Memory is Reconstructed, Not Retrieved: Graph Memory for LLM Agents
Pith reviewed 2026-06-28 01:06 UTC · model grok-4.3
The pith
LLM agents can reason over long histories by actively reconstructing memory from a Cue-Tag-Content graph instead of using static retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Memory for LLM agents is reconstructed rather than retrieved: an associative Cue-Tag-Content graph supplies semantic bridges via tags, and an active reconstruction mechanism folds LLM reasoning directly into the access process so that retrieval paths are explored and pruned on the basis of accumulating evidence.
What carries the argument
The Cue-Tag-Content graph, in which associative tags serve as semantic bridges between fine-grained cues and memory contents, operated on by an active reconstruction mechanism that integrates LLM reasoning into iterative path exploration and pruning.
If this is right
- Memory access becomes dynamically adapted to intermediate evidence discovered during inference.
- Unconstrained expansion of retrieval paths is prevented by evidence-driven pruning.
- Long-horizon memory reasoning tasks become feasible with lower token consumption and shorter runtimes.
- The rigid retrieve-then-reason pipeline is replaced by a unified reconstruction loop.
Where Pith is reading between the lines
- The same graph-plus-reconstruction pattern could be tested on agent benchmarks that involve multi-turn tool use or multi-agent coordination.
- If the tag-construction step can be made incremental, the method might support streaming memory updates without periodic rebuilds.
- The approach may reduce the need for ever-larger context windows by keeping only the reconstructed subset active.
Load-bearing premise
The Cue-Tag-Content graph can be built and maintained so that its associative tags reliably connect cues to contents without representation errors or overhead that cancels the efficiency gains.
What would settle it
Running the MRAgent framework against the same strong baselines on the LoCoMo and LongMemEval benchmarks and observing no accuracy gain or no reduction in token or runtime cost.
Figures





read the original abstract
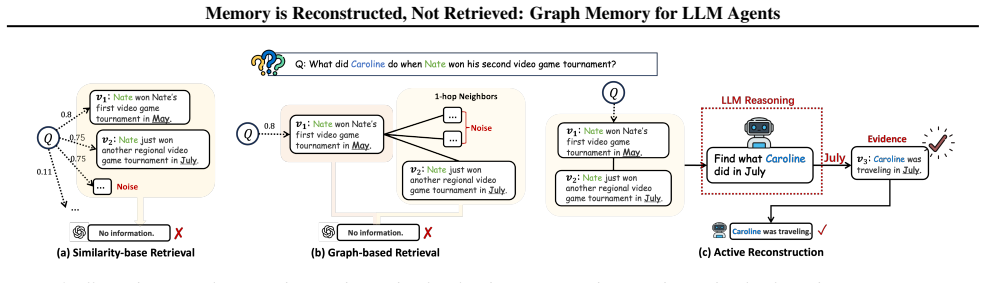
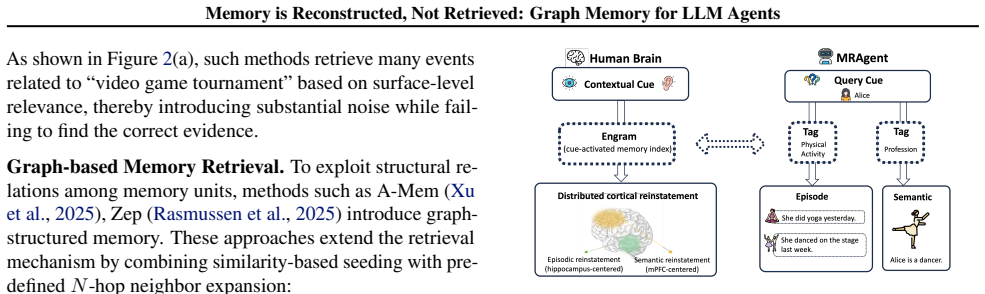
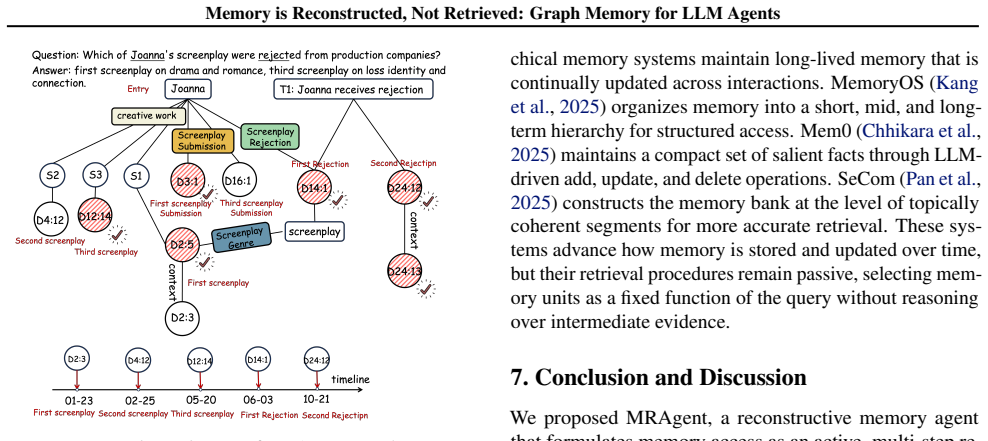
Despite recent progress, LLM agents still struggle with reasoning over long interaction histories. While current memory-augmented agents rely on a static retrieve-then-reason paradigm, this rigid pipeline design prevents them from dynamically adapting memory access to intermediate evidence discovered during inference. To bridge this gap, we propose MRAgent, a framework that combines an associative memory graph with an active reconstruction mechanism. We represent memory as a Cue-Tag-Content graph, where associative tags serve as semantic bridges connecting fine-grained cues to memory contents. Operating on this structure, our active reconstruction mechanism integrates LLM reasoning directly into memory access, allowing the agent to iteratively explore and prune retrieval paths based on accumulated evidence. This ensures that memory retrieval is dynamically adapted to the reasoning context while avoiding combinatorial explosion caused by unconstrained expansion. Experiments on the LoCoMo benchmark and LongMemEval benchmark demonstrate significant improvements over strong baselines (up to 23%), while substantially reducing token and runtime cost, highlighting the effectiveness of active and associative reconstruction for long-horizon memory reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MRAgent, a memory-augmented LLM agent framework that represents interaction histories as a Cue-Tag-Content graph in which associative tags act as semantic bridges between cues and contents. It introduces an active reconstruction mechanism that integrates LLM reasoning into the retrieval process, allowing iterative exploration and pruning of paths based on intermediate evidence. The central claim is that this dynamic, evidence-driven approach outperforms static retrieve-then-reason baselines by up to 23% on the LoCoMo and LongMemEval benchmarks while also reducing token usage and runtime.
Significance. If the performance and efficiency claims hold under rigorous validation, the work would represent a meaningful shift from static memory retrieval to adaptive reconstruction in LLM agents, with potential applicability to long-horizon tasks. The graph-based associative structure combined with evidence-driven pruning is a conceptually coherent proposal that addresses a recognized limitation in current memory-augmented agents.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): The headline claim of 'significant improvements over strong baselines (up to 23%)' and 'substantially reducing token and runtime cost' is presented without any description of the baselines used, statistical tests performed, error bars, dataset splits, or ablation studies. This absence makes it impossible to evaluate whether the reported gains support the central claim that active reconstruction is responsible for the observed benefits.
- [§3] §3 (Method): The Cue-Tag-Content graph construction, tag generation procedure, and update rules are not specified in sufficient detail to assess the weakest assumption that associative tags can be maintained as low-error semantic bridges. Without an explicit algorithm or cost model for tag creation and maintenance, it is unclear whether the claimed efficiency gains survive the overhead of graph operations.
- [§3.2] §3.2 (Active Reconstruction): The pruning mechanism is described as using 'intermediate LLM evidence' to avoid combinatorial explosion, yet no formal condition, threshold, or termination criterion is given. This leaves open the possibility that the mechanism either omits relevant paths or fails to prune, directly undermining both accuracy and runtime claims.
minor comments (2)
- [§3.1] Notation for the Cue-Tag-Content graph (e.g., how edges are typed and how tags are represented) is introduced without a formal definition or example instance, making the subsequent algorithmic description harder to follow.
- [Abstract] The abstract states results on 'LoCoMo benchmark and LongMemEval benchmark' but does not indicate whether these are standard public benchmarks or newly introduced; a citation or brief description would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The headline claim of 'significant improvements over strong baselines (up to 23%)' and 'substantially reducing token and runtime cost' is presented without any description of the baselines used, statistical tests performed, error bars, dataset splits, or ablation studies. This absence makes it impossible to evaluate whether the reported gains support the central claim that active reconstruction is responsible for the observed benefits.
Authors: We agree that the presentation of results requires greater transparency. In the revised manuscript we will expand both the abstract and §4 to name every baseline, report error bars across multiple runs, specify dataset splits, include statistical significance tests, and add ablation studies that isolate the contribution of active reconstruction from the graph structure alone. revision: yes
-
Referee: [§3] §3 (Method): The Cue-Tag-Content graph construction, tag generation procedure, and update rules are not specified in sufficient detail to assess the weakest assumption that associative tags can be maintained as low-error semantic bridges. Without an explicit algorithm or cost model for tag creation and maintenance, it is unclear whether the claimed efficiency gains survive the overhead of graph operations.
Authors: We will revise §3 to include an explicit algorithm (presented as pseudocode) for graph construction, tag generation, and update rules, together with a cost model that quantifies the overhead of tag maintenance relative to the observed token and runtime savings. revision: yes
-
Referee: [§3.2] §3.2 (Active Reconstruction): The pruning mechanism is described as using 'intermediate LLM evidence' to avoid combinatorial explosion, yet no formal condition, threshold, or termination criterion is given. This leaves open the possibility that the mechanism either omits relevant paths or fails to prune, directly undermining both accuracy and runtime claims.
Authors: We accept that a more formal specification is needed. The revised §3.2 will define explicit pruning conditions, evidence thresholds, and termination criteria that govern path exploration and pruning, thereby clarifying how the mechanism balances completeness and efficiency. revision: yes
Circularity Check
No circularity: framework proposal evaluated on external benchmarks with no fitted predictions or self-referential derivations.
full rationale
The paper introduces MRAgent as a new Cue-Tag-Content graph plus active reconstruction mechanism, then reports empirical gains on the independent LoCoMo and LongMemEval benchmarks. No equations, fitted parameters, or predictions appear that reduce by construction to the inputs; the central claims rest on the external benchmark results rather than any self-definition or self-citation chain. The absence of any load-bearing mathematical derivation makes circularity analysis inapplicable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Current memory-augmented agents rely on a static retrieve-then-reason paradigm that prevents dynamic adaptation.
invented entities (1)
-
Cue-Tag-Content graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nature Neuroscience , volume =
The neurobiological foundation of memory retrieval , author =. Nature Neuroscience , volume =
-
[2]
Neuroscience & Biobehavioral Reviews , volume =
The cognitive neuroscience of memory representation , author =. Neuroscience & Biobehavioral Reviews , volume =
-
[3]
Neuron , year =
Key--value memory in the brain , author =. Neuron , year =
-
[4]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , booktitle =
Di Wu and Hongwei Wang and Wenhao Yu and Yuwei Zhang and Kai. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , booktitle =. 2025 , url =
2025
-
[10]
Proceedings of the AAAI Symposium Series , volume=
Memory matters: The need to improve long-term memory in llm-agents , author=. Proceedings of the AAAI Symposium Series , volume=
-
[11]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
2020
-
[13]
Organization of memory , volume=
Episodic and semantic memory , author=. Organization of memory , volume=. 1972 , publisher=
1972
-
[14]
Current opinion in neurobiology , volume=
Brain networks underlying episodic memory retrieval , author=. Current opinion in neurobiology , volume=. 2013 , publisher=
2013
-
[18]
2025 , howpublished =
LangMem SDK for Agent Long-Term Memory , author =. 2025 , howpublished =
2025
-
[20]
Science , volume=
Competition between engrams influences fear memory formation and recall , author=. Science , volume=. 2016 , publisher=
2016
-
[21]
Neuron , volume=
Semantic memory and the human hippocampus , author=. Neuron , volume=. 2003 , publisher=
2003
-
[22]
A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to Artificial Super Intelligence , journal =
Huan. A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to Artificial Super Intelligence , journal =. 2026 , biburl =
2026
-
[23]
arXiv preprint arXiv:2510.13614 , year=
Memotime: Memory-augmented temporal knowledge graph enhanced large language model reasoning , author=. arXiv preprint arXiv:2510.13614 , year=
-
[24]
From Isolated Conversations to Hierarchical Schemas: Dynamic Tree Memory Representation for LLMs , author=
-
[25]
The Thirteenth International Conference on Learning Representations , year=
Secom: On memory construction and retrieval for personalized conversational agents , author=. The Thirteenth International Conference on Learning Representations , year=
-
[26]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[32]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[33]
M. J. Kearns , title =
-
[34]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[35]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[36]
Suppressed for Anonymity , author=
-
[37]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[38]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[39]
Arigraph: Learning knowledge graph world models with episodic memory for llm agents
Anokhin, P., Semenov, N., Sorokin, A., Evseev, D., Kravchenko, A., Burtsev, M., and Burnaev, E. Arigraph: Learning knowledge graph world models with episodic memory for llm agents. arXiv preprint arXiv:2407.04363, 2024
arXiv 2024
-
[40]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Chhikara, P., Khant, D., Aryan, S., Singh, T., and Yadav, D. Mem0: Building production-ready AI agents with scalable long-term memory. CoRR, abs/2504.19413, 2025. doi:10.48550/ARXIV.2504.19413. URL https://doi.org/10.48550/arXiv.2504.19413
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.19413 2025
-
[41]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Fang, J., Deng, X., Xu, H., Jiang, Z., Tang, Y., Xu, Z., Deng, S., Yao, Y., Wang, M., Qiao, S., Chen, H., and Zhang, N. Lightmem: Lightweight and efficient memory-augmented generation. CoRR, abs/2510.18866, 2025. doi:10.48550/ARXIV.2510.18866. URL https://doi.org/10.48550/arXiv.2510.18866
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.18866 2025
-
[42]
Frankland, P. W. and Josselyn, S. A. The neurobiological foundation of memory retrieval. Nature Neuroscience, 22 0 (10): 0 1576--1585, 2019
2019
-
[43]
A survey of self-evolving agents: What, when, how, and where to evolve on the path to artificial super intelligence
Gao, H., Geng, J., Hua, W., Hu, M., Juan, X., Liu, H., Liu, S., Qiu, J., Qi, X., Ren, Q., Wu, Y., Wang, H., Xiao, H., Zhou, Y., Zhang, S., Zhang, J., Xiang, J., Fang, Y., Zhao, Q., Liu, D., Qian, C., Wang, Z., Hu, M., Wang, H., Wu, Q., Ji, H., and Wang, M. A survey of self-evolving agents: What, when, how, and where to evolve on the path to artificial sup...
2026
-
[44]
Retrieval-Augmented Generation with Graphs (GraphRAG)
Han, H., Wang, Y., Shomer, H., Guo, K., Ding, J., Lei, Y., Halappanavar, M., Rossi, R. A., Mukherjee, S., Tang, X., He, Q., Hua, Z., Long, B., Zhao, T., Shah, N., Javari, A., Xia, Y., and Tang, J. Retrieval-augmented generation with graphs (graphrag). CoRR, abs/2501.00309, 2025. doi:10.48550/ARXIV.2501.00309. URL https://doi.org/10.48550/arXiv.2501.00309
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.00309 2025
-
[45]
Memory matters: The need to improve long-term memory in llm-agents
Hatalis, K., Christou, D., Myers, J., Jones, S., Lambert, K., Amos-Binks, A., Dannenhauer, Z., and Dannenhauer, D. Memory matters: The need to improve long-term memory in llm-agents. In Proceedings of the AAAI Symposium Series, volume 2, pp.\ 277--280, 2023
2023
-
[46]
A definition of agi.arXiv preprint arXiv:2510.18212, 2025
Hendrycks, D., Song, D., Szegedy, C., Lee, H., Gal, Y., Brynjolfsson, E., Li, S., Zou, A., Levine, L., Han, B., Fu, J., Liu, Z., Shin, J., Lee, K., Mazeika, M., Phan, L., Ingebretsen, G., Khoja, A., Xie, C., Salaudeen, O., Hein, M., Zhao, K., Pan, A., Duvenaud, D., Li, B., Omohundro, S., Alfour, G., Tegmark, M., McGrew, K., Marcus, G., Tallinn, J., Schmid...
-
[47]
Memory in the age of ai agents
Hu, Y., Liu, S., Yue, Y., Zhang, G., Liu, B., Zhu, F., Lin, J., Guo, H., Dou, S., Xi, Z., et al. Memory in the age of ai agents. arXiv preprint arXiv:2512.13564, 2025
Pith/arXiv arXiv 2025
-
[48]
Licomemory: Lightweight and cognitive agentic memory for efficient long-term reasoning
Huang, Z., Tian, Z., Guo, Q., Zhang, F., Zhou, Y., Jiang, D., and Zhou, X. Licomemory: Lightweight and cognitive agentic memory for efficient long-term reasoning. CoRR, abs/2511.01448, 2025. doi:10.48550/ARXIV.2511.01448. URL https://doi.org/10.48550/arXiv.2511.01448
-
[49]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Jin, B., Zeng, H., Yue, Z., Wang, D., Zamani, H., and Han, J. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. CoRR, abs/2503.09516, 2025. doi:10.48550/ARXIV.2503.09516. URL https://doi.org/10.48550/arXiv.2503.09516
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.09516 2025
-
[50]
URLhttps://arxiv.org/abs/2506.06326
Kang, J., Ji, M., Zhao, Z., and Bai, T. Memory OS of AI agent. CoRR, abs/2506.06326, 2025. doi:10.48550/ARXIV.2506.06326. URL https://doi.org/10.48550/arXiv.2506.06326
-
[51]
Langmem sdk for agent long-term memory
LangChain . Langmem sdk for agent long-term memory. https://blog.langchain.com/langmem-sdk-launch/, 2025. Accessed: 2025-01
2025
-
[52]
u ttler, H., Lewis, M., Yih, W., Rockt \
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., K \" u ttler, H., Lewis, M., Yih, W., Rockt \" a schel, T., Riedel, S., and Kiela, D. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems 33: A...
2020
-
[53]
Li, X., Dong, G., Jin, J., Zhang, Y., Zhou, Y., Zhu, Y., Zhang, P., and Dou, Z. Search-o1: Agentic search-enhanced large reasoning models. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V. (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025 , pp.\ 54...
-
[54]
URLhttps://aclanthology.org/2024.acl-long.747/
Maharana, A., Lee, D., Tulyakov, S., Bansal, M., Barbieri, F., and Fang, Y. Evaluating very long-term conversational memory of LLM agents. In Ku, L., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024 , pp.\ 1...
-
[55]
R., Hopkins, R
Manns, J. R., Hopkins, R. O., and Squire, L. R. Semantic memory and the human hippocampus. Neuron, 38 0 (1): 0 127--133, 2003
2003
-
[56]
V., Qiu, L., et al
Pan, Z., Wu, Q., Jiang, H., Luo, X., Cheng, H., Li, D., Yang, Y., Lin, C.-Y., Zhao, H. V., Qiu, L., et al. Secom: On memory construction and retrieval for personalized conversational agents. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[57]
J., Yan, C., Mercaldo, V., Hsiang, H.-L., Park, S., Cole, C
Rashid, A. J., Yan, C., Mercaldo, V., Hsiang, H.-L., Park, S., Cole, C. J., De Cristofaro, A., Yu, J., Ramakrishnan, C., Lee, S. Y., et al. Competition between engrams influences fear memory formation and recall. Science, 353 0 (6297): 0 383--387, 2016
2016
-
[58]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Rasmussen, P., Paliychuk, P., Beauvais, T., Ryan, J., and Chalef, D. Zep: A temporal knowledge graph architecture for agent memory. CoRR, abs/2501.13956, 2025. doi:10.48550/ARXIV.2501.13956. URL https://doi.org/10.48550/arXiv.2501.13956
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.13956 2025
-
[59]
Rugg, M. D. and Renoult, L. The cognitive neuroscience of memory representation. Neuroscience & Biobehavioral Reviews, 155: 0 105450, 2025
2025
-
[60]
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents
Tan, Z., Yan, J., Hsu, I.-H., Han, R., Wang, Z., Le, L., Song, Y., Chen, Y., Palangi, H., Lee, G., et al. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 8416--8439, 2025
2025
-
[61]
Longmemeval: Benchmarking chat assistants on long-term interactive memory
Wu, D., Wang, H., Yu, W., Zhang, Y., Chang, K., and Yu, D. Longmemeval: Benchmarking chat assistants on long-term interactive memory. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=pZiyCaVuti
2025
-
[62]
A-MEM: Agentic Memory for LLM Agents
Xu, W., Liang, Z., Mei, K., Gao, H., Tan, J., and Zhang, Y. A-MEM: agentic memory for LLM agents. CoRR, abs/2502.12110, 2025. doi:10.48550/ARXIV.2502.12110. URL https://doi.org/10.48550/arXiv.2502.12110
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.12110 2025
-
[63]
URL https://ojs.aaai.org/index.php/AAAI/article/view/29946
Zhong, W., Guo, L., Gao, Q., Ye, H., and Wang, Y. Memorybank: Enhancing large language models with long-term memory. In Wooldridge, M. J., Dy, J. G., and Natarajan, S. (eds.), Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.