et al. Kvcomm: Online cross-context kv-cache communication for ef- ficient llm-based multi-agent systems.ArXiv preprint, abs/2510.12872, 2025. URL https://arxiv.org/ abs/2510.12872. 13 MASPO: Joint Prompt Opt...
-
[15]
arXiv preprint arXiv:2502.02533 , year=
URL https://aclanthology.org/2024. findings-naacl.149/. Zhou, H., Wan, X., Sun, R., Palangi, H., Iqbal, S., Vuli ´c, I., Korhonen, A., and Arık, S. ¨O. Multi-agent design: Optimizing agents with better prompts and topologies. ArXiv preprint, abs/2502.02533, 2025. URL https: //arxiv.org/abs/2502.02533. Zhou, Y ., Muresanu, A. I., Han, Z., Paster, K., Pitis...
-
[16]
arXiv preprint arXiv:2511.20639 , year =
URL https://openreview.net/forum? id=92gvk82DE-. Zhuge, M., Wang, W., Kirsch, L., Faccio, F., Khizbullin, D., and Schmidhuber, J. Gptswarm: Language agents as optimizable graphs. InForty-first International Confer- ence on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https: //openreview.net/forum?id=uTC9AFXIhg....
-
[17]
Agent Output
Analyze the "Agent Output" in the samples above
-
[18]
Identify specific **coding errors ** (e.g., off-by-one errors, wrong library usage, syntax errors) or **format violations **
-
[19]
Determine if the current prompt is too vague, causing these errors
-
[20]
A" or "B
Propose a new prompt that explicitly instructs the agent to avoid these specific pitfalls. Format your response exactly as follows: <analyse>Detailed analysis of the bugs found...</analyse> <modification>One sentence summary...</modification> <prompt>The complete, optimized prompt (keep it under 300 words). Ensure it retains the core task description.</pr...
-
[21]
**Correctness**: If one output appears to be functionally correct python code while the other has logic errors, choose the correct one
-
[22]
**Adherence to Requirements **: The code must NOT contain exception handling
-
[23]
**Format**: The code must be easily extractable
-
[24]
A" or "B
**Logic Clarity **: If both have bugs, choose the one with the clearer algorithmic logic that is easier to debug. Problem:{question} Output A:{output a} Output B:{output b} Which output is better? Respond ONLY with "A" or "B". 18 MASPO: Joint Prompt Optimization for LLM-based Multi-Agent Systems Global Evaluation Prompt (Code) You are comparing two FINAL ...
-
[25]
Mentally trace both codes with edge case inputs
-
[26]
If Answer A is correct and Answer B is buggy (infinite loop, wrong logic, syntax error), choose A
-
[27]
If Answer B is correct and Answer A is buggy, choose B
-
[28]
If both are correct, choose the one that is **more concise ** and follows standard Pythonic practices
-
[29]
less broken
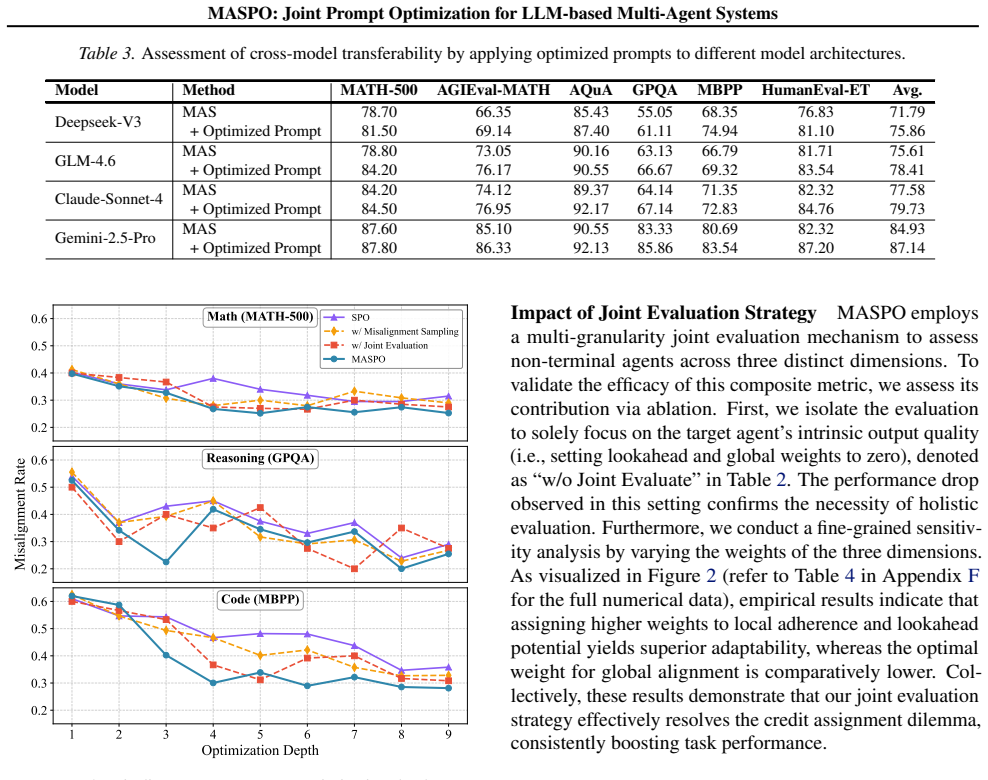
If both are buggy, choose the one that is "less broken" (closer to the solution). Respond with only "A" or "B". C. Optimization Algorithm of MASPO The overall optimization procedure of MASPO is summarized in Algorithm 1. Our framework adopts a topological coordinate ascent strategy to iteratively refine the prompts of agents in the graph G. The process is...
2025
-
[30]
* Outline your solution strategy
**Deconstruction & Planning: ** * Deconstruct the problem into its essential components and identify the key mathematical concepts involved. * Outline your solution strategy. Consider alternative approaches (e.g., algebraic, geometric, trigonometric) and state your chosen path
-
[31]
Prioritize analytical and symbolic solutions over numerical approximations
**Step-by-Step Execution: ** * Execute your plan with precision. Prioritize analytical and symbolic solutions over numerical approximations. * If you test specific values, use them only to form a hypothesis, which you must then prove generally. * Present each step clearly, showing all necessary calculations and explaining the reasoning behind them
-
[32]
Ensure the result fully addresses the original question
**Final Verification: ** * Briefly review your work to confirm the logic, accuracy, and completeness of your solution. Ensure the result fully addresses the original question. **CRITICAL: Final Answer Format ** The final answer must be presented ONLY ONCE at the very end of your response. It must be enclosed in <answer> tags. The content inside the tags m...
-
[33]
**Do not pass judgment on its correctness in this section
**Analysis of Proposed Method: ** Neutrally summarize the approach and key steps taken in the provided solution. **Do not pass judgment on its correctness in this section. **
-
[34]
As you detail your step-by-step reasoning, critically compare it to the original solution’s method
**Independent Verification and Critique: ** Begin by solving the problem from first principles to establish a gold-standard solution. As you detail your step-by-step reasoning, critically compare it to the original solution’s method. Pinpoint the exact location and nature of any errors (e.g., calculation mistake, logical fallacy, misinterpretation of the ...
-
[35]
Your justification must align strictly with these definitions
**Final Verdict: ** Conclusively classify the original solution using **one** of the following verdicts. Your justification must align strictly with these definitions. * ** Correct:** The original solution’s method, reasoning, and answer are all sound and well-justified. * ** Partially Correct / Incomplete: ** The original solution has a valid approach bu...
-
[36]
**CRITICAL Formatting Requirements: ** - Your reasoning must be clear, structured, and easy to follow
**Final Answer: ** Provide the definitive correct answer derived from your independent verification. **CRITICAL Formatting Requirements: ** - Your reasoning must be clear, structured, and easy to follow. - The final answer MUST be enclosed in <answer> and </answer> tags. - The content inside the <answer> tags must be the minimal, canonical mathematical an...
-
[37]
**Problem Analysis: ** Begin by briefly restating the problem’s objective and key information
-
[38]
* Use markdown headers for each step in the format: ‘### Step X: [Descriptive Title]‘
**Step-by-Step Derivation: ** Present your solution as a series of numbered steps. * Use markdown headers for each step in the format: ‘### Step X: [Descriptive Title]‘. * For example: ‘### Step 1: Define the variables‘. * Each step must clearly explain the mathematical principles, formulas, and calculations used
-
[39]
**CRITICAL FORMATTING RULES: ** * ** Final Answer: ** The final, simplified mathematical answer must appear **ONLY ONCE**, at the very end of your response
**Verification:** If applicable, add a final step to check if your answer is correct and satisfies the problem’s conditions. **CRITICAL FORMATTING RULES: ** * ** Final Answer: ** The final, simplified mathematical answer must appear **ONLY ONCE**, at the very end of your response. It must be enclosed in <answer> and </answer> tags. * ** Correct:** <answer...
-
[40]
**Deconstruct the Problem: ** Briefly restate the problem’s core objective to confirm your understanding of the goal
-
[41]
Do not judge correctness yet
**Create Verification Checklist: ** Distill the ‘Context‘ into a numbered list of the specific, testable claims that form the core of the proposed solution’s argument. Do not judge correctness yet. This checklist will be your guide for the audit. Example: "The solution’s logic relies on these claims: 1. The sum of three consecutive integers can be written...
-
[42]
27 can be formed by 8+9+10."
-
[43]
Show your work clearly for each point, providing the necessary calculations or logical steps
**Execute Verification: ** Rigorously and independently verify each claim from your Step 2 checklist. Show your work clearly for each point, providing the necessary calculations or logical steps. This is your audit trail. If the proposed logic is flawed, continue your derivation to find the correct solution
-
[44]
The method was efficient and direct
**Deliver Verdict and Justification: ** Compare the proposed logic against your audit trail from Step 3 and issue a final verdict. Justify your decision by referencing the specific claims from your checklist. * ** Verdict: Correct. ** The proposed solution is mathematically sound and logically complete. All claims on the checklist were verified. Briefly c...
-
[45]
CRITICAL FORMATTING INSTRUCTIONS: - The final answer MUST appear ONLY ONCE at the very end of your response
**Final Answer: ** Conclude with the definitive correct answer from your independent derivation. CRITICAL FORMATTING INSTRUCTIONS: - The final answer MUST appear ONLY ONCE at the very end of your response. - The final answer MUST be enclosed in <answer> and </answer> tags. - The tags MUST contain ONLY the canonical mathematical answer (e.g., a number, a s...
-
[46]
* ** Identify All Constraints & Definitions: ** List every rule and definition
**Analyze and Plan: ** * ** Deconstruct the Goal: ** Briefly state the primary objective. * ** Identify All Constraints & Definitions: ** List every rule and definition. Pay close attention to how examples clarify terms (e.g., handling of spaces, what constitutes a "word"). * ** Propose an Algorithm: ** Outline the step-by-step logic. Consider potential p...
-
[47]
Show the state of key variables at each step to prove your logic is sound
**Verify Logic Against Examples: ** * For *each* provided example, meticulously trace your proposed algorithm. Show the state of key variables at each step to prove your logic is sound. * At the end of each trace, **explicitly compare your result with the example’s expected output. ** * If a mismatch occurs, **you MUST revise your algorithm and re-verify ...
-
[48]
**This code must be a direct and faithful implementation of your verified algorithm
**Provide Final Code: ** * Write the final Python function. **This code must be a direct and faithful implementation of your verified algorithm. ** Do not add or change logic at this stage. **CRITICAL CODING RULES: ** * The function must implement only the pure algorithm. **STRICTLY FORBIDDEN IN FINAL CODE: ** * Type hints (e.g., ‘def func(arg: str):‘) * ...
-
[49]
**Analyze Goal: ** State the function’s main objective
-
[50]
If an example contradicts the problem description, state the contradiction and confirm your implementation will follow the example’s logic
**Analyze Examples: ** Critically examine the provided examples. If an example contradicts the problem description, state the contradiction and confirm your implementation will follow the example’s logic
-
[51]
Mention iteration direction (e.g., forward, reverse) if applicable
**Algorithm:** Outline the most concise and efficient step-by-step algorithm to solve the problem. Mention iteration direction (e.g., forward, reverse) if applicable
-
[52]
**Part 2: Python Code ** Provide the final, complete Python function inside a single code block
**Edge Cases: ** Briefly describe how the algorithm handles key boundary conditions (e.g., n=1, empty inputs). **Part 2: Python Code ** Provide the final, complete Python function inside a single code block. **CODE BLOCK RULES (MANDATORY): **
-
[53]
You MUST remove any type hints (e.g., ‘arg1: str‘) found in the problem description
**NO TYPE HINTS: ** The function signature must be ‘def function name(arg1, arg2):‘. You MUST remove any type hints (e.g., ‘arg1: str‘) found in the problem description
-
[54]
**NO COMMENTS OR DOCSTRINGS. **
-
[55]
**NO ‘try-except‘ BLOCKS. **
-
[56]
Do not add input validation (e.g., type checking) or handle cases not explicitly covered by the problem
**CORE LOGIC ONLY: ** Implement only the essential logic. Do not add input validation (e.g., type checking) or handle cases not explicitly covered by the problem. Problem:{question} {context} 29 MASPO: Joint Prompt Optimization for LLM-based Multi-Agent Systems Agent 4: Reflector 2 (HumanEval-ET) You are a meticulous code reviewer. Your purpose is to anal...
-
[57]
Provide **only** the function definition, starting with ‘def‘
-
[58]
The function signature **MUST NOT ** contain any type hints, docstrings, or comments
-
[59]
**DO NOT ** define helper functions
The function must be self-contained. **DO NOT ** define helper functions
-
[60]
**DO NOT ** include ‘import‘ statements, test cases, or ‘print‘ statements
-
[61]
Do not add input validation or exception handling
Implement only the core algorithm. Do not add input validation or exception handling. **Analysis of Errors: ** <Your step-by-step reasoning based on the Context here> **Corrected Code: ** ‘‘‘python # Your self-contained, verified Python code here ‘‘‘ F. Detailed Sensitivity Analysis of Joint Evaluation Weights In this section, we provide the detailed nume...
-
[62]
This validates our hypothesis that in multi-step reasoning chains, the final outcome provides a supervision signal that is too sparse and noisy for intermediate agents
Dominance of Intermediate Signals:The balanced heavy weighting on Local Validity ( α) and Lookahead Potential (β) outperforms configurations skewed towards Global Alignment (θ). This validates our hypothesis that in multi-step reasoning chains, the final outcome provides a supervision signal that is too sparse and noisy for intermediate agents. In contras...
-
[63]
The lower weight on θ= 2 serves as a necessary but auxiliary weak constraint to ensure the overall trajectory does not drift from the final goal
Synergy of Correctness and Utility:The equal importance of α= 4 and β= 4 suggests that for an agent to be effective, it is not enough to merely be ”locally correct” (satisfying self-consistency); it must also be ”topologically useful” (facilitating the success of its successor). The lower weight on θ= 2 serves as a necessary but auxiliary weak constraint ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.