Reducing Hallucinations in Complex Question Answering using Simple Graph-based Retrieval-Augmented Generation (long version)
Pith reviewed 2026-06-28 01:13 UTC · model grok-4.3
The pith
A lightweight graph with simple schema in RAG systems halves hallucinated answers and raises factual precision on complex Wikipedia questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The introduction of graph-based tools can significantly increase the precision and recall of factual correctness, can halve the number of hallucinated answers, and achieves the highest fine-grained truthfulness score among the three evaluated scenarios, all with a modest increase in token usage.
What carries the argument
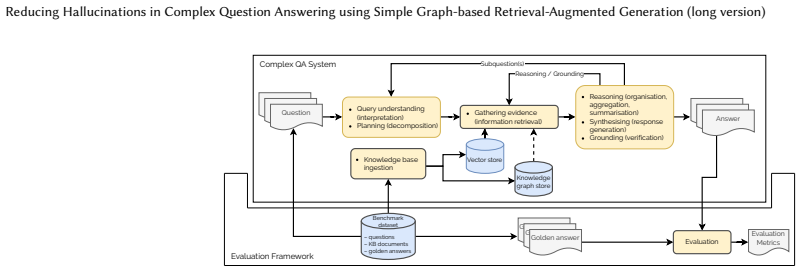
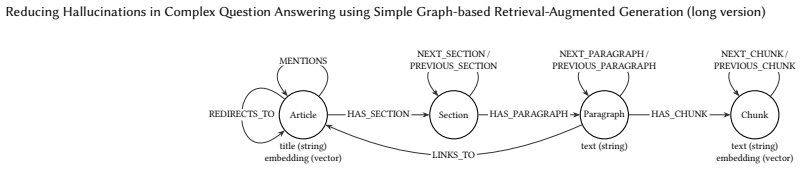
An agentic toolset of vector search and graph query tools operating over a lightweight graph with a simple schema built from curated Wikipedia articles.
If this is right
- Precision and recall of factual correctness rise when graph queries supplement vector search.
- The count of hallucinated answers drops by approximately half.
- Fine-grained truthfulness scores reach the highest level among the tested retrieval setups.
- Token usage increases only modestly compared with the non-graph baselines.
Where Pith is reading between the lines
- The same lightweight graph approach could be applied to proprietary document collections without retraining the underlying language model.
- Simple graph schemas may generalize to other complex reasoning tasks that require multi-hop factual grounding.
- Combining the graph tools with additional retrieval methods might yield further reductions in unsupported claims.
Load-bearing premise
The curated subset of English Wikipedia articles together with the chosen simple graph schema and agentic toolset are sufficient to support accurate retrieval for the complex queries in the MoNaCo benchmark.
What would settle it
Running the same agentic system on a different complex QA benchmark drawn from non-Wikipedia sources and finding no reduction in hallucination rate or truthfulness score.
Figures



read the original abstract
Large language models (LLMs) have fundamentally transformed the landscape of Natural Language Processing. Despite these advances, LLMs and LLM-based systems remain prone to a variety of failure modes. Retrieval-augmented generation (RAG) systems have emerged as a common deployment scenario seeking to both avoid the well known risk of the LLM "hallucinating" information, and to enable reasoning and question answering over proprietary information that the LLM did not have access to during training without resorting to expensive model fine-tuning. In this work, we explore the idea of using a lightweight graph structure with a relatively simple graph schema, to support the RAG subsystem via a dedicated toolset. We design an agentic system with a variety of vector search and graph query tools operating over a structured dataset based on a curated subset of English Wikipedia articles, and evaluate its performance on questions from MoNaCo, a challenging Wikipedia QA benchmark of complex query answering tasks. Our results show that the introduction of graph-based tools can significantly increase the precision and recall of factual correctness, can halve the number of hallucinated answers, and achieves the highest fine-grained truthfulness score among the three evaluated scenarios. All this with a modest increase in token usage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes an agentic RAG system that augments an LLM with both vector-search and graph-query tools over a graph constructed from a curated subset of English Wikipedia using a relatively simple schema. It evaluates the system on the MoNaCo benchmark of complex Wikipedia-based QA tasks and reports that the addition of graph-based tools raises precision and recall of factual correctness, halves the rate of hallucinated answers, and produces the highest fine-grained truthfulness score among the three evaluated configurations, at the cost of only a modest increase in token usage.
Significance. If the empirical claims are substantiated, the work would indicate that lightweight graph retrieval can materially reduce hallucinations on multi-hop factual questions without requiring elaborate schemas or fine-tuning, providing a practical, low-overhead extension to standard RAG pipelines.
major comments (2)
- [Abstract / system design paragraph] Abstract and system-design paragraph: the headline claim that graph tools raise precision/recall, halve hallucinations, and achieve top truthfulness on MoNaCo presupposes that the chosen simple schema plus agentic tools actually retrieve the facts required by the benchmark queries. No section demonstrates schema coverage of MoNaCo’s multi-hop or relational patterns, nor reports how many benchmark questions lie outside the schema’s expressivity; without this, measured gains cannot be attributed to graph retrieval.
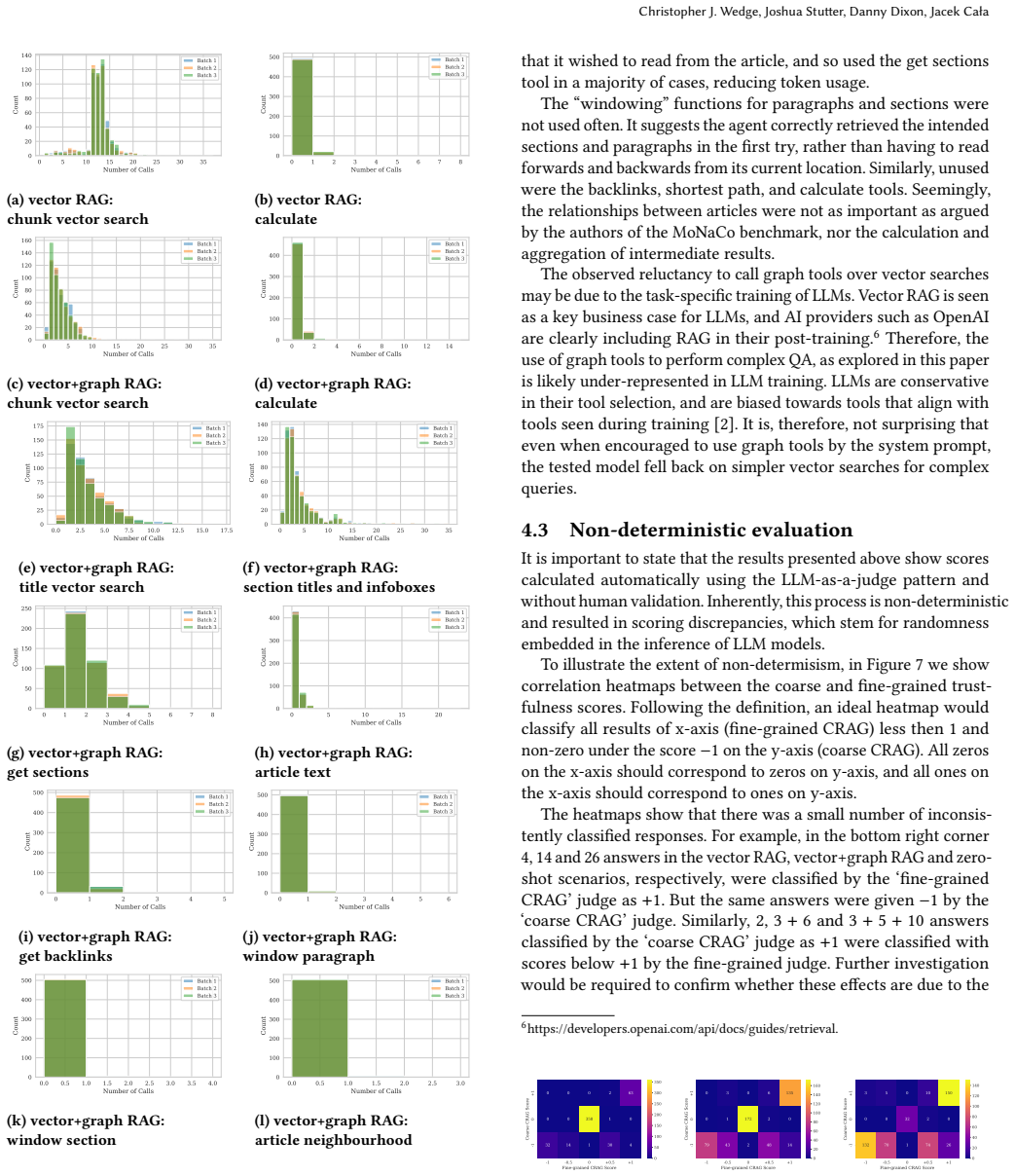
- [Evaluation] Evaluation section (implied by abstract): the abstract states positive outcomes on precision, recall, hallucination rate, and truthfulness but supplies no experimental details, baseline definitions, statistical tests, or error analysis. The support for the central claim therefore cannot be verified from the given text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / system design paragraph] Abstract and system-design paragraph: the headline claim that graph tools raise precision/recall, halve hallucinations, and achieve top truthfulness on MoNaCo presupposes that the chosen simple schema plus agentic tools actually retrieve the facts required by the benchmark queries. No section demonstrates schema coverage of MoNaCo’s multi-hop or relational patterns, nor reports how many benchmark questions lie outside the schema’s expressivity; without this, measured gains cannot be attributed to graph retrieval.
Authors: We agree that the manuscript would be strengthened by an explicit analysis of how well the chosen schema covers the relational and multi-hop patterns present in MoNaCo. No such coverage study appears in the current version. In the revision we will add a new subsection (in System Design or Evaluation) that (a) enumerates the schema’s supported relation types and path lengths, (b) samples MoNaCo questions to assess expressivity, and (c) reports an approximate coverage fraction. This will allow readers to judge how much of the measured improvement can be attributed to graph retrieval. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by abstract): the abstract states positive outcomes on precision, recall, hallucination rate, and truthfulness but supplies no experimental details, baseline definitions, statistical tests, or error analysis. The support for the central claim therefore cannot be verified from the given text.
Authors: The full manuscript contains an Evaluation section that defines the three configurations (vector-only, graph-only, combined), the MoNaCo benchmark, the factual-correctness and truthfulness metrics, and the reported numerical results. However, the referee is correct that the current text lacks statistical significance tests and a systematic error analysis. We will add both in the revision: bootstrap confidence intervals or paired significance tests for the key deltas, plus a categorized error breakdown (e.g., retrieval failure vs. reasoning failure vs. schema limitation). revision: partial
Circularity Check
No circularity: empirical evaluation on external benchmark
full rationale
The paper reports experimental results from an agentic RAG system with graph tools evaluated on the independent MoNaCo benchmark. Claims of improved precision/recall, halved hallucinations, and highest truthfulness scores rest on direct measurement against that external test set rather than any derivation, fitted parameters, or self-referential definitions. No equations, ansatzes, or load-bearing self-citations appear in the provided text; the graph schema is presented as a design choice whose coverage is tested via benchmark performance, not assumed by construction. This is a standard self-contained empirical comparison.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jinheon Baek, Alham Fikri Aji, Jens Lehmann, and Sung Ju Hwang. 2023. Direct Fact Retrieval from Knowledge Graphs without Entity Linking. InProceedings of Christopher J. Wedge, Joshua Stutter, Danny Dixon, Jacek Cała the 61st Annual Meeting of the Association for Computational Linguistics. Toronto, Canada. https://doi.org/10.18653/v1/2023.acl-long.558
-
[2]
Thierry Blankenstein, Jialin Yu, Zixuan Li, Vassilis Plachouras, Sunando Sen- gupta, Philip Torr, Yarin Gal, Alasdair Paren, and Adel Bibi. 2026. BiasBusters: Uncovering and Mitigating Tool Selection Bias in Large Language Models. In Proceedings of the Fourteenth International Conference on Learning Representations. Rio de Janeiro, Brazil. https://doi.org...
-
[3]
2025.Essential GraphRAG: Knowledge Graph- Enhanced RAG
Tomaž Bratanič and Oskar Hane. 2025.Essential GraphRAG: Knowledge Graph- Enhanced RAG. Manning Publications, Shelter Island, NY
2025
-
[4]
Andrew Brown, Muhammad Roman, and Barry Devereux. 2025. A Systematic Literature Review of Retrieval-Augmented Generation: Techniques, Metrics, and Challenges.Big Data and Cognitive Computing9 (2025), 320. Issue 12. https://doi.org/10.3390/bdcc9120320
-
[5]
Avi Caciularu, Arman Cohan, Iz Beltagy, Matthew Peters, Arie Cattan, and Ido Dagan. 2021. CDLM: Cross-Document Language Modeling. InFindings of the Association for Computational Linguistics. Punta Cana, Dominican Republic. https://doi.org/10.18653/v1/2021.findings-emnlp.225
-
[6]
Shulin Cao, Jiaxin Shi, Liangming Pan, Lunyiu Nie, Yutong Xiang, Lei Hou, Juanzi Li, Bin He, and Hanwang Zhang. 2022. KQA Pro: A Dataset with Explicit Compositional Programs for Complex Question Answering over Knowledge Base. InProceedings of the 60th Meeting of the Association for Computational Linguistics, Vol. 1: Long Papers. Dublin, Ireland, 6101–6119...
2022
-
[7]
Abir Chakraborty. 2024. Multi-hop Question Answering over Knowledge Graphs using Large Language Models. arXiv:2404.19234 https://arxiv.org/abs/2404.19234
arXiv 2024
-
[8]
Yun-Nung (Vivian) Chen, Margot Mieskes, and Siva Reddy. 2023. Retrieval-based Language Models and Applications. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Vol. 6: Tutorial Abstracts. Toronto, Canada, 41–46. https://doi.org/10.18653/v1/2023.acl-tutorials.6
-
[9]
[n.d.].The Developer’s Guide to GraphRAG
Alison Cossette, Zach Blumenfeld, and Damaso Sanoja. [n.d.].The Developer’s Guide to GraphRAG. Neo4j, San Mateo, CA. https://neo4j.com/books/the- developers-guide-to-graphrag/
-
[10]
Minghang Deng, Ashwin Ramachandran, Canwen Xu, Lanxiang Hu, Zhewei Yao, Anupam Datta, and Hao Zhang. 2025. ReFoRCE: A Text-to-SQL Agent with Self- Refinement, Format Restriction, and Column Exploration. https://openreview. net/forum?id=OuFIfDBwQd. InProceedings of the ICLR 2025 Workshop VerifAI: AI Verification in the Wild. Singapore
2025
-
[11]
Xin Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, and Wei Zhang. 2014. Knowledge vault: A Web-scale Approach to Probabilistic Knowledge Fusion. InProceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY, 601–610. https://doi.org/10.1145/2623...
-
[12]
Hwang, Soumya Sanyal, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi. 2023. Faith and Fate: Limits of Transformers on Composability. InPro- ceedings of the 37th Conference on Neural Informati...
2023
-
[13]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2025. From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130 [cs.CL] https://arxiv.org/abs/2404.16130
Pith/arXiv arXiv 2025
-
[14]
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, Márton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemiński, Genta Indra Winata, Saba Sturua, Saiteja Utpala, Mathieu Ciancone, Marion Schaeffer, Gabriel Sequeira, Diganta Misra, Shreeya Dhakal, Jonathan Rystrøm, Roman Solomatin, Ömer Çağatan, Akash Kundu, Martin Bernstorff, Shitao...
arXiv 2025
-
[15]
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. 2024. RAGAs: Automated Evaluation of Retrieval Augmented Generation. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. Association for Computational Linguistics, St. Julians, Malta, 150–158. https://aclant...
2024
-
[16]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Barcelona, Spain. https://doi.org/10.1145/3637528.3671470
-
[17]
Tengfei Feng and Liang He. 2025. RGR-KBQA: Generating Logical Forms for Question Answering Using Knowledge-Graph-Enhanced Large Language Model. InProceedings of the 31st International Conference on Computational Linguistics. Abu Dhabi, UAE, 3057–3070. https://aclanthology.org/2025.coling-main.205/
2025
-
[18]
Yanlin Feng, Simone Papicchio, and Sajjadur Rahman. 2025. CypherBench: Towards Precise Retrieval over Full-scale Modern Knowledge Graphs in the LLM Era. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. Vienna, Austria. https://doi.org/10.18653/v1/2025.acl-long.438
-
[19]
Robert Friel, Masha Belyi, and Atindriyo Sanyal. 2025. RAGBench: Explainable Benchmark for Retrieval-Augmented Generation Systems. arXiv:2407.11005 [cs.CL] https://arxiv.org/abs/2407.11005
arXiv 2025
-
[20]
Aoran Gan, Hao Yu, Kai Zhang, Qi Liu, Wenyu Yan, Zhenya Huang, Shiwei Tong, and Guoping Hu. 2025. Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey. arXiv:2504.14891 [cs.CL] https://arxiv.org/abs/2504.14891
arXiv 2025
-
[21]
Mingqi Gao, Xinyu Hu, Jie Ruan, Xiao Pu, and Xiaojun Wan. 2025. LLM-based NLG Evaluation: Current Status and Challenges. arXiv:2402.01383 [cs.CL] https://arxiv.org/abs/2402.01383
arXiv 2025
-
[22]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 https: //arxiv.org/abs/2312.10997
Pith/arXiv arXiv 2024
-
[23]
Yu Gu, Sue Kase, Michelle Vanni, Brian Sadler, Percy Liang, Xifeng Yan, and Yu Su. 2021. Beyond I.I.D.: Three Levels of Generalization for Question Answering on Knowledge Bases. InProceedings of the Web Conference 2021 (WWW ’21). ACM, 3477—-3488. https://doi.org/10.1145/3442381.3449992
-
[24]
Willis Guo, Armin Toroghi, and Scott Sanner. 2024. CR-LT-KGQA: A Knowledge Graph Question Answering Dataset Requiring Commonsense Reasoning and Long-Tail Knowledge. arXiv:2403.01395 https://arxiv.org/abs/2403.01395
arXiv 2024
-
[25]
Haoyu Han, Yu Wang, Harry Shomer, Kai Guo, Jiayuan Ding, Yongjia Lei, Ma- hantesh Halappanavar, Ryan A. Rossi, Subhabrata Mukherjee, Xianfeng Tang, Qi He, Zhigang Hua, Bo Long, Tong Zhao, Neil Shah, Amin Javari, Yinglong Xia, and Jiliang Tang. 2025. Retrieval-Augmented Generation with Graphs (GraphRAG). arXiv:2501.00309 https://arxiv.org/abs/2501.00309
Pith/arXiv arXiv 2025
-
[26]
Tianxing He, Jingyu Zhang, Tianle Wang, Sachin Kumar, Kyunghyun Cho, James Glass, and Yulia Tsvetkov. 2023. On the Blind Spots of Model-Based Evaluation Metrics for Text Generation. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). ...
2023
-
[27]
Dan Hendrycks, Collin Burns, Anya Chen, and Spencer Ball. 2021. CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review.CoRRabs/2103.06268 (2021). arXiv:2103.06268 https://arxiv.org/abs/2103.06268
arXiv 2021
-
[28]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a Multi-hop QA Dataset for Comprehensive Evaluation of Reason- ing Steps. InProceedings of the 28th International Conference on Computational Linguistics. https://doi.org/10.18653/v1/2020.coling-main.580
-
[29]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. 2024. RULER: What’s the Real Context Size of Your Long-Context Language Models?. InProccedings of the First Confer- ence on Language Modeling 2024. https://openreview.net/forum?id=kIoBbc76Sy
2024
-
[30]
Jiatan Huang, Mingchen Li, Zonghai Yao, Zhichao Yang, Yongkang Xiao, Feiyun Ouyang, Xiaohan Li, Shuo Han, and Hong Yu. 2024. RiTeK: A Dataset for Large Language Models Complex Reasoning over Textual Knowledge Graphs. arXiv:2410.13987 [cs.CL] https://arxiv.org/abs/2410.13987
Pith/arXiv arXiv 2024
-
[31]
Xiaolong Huang, Liang Wang, Furu Wei, Jingwen Lu, Knut Risvik, and Jason Li. 2026. Microsoft Open-Sources Industry-Leading Embedding Model. https://blogs.bing.com/search/April-2026/Microsoft-Open-Sources- Industry-Leading-Embedding-Model
2026
-
[32]
Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel
-
[33]
InPro- ceedings of the 40th International Conference on Machine Learning
Large Language Models Struggle to Learn Long-Tail Knowledge. InPro- ceedings of the 40th International Conference on Machine Learning. Honolulu, Hawaii, 15696–15707. https://dl.acm.org/doi/10.5555/3618408.3619049
-
[34]
Catherine Kosten, Philippe Cudré-Mauroux, and Kurt Stockinger. 2023. Spi- der4SPARQL: A Complex Benchmark for Evaluating Knowledge Graph Question Answering Systems. In2023 IEEE International Conference on Big Data (BigData). IEEE, 5272–5281. https://doi.org/10.1109/bigdata59044.2023.10386182
-
[35]
Liubov Kovriguina, Roman Teucher, Daniil Radyush, and Dmitry Mouromtsev
-
[36]
InProceedings of SEMANTiCS 2023
SPARQLGEN: One-Shot Prompt-based Approach for SPARQL Query Generation. InProceedings of SEMANTiCS 2023. Leipzig, Germany. https://ceur- ws.org/Vol-3526/paper-08.pdf Reducing Hallucinations in Complex Question Answering using Simple Graph-based Retrieval-Augmented Generation (long version)
2023
-
[37]
Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. 2019. Latent Retrieval for Weakly Supervised Open Domain Question Answering. InProcedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy. https://doi.org/10.18653/v1/P19-1612
-
[38]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented gen- eration for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M...
2020
-
[39]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Ma Chenhao, Guoliang Li, Kevin Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM Already Serve as a Databaes Interface? A Big Bench for Large-Scale Database Grounded Text-to-SQLs. InProceedings of the 37th Conference on...
2023
-
[40]
Teng Lin, Yuyu Luo, Honglin Zhang, Jicheng Zhang, Chunlin Liu, Kaishun Wu, and Nan Tang. 2025. MEBench: Benchmarking Large Language Models for Cross-Document Multi-Entity Question Answering. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Suzhou, China. https://doi.org/10.18653/v1/2025.emnlp-main.77
-
[41]
Shicheng Liu, Sina Semnani, Harold Triedman, Jialiang Xu, Isaac Dan Zhao, and Monica Lam. 2024. SPINACH: SPARQL-Based Information Navigation for Chal- lenging Real-World Questions. InFindings of the Association for Computational Linguistics: EMNLP 2024. Association for Computational Linguistics, Miami, FL, 15977–16001. https://doi.org/10.18653/v1/2024.fin...
-
[42]
Ozan Baris Mulayim, Avia Anwar, Umut Mete Saka, Lazlo Paul, Anand Krishnan Prakash, Gabe Fierro, Marco Pritoni, and Mario Bergés. 2025. BuildingQA: A Benchmark for Natural Language Question Answering over Building Knowledge Graphs. InProceedings of the 12th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation(...
-
[43]
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, Juntong Song, and Tong Zhang. 2024. RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Bangkok, Thailand. https://doi.org/10.18653/v1/2024.acl-long.585
-
[44]
Yone, Samyak Rajesh Jain, Namyong Park, Ryan A
Anish Pahilajani, Devasha Trivedi, Jincen Shuai, Khin S. Yone, Samyak Rajesh Jain, Namyong Park, Ryan A. Rossi, Nesreen K. Ahmed, Franck Dernoncourt, and Yu Wang. 2024. GRS-QA – Graph Reasoning-Structured Question Answering Dataset. arXiv:2411.00369 [cs.CL] https://arxiv.org/abs/2411.00369
arXiv 2024
-
[45]
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. 2024. LLM Evaluators Recognize and Favor Their Own Generations. arXiv:2404.13076 [cs.CL] https: //arxiv.org/abs/2404.13076
Pith/arXiv arXiv 2024
-
[46]
Chanhee Park, Hyeonseok Moon, Chanjun Park, and Heuiseok Lim. 2025. MI- RAGE: A Metric-Intensive Benchmark for Retrieval-Augmented Generation Evaluation. InFindings of the Association for Computational Linguistics: NAACL
2025
-
[47]
https://aclanthology.org/2025.findings-naacl.157
Association for Computational Linguistics, Albuquerque, New Mexico, 2883–2900. https://aclanthology.org/2025.findings-naacl.157
2025
-
[48]
Miller, and Sebastian Riedel
Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, and Sebastian Riedel. 2019. Language Models as Knowledge Bases?. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Hong Kong, China, 2463–2473. https://doi.org/10.18653/ v1/D19-1250
2019
-
[49]
Julian Schnitzler, Xanh Ho, Jiahao Huang, Florian Boudin, Saku Sugawara, and Akiko Aizawa. 2024. MoreHopQA: More Than Multi-hop Reasoning. arXiv:2406.13397 https://arxiv.org/abs/2406.13397
arXiv 2024
-
[50]
Tommaso Soru, Edgard Marx, Diego Moussallem, Gustavo Publio, André Valdes- tilhas, Diego Esteves, and Ciro Baron Neto. 2017. SPARQL as a Foreign Language. https://ceur-ws.org/Vol-2044/paper14/paper14.pdf. InProceedings of SEMAN- TiCS 2017. Amsterdam, Netherlands
2017
-
[51]
Heydar Soudani, Evangelos Kanoulas, and Faegheh Hasibi. 2024. Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge. InSIGIR-AP 2024: Proceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region. Tokyo, Japan. https://doi.org/10.1145/3673791.3698415
-
[52]
Jan Strich, Enes Kutay Isgorur, Maximilian Trescher, Chris Biemann, and Mar- tin Semmann. 2025. T 2-RAGBench: Text-and-Table Benchmark for Evaluating Retrieval-Augmented Generation. arXiv:2506.12071 https://arxiv.org/abs/2506. 12071
arXiv 2025
-
[53]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[54]
arXiv:2108.00573 https://arxiv.org/abs/2108.00573
MuSiQue: Multihop Questions via Single-hop Question Composition. arXiv:2108.00573 https://arxiv.org/abs/2108.00573
-
[55]
VibrantLabs. 2024. Ragas: Supercharge Your LLM Application Evaluations. https: //github.com/vibrantlabsai/ragas
2024
-
[56]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. 2024. MMLU-Pro: A More Robust and Challenging Multi-Task Language Understand- ing Benchmark. arXiv:2406.01574 [cs.CL] https://arxiv.org/abs/2406.01574
Pith/arXiv arXiv 2024
-
[57]
Tomer Wolfson, Harsh Trivedi, Mor Geva, Yoav Goldberg, Dan Roth, Tushar Khot, Ashish Sabharwal, and Reut Tsarfaty. 2026. MoNaCo: More Natural and Complex Questions for Reasoning Across Dozens of Documents.Transactions of the Association for Computational Linguistics14 (Jan. 2026), 23–46. https: //doi.org/10.1162/TACL.a.64
-
[58]
Ioannidis, Karthik Subbian, James Zou, and Jure Leskovec
Shirley Wu, Shiyu Zhao, Michihiro Yasunaga, Kexin Huang, Kaidi Cao, Qian Huang, Vassilis N. Ioannidis, Karthik Subbian, James Zou, and Jure Leskovec. 2024. STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, an...
-
[59]
Yilin Xiao, Junnan Dong, Chuang Zhou, Su Dong, Qian wen Zhang, Di Yin, Xing Sun, and Xiao Huang. 2025. GraphRAG-Bench: Challenging Domain- Specific Reasoning for Evaluating Graph Retrieval-Augmented Generation. arXiv:2506.02404 [cs.CL] https://arxiv.org/abs/2506.02404
arXiv 2025
-
[60]
Xiao Yang, Kai Sun, Hao Xin, Yushi Sun, Nikita Bhalla, Xiangsen Chen, Sa- jal Choudhary, Rongze Daniel Gui, Ziran Will Jiang, Ziyu Jiang, Lingkun Kong, Brian Moran, Jiaqi Wang, Yifan Ethan Xu, An Yan, Chenyu Yang, Et- ing Yuan, Hanwen Zha, Nan Tang, Lei Chen, Nicolas Scheffer, Yue Liu, Nirav Shah, Rakesh Wanga, Anuj Kumar, Wen-tau Yih, and Xin Luna Dong. ...
-
[61]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Rus- lan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium. https://doi.org/10.18653/v1/D18-1259
-
[62]
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, and Zhaofeng Liu. 2025. Evaluation of Retrieval-Augmented Generation: A Survey. Springer Nature Singa- pore, 102–120. http://dx.doi.org/10.1007/978-981-96-1024-2_8
-
[63]
Yixiao Zeng, Tianyu Cao, Danqing Wang, Xinran Zhao, Zimeng Qiu, Morteza Ziyadi, Tongshuang Wu, and Lei Li. 2025. RARE: Retrieval-Aware Robustness Evaluation for Retrieval-Augmented Generation Systems. https://doi.org/10. 48550/arXiv.2506.00789 arXiv:2506.00789
arXiv 2025
-
[64]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Killian Q. Weinberger, and Yoav Artzi
-
[65]
", t IN texts | CASE WHEN s =
BERTScore: Evaluating Text Generation with BERT. InProceedings of the 2020 International Conference on Learning Representations. Addis Ababa, Ethiopia. https://openreview.net/pdf?id=SkeHuCVFDr A BENCHMARK DATASET There are three main advantages to using an external knowledge base as a backend for information retrieval to an LLM. Firstly, an LLM is of a se...
2020
-
[66]
A concise answer or list of answers with no additional text,
-
[67]
article:1234:s8:p2:c0
A concise explanation of how you arrived at the answer. If you don't know the answer to the question, return the answer as'unknown'and in the explanation describe why you can't answer the question. This is a test so you can't ask any clarifying questions, so might need to make assumptions. If you make an assumption provide in the explanation a concise sta...
-
[68]
start by using the'vector_search_article' tool to find relevant articles
-
[69]
use the'get_section_titles_and_infoboxes' tool to read the infoboxes and find the relevant sections of those articles
-
[70]
Answer:␣{agent_answer}\ nExplanation:␣{explanation}
use'get_sections'to retrieve the text and tables of the relevant sections. Sometimes the required information might be in an infobox so you might not need to read any sections. Some sections might be empty as they contained links that aren't in the snapshot, but you can use the'get_backlinks' tool to find other articles that link to the relevant article. ...
-
[71]
If the model returns'unknown'or says that it couldn't answer the question or it doesn't have enough information to answer the question, then you must return 0
-
[72]
If the model makes a prediction, rather than saying it doesn't know, but the prediction does not match any of the provided answers from the Ground Truth Answer list then the prediction is wrong and you must return -1
-
[73]
If the model prediction matches all provided answers from the Ground Truth Answer list then the prediction is fully correct and you must return +1
-
[74]
Only if the prediction does not include any additional incorrect answers, then you must return +0.5
If the model prediction matches a subset of the provided answers from the Ground Truth Answer list but some correct answers are missing, then the prediction is partially correct. Only if the prediction does not include any additional incorrect answers, then you must return +0.5
-
[75]
The question is {user_input}, the model prediction and explanation are {combined_answer}, and the Ground Truth answers are {reference}
If the model prediction includes some correct answers from the Ground Truth Answer list but also includes any incorrect answers (answers not in the Ground Truth Answer list), then model is incorrect, and you must return -0.5. The question is {user_input}, the model prediction and explanation are {combined_answer}, and the Ground Truth answers are {referen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.