Membrane: A Self-Evolving Contrastive Safety Memory for LLM Agent Defense
Pith reviewed 2026-06-28 00:52 UTC · model grok-4.3
The pith
A self-evolving contrastive memory enables LLM agents to block jailbreaks without over-refusing similar benign requests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
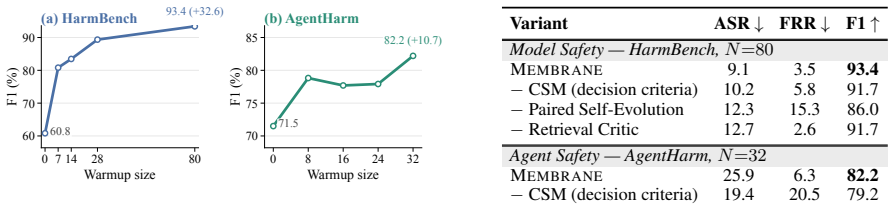
Membrane is a self-evolving guardrail built on Contrastive Safety Memory where each cell pairs the conditions for blocking a harmful query with those for permitting a superficially similar benign request. Without retraining, it evolves by distilling each harmful interaction and its benign counterpart into a cell indexed by the attack strategy. Retrieved cells then serve as grounding context for safety decisions, resulting in the highest F1 scores on all six jailbreak attacks tested.
What carries the argument
Contrastive Safety Memory (CSM) that indexes paired harmful-benign conditions by attack strategy to generalize across variants.
If this is right
- Achieves the highest F1 on all six jailbreak attacks on HarmBench and AgentHarm.
- Benign refusal on AgentHarm stays at 7-14%, below the 28-85% range of prior guards.
- Memory cells retain 87-88% F1 under cross-attack transfer.
- Performance remains stable under memory poisoning.
Where Pith is reading between the lines
- The strategy-indexed contrastive pairing could enable similar adaptive defenses in other domains like misinformation detection.
- If attack strategies prove limited in number, this might lead to a compact, long-term memory for safety that rarely needs expansion.
- Testing on additional agent benchmarks could reveal whether the low over-refusal holds for more complex multi-turn interactions.
Load-bearing premise
That indexing by attack strategy lets one cell generalize across topical variants of the same mechanism without retraining.
What would settle it
A benchmark result showing that after adding cells for several attacks, a new variant of one attack strategy is not blocked or causes refusal rates above 20% on benign queries.
Figures











read the original abstract
Despite advances in safety alignment, large language models remain vulnerable to continuously evolving jailbreaks. Existing fine-tuned safety classifiers cannot adapt to these evolving attacks, while adaptive memory-based guardrails tend to over-refuse benign queries that resemble stored attacks. We propose Membrane, a self-evolving guardrail built on Contrastive Safety Memory (CSM): each cell pairs the conditions for blocking a harmful query with those for permitting a superficially similar benign request. Without retraining, Membrane evolves CSM by distilling each harmful interaction and its benign counterpart into a contrastive cell indexed by the underlying attack strategy, so that one cell generalizes across topical variants of the same mechanism. At inference, retrieved cells serve as grounding context for precise safety decisions. Across model-level safety on HarmBench and agent-level safety on AgentHarm, Membrane achieves the highest F1 on all six jailbreak attacks. Notably, benign refusal on AgentHarm stays at 7-14%, well below the 28-85% range of prior guards. Memory cells also retain 87-88% F1 under cross-attack transfer and remain stable under memory poisoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Membrane, a self-evolving guardrail for LLM agents that uses Contrastive Safety Memory (CSM) cells. Each cell stores paired conditions for blocking a harmful query and permitting a similar benign request, indexed by attack strategy. Without retraining, new interactions are distilled into cells that are claimed to generalize across topical variants of the same mechanism. At inference, retrieved cells provide context for safety decisions. The abstract reports that Membrane achieves the highest F1 on all six jailbreak attacks in HarmBench and AgentHarm evaluations, with benign refusal rates of 7-14% (vs. 28-85% for priors), 87-88% F1 under cross-attack transfer, and stability under memory poisoning.
Significance. If the empirical claims hold and the unstated mechanisms for strategy extraction, cell construction, and retrieval are sound, the approach could address a key limitation in current LLM safety systems by enabling adaptation to evolving jailbreaks while maintaining low over-refusal on benign queries, which is particularly relevant for agent-level deployments.
major comments (2)
- [Abstract] Abstract: The central generalization claim—that distilling a harmful interaction and benign counterpart into a cell indexed by 'underlying attack strategy' enables transfer to unseen topical variants—rests on three un described components: (a) the procedure for extracting the strategy label, (b) the exact content stored in each CSM cell, and (c) the retrieval function used at inference. The reported 87-88% cross-attack F1 does not isolate whether success occurs only under manual strategy matching or under the automatic indexer on novel phrasings.
- [Abstract] Abstract: Performance numbers (highest F1 on six attacks, specific refusal rates, transfer results) are stated without any description of methods, data splits, statistical tests, implementation details, or baselines, preventing verification that the experiments support the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional clarity is needed on the core mechanisms and experimental details to support the claims. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central generalization claim—that distilling a harmful interaction and benign counterpart into a cell indexed by 'underlying attack strategy' enables transfer to unseen topical variants—rests on three un described components: (a) the procedure for extracting the strategy label, (b) the exact content stored in each CSM cell, and (c) the retrieval function used at inference. The reported 87-88% cross-attack F1 does not isolate whether success occurs only under manual strategy matching or under the automatic indexer on novel phrasings.
Authors: We acknowledge the abstract's brevity leaves these components undescribed. The full manuscript details (a) LLM-based strategy extraction in Section 3.2, (b) paired harmful/benign conditions in each cell in Section 3.1, and (c) embedding-based retrieval in Section 3.3. The 87-88% cross-attack F1 used the automatic indexer on novel phrasings (Section 4.3), not manual matching. We will add a clarifying sentence to the abstract and ensure the evaluation protocol is explicit. revision: yes
-
Referee: [Abstract] Abstract: Performance numbers (highest F1 on six attacks, specific refusal rates, transfer results) are stated without any description of methods, data splits, statistical tests, implementation details, or baselines, preventing verification that the experiments support the claims.
Authors: The abstract is concise by design, but we agree it should better signpost the supporting details. Section 4 describes the HarmBench and AgentHarm splits, baselines, implementation, and statistical tests (with full results in the appendix). We will incorporate a brief methods overview into the abstract and verify all experimental claims are traceable to the methods section. revision: yes
Circularity Check
No circularity: empirical benchmark results on jailbreak defense with no derivation chain or self-referential definitions
full rationale
The paper presents Membrane as an empirical system for LLM safety: it describes a contrastive memory construction process and reports F1 scores, transfer results, and refusal rates on HarmBench and AgentHarm. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citations are invoked to derive the core performance claims. The abstract and provided text contain only system description plus measured outcomes; the generalization assumption is stated as a design goal but is not reduced to a tautology or prior self-result by construction. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Contrastive Safety Memory (CSM) cells
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 , month = apr, howpublished =
Our evaluation of. 2026 , month = apr, howpublished =
2026
-
[2]
Gemini 3 Flash Model Card , year=
-
[3]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Jailbreaking black box large language models in twenty queries , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
2025
-
[4]
arXiv preprint arXiv:2510.02373 , year=
A-memguard: A proactive defense framework for llm-based agent memory , author=. arXiv preprint arXiv:2510.02373 , year=
-
[5]
International Conference on Machine Learning , pages=
ShieldAgent: Shielding Agents via Verifiable Safety Policy Reasoning , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[6]
arXiv preprint arXiv:2510.21910 , year=
Adversarial D\'ej\`a Vu: Jailbreak Dictionary Learning for Stronger Generalization to Unseen Attacks , author=. arXiv preprint arXiv:2510.21910 , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
A wolf in sheep’s clothing: Generalized nested jailbreak prompts can fool large language models easily , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=. 2024 , url=
2024
-
[9]
Advances in neural information processing systems , volume=
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms , author=. Advances in neural information processing systems , volume=. 2024 , url=
2024
-
[10]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Trustagent: Towards safe and trustworthy llm-based agents , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=. 2024 , url=
2024
-
[11]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
International Conference on Machine Learning , pages=
FlipAttack: Jailbreak LLMs via Flipping , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[13]
Edward Suh and Yevgeniy Vorobeychik and Zhuoqing Mao and Somesh Jha and Patrick McDaniel and Huan Sun and Bo Li and Chaowei Xiao , booktitle=
Xiaogeng Liu and Peiran Li and G. Edward Suh and Yevgeniy Vorobeychik and Zhuoqing Mao and Somesh Jha and Patrick McDaniel and Huan Sun and Bo Li and Chaowei Xiao , booktitle=. Auto. 2025 , url=
2025
-
[14]
ICLR 2025 Workshop on Foundation Models in the Wild , year=
GuardReasoner: Towards Reasoning-based LLM Safeguards , author=. ICLR 2025 Workshop on Foundation Models in the Wild , year=
2025
-
[15]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Agrail: A lifelong agent guardrail with effective and adaptive safety detection , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , url=
2025
-
[16]
Proceedings of the 41st International Conference on Machine Learning , pages=
HarmBench: a standardized evaluation framework for automated red teaming and robust refusal , author=. Proceedings of the 41st International Conference on Machine Learning , pages=. 2024 , url=
2024
-
[17]
Advances in Neural Information Processing Systems , volume=
Tree of attacks: Jailbreaking black-box llms automatically , author=. Advances in Neural Information Processing Systems , volume=. 2024 , url=
2024
-
[18]
Patil and Ion Stoica and Joseph E
Charles Packer and Sarah Wooders and Kevin Lin and Vivian Fang and Shishir G. Patil and Ion Stoica and Joseph E. Gonzalez , title =. 2024 , eprint =
2024
-
[19]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
The Fourteenth International Conference on Learning Representations , year=
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory , author=. The Fourteenth International Conference on Learning Representations , year=
-
[21]
Transactions on Machine Learning Research , year=
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks , author=. Transactions on Machine Learning Research , year=
-
[22]
SafeHarbor: Hierarchical Memory-Augmented Guardrail for LLM Agent Safety
SafeHarbor: Hierarchical Memory-Augmented Guardrail for LLM Agent Safety , author=. arXiv preprint arXiv:2605.05704 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[24]
Transactions on Machine Learning Research , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , year=
-
[25]
34th USENIX Security Symposium (USENIX Security 25) , pages=
\ SelfDefend \ : \ LLMs \ can defend themselves against jailbreaking in a practical manner , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=. 2025 , url=
2025
-
[26]
Advances in neural information processing systems , volume=
Jailbroken: How does llm safety training fail? , author=. Advances in neural information processing systems , volume=. 2023 , url=
2023
-
[27]
GuardAgent: Safeguard
Zhen Xiang and Linzhi Zheng and Yanjie Li and Junyuan Hong and Qinbin Li and Han Xie and Jiawei Zhang and Zidi Xiong and Chulin Xie and Carl Yang and Dawn Song and Bo Li , booktitle=. GuardAgent: Safeguard. 2025 , url=
2025
-
[28]
Nature Machine Intelligence , volume=
Defending chatgpt against jailbreak attack via self-reminders , author=. Nature Machine Intelligence , volume=. 2023 , publisher=
2023
-
[29]
Advances in Neural Information Processing Systems , volume=
A-mem: Agentic memory for llm agents , author=. Advances in Neural Information Processing Systems , volume=. 2026 , url=
2026
-
[30]
arXiv preprint arXiv:2509.16861 , year=
AdaptiveGuard: Towards Adaptive Runtime Safety for LLM-Powered Software , author=. arXiv preprint arXiv:2509.16861 , year=
-
[31]
arXiv preprint arXiv:2508.16406 , year=
Retrieval-Augmented Defense: Adaptive and Controllable Jailbreak Prevention for Large Language Models , author=. arXiv preprint arXiv:2508.16406 , year=
-
[32]
The Eleventh International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[33]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , url=
2024
-
[34]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[35]
Agent Security Bench (
Hanrong Zhang and Jingyuan Huang and Kai Mei and Yifei Yao and Zhenting Wang and Chenlu Zhan and Hongwei Wang and Yongfeng Zhang , booktitle=. Agent Security Bench (. 2025 , url=
2025
-
[36]
Proceedings of the AAAI conference on artificial intelligence , volume=
Memorybank: Enhancing large language models with long-term memory , author=. Proceedings of the AAAI conference on artificial intelligence , volume=. 2024 , url=
2024
-
[37]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
2025 , url=
Chi-Wei Chang and Richard Tzong-Han Tsai , journal=. 2025 , url=
2025
-
[39]
Proceedings of the 41st International Conference on Machine Learning , pages=
The WMDP benchmark: measuring and reducing malicious use with unlearning , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[40]
Llama Guard 3 Model Card , year =
-
[41]
AEGIS 2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails
Ghosh, Shaona and Varshney, Prasoon and Sreedhar, Makesh Narsimhan and Padmakumar, Aishwarya and Rebedea, Traian and Varghese, Jibin Rajan and Parisien, Christopher. AEGIS 2.0: A Diverse AI Safety Dataset and Risks Taxonomy for Alignment of LLM Guardrails. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com...
2025
-
[42]
do anything now
" do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models , author=. Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages=. 2024 , url=
2024
-
[43]
Towards Understanding Jailbreak Attacks in LLM s: A Representation Space Analysis
Lin, Yuping and He, Pengfei and Xu, Han and Xing, Yue and Yamada, Makoto and Liu, Hui and Tang, Jiliang. Towards Understanding Jailbreak Attacks in LLM s: A Representation Space Analysis. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024
2024
-
[44]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=. 2024 , url=
2024
-
[45]
International Conference on Machine Learning , pages=
OR-Bench: An Over-Refusal Benchmark for Large Language Models , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[46]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Many-shot Jailbreaking , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[47]
Jailbreaking Leading Safety-Aligned
Maksym Andriushchenko and Francesco Croce and Nicolas Flammarion , booktitle=. Jailbreaking Leading Safety-Aligned. 2025 , url=
2025
-
[48]
Passage Re-ranking with BERT , author=. arXiv preprint arXiv:1901.04085 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[49]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=. 2020 , url=
2020
-
[50]
Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
Colbert: Efficient and effective passage search via contextualized late interaction over bert , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[51]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Is ChatGPT good at search? investigating large language models as re-ranking agents , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=. 2023 , url=
2023
-
[52]
Tricking LLM s into Disobedience: Formalizing, Analyzing, and Detecting Jailbreaks
Rao, Abhinav and Vashistha, Sachin and Naik, Atharva and Aditya, Somak and Choudhury, Monojit. Tricking LLM s into Disobedience: Formalizing, Analyzing, and Detecting Jailbreaks. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[53]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
Jailbreak attacks and defenses against large language models: A survey , author=. arXiv preprint arXiv:2407.04295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
AgentHarm: A Benchmark for Measuring Harmfulness of
Maksym Andriushchenko and Alexandra Souly and Mateusz Dziemian and Derek Duenas and Maxwell Lin and Justin Wang and Dan Hendrycks and Andy Zou and J Zico Kolter and Matt Fredrikson and Yarin Gal and Xander Davies , booktitle=. AgentHarm: A Benchmark for Measuring Harmfulness of. 2025 , url=
2025
-
[55]
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Nvidia nemotron nano 2: An accurate and efficient hybrid mamba-transformer reasoning model , author=. arXiv preprint arXiv:2508.14444 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Olmo 3 , author=. arXiv preprint arXiv:2512.13961 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Athena: Safe Autonomous Agents with Verbal Contrastive Learning
Sadhu, Tanmana and Pesaranghader, Ali and Chen, Yanan and Yi, Dong Hoon. Athena: Safe Autonomous Agents with Verbal Contrastive Learning. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2024. doi:10.18653/v1/2024.emnlp-industry.84
-
[58]
Yi Nian and Shenzhe Zhu and Yuehan Qin and Li Li and Ziyi Wang and Chaowei Xiao and Yue Zhao , booktitle=. Jail. 2025 , url=
2025
-
[59]
AgentPoison: Red-teaming
Zhaorun Chen and Zhen Xiang and Chaowei Xiao and Dawn Song and Bo Li , booktitle=. AgentPoison: Red-teaming. 2024 , url=
2024
-
[60]
Memory Injection Attacks on
Shen Dong and Shaochen Xu and Pengfei He and Yige Li and Jiliang Tang and Tianming Liu and Hui Liu and Zhen Xiang , booktitle=. Memory Injection Attacks on. 2025 , url=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.