Imagine Before You Predict: Interleaved Latent Visual Reasoning for Video Event Prediction
Pith reviewed 2026-06-28 02:42 UTC · model grok-4.3
The pith
Interleaved latent visual reasoning improves video event prediction by keeping intermediate steps in visual latent space rather than text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
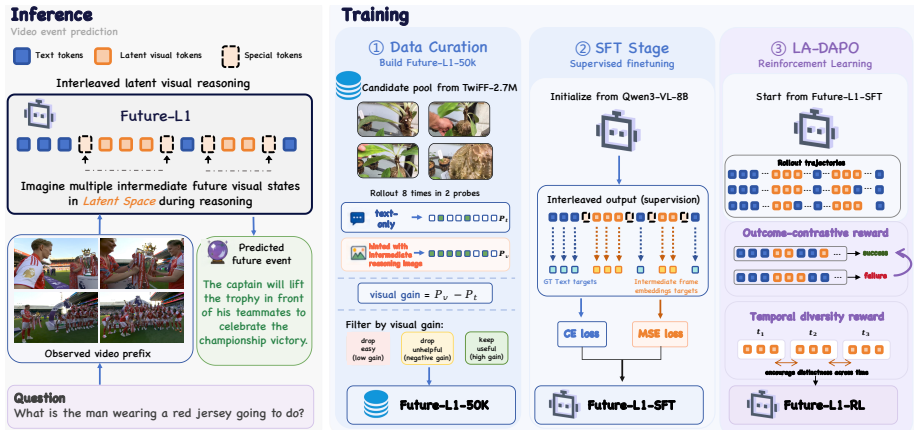
Future-L1 enables an MLLM to perform autoregressive decoding that interleaves language tokens with continuous latent visual spans, trained on Future-L1-50K examples selected for helpful future visual hints, with latent states aligned to future-frame embeddings and further optimized by LA-DAPO using outcome-contrastive and temporal-diversity rewards, producing state-of-the-art scores of 85.4 on FutureBench and 3.04 on TwiFF-Bench.
What carries the argument
Interleaved latent visual reasoning that alternates language tokens with continuous latent visual spans to retain intermediate visual semantics during prediction.
If this is right
- Future-L1 raises the base model's FutureBench score from 61.0 to 85.4.
- Future-L1 surpasses the prior best method by 10.4 points on FutureBench.
- Future-L1 raises the average TwiFF-Bench score from 2.44 to 3.04.
- Future-oriented video reasoning improves when intermediate visual semantics stay in latent space instead of being translated to text.
Where Pith is reading between the lines
- The interleaving technique may transfer to other predictive multimodal tasks such as robotic action planning where visual continuity matters.
- Similar latent preservation could reduce hallucinations in longer-horizon video tasks if the alignment procedure scales without additional supervision.
- The approach suggests a broader design pattern: keep visual information in continuous latent form until the final output step is required.
Load-bearing premise
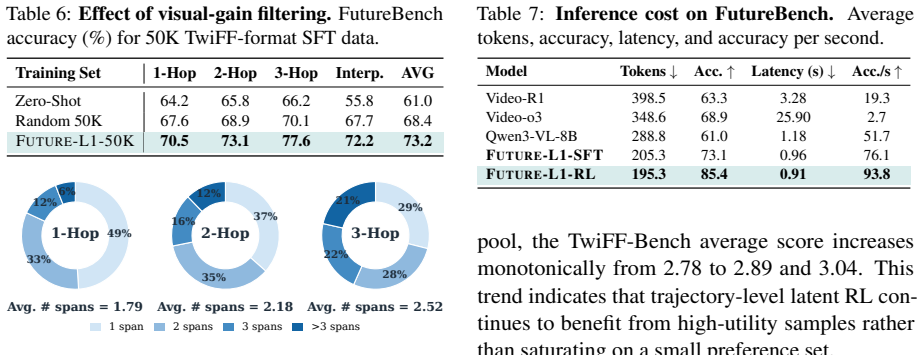
Selecting examples where future visual hints help prediction and aligning latent states to future-frame embeddings produces a generalizable signal rather than overfitting to the chosen subset or alignment artifacts.
What would settle it
An ablation that trains the same base model on the identical data but removes the latent-state alignment step or the selection criterion, then measures whether the large benchmark gains disappear.
Figures














read the original abstract
Video event prediction (VEP) requires models to infer unobserved future states from partial video evidence. Existing video MLLMs usually verbalize intermediate future reasoning in text space: once visual evidence is verbalized, fine-grained motion, geometry, and interaction cues can be lost, leading to plausible but visually ungrounded hallucinations. We introduce Future-L1, an interleaved latent visual reasoning framework that lets an MLLM alternate between language tokens and continuous latent visual spans during autoregressive decoding. To train this capability, we construct Future-L1-50K by selecting examples where future visual hints help prediction and align latent states to future-frame embeddings, then further optimize sampled latent trajectories with LA-DAPO, a latent-aware RL objective with outcome-contrastive and temporal-diversity rewards. Future-L1 achieves new state-of-the-art results on both benchmarks: on FutureBench, it improves Qwen3-VL-8B from 61.0 to 85.4 and exceeds the previous best Video-CoE by 10.4 points; on TwiFF-Bench, it improves the average score from 2.44 to 3.04. These results suggest that future-oriented video reasoning benefits from preserving intermediate visual semantics in latent space rather than translating every reasoning step into text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Future-L1, an interleaved latent visual reasoning framework for video event prediction in multimodal large language models. It constructs the Future-L1-50K dataset by filtering for examples where future visual hints aid prediction and aligning latent states to future-frame embeddings, then optimizes using the LA-DAPO objective with outcome-contrastive and temporal-diversity rewards. The method claims to achieve state-of-the-art performance, improving Qwen3-VL-8B from 61.0 to 85.4 on FutureBench and from 2.44 to 3.04 on TwiFF-Bench, attributing the gains to preserving intermediate visual semantics in latent space rather than verbalizing all reasoning steps.
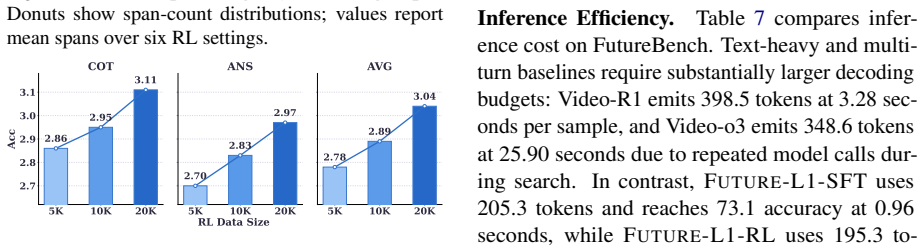
Significance. If the central performance improvements can be shown to arise specifically from the interleaved latent reasoning mechanism rather than from the dataset curation and alignment procedures, the work would represent a meaningful advance in video event prediction by highlighting the benefits of maintaining visual information in continuous latent form during reasoning. The reported gains are large, but their attribution requires further validation.
major comments (3)
- [Abstract / Dataset construction] The Future-L1-50K dataset is constructed by selecting only those examples where future visual hints help prediction. This filtering step, combined with alignment of latent states to future-frame embeddings, may preferentially include cases amenable to visual matching or introduce leakage; without an ablation on the unfiltered dataset or without the alignment loss, the claim that gains (e.g., +24.4 points on FutureBench) result from interleaved latent reasoning is not isolated from these training choices.
- [Abstract / Training procedure] The optimization uses LA-DAPO with custom outcome-contrastive and temporal-diversity rewards after alignment. These steps explicitly tie predictions to quantities derived from the training data's future frames. The manuscript provides no controls or ablations demonstrating that the same architecture without selection filter or alignment would yield comparable results, undermining the mechanistic attribution in the abstract.
- [Abstract / Experimental results] The abstract reports large benchmark gains but supplies no experimental details, error bars, ablation studies, or controls for the dataset selection step. This prevents verification of whether the central performance claim is supported by the methods.
minor comments (1)
- The abstract mentions 'Future-L1-50K' and 'LA-DAPO' without defining them in the provided text; ensure full definitions and motivations are clear in the introduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to isolate the contribution of interleaved latent visual reasoning from dataset construction and optimization choices. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Dataset construction] The Future-L1-50K dataset is constructed by selecting only those examples where future visual hints help prediction. This filtering step, combined with alignment of latent states to future-frame embeddings, may preferentially include cases amenable to visual matching or introduce leakage; without an ablation on the unfiltered dataset or without the alignment loss, the claim that gains (e.g., +24.4 points on FutureBench) result from interleaved latent reasoning is not isolated from these training choices.
Authors: We agree that the filtering and alignment steps require explicit controls to strengthen attribution. In the revision we will add ablations on the unfiltered dataset and without the alignment loss, reporting the resulting performance to demonstrate the incremental benefit of the interleaved latent mechanism. revision: yes
-
Referee: [Abstract / Training procedure] The optimization uses LA-DAPO with custom outcome-contrastive and temporal-diversity rewards after alignment. These steps explicitly tie predictions to quantities derived from the training data's future frames. The manuscript provides no controls or ablations demonstrating that the same architecture without selection filter or alignment would yield comparable results, undermining the mechanistic attribution in the abstract.
Authors: The LA-DAPO rewards are intended to promote latent-space future reasoning. We will include the requested controls (architecture without the selection filter and without alignment) in the revised manuscript to clarify the source of the observed gains. revision: yes
-
Referee: [Abstract / Experimental results] The abstract reports large benchmark gains but supplies no experimental details, error bars, ablation studies, or controls for the dataset selection step. This prevents verification of whether the central performance claim is supported by the methods.
Authors: Abstract length limits preclude full experimental detail. The main text and supplement already contain the core experimental protocol; we will add error bars, the new ablation results, and explicit controls for the selection step in the revision to enable direct verification. revision: yes
Circularity Check
No significant circularity; empirical method with external benchmarks
full rationale
The paper presents an empirical training procedure (data curation, latent alignment, and custom RL) and reports numerical improvements on named external benchmarks (FutureBench, TwiFF-Bench). No equations, uniqueness theorems, or self-citations are invoked to derive the central claim; the performance numbers are presented as measured outcomes rather than identities or forced statistical consequences of the training inputs. The method is therefore self-contained against its stated benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- LA-DAPO reward weights
axioms (1)
- domain assumption Aligning model latent states to future-frame embeddings preserves useful visual semantics for downstream prediction
invented entities (3)
-
Future-L1-50K dataset
no independent evidence
-
LA-DAPO objective
no independent evidence
-
latent visual spans
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ECCV , pages =
Yi Wang and Kunchang Li and Xinhao Li and Jiashuo Yu and Yinan He and Guo Chen and Baoqi Pei and Rongkun Zheng and Zun Wang and Yansong Shi and Tianxiang Jiang and Songze Li and Jilan Xu and Hongjie Zhang and Yifei Huang and Yu Qiao and Yali Wang and Limin Wang , title =. ECCV , pages =
-
[2]
Hello GPT-4o , author=
-
[3]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Janus-pro: Unified multimodal understanding and generation with data and model scaling , author=. arXiv preprint arXiv:2501.17811 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
VideoChat: Chat-Centric Video Understanding
Videochat: Chat-centric video understanding , author=. arXiv preprint arXiv:2305.06355 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
2024 , journal =
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling , author =. 2024 , journal =
2024
-
[7]
2024 , journal =
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning , author =. 2024 , journal =
2024
-
[8]
2025 , journal =
Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment , author =. 2025 , journal =
2025
-
[9]
2025 , journal =
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling , author =. 2025 , journal =
2025
-
[10]
2025 , journal =
Emerging Properties in Unified Multimodal Pretraining , author =. 2025 , journal =
2025
-
[11]
Advances in Neural Information Processing Systems , volume=
Video-r1: Reinforcing video reasoning in mllms , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning , author=. arXiv preprint arXiv:2504.06958 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2025 , journal =
Qwen2.5-VL Technical Report , author =. 2025 , journal =
2025
-
[14]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis , author=. arXiv preprint arXiv:2405.21075 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
MLVU: Benchmarking Multi-task Long Video Understanding
Mlvu: A comprehensive benchmark for multi-task long video understanding , author=. arXiv preprint arXiv:2406.04264 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mvbench: A comprehensive multi-modal video understanding benchmark , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[17]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[18]
YOLOv11: An Overview of the Key Architectural Enhancements
Yolov11: An overview of the key architectural enhancements , author=. arXiv preprint arXiv:2410.17725 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding , author=. arXiv preprint arXiv:2501.13106 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms , author=. arXiv preprint arXiv:2406.07476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Llava-video: Video instruction tuning with synthetic data , author=. arXiv preprint arXiv:2410.02713 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Thinking in space: How multimodal large language models see, remember, and recall spaces , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[23]
LLaVA-NeXT: A Strong Zero-shot Video Understanding Model , url=
Zhang, Yuanhan and Li, Bo and Liu, haotian and Lee, Yong jae and Gui, Liangke and Fu, Di and Feng, Jiashi and Liu, Ziwei and Li, Chunyuan , month=. LLaVA-NeXT: A Strong Zero-shot Video Understanding Model , url=
-
[24]
2025 , eprint=
MiMo-VL Technical Report , author=. 2025 , eprint=
2025
-
[25]
2025 , journal =
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models , author =. 2025 , journal =
2025
-
[26]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Claude 3.5 Sonnet , year =
-
[28]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Tempcompass: Do video llms really understand videos? , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[29]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Make your training flexible: Towards deployment-efficient video models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[30]
arXiv preprint arXiv:2511.20272 , year=
VKnowU: Evaluating Visual Knowledge Understanding in Multimodal LLMs , author=. arXiv preprint arXiv:2511.20272 , year=
-
[31]
arXiv preprint arXiv:2410.12381 , year=
HumanEval-V: Benchmarking High-Level Visual Reasoning with Complex Diagrams in Coding Tasks , author=. arXiv preprint arXiv:2410.12381 , year=
-
[32]
Multimodal Chain-of-Thought Reasoning in Language Models
Multimodal Chain-of-Thought Reasoning in Language Models , author=. arXiv preprint arXiv:2302.00923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Anticipating Human Activities Using Object Affordances for Reactive Robotic Response , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[34]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Anticipating Visual Representations from Unlabeled Video , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[35]
arXiv preprint arXiv:2403.13315 , year=
PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns , author=. arXiv preprint arXiv:2403.13315 , year=
-
[36]
arXiv preprint arXiv:2404.03622 , year=
Mind's Eye of LLMs: Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models , author=. arXiv preprint arXiv:2404.03622 , year=
-
[37]
arXiv preprint arXiv:2406.09403 , year=
Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models , author=. arXiv preprint arXiv:2406.09403 , year=
-
[38]
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought , author=. arXiv preprint arXiv:2501.07542 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Multimodal Chain of Continuous Thought for Latent-Space Reasoning in Vision-Language Models , author=. arXiv preprint arXiv:2508.12587 , year=
-
[40]
arXiv preprint arXiv:2511.19418 , year=
Chain-of-Visual-Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens , author=. arXiv preprint arXiv:2511.19418 , year=
-
[41]
arXiv preprint arXiv:2510.11606 , year=
ExpVid: A Benchmark for Experiment Video Understanding & Reasoning , author=. arXiv preprint arXiv:2510.11606 , year=
-
[42]
European conference on computer vision , pages=
Internvideo2: Scaling foundation models for multimodal video understanding , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[43]
International Conference on Learning Representations , volume=
Timesuite: Improving mllms for long video understanding via grounded tuning , author=. International Conference on Learning Representations , volume=
-
[44]
arXiv preprint arXiv:2603.03985 , year=
RIVER: A Real-Time Interaction Benchmark for Video LLMs , author=. arXiv preprint arXiv:2603.03985 , year=
-
[45]
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning , author=. arXiv preprint arXiv:2601.23224 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Kimi K2.5: Visual Agentic Intelligence
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding , author=. arXiv preprint arXiv:2604.05015 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
2026 , eprint=
LLaVA-OneVision-2: Towards Next-Generation Perceptual Intelligence , author=. 2026 , eprint=
2026
-
[50]
GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents
GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents , author=. arXiv preprint arXiv:2604.26752 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Thinking with Visual Primitives , author=
-
[52]
MiMo-V2-Flash Technical Report
Mimo-v2-flash technical report , author=. arXiv preprint arXiv:2601.02780 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Videoespresso: A large-scale chain-of-thought dataset for fine-grained video reasoning via core frame selection , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[54]
arXiv preprint arXiv:2602.10675 , year=
TwiFF (Think With Future Frames): A Large-Scale Dataset for Dynamic Visual Reasoning , author=. arXiv preprint arXiv:2602.10675 , year=
-
[55]
arXiv preprint arXiv:2507.16746 , year=
Zebra-cot: A dataset for interleaved vision language reasoning , author=. arXiv preprint arXiv:2507.16746 , year=
-
[56]
arXiv preprint arXiv:2510.27492 , year=
Thinkmorph: Emergent properties in multimodal interleaved chain-of-thought reasoning , author=. arXiv preprint arXiv:2510.27492 , year=
-
[57]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Deepeyes: Incentivizing" thinking with images" via reinforcement learning , author=. arXiv preprint arXiv:2505.14362 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
arXiv preprint arXiv:2601.05175 , year=
VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice , author=. arXiv preprint arXiv:2601.05175 , year=
-
[59]
Advances in Neural Information Processing Systems , volume=
Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Training Large Language Models to Reason in a Continuous Latent Space
Training large language models to reason in a continuous latent space , author=. arXiv preprint arXiv:2412.06769 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
arXiv preprint arXiv:2509.20317 , year=
SIM-CoT: Supervised Implicit Chain-of-Thought , author=. arXiv preprint arXiv:2509.20317 , year=
-
[62]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Codi: Compressing chain-of-thought into continuous space via self-distillation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[63]
arXiv preprint arXiv:2601.10129 , year=
LaViT: Aligning Latent Visual Thoughts for Multi-modal Reasoning , author=. arXiv preprint arXiv:2601.10129 , year=
-
[64]
Latent visual reasoning , author=. arXiv preprint arXiv:2509.24251 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens
Machine mental imagery: Empower multimodal reasoning with latent visual tokens , author=. arXiv preprint arXiv:2506.17218 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
arXiv preprint arXiv:2511.21395 , year=
Monet: Reasoning in latent visual space beyond images and language , author=. arXiv preprint arXiv:2511.21395 , year=
-
[67]
arXiv preprint arXiv:2512.16584 , year=
Sketch-in-latents: Eliciting unified reasoning in mllms , author=. arXiv preprint arXiv:2512.16584 , year=
-
[68]
arXiv preprint arXiv:2602.06040 , year=
SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMs , author=. arXiv preprint arXiv:2602.06040 , year=
-
[69]
Xiaomi OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
OneVL: One-step latent reasoning and planning with vision-language explanation , author=. arXiv preprint arXiv:2604.18486 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
European conference on computer vision , pages=
A hierarchical representation for future action prediction , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[71]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Predicting the future: A jointly learnt model for action anticipation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[72]
Video (language) modeling: a baseline for generative models of natural videos
Video (language) modeling: a baseline for generative models of natural videos , author=. arXiv preprint arXiv:1412.6604 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Advances in neural information processing systems , volume=
Generating videos with scene dynamics , author=. Advances in neural information processing systems , volume=
-
[74]
arXiv preprint arXiv:2603.14935 , year=
Video-CoE: Reinforcing Video Event Prediction via Chain of Events , author=. arXiv preprint arXiv:2603.14935 , year=
-
[75]
arXiv preprint arXiv:2511.16669 , year=
Video-as-Answer: Predict and Generate Next Video Event with Joint-GRPO , author=. arXiv preprint arXiv:2511.16669 , year=
-
[76]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
EventFormer: A Node-graph Hierarchical Attention Transformer for Action-centric Video Event Prediction , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[77]
arXiv preprint arXiv:2505.22457 , year=
Fostering video reasoning via next-event prediction , author=. arXiv preprint arXiv:2505.22457 , year=
-
[78]
arXiv preprint arXiv:2505.01583 , year=
Tempura: Temporal event masked prediction and understanding for reasoning in action , author=. arXiv preprint arXiv:2505.01583 , year=
-
[79]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
What is more likely to happen next? video-and-language future event prediction , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[80]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
VidEvent: A Large Dataset for Understanding Dynamic Evolution of Events in Videos , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.