Ouvia: A User-centered Framework for Measuring Usability of Speech Translation in Real-World Communication Scenarios
Pith reviewed 2026-06-28 01:08 UTC · model grok-4.3
The pith
A user study finds speech translation usable in only about half of real one-to-one interactions, with large gaps by demographic group and QA metrics as stronger predictors than standard scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
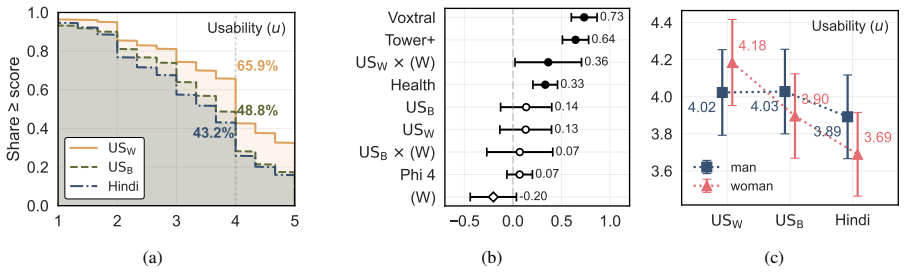
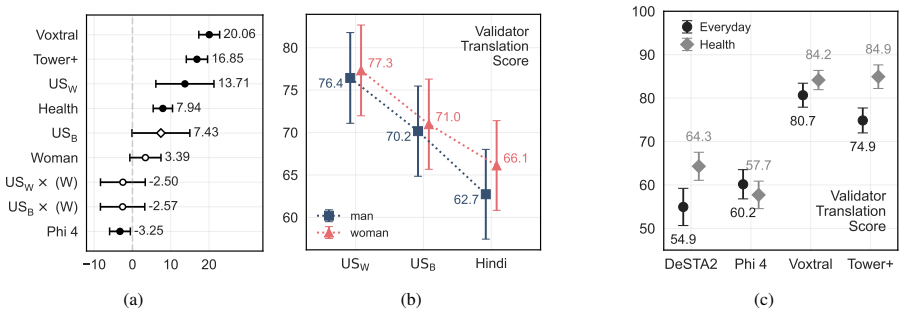
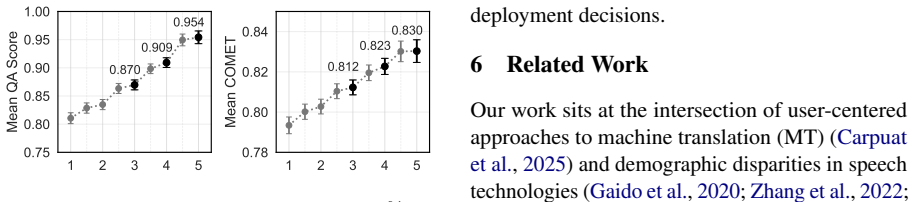
Ouvia measures user-perceived usability of speech translation by placing English speakers and Portuguese speakers in one-to-one request-conveying tasks that mimic real healthcare and daily situations. Data from over 1750 mediated interactions across four systems show modern speech translation produces usable results in only around half of cases, with substantial reported differences by English dialect and gender. Among available quality metrics, question-answering evaluation predicts these usability ratings substantially better than standard approaches.
What carries the argument
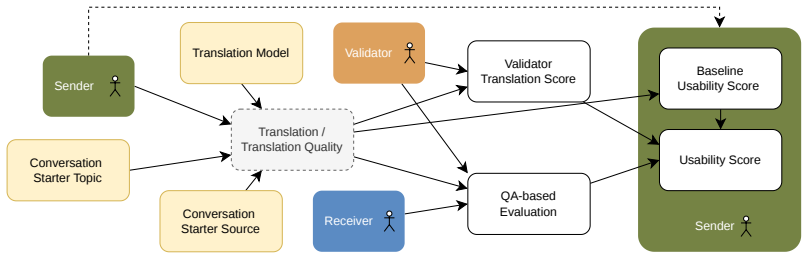
Ouvia, a framework that gathers usability ratings from situated one-to-one communication tasks run inside a custom web app.
If this is right
- Only around half of speech translation interactions receive usable ratings in realistic settings.
- Usability ratings differ significantly across demographic groups including English dialects and genders.
- QA-based evaluation predicts real-world usability ratings substantially better than standard quality metrics.
- Evaluation of speech translation benefits from moving beyond decontextualized test sets to user-centered, situated designs.
Where Pith is reading between the lines
- The approach could be applied to additional language pairs to test whether similar usability ceilings appear.
- Demographic gaps may trace to uneven performance on particular dialects or speaker characteristics in current models.
- Developers might adopt QA-style checks during system tuning to improve alignment with actual user experience.
Load-bearing premise
The custom web app and multi-phase study design with healthcare and everyday interactions accurately reflect real-world communication needs and user-perceived usability for the tested systems.
What would settle it
A follow-up study that uses different real-world scenarios or in-person interactions and reports usability rates well above or below 50 percent, or no demographic differences, would challenge the central findings.
Figures






read the original abstract
Speech translation (ST) is increasingly adopted in user applications, yet its evaluation largely focuses on decontextualized testbeds and holistic quality, rather than end users' communication needs. We introduce Ouvia, an evaluation framework for measuring user-perceived usability of speech translation outputs in real-world settings. Ouvia focuses on one-to-one communication: an English speaker needs to convey a request to a Portuguese speaker, and the message is automatically translated. Through a custom web app and multi-phase study design, we collect more than 1,750 such interactions in healthcare and everyday situations, mediated by four ST systems, involving speakers from three English dialects and two genders. We find that modern ST serves people only to a limited extent -- only around half of interactions are rated as usable -- with significant gaps in reported usability across demographic groups. Moreover, among quality metrics, we find that QA-based evaluation is a substantially stronger predictor of real-world usability than standard approaches. Together, these findings stress the importance of situated, user-centered evaluation frameworks that go beyond holistic quality scores and attend to who the technology serves -- and how well.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ouvia, a user-centered evaluation framework for measuring the usability of speech translation (ST) outputs in real-world one-to-one communication scenarios (English speaker conveying requests to a Portuguese speaker). It describes a custom web app and multi-phase study collecting over 1,750 interactions across healthcare and everyday situations using four ST systems, with participants from three English dialects and two genders. Key claims are that modern ST is usable in only around half of interactions, with significant demographic gaps in usability ratings, and that QA-based metrics substantially outperform standard quality metrics as predictors of real-world usability.
Significance. If the empirical results hold after detailed validation, the work would provide concrete evidence that current ST systems have limited practical utility and that evaluation must move beyond decontextualized holistic scores to situated, user-centered measures that account for demographic factors. This could shift research priorities in speech translation and human-AI communication toward more ecologically valid testing protocols.
major comments (2)
- [§3] §3 (Study Design): The central claim that the custom web app and multi-phase protocol accurately capture real-world usability rests on an untested assumption that simulated healthcare/everyday interactions via the app generalize to natural face-to-face or device-mediated communication; without a validation study or comparison to field data, this undermines the external validity of the 50% usability rate and demographic-gap findings.
- [§4] §4 (Results): The assertion that QA-based evaluation is a 'substantially stronger predictor' of usability requires the specific correlation coefficients, regression models, and baseline comparisons (e.g., vs. BLEU, COMET) to be reported with confidence intervals and cross-validation details; the abstract alone does not allow assessment of whether this superiority is robust or driven by particular operationalizations of 'usable'.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from an explicit operational definition of 'usable' (e.g., rating threshold or binary criterion) to allow readers to interpret the 'around half' figure.
- [§4] Table or figure presenting the exact distribution of usability ratings across the four ST systems and demographic strata should be added for transparency.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and describe planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: §3 (Study Design): The central claim that the custom web app and multi-phase protocol accurately capture real-world usability rests on an untested assumption that simulated healthcare/everyday interactions via the app generalize to natural face-to-face or device-mediated communication; without a validation study or comparison to field data, this undermines the external validity of the 50% usability rate and demographic-gap findings.
Authors: We acknowledge that the study relies on a simulated web-app environment rather than direct field observations. This design enables ethical, large-scale data collection (1,750+ interactions) with controlled variables across demographics and scenarios. We agree this introduces an assumption about generalizability. In revision we will expand the limitations section to explicitly discuss the simulation's scope and implications for the reported usability rates and demographic differences. revision: partial
-
Referee: §4 (Results): The assertion that QA-based evaluation is a 'substantially stronger predictor' of usability requires the specific correlation coefficients, regression models, and baseline comparisons (e.g., vs. BLEU, COMET) to be reported with confidence intervals and cross-validation details; the abstract alone does not allow assessment of whether this superiority is robust or driven by particular operationalizations of 'usable'.
Authors: We agree that detailed statistical reporting is required for evaluation of the claim. The manuscript body contains the relevant analyses, but we will revise to present explicit correlation coefficients, regression models, confidence intervals, and cross-validation results in a dedicated table or subsection, ensuring readers can fully assess the comparison to BLEU, COMET, and other baselines. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical user study collecting 1750+ real-world interactions via a custom web app across healthcare and everyday scenarios, with usability ratings provided directly by participants. Central claims (approximately 50% usability rate, demographic gaps, and QA metrics outperforming standard ones) rest on observed data and statistical comparisons rather than any derivation, equation, fitted parameter renamed as prediction, or self-citation chain. No mathematical model, ansatz, uniqueness theorem, or self-referential definition appears in the provided text; the evaluation framework is defined by the study protocol itself and is externally falsifiable through replication of the user ratings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, and 1 others. 2025. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras. arXiv preprint arXiv:2503.01743
Pith/arXiv arXiv 2025
-
[2]
AIMA . 2025. https://aima.gov.pt/media/pages/documents/fec4d6a712-1760603125/relatorio-migracoes-e-asilo-2024.pdf Relatório de migrações e asilo 2024 . Technical report, Agência para a Integração, Migrações e Asilo (AIMA I.P.), Lisboa. Edição Digital. Coordenação: Sílvia Lopes
2025
-
[3]
Giuseppe Attanasio, Beatrice Savoldi, Dennis Fucci, and Dirk Hovy. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1188 Twists, humps, and pebbles: Multilingual speech recognition models exhibit gender performance gaps . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21318--21340, Miami, Florida, USA. As...
-
[4]
Jeffrey Basoah, Daniel Chechelnitsky, Tao Long, Katharina Reinecke, Chrysoula Zerva, Kaitlyn Zhou, Mark D \' az, and Maarten Sap. 2025. Not like us, hunty: Measuring perceptions and behavioral effects of minoritized anthropomorphic cues in llms. In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pages 710--745
2025
-
[5]
Anol Bhattacherjee. 2001. Understanding information systems continuance: An expectation-confirmation model1. MIS quarterly, 25(3):351--370
2001
-
[6]
Marc Brysbaert. 2019. How many participants do we have to include in properly powered experiments? a tutorial of power analysis with reference tables. Journal of cognition, 2(1):16
2019
-
[7]
Marine Carpuat, Omri Asscher, Kalika Bali, Luisa Bentivogli, Fr \'e d \'e ric Blain, Lynne Bowker, Monojit Choudhury, Hal Daum \'e III, Kevin Duh, Ge Gao, Alvin Grissom II, Marzena Karpinska, Elaine C. Khoong, William D. Lewis, Andr \'e F. T. Martins, Mary Nurminen, Douglas W. Oard, Maja Popovic, Michel Simard, and Fran c ois Yvon. 2025. https://doi.org/1...
-
[8]
Gary Charness, Uri Gneezy, and Michael A Kuhn. 2012. Experimental methods: Between-subject and within-subject design. Journal of economic behavior & organization, 81(1):1--8
2012
-
[9]
Sonia Colina. 2009. Further evidence for a functionalist approach to translation quality evaluation. Target. International Journal of Translation Studies, 21(2):235--264
2009
-
[10]
M. Amin Farajian, Ant \'o nio V. Lopes, Andr \'e F. T. Martins, Sameen Maruf, and Gholamreza Haffari. 2020. https://doi.org/10.18653/v1/2020.wmt-1.3 Findings of the WMT 2020 shared task on chat translation . In Proceedings of the Fifth Conference on Machine Translation, pages 65--75, Online. Association for Computational Linguistics
-
[11]
Faiha Fareez, Tishya Parikh, Christopher Wavell, Saba Shahab, Meghan Chevalier, Scott Good, Isabella De Blasi, Rafik Rhouma, Christopher McMahon, Jean-Paul Lam, and 1 others. 2022. A dataset of simulated patient-physician medical interviews with a focus on respiratory cases. Scientific Data, 9(1):313
2022
-
[12]
Patrick Fernandes, Sweta Agrawal, Emmanouil Zaranis, Andr \'e FT Martins, and Graham Neubig. 2025. Do llms understand your translations? evaluating paragraph-level mt with question answering. arXiv preprint arXiv:2504.07583
arXiv 2025
-
[13]
Dennis Fucci, Marco Gaido, Matteo Negri, Luisa Bentivogli, Andre Martins, and Giuseppe Attanasio. 2025. https://doi.org/10.18653/v1/2025.acl-short.78 Different speech translation models encode and translate speaker gender differently . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), page...
-
[14]
Susanne Fuchs and Martine Toda. 2010. Do differences in male versus female/s/reflect biological or sociophonetic factors . Turbulent sounds: An interdisciplinary guide, 21:281--302
2010
-
[15]
Marco Gaido, Beatrice Savoldi, Luisa Bentivogli, Matteo Negri, and Marco Turchi. 2020. https://doi.org/10.18653/v1/2020.coling-main.350 Breeding gender-aware direct speech translation systems . In Proceedings of the 28th International Conference on Computational Linguistics, pages 3951--3964, Barcelona, Spain (Online). International Committee on Computati...
-
[16]
Ariana Genovese, Sahar Borna, Cesar A Gomez-Cabello, Syed Ali Haider, Srinivasagam Prabha, Antonio J Forte, and Benjamin R Veenstra. 2024. Artificial intelligence in clinical settings: a systematic review of its role in language translation and interpretation. Annals of Translational Medicine, 12(6):117
2024
-
[17]
Yvette Graham, Timothy Baldwin, Alistair Moffat, and Justin Zobel. 2013. https://aclanthology.org/W13-2305/ Continuous measurement scales in human evaluation of machine translation . In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, pages 33--41, Sofia, Bulgaria. Association for Computational Linguistics
2013
-
[18]
and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr \'e F
Nuno M. Guerreiro, Ricardo Rei, Daan van Stigt, Luisa Coheur, Pierre Colombo, and Andr \'e F. T. Martins. 2024. https://doi.org/10.1162/tacl_a_00683 x COMET : Transparent machine translation evaluation through fine-grained error detection . Transactions of the Association for Computational Linguistics, 12:979--995
-
[19]
HyoJung Han, Kevin Duh, and Marine Carpuat. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1218 S peech QE : Estimating the quality of direct speech translation . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21852--21867, Miami, Florida, USA. Association for Computational Linguistics
-
[20]
Camille Harris, Chijioke Mgbahurike, Neha Kumar, and Diyi Yang. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.890 Modeling gender and dialect bias in automatic speech recognition . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 15166--15184, Miami, Florida, USA. Association for Computational Linguistics
-
[21]
Robert R. Hoffman, Shane T. Mueller, Gary Klein, and Jordan Litman. 2023. https://doi.org/10.3389/fcomp.2023.1096257 Measures for explainable ai: Explanation goodness, user satisfaction, mental models, curiosity, trust, and human-ai performance . Frontiers in Computer Science, Volume 5 - 2023
-
[22]
Eduard Hovy, Margaret King, and Andrei Popescu-Belis. 2002. Principles of context-based machine translation evaluation. Machine Translation, 17(1):43--75
2002
-
[23]
John Hutchins. 2005. Current commercial machine translation systems and computer-based translation tools: system types and their uses. International journal of translation, 17(1-2):5--38
2005
-
[24]
ISO . 2018. https://www.iso.org/obp/ui/en/#iso:std:iso:9241:-11:ed-2:v1:en ISO 9241-11:2018 --- ergonomics of human-system interaction---part 11: Usability: Definitions and concepts . Standard, International Organization for Standardization
2018
-
[25]
Eshin Jolly. 2018. Pymer4: Connecting r and python for linear mixed modeling. Journal of Open Source Software, 3(31):862
2018
-
[26]
Juraj Juraska, Daniel Deutsch, Mara Finkelstein, and Markus Freitag. 2024. https://doi.org/10.18653/v1/2024.wmt-1.35 M etric X -24: The G oogle submission to the WMT 2024 metrics shared task . In Proceedings of the Ninth Conference on Machine Translation, pages 492--504, Miami, Florida, USA. Association for Computational Linguistics
-
[27]
Juraj Juraska, Tobias Domhan, Mara Finkelstein, Tetsuji Nakagawa, Geza Kovacs, Daniel Deutsch, Pidong Wang, and Markus Freitag. 2025. https://doi.org/10.18653/v1/2025.wmt-1.70 M etric X -25 and G em S pan E val: G oogle T ranslate submissions to the WMT 25 evaluation shared task . In Proceedings of the Tenth Conference on Machine Translation, pages 957--9...
-
[28]
Elaine C Khoong, Eric Steinbrook, Cortlyn Brown, and Alicia Fernandez. 2019. Assessing the use of google translate for spanish and chinese translations of emergency department discharge instructions. JAMA internal medicine, 179(4):580--582
2019
-
[29]
Dayeon Ki, Kevin Duh, and Marine Carpuat. 2025 a . https://doi.org/10.18653/v1/2025.findings-acl.899 A sk QE : Question answering as automatic evaluation for machine translation . In Findings of the Association for Computational Linguistics: ACL 2025, pages 17478--17515, Vienna, Austria. Association for Computational Linguistics
-
[30]
Dayeon Ki, Kevin Duh, and Marine Carpuat. 2025 b . https://doi.org/10.18653/v1/2025.emnlp-main.606 Should I share this translation? evaluating quality feedback for user reliance on machine translation . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12069--12092, Suzhou, China. Association for Computationa...
-
[31]
Tom Kocmi, Ekaterina Artemova, Eleftherios Avramidis, Rachel Bawden, Ond r ej Bojar, Konstantin Dranch, Anton Dvorkovich, Sergey Dukanov, Mark Fishel, Markus Freitag, Thamme Gowda, Roman Grundkiewicz, Barry Haddow, Marzena Karpinska, Philipp Koehn, Howard Lakougna, Jessica Lundin, Christof Monz, Kenton Murray, and 10 others. 2025. https://doi.org/10.18653...
-
[32]
Tom Kocmi, Rachel Bawden, Ond r ej Bojar, Anton Dvorkovich, Christian Federmann, Mark Fishel, Thamme Gowda, Yvette Graham, Roman Grundkiewicz, Barry Haddow, Rebecca Knowles, Philipp Koehn, Christof Monz, Makoto Morishita, Masaaki Nagata, Toshiaki Nakazawa, Michal Nov \'a k, Martin Popel, and Maja Popovi \'c . 2022. https://doi.org/10.18653/v1/2022.wmt-1.1...
-
[33]
Proceedings of the National Academy of Sciences , author =
Allison Koenecke, Andrew Nam, Emily Lake, Joe Nudell, Minnie Quartey, Zion Mengesha, Connor Toups, John R. Rickford, Dan Jurafsky, and Sharad Goel. 2020. https://doi.org/10.1073/pnas.1915768117 Racial disparities in automated speech recognition . Proceedings of the National Academy of Sciences, 117(14):7684--7689
-
[34]
Beomseok Lee, Marco Gaido, Ioan Calapodescu, Laurent Besacier, and Matteo Negri. 2025. https://aclanthology.org/2025.coling-main.455/ Speech foundation models and crowdsourcing for efficient, high-quality data collection . In Proceedings of the 31st International Conference on Computational Linguistics, pages 6816--6826, Abu Dhabi, UAE. Association for Co...
2025
-
[35]
Daniel Liebling, Katherine Heller, Samantha Robertson, and Wesley Deng. 2022. https://doi.org/10.18653/v1/2022.findings-naacl.17 Opportunities for human-centered evaluation of machine translation systems . In Findings of the Association for Computational Linguistics: NAACL 2022, pages 229--240, Seattle, United States. Association for Computational Linguistics
-
[36]
Alexander H Liu, Andy Ehrenberg, Andy Lo, Cl \'e ment Denoix, Corentin Barreau, Guillaume Lample, Jean-Malo Delignon, Khyathi Raghavi Chandu, Patrick von Platen, Pavankumar Reddy Muddireddy, and 1 others. 2025. Voxtral. arXiv preprint arXiv:2507.13264
arXiv 2025
-
[37]
Ting Liu, Chi-kiu Lo, Elizabeth Marshman, and Rebecca Knowles. 2024. https://aclanthology.org/2024.amta-research.17/ Evaluation briefs: Drawing on translation studies for human evaluation of MT . In Proceedings of the 16th Conference of the Association for Machine Translation in the Americas (Volume 1: Research Track), pages 190--208, Chicago, USA. Associ...
2024
-
[38]
Ke-Han Lu, Zhehuai Chen, Szu-Wei Fu, Chao-Han Huck Yang, Jagadeesh Balam, Boris Ginsburg, Yu-Chiang Frank Wang, and Hung-yi Lee. 2025. Developing instruction-following speech language model without speech instruction-tuning data. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1--5. IEEE
2025
-
[39]
McGrath, Oliver Lack, James Tisch, and Andreas Duenser
Melanie J. McGrath, Oliver Lack, James Tisch, and Andreas Duenser. 2025. https://doi.org/10.3389/frai.2025.1582880 Measuring trust in artificial intelligence: validation of an established scale and its short form . Frontiers in Artificial Intelligence, Volume 8 - 2025
-
[40]
Nikita Mehandru, Sweta Agrawal, Yimin Xiao, Ge Gao, Elaine Khoong, Marine Carpuat, and Niloufar Salehi. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.712 Physician detection of clinical harm in machine translation: Quality estimation aids in reliance and backtranslation identifies critical errors . In Proceedings of the 2023 Conference on Empirical Me...
-
[41]
Mary Nurminen. 2021. Investigating the influence of context in the use and reception of raw machine translation
2021
-
[42]
Sara Papi, Javier Garcia Gilabert, Zachary Hopton, Vil \'e m Zouhar, Carlos Escolano, Gerard I G \'a llego, Jorge Iranzo-S \'a nchez, Ahrii Kim, Dominik Mach \'a c ek, Patricia Schmidtova, and 1 others. 2025. Hearing to translate: The effectiveness of speech modality integration into llms. arXiv preprint arXiv:2512.16378
Pith/arXiv arXiv 2025
-
[43]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492--28518. PMLR
2023
-
[44]
Ricardo Rei, Jos \'e G. C. de Souza, Duarte Alves, Chrysoula Zerva, Ana C Farinha, Taisiya Glushkova, Alon Lavie, Luisa Coheur, and Andr \'e F. T. Martins. 2022. https://doi.org/10.18653/v1/2022.wmt-1.52 COMET -22: Unbabel- IST 2022 submission for the metrics shared task . In Proceedings of the Seventh Conference on Machine Translation (WMT), pages 578--5...
-
[45]
Ricardo Rei, Nuno M Guerreiro, Jos \'e Pombal, Jo \ a o Alves, Pedro Teixeirinha, Amin Farajian, and Andr \'e FT Martins. 2025. Tower+: Bridging generality and translation specialization in multilingual llms. arXiv preprint arXiv:2506.17080
arXiv 2025
-
[46]
Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.213 COMET : A neural framework for MT evaluation . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685--2702, Online. Association for Computational Linguistics
-
[47]
Elizabeth Salesky, Marcello Federico, and Antonis Anastasopoulos, editors. 2025. https://doi.org/10.18653/v1/2025.iwslt-1.0 Proceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025) . Association for Computational Linguistics, Vienna, Austria (in-person and online)
-
[48]
Ariadna Sanchez, Alice Ross, and Nina Markl. 2024. Beyond the binary: Limitations and possibilities of gender-related speech technology research. In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 526--532. IEEE
2024
-
[49]
Beatrice Savoldi, Sara Papi, Matteo Negri, Ana Guerberof-Arenas, and Luisa Bentivogli. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1002 What the harm? quantifying the tangible impact of gender bias in machine translation with a human-centered study . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 180...
-
[50]
Beatrice Savoldi, Alan Ramponi, Matteo Negri, and Luisa Bentivogli. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.700 Translation in the hands of many: Centering lay users in machine translation interactions . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 13876--13889, Suzhou, China. Association for C...
-
[51]
Breena R Taira, Vanessa Kreger, Aristides Orue, and Lisa C Diamond. 2021. A pragmatic assessment of google translate for emergency department instructions. Journal of General Internal Medicine, 36(11):3361--3365
2021
-
[52]
Ungless, Sunipa Dev, Cynthia L
Eddie L. Ungless, Sunipa Dev, Cynthia L. Bennett, Rebecca Gulotta, Jasmijn Bastings, and Remi Denton. 2025. https://doi.org/10.18653/v1/2025.acl-long.1001 Amplifying trans and nonbinary voices: A community-centred harm taxonomy for LLM s . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
-
[53]
google translate is our best friend here
Susana Valdez and Ana Guerberof-Arenas. 2025. “google translate is our best friend here” a vignette-based interview study on machine translation use for health communication. Translation Spaces, 14(2):253--276
2025
-
[54]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://doi.org/10.18653/v1/2020.emnlp-demos.6 Transformers: Sta...
-
[55]
Martindale, Charlotte Vaughn, Ge Gao, and Marine Carpuat
Yimin Xiao, Yongle Zhang, Dayeon Ki, Calvin Bao, Marianna J. Martindale, Charlotte Vaughn, Ge Gao, and Marine Carpuat. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1725 Toward machine translation literacy: How lay users perceive and rely on imperfect translations . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Process...
-
[56]
Emmanouil Zaranis, Giuseppe Attanasio, Sweta Agrawal, and Andre Martins. 2025. https://doi.org/10.18653/v1/2025.acl-long.1228 Watching the watchers: Exposing gender disparities in machine translation quality estimation . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 25261--25284, ...
-
[57]
Yuanyuan Zhang, Yixuan Zhang, Bence Mark Halpern, Tanvina Patel, and Odette Scharenborg. 2022. Mitigating bias against non-native accents. In Interspeech, pages 3168--3172
2022
-
[58]
Lal Zimman. 2020. Sociophonetics. The International Encyclopedia of Linguistic Anthropology, pages 1--5
2020
-
[59]
Lal Zimman. 2021. Gender diversity and the voice. In The Routledge handbook of language, gender, and sexuality, pages 69--90. Routledge
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.