Seeing Time: Benchmarking Chronological Reasoning and Shortcut Biases in Vision-Language Models
Pith reviewed 2026-06-28 01:28 UTC · model grok-4.3
The pith
Vision-language models often detect color filters instead of reasoning about time across images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VLMs show promise on chronological tasks yet frequently exploit superficial cues like grayscale versus color filters to bypass authentic chronological reasoning, as shown by performance differences across the three datasets that isolate temporal features from other visual and textual signals.
What carries the argument
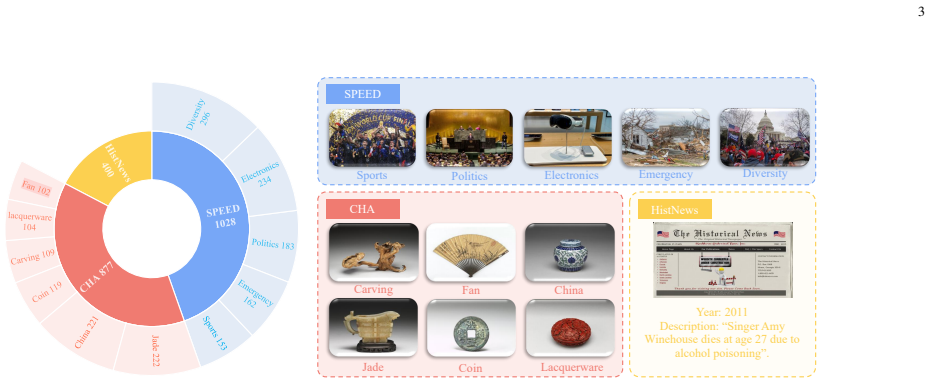
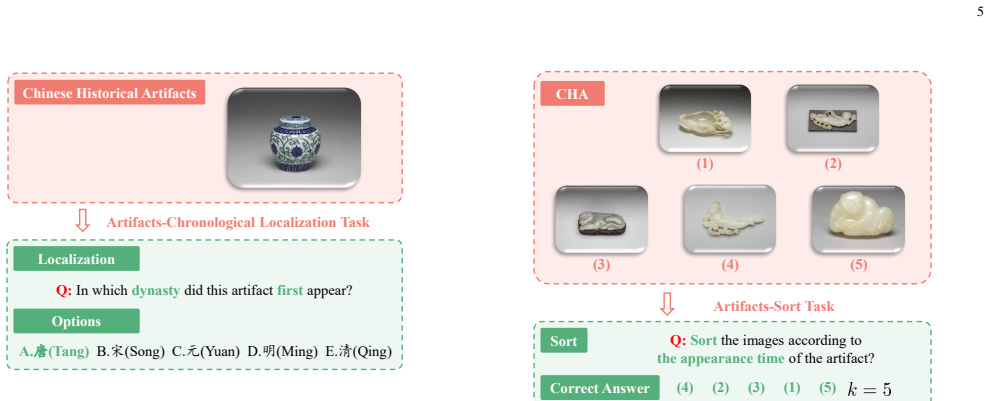
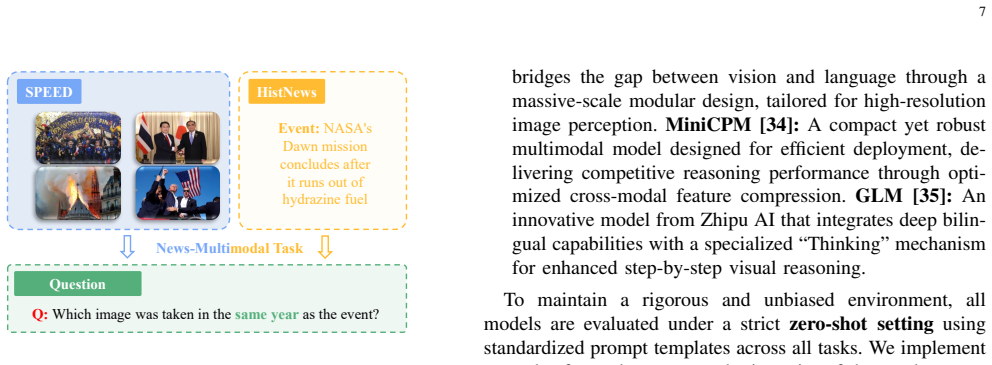
Three specialized datasets: one with visually similar objects across long historical spans, one organized by diverse event and object categories, and one pairing images with time-sensitive news text for cross-modal checks; these datasets expose whether models use incorrect shortcuts rather than chronological logic.
If this is right
- Models that succeed on all three datasets must demonstrate temporal order independent of image filters or caption style.
- The datasets supply a diagnostic tool for measuring genuine multimodal temporal integration.
- Performance gaps across categories point to specific weaknesses in how current models combine visual and textual time signals.
- Future training can target removal of reliance on low-level cues such as color to improve chronological judgment.
Where Pith is reading between the lines
- Training data may need explicit supervision on temporal order beyond visual correlations to reduce shortcut use.
- The benchmark could be adapted to test chronological reasoning in video sequences or multi-image stories.
- If shortcut reliance proves widespread, evaluation protocols for other reasoning tasks may also need controls for superficial cues.
Load-bearing premise
The three datasets isolate chronological reasoning without introducing other visual or textual patterns that models could use in place of time logic.
What would settle it
If models achieve equal accuracy on color and grayscale versions of the same historical-object images, the claim that they rely on color shortcuts would be falsified.
Figures








read the original abstract
Recent advancements in Vision-Language Models (VLMs) have significantly enhanced their ability to interpret complex visual semantics, yet their capacity for chronological reasoning remains under-explored. In this paper, we introduce a novel benchmark specifically designed to evaluate how VLMs perceive and reason about chronological information within and across images. Unlike existing video-based benchmarks that focus on frame sequencing, our work delves into the underlying logic of chronological judgment and the expansion toward multimodal integration. To facilitate this, we construct three specialized datasets: one containing visually similar objects spanning long historical durations, another categorized by diverse event and object types, and a third pairing images with time-sensitive news text for cross-modal alignment. Through extensive experiments, we analyze whether models exhibit performance disparities across categories and, crucially, explore whether they rely on ``incorrect shortcuts'', such as image color rather than genuine chronological features. Our results reveal that while VLMs show promise, they frequently exploit superficial cues like grayscale versus color filters to bypass authentic chronological reasoning. By providing these high-quality datasets and a rigorous evaluation framework, we offer a diagnostic tool to identify current limitations and guide the development of more robust, logically grounded multimodal models. The source code is shown in https://github.com/LuoRenqiang/ChronoVision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark for chronological reasoning in Vision-Language Models using three constructed datasets (visually similar objects over long durations, diverse event/object categories, and image-news text pairs) and reports that VLMs often rely on superficial cues such as grayscale versus color filters rather than authentic temporal logic.
Significance. If the datasets properly decouple color from chronological labels, the work supplies useful diagnostic datasets and an evaluation framework for identifying limitations in VLMs' multimodal temporal reasoning. The provision of source code on GitHub is a positive contribution toward reproducibility.
major comments (1)
- [Abstract] Abstract (dataset construction paragraph): The central claim that models 'frequently exploit superficial cues like grayscale versus color filters to bypass authentic chronological reasoning' requires that color is uncorrelated with ground-truth time labels. The first dataset (visually similar objects spanning long historical durations) draws from real archives where older images are disproportionately grayscale and recent ones color; without explicit balancing, counterfactual augmentation, or correlation statistics reported, color remains a statistically valid temporal signal. Performance gaps may therefore reflect genuine feature-label correlation rather than incorrect shortcut use, directly affecting the interpretation of the shortcut-bias results.
minor comments (1)
- The GitHub link is given but the manuscript should include a brief description of what the released code covers (dataset generation scripts, evaluation harness, or only model inference).
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a potential confound in the interpretation of shortcut bias on the first dataset. We address the concern directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract (dataset construction paragraph): The central claim that models 'frequently exploit superficial cues like grayscale versus color filters to bypass authentic chronological reasoning' requires that color is uncorrelated with ground-truth time labels. The first dataset (visually similar objects spanning long historical durations) draws from real archives where older images are disproportionately grayscale and recent ones color; without explicit balancing, counterfactual augmentation, or correlation statistics reported, color remains a statistically valid temporal signal. Performance gaps may therefore reflect genuine feature-label correlation rather than incorrect shortcut use, directly affecting the interpretation of the shortcut-bias results.
Authors: We agree that the current presentation does not sufficiently demonstrate that color is uncorrelated with the ground-truth chronological labels in the first dataset. Because the images are drawn from real historical archives, a natural correlation between grayscale and older timestamps is plausible and, if present, would weaken the shortcut-bias interpretation. In the revised manuscript we will (1) compute and report the Pearson correlation between the binary color/grayscale feature and the chronological label for this dataset, (2) if the correlation is non-negligible, either re-balance the dataset or introduce counterfactual color-augmented versions, and (3) update the abstract and results section to reflect the revised analysis. This change directly addresses the referee’s concern and strengthens the diagnostic value of the benchmark. revision: yes
Circularity Check
Empirical benchmark study; no derivations or predictions reduce to inputs by construction.
full rationale
The paper constructs three datasets and reports experimental performance of VLMs on chronological reasoning tasks, attributing gaps to shortcut use (e.g., color/grayscale). No equations, fitted parameters, or first-principles derivations appear; claims rest on direct empirical measurement rather than any step that reduces by definition or self-citation to the inputs. The dataset construction and shortcut interpretation are presented as observational findings, not as logical equivalences to prior fits or self-referential premises. This is a standard empirical benchmark paper whose central results are falsifiable against the released datasets and code.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large language models know what is key visual entity: An llm-assisted multimodal retrieval for vqa,
P. Jian, D. Yu, and J. Zhang, “Large language models know what is key visual entity: An llm-assisted multimodal retrieval for vqa,” inEMNLP, 2024, pp. 10 939–10 956
2024
-
[2]
Vqa: Visual question answering,
S. Antol, A. Agrawal, J. Luet al., “Vqa: Visual question answering,” inICCV, 2015, pp. 2425–2433
2015
-
[3]
Enhancing temporal un- derstanding in video-llms through stacked temporal attention in vision encoders,
A. Rasekh, E. B. Soula, O. Daliranet al., “Enhancing temporal un- derstanding in video-llms through stacked temporal attention in vision encoders,” inNeurIPS, 2025
2025
-
[4]
Language is not all you need: Aligning perception with language models,
S. Huang, L. Dong, W. Wanget al., “Language is not all you need: Aligning perception with language models,” inNeurIPS, 2023, pp. 72 096–72 109
2023
-
[5]
Bliva: A simple multimodal LLM for better handling of text-rich visual questions,
W. Hu, Y . Xu, Y . Liet al., “Bliva: A simple multimodal LLM for better handling of text-rich visual questions,” inAAAI, 2024, pp. 2256–2264
2024
-
[6]
MME-RealWorld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?
Y . Zhang, H. Zhang, H. Tianet al., “MME-RealWorld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?” inICLR, 2025
2025
-
[7]
Improving image captioning descriptiveness by ranking and LLM-based fusion,
L. Celona, S. Bianco, M. Donzellaet al., “Improving image captioning descriptiveness by ranking and LLM-based fusion,”Neural Computing and Applications, vol. 37, no. 32, pp. 27 279–27 299, 2025
2025
-
[8]
Can multimodal LLMs do visual temporal understanding and reasoning? the answer is no!
M. F. Imam, C. Lyu, and A. F. Aji, “Can multimodal LLMs do visual temporal understanding and reasoning? the answer is no!”arXiv preprint arXiv:2501.10674, 2025
-
[9]
LEGO-Puzzles: How good are MLLMs at multi-step spatial reasoning?
K. Tang, J. Gao, Y . Zenget al., “LEGO-Puzzles: How good are MLLMs at multi-step spatial reasoning?”arXiv preprint arXiv:2503.19990, 2025
-
[10]
Bridging semantic understanding and popularity bias with llms,
R. Luo, D. Zhang, Y . Gaoet al., “Bridging semantic understanding and popularity bias with llms,” inThe ACM Web Conference, 2026
2026
-
[11]
CompareBench: A benchmark for visual comparison reasoning in vision-language models,
J. Cai, K. Yang, L. Fuet al., “CompareBench: A benchmark for visual comparison reasoning in vision-language models,”arXiv preprint arXiv:2509.22737, 2025
-
[12]
Timebench: A comprehensive evalua- tion of temporal reasoning abilities in large language models,
Z. Chu, J. Chen, Q. Chenet al., “Timebench: A comprehensive evalua- tion of temporal reasoning abilities in large language models,” inACL, 2024, pp. 1204–1228
2024
-
[13]
Set the clock: Temporal alignment of pretrained language models,
B. Zhao, Z. Brumbaugh, Y . Wanget al., “Set the clock: Temporal alignment of pretrained language models,” inACL, 2024, pp. 15 015– 15 040
2024
-
[14]
Caparena: Benchmarking and analyzing detailed image captioning in the LLM era,
K. Cheng, W. Song, J. Fanet al., “Caparena: Benchmarking and analyzing detailed image captioning in the LLM era,”arXiv preprint arXiv:2503.12329, 2025
-
[15]
Investigating reasoning in large language models with counterfactual knowledge graphs,
F. Yan, J. Yao, M. K. Chenet al., “Investigating reasoning in large language models with counterfactual knowledge graphs,” inKDD, 2026
2026
-
[16]
How far are we from AGI: Are LLMs all we need?
T. Feng, C. Jin, J. Liuet al., “How far are we from AGI: Are LLMs all we need?”TMLR, 2024
2024
-
[17]
ChroKnowledge: Unveiling chrono- logical knowledge of language models in multiple domains,
Y . Park, C. Yoon, J. Parket al., “ChroKnowledge: Unveiling chrono- logical knowledge of language models in multiple domains,” inICLR, 2025
2025
-
[18]
Facts fade fast: Evaluating memorization of outdated medical knowledge in large language models,
J. Vladika, M. Dhaini, and F. Matthes, “Facts fade fast: Evaluating memorization of outdated medical knowledge in large language models,” inEMNLP, 2025, pp. 9161–9174
2025
-
[19]
Does time have its place? temporal heads: Where language models recall time-specific information,
Y . Park, C. Yoon, J. Parket al., “Does time have its place? temporal heads: Where language models recall time-specific information,” inACL, 2025
2025
-
[20]
Visual news: Benchmark and challenges in news image captioning,
F. Liu, Y . Wang, T. Wanget al., “Visual news: Benchmark and challenges in news image captioning,” inEMNLP, 2021, pp. 6761–6771
2021
-
[21]
A matter of time: Revealing the structure of time in vision-language models,
N. Tekaya, M. Waldner, and M. Zeppelzauer, “A matter of time: Revealing the structure of time in vision-language models,” inACM MM, 2025, pp. 12 371–12 380
2025
-
[22]
Ok-vqa: A visual question answering benchmark requiring external knowledge,
K. Marino, M. Rastegari, A. Farhadiet al., “Ok-vqa: A visual question answering benchmark requiring external knowledge,” inCVPR, 2019, pp. 3195–3204
2019
-
[23]
Mmbench: Is your multi-modal model an all-around player?
Y . Liu, H. Duan, Y . Zhanget al., “Mmbench: Is your multi-modal model an all-around player?” inECCV, 2024, pp. 216–233
2024
-
[24]
Are we on the right way for evaluating large vision-language models?
L. Chen, J. Li, X. Donget al., “Are we on the right way for evaluating large vision-language models?” 2024, pp. 27 056–27 087
2024
-
[25]
Simplevqa: Multimodal factuality evaluation for multimodal large language models,
X. Cheng, W. Zhang, S. Zhanget al., “Simplevqa: Multimodal factuality evaluation for multimodal large language models,” inICCV, 2025, pp. 4637–4646
2025
-
[26]
Benchmarking and improving detail image caption,
H. Dong, J. Li, B. Wuet al., “Benchmarking and improving detail image caption,”arXiv preprint arXiv:2405.19092, 2024
-
[27]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi,
X. Yue, Y . Ni, K. Zhanget al., “Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi,” in CVPR, 2024, pp. 9556–9567
2024
-
[28]
MuirBench: A comprehensive benchmark for robust multi-image understanding,
F. Wang, X. Fu, J. Y . Huanget al., “MuirBench: A comprehensive benchmark for robust multi-image understanding,” inICLR, 2025
2025
-
[29]
Journeydb: A benchmark for generative image understanding,
K. Sun, J. Pan, Y . Geet al., “Journeydb: A benchmark for generative image understanding,”NeurIPS, pp. 49 659–49 678, 2023
2023
-
[30]
The OpenCV library
G. Bradski, “The OpenCV library.”Dr. Dobb’s Journal: Software Tools for the Professional Programmer, vol. 25, no. 11, pp. 120–123, 2000
2000
-
[31]
G. Comanici, E. Bieber, M. Schaekermannet al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
A. Yang, A. Li, B. Yanget al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Guet al., “Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
T. Yu, Z. Wang, C. Wanget al., “Minicpm-v 4.5: Cooking effi- cient mllms via architecture, data, and training recipe,”arXiv preprint arXiv:2509.18154, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
W. Hong, W. Yu, X. Guet al., “Glm-4.1 v-thinking: Towards versa- tile multimodal reasoning with scalable reinforcement learning,”arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Estimates of the regression coefficient based on Kendall’s tau,
P. K. Sen, “Estimates of the regression coefficient based on Kendall’s tau,”Journal of the American Statistical Association, vol. 63, no. 324, pp. 1379–1389, 1968
1968
-
[37]
Advantages of the mean absolute error (mae) over the root mean square error (rmse) in assessing average model performance,
C. J. Willmott and K. Matsuura, “Advantages of the mean absolute error (mae) over the root mean square error (rmse) in assessing average model performance,”Climate research, vol. 30, no. 1, pp. 79–82, 2005
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.