DisasterBench: A Multimodal Benchmark for UAV-Based Disaster Response in Complex Environments
Pith reviewed 2026-06-28 02:32 UTC · model grok-4.3
The pith
DisasterVL reaches GPT-4o-comparable accuracy on multi-stage UAV disaster reasoning at 2B parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
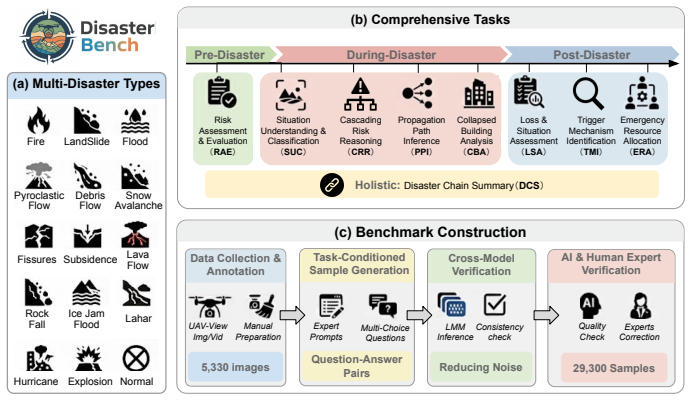
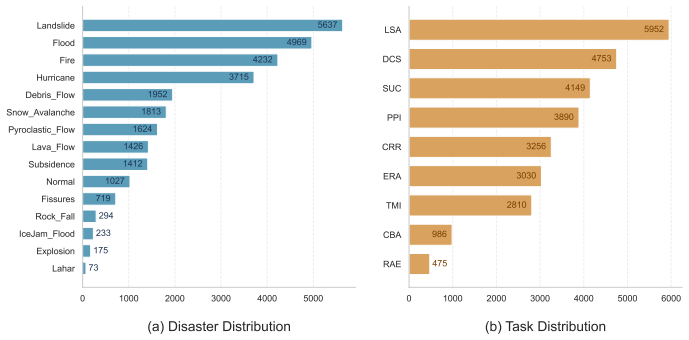
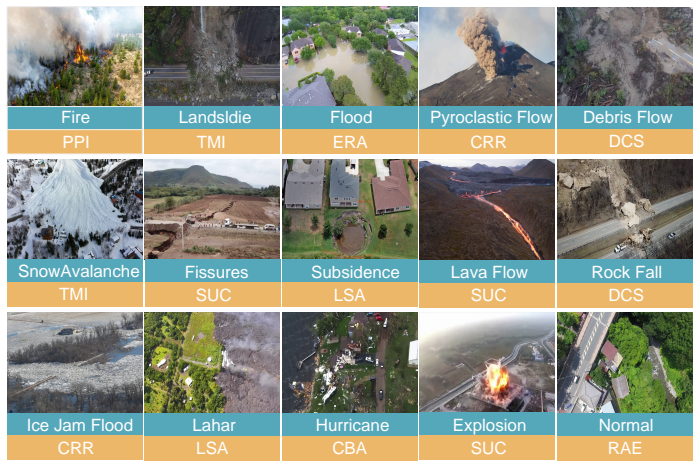
DisasterBench supplies 14 scene types and 9 tasks with explicit mappings across pre-, during-, and post-disaster phases that probe causal attribution, propagation prediction, damage analysis, and decision-oriented reasoning; the companion DisasterVL model, produced by domain instruction tuning followed by chain-of-thought multimodal alignment and reinforcement-learning policy optimization, delivers GPT-4o-level accuracy on these tasks while remaining efficient enough for on-site deployment.
What carries the argument
The three-stage optimization pipeline (domain instruction tuning, chain-of-thought-guided multimodal alignment, reinforcement learning-based policy optimization) that yields the 2B-parameter DisasterVL model.
If this is right
- Multimodal models can be scored on the full pre-during-post reasoning chain rather than isolated perception tasks.
- A 2B-parameter model can exceed every evaluated open-source MLLM and approach closed-source performance on these tasks.
- Reasoning models become feasible under the tight compute limits typical of field UAV operations.
- Fine-grained task mappings allow targeted diagnosis of where models fail at attribution, prediction, or decision steps.
Where Pith is reading between the lines
- The same staged training recipe could be applied to other specialized edge domains that need causal and decision reasoning from visual input.
- If the benchmark scenes prove narrower than real incidents, performance gains may shrink when models encounter novel disaster signatures or sensor noise.
- Pairing the model outputs directly with UAV flight controls could turn passive observation into automated initial response suggestions.
Load-bearing premise
The 14 chosen scene types, 9 tasks, and their disaster-task mappings are sufficient to represent the causal, predictive, damage, and decision reasoning actually required during UAV disaster response.
What would settle it
Running DisasterVL and GPT-4o side-by-side on new, previously unseen UAV footage from an actual or high-fidelity simulated disaster and measuring agreement with expert responder judgments on the same causal, predictive, and action questions.
Figures


read the original abstract
When a disaster unfolds, responders must answer not only what is happening, but also why it is happening, what will happen next, and what to do now, often from noisy low-altitude UAV views and under tight on-site compute constraints. However, most existing multimodal benchmarks emphasize perception (e.g., recognition/description), cover limited disaster types, and provide insufficient support for the multi-stage reasoning required in practical emergency response. We introduce DisasterBench, a multi-stage multimodal reasoning benchmark for UAV-Based disaster response in complex environments. DisasterBench spans 14 disaster-related scene types and 9 response-critical tasks across pre-, during-, and post-disaster stages, with fine-grained disaster-task mappings that explicitly test causal attribution, propagation prediction, damage analysis, and decision-oriented reasoning. To enable reasoning on the edge, we further propose DisasterVL, a lightweight multimodal model optimized with a three-stage pipeline combining domain instruction tuning, chain-of-thought-guided multimodal alignment, and reinforcement learning-based policy optimization. Experiments across 21 popular MLLMs show that our 2B-parameter DisasterVL outperforms all evaluated open-source models and substantially narrows the gap to state-of-the-art closed-source models, achieving GPT-4o-comparable reasoning accuracy with superior efficiency. The project page is available at https://github.com/TanmouTT/DisasterBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DisasterBench, a multimodal benchmark spanning 14 disaster-related scene types and 9 response-critical tasks across pre-, during-, and post-disaster stages, with mappings to test causal attribution, propagation prediction, damage analysis, and decision-oriented reasoning from UAV imagery. It also proposes DisasterVL, a 2B-parameter multimodal model trained via a three-stage pipeline of domain instruction tuning, chain-of-thought-guided alignment, and RL-based policy optimization. Experiments on 21 MLLMs claim that DisasterVL outperforms all open-source models evaluated and narrows the gap to closed-source models like GPT-4o while offering superior efficiency. The project page with code is provided.
Significance. If the benchmark tasks are shown to be representative and the evaluation uses proper held-out data, the work would provide a useful resource for advancing multimodal reasoning in time-critical, resource-constrained disaster response scenarios. The emphasis on edge-deployable models and the public release of the benchmark and code are positive contributions that could support reproducible follow-on research.
major comments (2)
- [Abstract (benchmark description)] The central performance claim for DisasterVL (outperforming open-source models and approaching GPT-4o) rests on DisasterBench testing the claimed multi-stage reasoning capabilities, yet the abstract provides no details on expert validation, comparison to real incident logs, or coverage against established disaster-response protocols for the 14 scene types and 9 tasks. This is load-bearing because narrower or less representative tasks would make the reported accuracy gaps difficult to interpret as evidence of practical capability.
- [Experiments (model training and evaluation)] DisasterVL is trained via domain instruction tuning and RL policy optimization on the newly introduced benchmark; without explicit information on data partitioning, held-out evaluation sets, or leakage controls in the Experiments section, the reported gains may partly reflect fitting to the test distribution rather than generalization.
minor comments (1)
- [Abstract] The abstract states results across 21 MLLMs but does not specify which models or the exact metrics used for 'reasoning accuracy'; adding this detail would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The two major comments highlight important aspects for strengthening the presentation of the benchmark's validity and the evaluation rigor. We address each point below and commit to revisions that improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract (benchmark description)] The central performance claim for DisasterVL (outperforming open-source models and approaching GPT-4o) rests on DisasterBench testing the claimed multi-stage reasoning capabilities, yet the abstract provides no details on expert validation, comparison to real incident logs, or coverage against established disaster-response protocols for the 14 scene types and 9 tasks. This is load-bearing because narrower or less representative tasks would make the reported accuracy gaps difficult to interpret as evidence of practical capability.
Authors: We agree that the abstract is highly concise and omits these supporting details, which could help readers immediately assess task representativeness. The manuscript body (Section 3) details the benchmark construction, including mappings to established protocols and expert input during scene and task design. To directly address the concern, we will revise the abstract to include a brief clause summarizing the expert validation process and alignment with disaster-response frameworks. This change will make the load-bearing aspects more transparent while preserving the abstract's brevity. revision: yes
-
Referee: [Experiments (model training and evaluation)] DisasterVL is trained via domain instruction tuning and RL policy optimization on the newly introduced benchmark; without explicit information on data partitioning, held-out evaluation sets, or leakage controls in the Experiments section, the reported gains may partly reflect fitting to the test distribution rather than generalization.
Authors: This observation is correct and points to a genuine gap in the current Experiments section. The manuscript does not currently provide explicit details on data partitioning or leakage prevention. We will add a dedicated paragraph in the Experiments section describing the split (60/20/20 train/val/test with scene-level disjointness), confirmation that all reported metrics use the held-out test set, and the controls implemented to avoid leakage between training and evaluation. These additions will allow readers to properly interpret the generalization claims. revision: yes
Circularity Check
No circularity in claimed derivation or results
full rationale
The paper introduces a new benchmark (DisasterBench with 14 scenes and 9 tasks) and a model (DisasterVL) trained via a three-stage optimization pipeline on the domain data, then reports empirical performance across 21 MLLMs. No mathematical derivation, first-principles prediction, or uniqueness theorem is claimed that reduces to its own inputs by construction. There are no self-citations of load-bearing results, no fitted parameters renamed as predictions, and no ansatz or renaming patterns. The performance claims are presented as experimental outcomes on the introduced benchmark, making the contribution self-contained as an empirical proposal without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D. Shianios, P. Kolios, C. Kyrkou, Multifire20k: A semi-supervised enhanced large-scale uav-based benchmark for advancing multi-task learning in fire mon- itoring, Computer Vision and Image Understanding 254 (2025) 104318.doi: https://doi.org/10.1016/j.cviu.2025.104318. URLhttps://www.sciencedirect.com/science/article/pii/S10773 14225000414
-
[2]
D. Townsell, L. Chen, M. Xie, C. Pan, W. Zhang, Stars: Semantics-aware text- guided aerial image refinement and synthesis, Computer Vision and Image Un- derstanding 262 (2025) 104561.doi:https://doi.org/10.1016/j.cviu.2 025.104561. URLhttps://www.sciencedirect.com/science/article/pii/S10773 1422500284X
-
[3]
Y . Yu, Q. Hu, X. Du, J. Wang, F. Mo, R. Sieber, WXImpactBench: A disruptive weather impact understanding benchmark for evaluating large language models, in: Findings of the Association for Computational Linguistics: ACL 2025, Asso- ciation for Computational Linguistics, Vienna, Austria, 2025, pp. 4016–4035
2025
-
[4]
Z. Lei, Y . Dong, W. Li, R. Ding, Q. R. Wang, J. Li, Harnessing large language models for disaster management: A survey, in: Findings of the Association for Computational Linguistics: ACL 2025, Association for Computational Linguis- tics, Vienna, Austria, 2025, pp. 14528–14551
2025
-
[5]
P. Xu, F. Yan, Rssr: Efficient knowledge transfer and deep spatial modeling for remote sensing visual question answering, Computer Vision and Image Under- standing 268 (2026) 104753.doi:https://doi.org/10.1016/j.cviu.202 6.104753. URLhttps://www.sciencedirect.com/science/article/pii/S10773 14226001207 21
-
[6]
J. Cleland-Huang, P. A. A. Granadeno, A. M. R. Bernal, D. Hernandez, M. Mur- phy, M. Petterson, W. Scheirer, Cognitive guardrails for open-world decision making in autonomous drone swarms, arXiv preprint arXiv:2505.23576 (2025)
arXiv 2025
-
[7]
K. Li, Z. Xin, L. Pang, C. Pang, Y . Deng, J. Yao, G. Xia, D. Meng, Z. Wang, X. Cao, Segearth-r1: Geospatial pixel reasoning via large language model, arXiv preprint arXiv:2504.09644 (2025)
arXiv 2025
-
[8]
K. Yin, X. Dong, C. Liu, L. Huang, Y . Xiao, Z. Liu, A. Mostafavi, J. Caver- lee, DisastIR: A comprehensive information retrieval benchmark for disaster management, in: Findings of the Association for Computational Linguistics: EMNLP 2025, Association for Computational Linguistics, Suzhou, China, 2025, pp. 1836–1867
2025
-
[9]
X. Ma, J. Li, C. Pei, H. Liu, Geomag: A vision-language model for pixel-level fine-grained remote sensing image parsing, in: Proceedings of the 33rd ACM International Conference on Multimedia, MM ’25, Association for Computing Machinery, New York, NY , USA, 2025, p. 5441–5450.doi:10.1145/374602 7.3754559. URLhttps://doi.org/10.1145/3746027.3754559
-
[10]
L. Yao, F. Liu, D. Chen, C. Zhang, Y . Wang, Z. Chen, W. Xu, S. Di, Y . Zheng, Remotesam: Towards segment anything for earth observation, in: Proceedings of the 33rd ACM International Conference on Multimedia, MM ’25, Association for Computing Machinery, New York, NY , USA, 2025, p. 3027–3036.doi: 10.1145/3746027.3754950. URLhttps://doi.org/10.1145/374602...
-
[11]
J. Zhao, Q. Luo, S. Zhang, S. Gao, J. Wu, Hdcfn: Haze distribution-aware cross-modal fusion network for infrared-guided dense haze removal in uavs, in: Proceedings of the 33rd ACM International Conference on Multimedia, MM ’25, Association for Computing Machinery, New York, NY , USA, 2025, p. 10867–10875.doi:10.1145/3746027.3754994. URLhttps://doi.org/10....
-
[12]
Kulahara, G
M. Kulahara, G. S. Kashyap, N. Joshi, A. Soni, Can we predict the unpredictable? leveraging disasternet-llm for multimodal disaster classification, IEEE Interna- tional Geoscience and Remote Sensing Symposium (2025)
2025
- [13]
- [14]
-
[15]
J. Wang, W. Xuan, H. Qi, Z. Liu, K. Liu, Y . Wu, H. Chen, J. Song, J. Xia, Z. Zheng, N. Yokoya, Disasterm3: A remote sensing vision-language dataset for disaster damage assessment and response, in: The Thirty-ninth Annual Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[16]
C. Kuai, Z. Li, B. Rosen, S. Paan, N. Jafari, J.-L. Briaud, Y . Zhang, Y . Hashash, Y . Zhou, Knowledge-grounded agentic large language models for multi-hazard understanding from reconnaissance reports, arXiv preprint arXiv:2511.14010 (2025)
arXiv 2025
-
[17]
A. Shabbir, M. A. Munir, A. Dudhane, M. U. Sheikh, M. H. Khan, P. Fraccaro, J. B. Moreno, F. S. Khan, S. Khan, Thinkgeo: Evaluating tool-augmented agents for remote sensing tasks, arXiv preprint arXiv:2505.23752 (2025)
arXiv 2025
-
[18]
Z. Chen, C. Wang, N. Zhang, F. Zhang, Rscc: A large-scale remote sensing change caption dataset for disaster events, in: The Thirty-ninth Annual Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[19]
Revankar, U
S. Revankar, U. Mall, C. P. Phoo, K. Bala, B. Hariharan, MONITRS: Multi- modal observations of natural incidents through remote sensing, in: The Thirty- 23 ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[20]
B. Jankovic, S. Jangirova, W. Ullah, L. U. Khan, M. Guizani, Uav-assisted real-time disaster detection using optimized transformer model, arXiv preprint arXiv:2501.12087 (2025)
arXiv 2025
-
[21]
Kyrkou, T
C. Kyrkou, T. Theocharides, Emergencynet: Efficient aerial image classification for drone-based emergency monitoring using atrous convolutional feature fusion, IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sens- ing 13 (2020) 1687–1699
2020
-
[22]
Rahnemoonfar, T
M. Rahnemoonfar, T. Chowdhury, A. Sarkar, D. Varshney, M. Yari, R. R. Mur- phy, Floodnet: A high resolution aerial imagery dataset for post flood scene un- derstanding, IEEE Access 9 (2021) 89644–89654
2021
-
[23]
Rahnemoonfar, T
M. Rahnemoonfar, T. Chowdhury, R. Murphy, Rescuenet: A high resolution uav semantic segmentation dataset for natural disaster damage assessment, Scientific data 10 (1) (2023) 913
2023
-
[24]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft coco: Common objects in context, in: European conference on computer vision, 2014, pp. 740–755
2014
-
[25]
B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hockenmaier, S. Lazebnik, Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models, in: Proceedings of the IEEE international con- ference on computer vision, 2015, pp. 2641–2649
2015
-
[26]
Kazemzadeh, V
S. Kazemzadeh, V . Ordonez, M. Matten, T. Berg, Referitgame: Referring to ob- jects in photographs of natural scenes, in: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), Association for Computational Linguistics, Doha, Qatar, 2014, pp. 787–798
2014
-
[27]
Marino, M
K. Marino, M. Rastegari, A. Farhadi, R. Mottaghi, Ok-vqa: A visual ques- tion answering benchmark requiring external knowledge, in: Proceedings of the 24 IEEE/cvf conference on computer vision and pattern recognition, 2019, pp. 3195– 3204
2019
-
[28]
Mathew, D
M. Mathew, D. Karatzas, C. Jawahar, Docvqa: A dataset for vqa on document images, in: Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 2200–2209
2021
-
[29]
Schwenk, A
D. Schwenk, A. Khandelwal, C. Clark, K. Marino, R. Mottaghi, A-okvqa: A benchmark for visual question answering using world knowledge, in: European conference on computer vision, 2022, pp. 146–162
2022
-
[30]
Singh, G
A. Singh, G. Pang, M. Toh, J. Huang, W. Galuba, T. Hassner, Textocr: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8802–8812
2021
-
[31]
X. Yue, Y . Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y . Sun, et al., Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2024, pp. 9556–9567
2024
-
[32]
P. Lu, H. Bansal, T. Xia, J. Liu, C. Li, H. Hajishirzi, H. Cheng, K.-W. Chang, M. Galley, J. Gao, Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts, in: International Conference on Learning Representa- tions (ICLR), 2024
2024
-
[33]
Hiippala, M
T. Hiippala, M. Alikhani, J. Haverinen, T. Kalliokoski, E. Logacheva, S. Orekhova, A. Tuomainen, M. Stone, J. A. Bateman, Ai2d-rst: a multimodal corpus of 1000 primary school science diagrams, Language Resources and Eval- uation 55 (3) (2021) 661–688
2021
-
[34]
Masry, D
A. Masry, D. X. Long, J. Q. Tan, S. Joty, E. Hoque, ChartQA: A benchmark for question answering about charts with visual and logical reasoning, in: Findings of the Association for Computational Linguistics: ACL 2022, Association for Computational Linguistics, Dublin, Ireland, 2022, pp. 2263–2279. 25
2022
-
[35]
H. Liu, C. Li, Q. Wu, Y . J. Lee, Visual instruction tuning, in: Thirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[36]
C. Fu, P. Chen, Y . Shen, Y . Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sun, et al., Mme: A comprehensive evaluation benchmark for multimodal large language models, in: The Thirty-ninth Annual Conference on Neural Infor- mation Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[37]
Y . Liu, H. Duan, Y . Zhang, B. Li, S. Zhang, W. Zhao, Y . Yuan, J. Wang, C. He, Z. Liu, et al., Mmbench: Is your multi-modal model an all-around player?, in: European conference on computer vision, 2024, pp. 216–233
2024
-
[38]
W. Yu, Z. Yang, L. Li, J. Wang, K. Lin, Z. Liu, X. Wang, L. Wang, Mm-vet: Evaluating large multimodal models for integrated capabilities, arXiv preprint arXiv:2308.02490 (2023)
Pith/arXiv arXiv 2023
-
[39]
L. Chen, J. Li, X. Dong, P. Zhang, Y . Zang, Z. Chen, H. Duan, J. Wang, Y . Qiao, D. Lin, F. Zhao, Are we on the right way for evaluating large vision-language models?, in: The Thirty-eighth Annual Conference on Neural Information Pro- cessing Systems, 2024
2024
- [40]
-
[41]
S. Bai, S. Yang, J. Bai, P. Wang, X. Zhang, J. Lin, X. Wang, C. Zhou, J. Zhou, Touchstone: Evaluating vision-language models by language models, arXiv preprint arXiv:2308.16890 (2023)
arXiv 2023
-
[42]
J. Li, W. Lu, H. Fei, M. Luo, M. Dai, M. Xia, Y . Jin, Z. Gan, D. Qi, C. Fu, et al., A survey on benchmarks of multimodal large language models, arXiv preprint arXiv:2408.08632 (2024)
arXiv 2024
-
[43]
Huang, J
J. Huang, J. Zhang, A survey on evaluation of multimodal large language models (2024). 26
2024
-
[44]
R. Rawat, Disasterqa: A benchmark for assessing the performance of llms in disaster response, arXiv preprint arXiv:2410.20707 (2024)
arXiv 2024
-
[45]
N. Zhou, H. Wang, J. Li, H. Li, Y . Song, Q. Wang, Y . Li, X. Chen, Firesentry: A multi-modal spatio-temporal benchmark dataset for fine-grained wildfire spread forecasting, arXiv preprint arXiv:2512.03369 (2025)
arXiv 2025
-
[46]
G. Simantiris, K. Bacharidis, A. Papanikolaou, P. Giannakakis, C. Panagiotakis, Aifloodsense: A global aerial imagery dataset for semantic segmentation and un- derstanding of flooded environments, arXiv preprint arXiv:2512.17432 (2025)
arXiv 2025
-
[47]
A. Khan, S. Gupta, S. K. Gupta, Emerging uav technology for disaster detection, mitigation, response, and preparedness, Journal of Field Robotics 39 (6) (2022) 905–955
2022
-
[48]
rep., United Nations Office for Disaster Risk Reduction, accessed 3 January 2026 (2020)
UNDRR, Hazard definition and classification review, Tech. rep., United Nations Office for Disaster Risk Reduction, accessed 3 January 2026 (2020). URLhttps://www.undrr.org/publication/documents-and-publicati ons/hazard-definition-and-classification-review-technical-0
2026
-
[49]
rep., United Nations Office for Disaster Risk Reduction, accessed 3 January 2026 (2017)
UNDRR, The sendai framework terminology on disaster risk reduction: ¨disaster risk management¨, Tech. rep., United Nations Office for Disaster Risk Reduction, accessed 3 January 2026 (2017). URLhttps://www.undrr.org/terminology/disaster-risk-managemen t
2026
-
[50]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al., Deepseekmath: Pushing the limits of mathematical reasoning in open language models, arXiv preprint arXiv:2402.03300 (2024)
Pith/arXiv arXiv 2024
-
[51]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al., Gpt-4o system card, arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[52]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al., Gemini 2.5: Pushing the fron- 27 tier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, arXiv preprint arXiv:2507.06261 (2025)
Pith/arXiv arXiv 2025
-
[53]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, et al., Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, arXiv preprint arXiv:2409.12191 (2024)
Pith/arXiv arXiv 2024
-
[54]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, et al., Qwen2.5-vl technical report, arXiv preprint arXiv:2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[55]
X. Chen, Z. Wu, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruan, Janus-pro: Unified multimodal understanding and generation with data and model scaling, arXiv preprint arXiv:2501.17811 (2025)
Pith/arXiv arXiv 2025
-
[56]
Z. Chen, W. Wang, Y . Cao, Y . Liu, Z. Gao, E. Cui, J. Zhu, S. Ye, H. Tian, Z. Liu, et al., Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling, arXiv preprint arXiv:2412.05271 (2024)
Pith/arXiv arXiv 2024
-
[57]
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shao, et al., Internvl3. 5: Advancing open-source multimodal models in versatility, rea- soning, and efficiency, arXiv preprint arXiv:2508.18265 (2025)
Pith/arXiv arXiv 2025
-
[58]
Z. Wu, X. Chen, Z. Pan, X. Liu, W. Liu, D. Dai, H. Gao, Y . Ma, C. Wu, B. Wang, et al., Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding, arXiv preprint arXiv:2412.10302 (2024)
Pith/arXiv arXiv 2024
-
[59]
M. Abdin, S. A. Jacobs, A. A. Awan, J. Aneja, A. Awadallah, H. H. Awadalla, N. Bach, A. Bahree, A. Bakhtiari, H. S. Behl, A. Benhaim, M. Bilenko, J. Bjorck, S. Bubeck, M. Cai, C. C. T. Mendes, W. Chen, V . Chaudhary, P. Chopra, A. D. Giorno, G. de Rosa, M. Dixon, R. Eldan, V . Fragoso, D. Iter, A. Goswami, S. Gu- nasekar, E. Haider, J. Hao, R. J. Hewett, ...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.