DiG-Plan: Mitigating Early Commitment for Tool-Graph Planning via Diffusion Guidance
Pith reviewed 2026-06-28 01:22 UTC · model grok-4.3
The pith
DiG-Plan uses diffusion to propose diverse tool sets before autoregressive refinement, lifting solution coverage from 0.32 to 0.94 under matched compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a diffusion-based proposer can generate diverse tool sets through iterative masked denoising; an autoregressive refiner then predicts dependencies to produce executable plans, overcoming the early-commitment bias of pure autoregressive decoding and thereby increasing both the fraction of solvable instances and the quality of plans on compositional benchmarks.
What carries the argument
Diffusion-based proposer that generates diverse tool sets via iterative refinement, followed by an AR refiner for dependency prediction.
If this is right
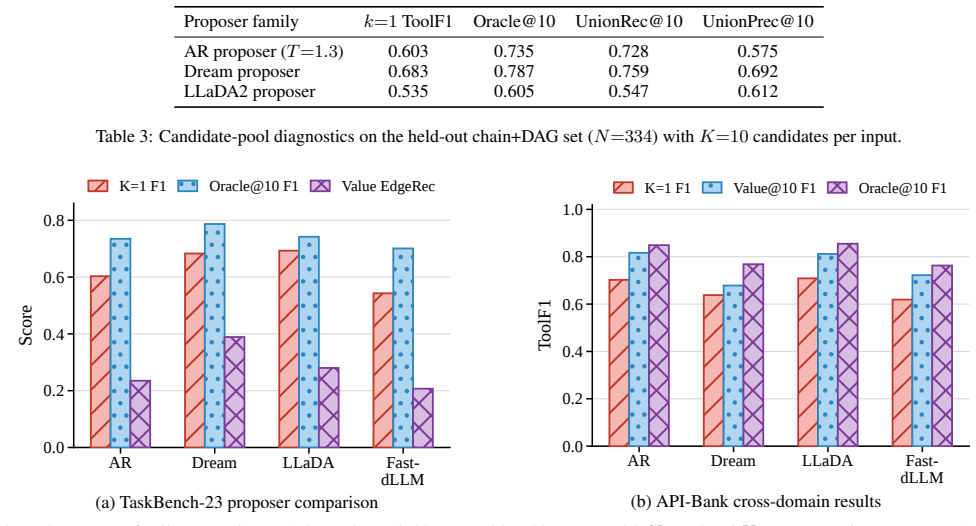
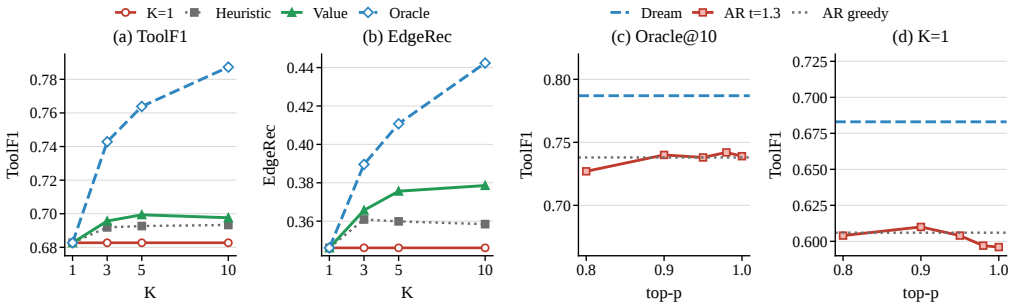
- Raises Pass@10 solution coverage from 0.320 to 0.943 over AR sampling under matched compute.
- Improves over AR baselines by a 10% relative margin on TaskBench.
- Delivers the largest gains on complex compositional tasks.
- The propose-refine-select design remains effective across domains on API-Bank.
Where Pith is reading between the lines
- The same decoupling of set exploration from sequence construction could be tested in other structured prediction settings where autoregressive models face early commitment, such as program synthesis or molecule design.
- Training the diffusion proposer and the refiner end-to-end rather than sequentially might further reduce the gap between proposed sets and executable plans.
- The observed coverage jump suggests that hybrid diffusion-plus-autoregressive pipelines merit direct comparison against pure diffusion or pure autoregressive planners on any task whose solution space is both combinatorial and ordered.
Load-bearing premise
The diffusion-based proposer generates diverse yet feasible tool sets that the subsequent AR refiner can successfully turn into executable plans without introducing new failure modes.
What would settle it
A direct head-to-head run in which the full propose-refine pipeline produces strictly fewer valid executable plans than matched autoregressive sampling on the same TaskBench or API-Bank instances would falsify the claimed benefit.
Figures

read the original abstract
Generating executable tool plans requires selecting appropriate subsets from tool libraries, a combinatorial search problem with an exponentially large solution space. However, we identify a critical misalignment in predominant approaches: standard autoregressive (AR) decoding suffers from early commitment, where initial token choices rigidly constrain the search trajectory. A controlled study shows that masked denoising raises Pass@10 solution coverage from 0.320 to 0.943 over AR sampling under matched compute. Motivated by this, we propose DiG-Plan, a framework that decouples combinatorial exploration from structural refinement. DiG-Plan employs a diffusion-based proposer to generate diverse tool sets via iterative refinement, followed by an AR refiner for dependency prediction. On TaskBench, DiG-Plan improves over AR baselines by a 10% relative margin, with the largest gains on complex compositional tasks; API-Bank results show that the propose-refine-select design remains effective across domains. Code is available at https://github.com/puddingyeah/DiG-Plan.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that autoregressive decoding in tool-graph planning suffers from early commitment and that a diffusion-based proposer using masked denoising can generate more diverse tool sets. A controlled study is reported to show Pass@10 solution coverage rising from 0.320 to 0.943 under matched compute; DiG-Plan then combines this proposer with an AR refiner for dependency prediction, yielding a 10% relative improvement over AR baselines on TaskBench (largest on complex tasks) and effective results on API-Bank. Code is released.
Significance. If the gains hold after addressing the feasibility gap, the work supplies a concrete propose-refine architecture that decouples combinatorial search from structural prediction, with open code enabling direct reproduction and extension in tool-use agent research.
major comments (2)
- [Abstract] Abstract: the central claim that the propose-refine design produces the reported TaskBench gains rests on the assumption that diffusion-generated tool sets remain feasible inputs for the AR refiner without introducing new failure modes, yet no validity, executability, or refiner-success metrics are supplied comparing diffusion proposals to AR proposals.
- [Abstract] Abstract: the controlled-study result (Pass@10 coverage 0.320 → 0.943) is presented without any description of the diffusion implementation, exact compute-matching procedure, data splits, or statistical tests, rendering it impossible to assess whether the improvement is robust or directly transferable to the full DiG-Plan pipeline.
minor comments (1)
- The GitHub link is given but the main text does not summarize repository contents (e.g., exact scripts for the controlled study or benchmark splits), which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our submission. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the propose-refine design produces the reported TaskBench gains rests on the assumption that diffusion-generated tool sets remain feasible inputs for the AR refiner without introducing new failure modes, yet no validity, executability, or refiner-success metrics are supplied comparing diffusion proposals to AR proposals.
Authors: The TaskBench and API-Bank results reported in the paper are generated using the complete DiG-Plan pipeline, in which diffusion proposals are directly input to the autoregressive refiner. The observed performance improvements demonstrate that these proposals serve as effective and feasible inputs. To make this clearer, we will revise the abstract to note that the propose-refine design was validated through end-to-end benchmark performance. revision: yes
-
Referee: [Abstract] Abstract: the controlled-study result (Pass@10 coverage 0.320 → 0.943) is presented without any description of the diffusion implementation, exact compute-matching procedure, data splits, or statistical tests, rendering it impossible to assess whether the improvement is robust or directly transferable to the full DiG-Plan pipeline.
Authors: Details of the diffusion implementation, compute-matching procedure, data splits, and evaluation are provided in the main text (Section 4) and appendix. We will update the abstract to include a reference to these sections so that the controlled study result is presented with appropriate context. revision: yes
Circularity Check
No circularity; empirical claims rest on benchmark comparisons
full rationale
The paper reports a controlled empirical study (Pass@10 coverage 0.320 to 0.943) and relative gains on TaskBench and API-Bank against AR baselines. No equations, derivations, fitted parameters, or self-citations are described that reduce any result to a quantity defined by the paper's own inputs. The propose-refine design and diffusion proposer are evaluated via external benchmarks, rendering the central claims self-contained and falsifiable outside the paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Masked denoising serves as a valid and comparable implementation of diffusion-based planning for tool selection
Reference graph
Works this paper leans on
-
[1]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
[Austinet al., 2021 ] Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state- spaces. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors,Advances in Neural Information Pro- cessing Systems 34: Annual Conferenc...
2021
-
[2]
Graph of thoughts: Solving elaborate problems with large lan- guage models
[Bestaet al., 2024 ] Maciej Besta, Nils Blach, Ales Ku- bicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large lan- guage models. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors,...
2024
-
[3]
Llada2.0: Scal- ing up diffusion language models to 100b,
[Bieet al., 2025 ] Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, Chengxi Li, Chongx- uan Li, Jianguo Li, Zehuan Li, Huabin Liu, Ling Liu, Guoshan Lu, Xiaocheng Lu, Yuxin Ma, Jianfeng Tan, Lanning Wei, Ji-Rong Wen, Yipeng Xing, Xiaolu Zhang, Junbo Zhao, Da Zheng, Jun Zhou, Junlin Z...
2025
-
[4]
Meta- tool benchmark for large language models: Deciding whether to use tools and which to use
[Huanget al., 2024 ] Yue Huang, Jiawen Shi, Yuan Li, Chen- rui Fan, Siyuan Wu, Qihui Zhang, Yixin Liu, Pan Zhou, Yao Wan, Neil Zhenqiang Gong, and Lichao Sun. Meta- tool benchmark for large language models: Deciding whether to use tools and which to use. InThe Twelfth Inter- national Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[5]
Hashimoto
[Liet al., 2022 ] Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori B. Hashimoto. Diffusion-lm improves controllable text generation. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Bel- grave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Sys...
2022
-
[6]
Api-bank: A comprehensive benchmark for tool-augmented llms
[Liet al., 2023 ] Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. Api-bank: A comprehensive benchmark for tool-augmented llms. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing, EMNLP 2023, Singapore, ...
2023
-
[7]
Agentbench: Evaluating llms as agents
[Liuet al., 2024 ] Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kai- wen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Ao- han Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yux- iao Dong, and Jie Tang. Agentbench: Evaluating llms as agents. InThe Twelfth International...
2024
-
[8]
Ad- vancing tool-augmented large language models via meta- verification and reflection learning
[Maet al., 2025 ] Zhiyuan Ma, Jiayu Liu, Xianzhen Luo, Zhenya Huang, Qingfu Zhu, and Wanxiang Che. Ad- vancing tool-augmented large language models via meta- verification and reflection learning. In Luiza Antonie, Jian Pei, Xiaohui Yu, Flavio Chierichetti, Hady W. Lauw, Yizhou Sun, and Srinivasan Parthasarathy, editors,Pro- ceedings of the 31st ACM SIGKDD...
2025
-
[9]
Large language diffusion models,
[Nieet al., 2025 ] Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. Large language diffusion models,
2025
-
[10]
[Pandeyet al., 2025 ] Tushar Pandey, Ara Ghukasyan, Ok- tay G ¨oktas, and Santosh Kumar Radha. Adaptive graph of thoughts: Test-time adaptive reasoning unifying chain, tree, and graph structures.CoRR, abs/2502.05078,
-
[11]
Scikit-learn: Machine learn- ing in python.J
[Pedregosaet al., 2011 ] Fabian Pedregosa, Ga¨el Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake VanderPlas, Alexandre Pas- sos, David Cournapeau, Matthieu Brucher, Matthieu Per- rot, and Edouard Duchesnay. Scikit-learn: Machine learn- ing in python.J. M...
2011
-
[12]
Toolink: Linking toolkit cre- ation and using through chain-of-solving on open-source model
[Qianet al., 2024 ] Cheng Qian, Chenyan Xiong, Zhenghao Liu, and Zhiyuan Liu. Toolink: Linking toolkit cre- ation and using through chain-of-solving on open-source model. In Kevin Duh, Helena G´omez-Adorno, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human...
2024
-
[13]
Toolllm: Facilitating large language models to master 16000+ real-world apis
[Qinet al., 2024 ] Yujia Qin, Shihao Liang, Yining Ye, Kun- lun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xian- gru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis. InThe Twelfth International...
2024
-
[14]
Sentence-bert: Sentence embeddings using siamese bert-networks
[Reimers and Gurevych, 2019] Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMN...
2019
-
[15]
Taskbench: Benchmark- ing large language models for task automation
[Shenet al., 2024 ] Yongliang Shen, Kaitao Song, Xu Tan, Wenqi Zhang, Kan Ren, Siyu Yuan, Weiming Lu, Dong- sheng Li, and Yueting Zhuang. Taskbench: Benchmark- ing large language models for task automation. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Informa...
2024
-
[16]
Le, Ed H
[Wanget al., 2023 ] Xuezhi Wang, Jason Wei, Dale Schuur- mans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Repre- sentations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[17]
[Weiet al., 2025 ] Xiaolong Wei, Yuehu Dong, Xingliang Wang, Xingyu Zhang, Zhejun Zhao, Dongdong Shen, Long Xia, and Dawei Yin. Beyond react: A planner- centric framework for complex tool-augmented LLM rea- soning.CoRR, abs/2511.10037,
-
[18]
[Yanget al., 2024 ] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Tree of thoughts: Deliberate problem solv- ing with large language models
[Yaoet al., 2023a ] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solv- ing with large language models. In Alice Oh, Tristan Nau- mann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual ...
2023
-
[20]
Narasimhan, and Yuan Cao
[Yaoet al., 2023b ] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language mod- els. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[21]
Dream 7B: Diffusion Large Language Models
[Yeet al., 2025 ] Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.CoRR, abs/2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.