TLA-Prover: Verifiable TLA+ Specification Synthesis via Preference-Optimized Low-Rank Adaptation
Pith reviewed 2026-06-28 00:19 UTC · model grok-4.3
The pith
TLA-Prover trains a 20B model on verified TLA+ examples and uses direct TLC feedback in GRPO to reach 30% semantic pass rate on held-out problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
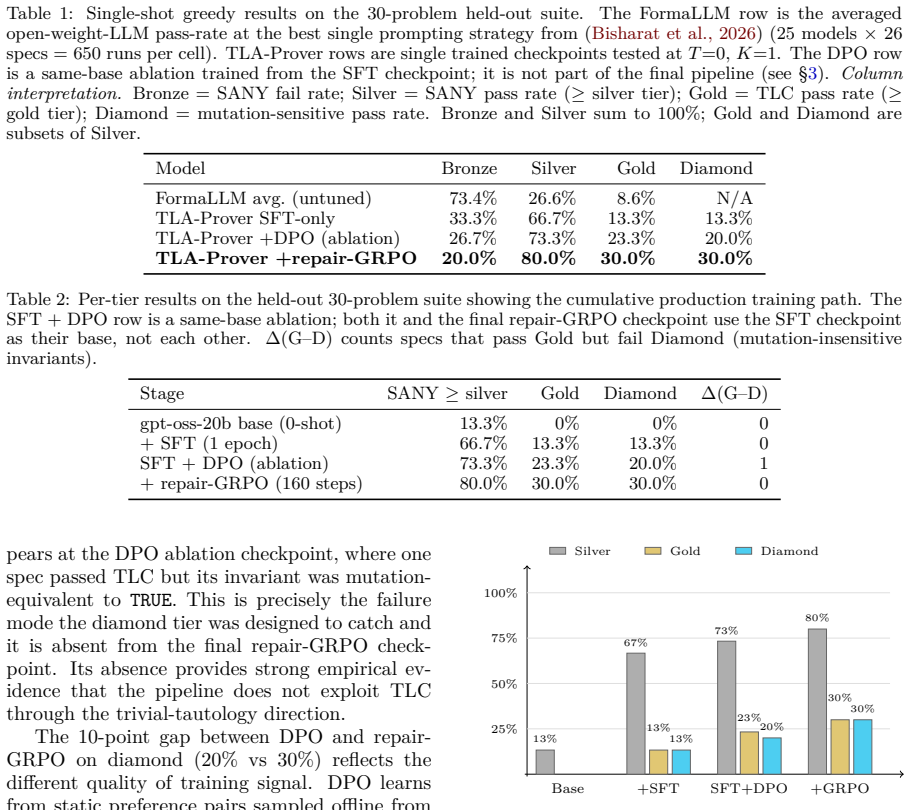
TLA-Prover is a 20-billion-parameter model trained first by supervised fine-tuning on verified TLA+ specifications and then by repair-based group-relative policy optimization. In the optimization stage the model receives direct rewards from the TLC model checker across Bronze, Silver, Gold, and Diamond tiers; Gold requires the specification to pass TLC while Diamond further requires that an automatically altered correctness property still produces a detectable violation. The resulting model achieves 9 out of 30 correct specifications at both Gold and Diamond on a held-out benchmark, compared with an 8.6% baseline, and the DPO ablation reaches 20% at Diamond.
What carries the argument
Group-relative policy optimization (GRPO) that uses the TLC model checker directly as the reward signal after supervised fine-tuning on verified TLA+ examples.
If this is right
- The trained model generates TLA+ specifications that pass TLC at 30% without further human repair.
- Gold and Diamond scores match at every checkpoint, showing the method avoids generating trivially true properties.
- A DPO variant trained from the same starting checkpoint reaches 20% at the Diamond tier.
- No separate learned reward model is required because TLC itself supplies the preference signal.
Where Pith is reading between the lines
- The same direct-verifier preference loop could be applied to other formal languages that possess an automatic checker.
- Increasing the number of repair iterations inside GRPO might raise the pass rate further on the same benchmark.
- The Diamond tier's property alteration offers a general template for testing that a generated artifact is not vacuously correct.
Load-bearing premise
The 30-problem held-out benchmark together with the automatic property-alteration step measures genuine specification quality that holds outside the training distribution.
What would settle it
Running the trained model on a new collection of 100 TLA+ problems drawn from published protocols and obtaining fewer than 15% Gold passes would falsify the reported generalization.
Figures

read the original abstract
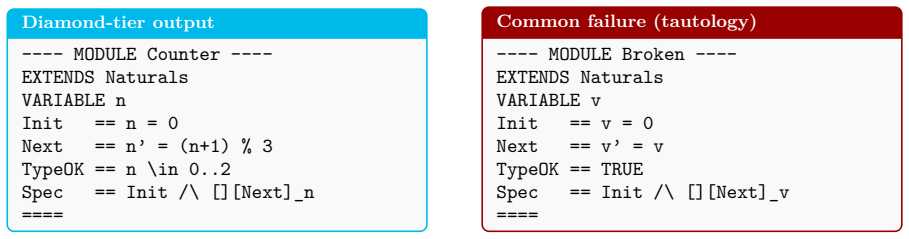
TLA+ is a formal specification language for verifying distributed systems and safety-critical protocols. Large language models (LLMs) frequently produce TLA+ specifications that fail the TLC model checker for semantic reasons. Across 25 LLMs, the best public baseline is 26.6% syntactic parse and 8.6% semantic model-check. We present TLA-Prover, a 20-billion-parameter model for TLA+ specification synthesis. Training combines supervised fine-tuning (SFT) on verified examples with repair-based group-relative policy optimization (GRPO). In the GRPO stage, the model learns to fix its own rejected specifications. We also train a direct preference optimization (DPO) variant from the same SFT checkpoint as an ablation. TLC provides the reward signal directly, with no learned reward model. Four tiers grade each output: Bronze (parses), Silver (no warnings), Gold (passes TLC), and Diamond. To reach Diamond, the model's correctness property is automatically altered in a small way; TLC must then detect a violation. If TLC still passes, the property was always-true and contributes nothing; the output fails Diamond. TLA-Prover reaches 9/30 (i.e. pass@1 = 30%) at both Gold and Diamond on a held-out 30-problem benchmark. This is roughly 3.5x the 8.6% untuned baseline. The DPO variant reaches 20% at Diamond. Gold and Diamond coincide at every checkpoint; this prevents the trivial-property failure mode.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TLA-Prover, a 20B-parameter model for TLA+ specification synthesis. It trains via supervised fine-tuning on verified examples followed by group-relative policy optimization (GRPO) that uses the TLC model checker directly as the reward signal to repair rejected specifications (with a DPO ablation). Outputs are graded on four tiers (Bronze: parses; Silver: no warnings; Gold: passes TLC; Diamond: passes after automatic small alteration of the correctness property). On a held-out 30-problem benchmark the model reaches 9/30 (30% pass@1) on both Gold and Diamond, stated as 3.5× the 8.6% untuned baseline; Gold and Diamond scores coincide at every checkpoint.
Significance. If the headline numbers hold under a properly characterized benchmark, the work supplies concrete evidence that direct model-checker feedback in preference optimization can lift semantic correctness of LLM-generated TLA+ specs well above both untuned and SFT baselines. Because TLA+ is used for safety-critical distributed protocols, a reproducible 3×–4× gain on verifiable synthesis would be a meaningful incremental contribution to automated formal-methods tooling.
major comments (2)
- [held-out 30-problem benchmark evaluation] The central 9/30 (30%) Gold/Diamond result and the 3.5× claim rest on a fixed 30-problem held-out set whose construction, domain coverage, statistical diversity, and distance from the SFT/GRPO training distribution are not quantified. With an expected ~2.6 baseline successes, binomial variance is large; without these statistics it is impossible to rule out that the observed lift arises from a few problems that happen to lie close to the training distribution rather than from improved specification synthesis.
- [Diamond-tier construction] The automatic property-alteration procedure used to create the Diamond tier is described only at a high level. No concrete definition is given for what counts as a “small” change, how many properties are altered per specification, or how vacuous or always-true alterations are detected and handled; without these details the claim that Diamond “prevents the trivial-property failure mode” cannot be verified across the 30 problems.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in benchmark construction and Diamond-tier mechanics. We will revise the manuscript to address both points with additional details and analysis.
read point-by-point responses
-
Referee: [held-out 30-problem benchmark evaluation] The central 9/30 (30%) Gold/Diamond result and the 3.5× claim rest on a fixed 30-problem held-out set whose construction, domain coverage, statistical diversity, and distance from the SFT/GRPO training distribution are not quantified. With an expected ~2.6 baseline successes, binomial variance is large; without these statistics it is impossible to rule out that the observed lift arises from a few problems that happen to lie close to the training distribution rather than from improved specification synthesis.
Authors: We agree that the original submission lacked sufficient quantification of the held-out set. The 30 problems were selected from publicly documented TLA+ specifications of distributed protocols (consensus, leader election, mutual exclusion, etc.) drawn from academic papers and the TLA+ examples repository, with explicit exclusion of any examples used in SFT or GRPO training data. In revision we will add a dedicated subsection describing benchmark construction, listing the source references for each problem, tabulating domain coverage, and providing a qualitative diversity assessment. We will also report binomial confidence intervals around the pass@1 rates. While automated distributional-distance metrics (e.g., embedding cosine similarity) are not currently computed, we will state that manual inspection confirmed no training-set overlap and will include representative problem excerpts to allow readers to assess proximity. revision: yes
-
Referee: [Diamond-tier construction] The automatic property-alteration procedure used to create the Diamond tier is described only at a high level. No concrete definition is given for what counts as a “small” change, how many properties are altered per specification, or how vacuous or always-true alterations are detected and handled; without these details the claim that Diamond “prevents the trivial-property failure mode” cannot be verified across the 30 problems.
Authors: We accept that the description was insufficiently precise. In the revised manuscript we will replace the high-level paragraph with an explicit procedure: (1) locate the primary correctness property; (2) apply at most one alteration—either negation of a single top-level conjunct or ±1 modification to a numeric constant appearing in the property; (3) re-run TLC on the altered specification; (4) if TLC reports no violation within the same bounds used for Gold, the output fails Diamond (vacuous case). We will also supply pseudocode for the alteration routine and confirm that this rule was applied uniformly to all 30 benchmark problems, allowing independent verification. revision: yes
Circularity Check
No circularity: performance claims rest on external TLC verification of held-out benchmark
full rationale
The paper's central result (9/30 pass@1 on Gold/Diamond tiers) is obtained by running the trained model on a held-out 30-problem set and scoring outputs with the external TLC model checker; the reward signal during GRPO is likewise supplied directly by TLC rather than any learned or self-referential quantity. No equation, training objective, or benchmark construction reduces by definition to a fitted parameter or prior self-citation. The DPO ablation and the observation that Gold/Diamond coincide are likewise measured against the same external checker. The derivation chain is therefore self-contained against an independent oracle.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The TLC model checker returns correct semantic verdicts for TLA+ specifications
- domain assumption The held-out 30-problem set and the Diamond-tier perturbation procedure measure non-trivial generalization
Reference graph
Works this paper leans on
-
[1]
Specifying Systems: The
Lamport, Leslie , year=. Specifying Systems: The
-
[2]
Model checking
Yu, Yuan and Manolios, Panagiotis and Lamport, Leslie , booktitle=. Model checking. 1999 , publisher=
1999
-
[3]
2025 , howpublished=
2025
-
[4]
Xin, Huajian and Guo, Daya and Shao, Zhihong and Ren, Zhizhou and Zhu, Qihao and Liu, Bo and Ruan, Chong and Li, Wenda and Liang, Xiaodan , journal=
-
[5]
Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE) , pages=
Baldur: Whole-proof generation and repair with large language models , author=. Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE) , pages=
-
[6]
Advances in Neural Information Processing Systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, YK and Wu, Y and others , journal=
-
[8]
and others , booktitle=
Bisharat, Arslan and Laufer, Konstantin and Spencer, Eric and Thiruvathukal, George K. and others , booktitle=
-
[9]
Konnov, Igor and Kukovec, Jure and Tran, Thanh-Hai , title =. Proc. ACM Program. Lang. , month = oct, articleno =. 2019 , issue_date =. doi:10.1145/3360549 , abstract =
-
[10]
Advances in Neural Information Processing Systems , volume=
Defining and characterizing reward hacking , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Proceedings of the 40th International Conference on Machine Learning , pages =
Gao, Leo and Schulman, John and Hilton, Jacob , title =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , publisher =
2023
-
[12]
Automated Deduction -- CADE 28 , series =
Moura, Leonardo de and Ullrich, Sebastian , title =. Automated Deduction – CADE 28: 28th International Conference on Automated Deduction, Virtual Event, July 12–15, 2021, Proceedings , pages =. 2021 , isbn =. doi:10.1007/978-3-030-79876-5_37 , abstract =
-
[13]
Logic and Computer Science , editor=
Isabelle: The Next 700 Theorem Provers , author=. Logic and Computer Science , editor=. 1990 , url=
1990
-
[14]
Communications of the ACM , volume =
Newcombe, Chris and Rath, Tim and Zhang, Fan and Munteanu, Bogdan and Brooker, Marc and Deardeuff, Michael , title =. Communications of the ACM , volume =. 2015 , publisher =
2015
-
[15]
and Loillier, Benjamin and Merz, Stephan , title =
Cirstea, Horatiu and Kuppe, Markus A. and Loillier, Benjamin and Merz, Stephan , title =. Software Engineering and Formal Methods (SEFM 2024) , series =. 2024 , doi =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.