Anchor PCA
Pith reviewed 2026-06-27 23:26 UTC · model grok-4.3
The pith
Anchor PCA recovers a maximal invariant subspace from multi-domain data by solving PCA on a modified target matrix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
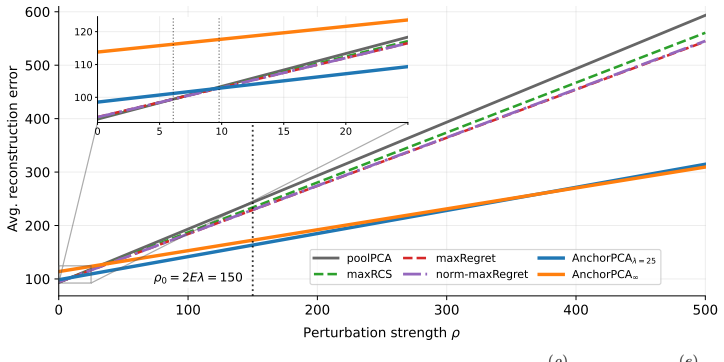
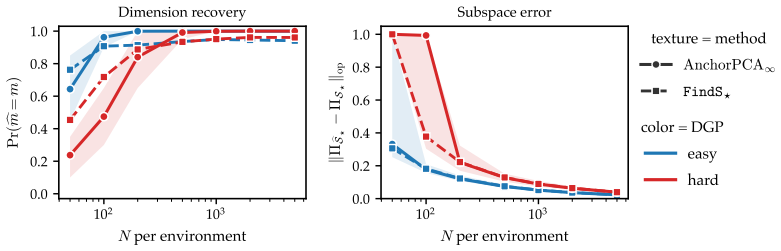
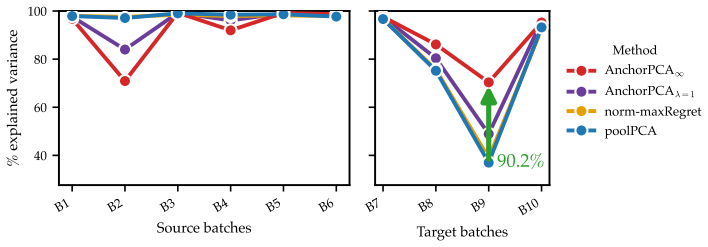
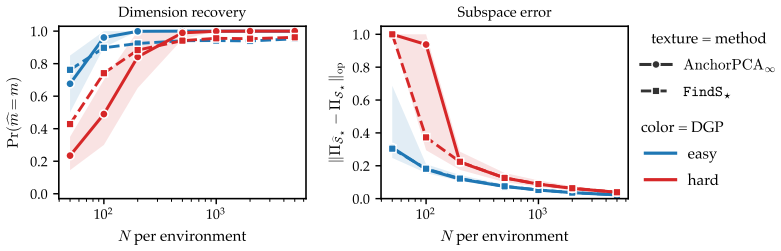
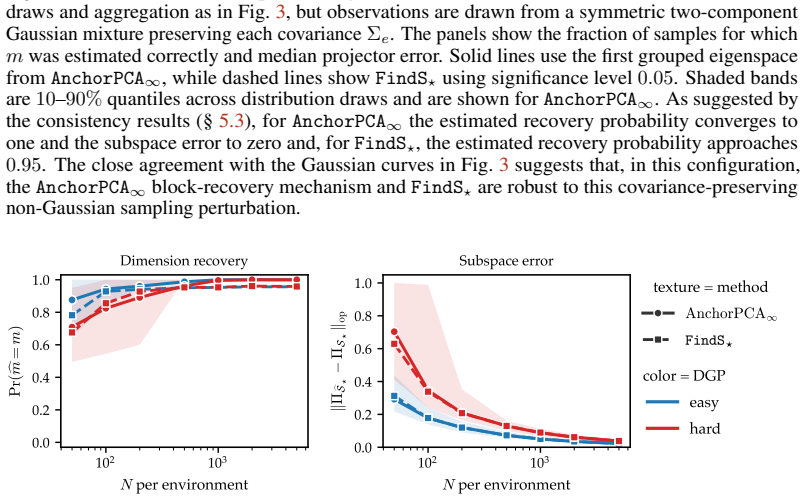
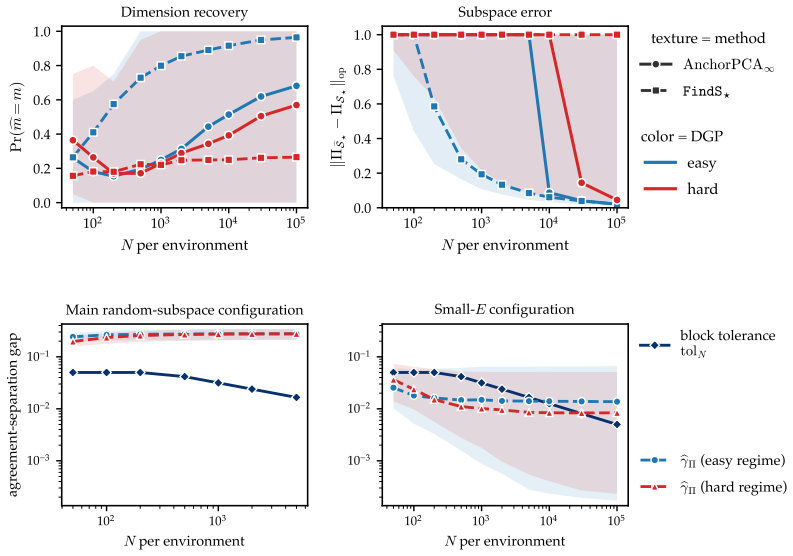
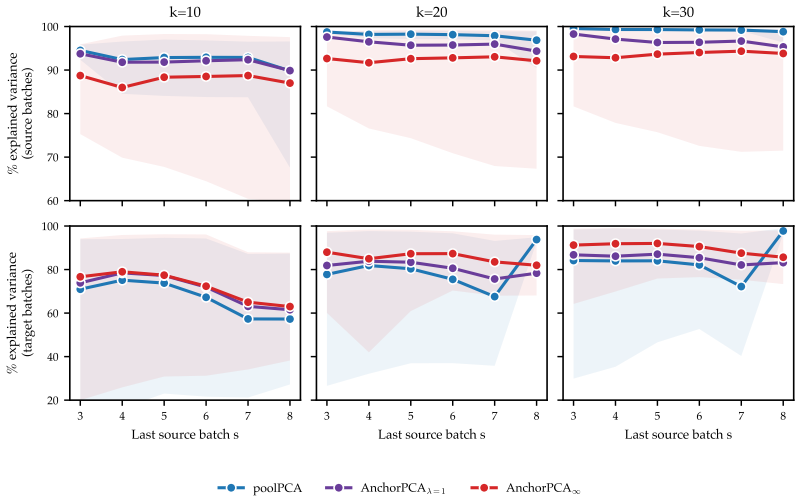
Anchor PCA amounts to PCA on a modified target matrix and thus can be solved efficiently. Moreover, it recovers a maximal invariant subspace and admits a minimax reconstruction interpretation under bounded domain-specific covariance inflations. On simulated and real-world gas sensor data with temporal drift, it yields embeddings that explain more variance on unseen domains than the pooling baseline and a worst-case alternative.
What carries the argument
Anchor PCA, which trades off overall explained variance with agreement between the shared and domain-specific low-rank embeddings and is implemented as PCA on a modified target matrix.
If this is right
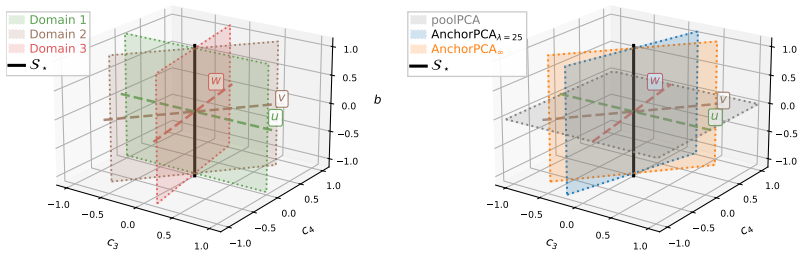
- Anchor PCA recovers the maximally invariant subspace on simulated data.
- It yields embeddings that explain more variance on unseen domains than the pooling baseline on real gas sensor data with temporal drift.
- It admits a minimax reconstruction interpretation when domain-specific covariances are bounded inflations of a shared matrix.
- It can be solved efficiently because it reduces to standard PCA on the modified target matrix.
Where Pith is reading between the lines
- The same trade-off idea could be applied to other unsupervised dimension-reduction methods beyond PCA for multi-domain data.
- The recovered invariant subspace may relate to domain-generalization techniques used in supervised learning settings.
- The method could be tested on additional time-series or sensor datasets that exhibit distribution shifts not limited to temporal drift.
Load-bearing premise
Domain-specific covariance matrices differ from a shared covariance by bounded inflations.
What would settle it
A concrete dataset where the bounded-inflation modeling assumption fails and where Anchor PCA neither recovers the maximal invariant subspace nor outperforms the pooling baseline on unseen domains would falsify the central claims.
Figures

read the original abstract
Principal component analysis (PCA) is one of the most widely used unsupervised dimension reduction techniques. We study PCA for data from multiple related domains. Since principal components generally differ across domains, one way to obtain a shared low-rank embedding is to perform PCA on the pooled data. However, this approach can focus on spurious directions that exhibit high variation in only a few domains. To find a robust embedding that still explains most variance in unseen but similar domains, we propose instead to focus on shared directions of variation. To this end, we introduce Anchor PCA which trades off overall explained variance with agreement between the shared and domain-specific low-rank embeddings. Anchor PCA amounts to PCA on a modified target matrix and thus can be solved efficiently. Moreover, we show that Anchor PCA recovers a maximal invariant subspace and admits a minimax reconstruction interpretation under bounded domain-specific covariance inflations. On simulated and real-world gas sensor data with temporal drift, we demonstrate, respectively, that Anchor PCA recovers the maximally invariant subspace and yields embeddings that explain more variance on unseen domains than the pooling baseline and a worst-case alternative. Taken together, these findings establish Anchor PCA as a promising approach to robust unsupervised dimension reduction from multi-domain data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Anchor PCA for unsupervised dimension reduction on multi-domain data. Instead of standard PCA on pooled data, it performs PCA on a modified target matrix that trades off total explained variance against agreement between the shared embedding and domain-specific embeddings. The method is claimed to recover a maximal invariant subspace and to admit a minimax reconstruction guarantee under the assumption of bounded domain-specific covariance inflations. Empirical results on simulated data and real gas-sensor data with temporal drift are presented to show that the resulting embeddings explain more variance on unseen domains than a pooling baseline.
Significance. If the bounded-inflation modeling assumption holds and the derivations are correct, Anchor PCA supplies a computationally efficient, theoretically grounded alternative to pooled PCA that targets invariant directions of variation. The explicit link to maximal invariant subspaces and minimax optimality would be a substantive contribution to multi-domain unsupervised learning. The empirical demonstration on drift-affected sensor data suggests practical relevance, though the scope is limited to regimes where the covariance-inflation bound is realistic.
major comments (2)
- [Abstract (theoretical-properties paragraph)] Abstract (theoretical-properties paragraph): the claims that Anchor PCA recovers a maximal invariant subspace and admits a minimax reconstruction interpretation are stated to hold only under bounded domain-specific covariance inflations. This modeling premise is load-bearing for both theoretical results, yet the abstract supplies neither the explicit form of the modified matrix nor any derivation or verification of the bound on the gas-sensor data. If the actual domain covariances exceed the posited bound, the recovery and minimax statements cease to apply.
- [Abstract (empirical paragraph)] Abstract (empirical paragraph): the reported gains in explained variance on unseen domains are presented without error bars, without specification of how the trade-off parameter lambda is chosen (cross-validation, fixed, or otherwise), and without the number of replications. These omissions make it impossible to judge whether the improvement over the pooling baseline is statistically reliable or sensitive to hyper-parameter selection.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly indicated the algebraic form of the modified target matrix (e.g., a linear combination involving the pooled covariance and domain-specific terms) rather than only describing the trade-off conceptually.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract (theoretical-properties paragraph)] Abstract (theoretical-properties paragraph): the claims that Anchor PCA recovers a maximal invariant subspace and admits a minimax reconstruction interpretation are stated to hold only under bounded domain-specific covariance inflations. This modeling premise is load-bearing for both theoretical results, yet the abstract supplies neither the explicit form of the modified matrix nor any derivation or verification of the bound on the gas-sensor data. If the actual domain covariances exceed the posited bound, the recovery and minimax statements cease to apply.
Authors: The abstract is space-constrained and therefore omits the explicit matrix form and full derivation; these appear in Equation (2) and Section 3 of the manuscript, where the modified target matrix is defined as a convex combination of the pooled covariance and a domain-agreement term. The bounded-inflation assumption is stated explicitly as the condition under which the maximal-invariant-subspace and minimax claims hold. We did not numerically verify the bound on the gas-sensor data, as it is a modeling premise rather than an empirically tested quantity in the current version. We will revise the abstract to make the conditional nature of the claims more prominent and add a short remark in the discussion section on the modeling assumption. revision: partial
-
Referee: [Abstract (empirical paragraph)] Abstract (empirical paragraph): the reported gains in explained variance on unseen domains are presented without error bars, without specification of how the trade-off parameter lambda is chosen (cross-validation, fixed, or otherwise), and without the number of replications. These omissions make it impossible to judge whether the improvement over the pooling baseline is statistically reliable or sensitive to hyper-parameter selection.
Authors: We agree that the abstract should report these details. In the full manuscript, λ is chosen by cross-validation on held-out training domains (Section 4.2), all reported numbers are averages over 20 independent replications, and standard-error bars appear in Figures 3–5. We will update the abstract to include the replication count, the cross-validation procedure for λ, and a reference to the error bars shown in the figures. revision: yes
Circularity Check
No circularity in derivation; method and claims are explicitly defined and derived under stated assumptions.
full rationale
The paper defines Anchor PCA directly as PCA performed on a modified target matrix that trades off explained variance against agreement across domains. The claims of recovering a maximal invariant subspace and admitting a minimax reconstruction are presented as derived results that hold under the explicit modeling premise of bounded domain-specific covariance inflations; these are not tautological or obtained by fitting a parameter to the target quantity itself. No equations reduce to their own inputs by construction, no predictions are statistically forced from fitted subsets, and no load-bearing self-citations or imported uniqueness theorems appear in the provided text. The derivation chain is therefore self-contained once the bounded-inflation assumption is granted.
Axiom & Free-Parameter Ledger
free parameters (1)
- trade-off parameter lambda
axioms (1)
- domain assumption Domain-specific covariance matrices differ from a shared covariance by bounded inflations.
Reference graph
Works this paper leans on
-
[1]
Zhang, Vivek K
Abubakar Abid, Martin J. Zhang, Vivek K. Bagaria, and James Zou. Exploring patterns enriched in a dataset with contrastive principal component analysis.Nature Communications, 9(1):2134,
-
[2]
doi: 10.1038/s41467-018-04608-8. 15
-
[3]
Minimax regret optimization for robust machine learning under distribution shift
Alekh Agarwal and Tong Zhang. Minimax regret optimization for robust machine learning under distribution shift. InProceedings of the 35th Conference on Learning Theory, volume 178 ofProceedings of Machine Learning Research, pages 2704–2729. PMLR, 2022. 40
2022
-
[4]
Invariant risk mini- mization.arXiv preprint arXiv:1907.02893, 2019
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk mini- mization.arXiv preprint arXiv:1907.02893, 2019. 1, 15
Pith/arXiv arXiv 1907
-
[5]
Krishna B. Athreya and Soumendra N. Lahiri.Measure Theory and Probability Theory. Springer Texts in Statistics. Springer, New York, 2006. doi: 10.1007/978-0-387-35434-7. 23
-
[6]
A Universal Prior for Integers and Estimation by Minimum Description Length
Rudolf Beran and Muni S. Srivastava. Bootstrap tests and confidence regions for functions of a covariance matrix.The Annals of Statistics, 13(1):95–115, 1985. doi: 10.1214/aos/1176346579. 7
-
[7]
twiddle” operation and bounds on derivatives of pro- jectors A.1 The “twiddle
Rajendra Bhatia.Matrix Analysis, volume 169 ofGraduate Texts in Mathematics. Springer, New York, 1997. doi: 10.1007/978-1-4612-0653-8. 16 10
-
[8]
Cambridge University Press,
Stephen Boyd and Lieven Vandenberghe.Convex Optimization. Cambridge University Press,
-
[9]
doi: 10.1017/CBO9780511804441. 28
-
[10]
Rune Christiansen, Niklas Pfister, Martin Emil Jakobsen, Nicola Gnecco, and Jonas Peters. A causal framework for distribution generalization.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):6614–6630, 2022. doi: 10.1109/TPAMI.2021.3094760. 15
-
[11]
Petros Drineas and Ilse C. F. Ipsen. Low-rank matrix approximations do not need a singular value gap.SIAM Journal on Matrix Analysis and Applications, 40(1):299–319, 2019. doi: 10.1137/18M1163658. 22
-
[12]
Qing Feng, Meilei Jiang, Jan Hannig, and J. S. Marron. Angle-based joint and individual variation explained.Journal of Multivariate Analysis, 166:241–265, 2018. doi: 10.1016/j.jmva. 2018.03.008. 15
-
[13]
Bernhard N. Flury. Common principal components in k groups.Journal of the American Statistical Association, 79(388):892–898, 1984. doi: 10.1080/01621459.1984.10477108. 15
-
[14]
Bernhard N. Flury and Walter Gautschi. An algorithm for simultaneous orthogonal transforma- tion of several positive definite symmetric matrices to nearly diagonal form.SIAM Journal on Scientific and Statistical Computing, 7(1):169–184, 1986. doi: 10.1137/0907013. 15
-
[15]
Chemical gas sensor array dataset
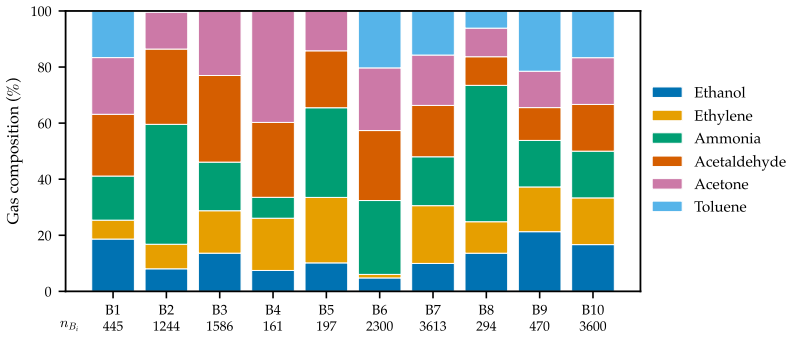
Jordi Fonollosa, Irene Rodríguez-Luján, and Ramón Huerta. Chemical gas sensor array dataset. Data in Brief, 3:85–89, 2015. doi: 10.1016/j.dib.2015.01.003. 9, 36
-
[16]
Maximum risk minimization with random forests.arXiv preprint arXiv:2512.10445, 2025
Francesco Freni, Anya Fries, Linus Kühne, Markus Reichstein, and Jonas Peters. Maximum risk minimization with random forests.arXiv preprint arXiv:2512.10445, 2025. 40
arXiv 2025
-
[17]
Worst-case low-rank approxima- tions.arXiv preprint arXiv:2603.11304, 2026
Anya Fries, Markus Reichstein, David Blei, and Jonas Peters. Worst-case low-rank approxima- tions.arXiv preprint arXiv:2603.11304, 2026. 1, 6, 10, 15, 32, 37
arXiv 2026
-
[18]
Tilmann Gneiting and Adrian E. Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102(477):359–378, 2007. doi: 10.1198/ 016214506000001437. 40
2007
-
[19]
The statistical implications of a system of simultaneous equations.Econo- metrica, 11(1):1–12, 1943
Trygve Haavelmo. The statistical implications of a system of simultaneous equations.Econo- metrica, 11(1):1–12, 1943. doi: 10.2307/1905714. 15
-
[20]
Geoffrey E. Hinton and Ruslan R. Salakhutdinov. Reducing the dimensionality of data with neural networks.Science, 313(5786):504–507, 2006. doi: 10.1126/science.1127647. 39
-
[21]
Horn and Charles R
Roger A. Horn and Charles R. Johnson.Matrix Analysis. Cambridge University Press, 2 edition,
-
[22]
doi: 10.1017/CBO9780511810817. 19, 22, 24, 25, 26, 30
-
[23]
Jolliffe.Principal Component Analysis
Ian T. Jolliffe.Principal Component Analysis. Springer Series in Statistics. Springer, New York, 2 edition, 2002. doi: 10.1007/b98835. 1
-
[24]
Invariant subspace decomposition
Margherita Lazzaretto, Jonas Peters, and Niklas Pfister. Invariant subspace decomposition. Journal of Machine Learning Research, 26(95):1–56, 2025. 15
2025
-
[25]
Eric F. Lock, Katherine A. Hoadley, J. S. Marron, and Andrew B. Nobel. Joint and individual variation explained (JIVE) for integrated analysis of multiple data types.The Annals of Applied Statistics, 7(1):523–542, 2013. doi: 10.1214/12-AOAS597. 15
-
[26]
Invariant causal representation learning for out-of-distribution generalization
Chaochao Lu, Yuhuai Wu, José Miguel Hernández-Lobato, and Bernhard Schölkopf. Invariant causal representation learning for out-of-distribution generalization. InInternational Conference on Learning Representations, 2022. 15
2022
-
[27]
Mahecha, Jacob A
Mirco Migliavacca, Talie Musavi, Miguel D. Mahecha, Jacob A. Nelson, Jürgen Knauer, Dennis D. Baldocchi, Oscar Perez-Priego, Rune Christiansen, Jonas Peters, et al. The three major axes of terrestrial ecosystem function.Nature, 598(7881):468–472, 2021. doi: 10.1038/ s41586-021-03939-9. 1 11
2021
-
[28]
Domain generalization via invariant feature representation
Krikamol Muandet, David Balduzzi, and Bernhard Schölkopf. Domain generalization via invariant feature representation. In Sanjoy Dasgupta and David McAllester, editors,Proceedings of the 30th International Conference on Machine Learning, volume 28 ofProceedings of Machine Learning Research, pages 10–18. PMLR, 2013. 15
2013
-
[29]
Unsupervised representation learning – an invariant risk min- imization perspective
Yotam Norman and Ron Meir. Unsupervised representation learning – an invariant risk min- imization perspective. InInternational Conference on Learning Representations, 2026. 1, 15
2026
-
[30]
Boyko, Adam Auton, Amit Indap, Karen S
John Novembre, Toby Johnson, Katarzyna Bryc, Zoltán Kutalik, Adam R. Boyko, Adam Auton, Amit Indap, Karen S. King, Sven Bergmann, Matthew R. Nelson, Matthew Stephens, and Carlos D. Bustamante. Genes mirror geography within europe.Nature, 456(7218):98–101,
-
[31]
doi: 10.1038/nature07331. 1
-
[32]
Sinno Jialin Pan, Ivor W. Tsang, James T. Kwok, and Qiang Yang. Domain adaptation via transfer component analysis.IEEE Transactions on Neural Networks, 22(2):199–210, 2011. doi: 10.1109/TNN.2010.2091281. 15
-
[33]
Causality: Models, Rea- soning, and Inference
Judea Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, 2 edition, 2009. doi: 10.1017/CBO9780511803161. 15
-
[34]
Causal Inference by using Invariant Prediction: Identification and Confidence Intervals , journal =
Jonas Peters, Peter Bühlmann, and Nicolai Meinshausen. Causal inference by using invariant prediction: Identification and confidence intervals.Journal of the Royal Statistical Society: Series B, 78(5):947–1012, 2016. doi: 10.1111/rssb.12167. 15
-
[35]
Herbert Robbins and Sutton Monro. A stochastic approximation method.The Annals of Mathematical Statistics, 22(3):400–407, 1951. doi: 10.1214/aoms/1177729586. 39
-
[36]
Invariant models for causal transfer learning.Journal of Machine Learning Research, 19(36):1–34, 2018
Mateo Rojas-Carulla, Bernhard Schölkopf, Richard Turner, and Jonas Peters. Invariant models for causal transfer learning.Journal of Machine Learning Research, 19(36):1–34, 2018. 15
2018
-
[37]
Dominik Rothenhäusler, Nicolai Meinshausen, Peter Bühlmann, and Jonas Peters. Anchor regression: Heterogeneous data meet causality.Journal of the Royal Statistical Society: Series B, 83(2):215–246, 2021. doi: 10.1111/rssb.12398. 1, 3, 15, 32
-
[38]
David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning representations by back-propagating errors.Nature, 323(6088):533–536, 1986. doi: 10.1038/323533a0. 39
-
[39]
The price of fair PCA: One extra dimension
Samira Samadi, Uthaipon Tantipongpipat, Jamie Morgenstern, Mohit Singh, and Santosh Vempala. The price of fair PCA: One extra dimension. InAdvances in Neural Information Processing Systems, volume 31, 2018. 14
2018
-
[40]
Bernhard Schölkopf, Dominik Janzing, Jonas Peters, Eleni Sgouritsa, Kun Zhang, and Joris M. Mooij. On causal and anticausal learning. InProceedings of the 29th International Conference on Machine Learning, pages 1255–1262. Omnipress, 2012. 15
2012
-
[41]
James R. Schott. Partial common principal component subspaces.Biometrika, 86(4):899–908,
- [42]
-
[43]
Distributional principal autoencoders.arXiv preprint arXiv:2404.13649, 2024
Xinwei Shen and Nicolai Meinshausen. Distributional principal autoencoders.arXiv preprint arXiv:2404.13649, 2024. 15, 40
Pith/arXiv arXiv 2024
-
[44]
Multi-criteria dimensionality reduction with applications to fairness
Uthaipon Tantipongpipat, Samira Samadi, Mohit Singh, Jamie Morgenstern, and Santosh Vempala. Multi-criteria dimensionality reduction with applications to fairness. InAdvances in Neural Information Processing Systems, volume 32, 2019. 15
2019
-
[45]
Eigenfaces for recognition.Journal of Cognitive Neuro- science, 3(1):71–86, 1991
Matthew Turk and Alex Pentland. Eigenfaces for recognition.Journal of Cognitive Neuro- science, 3(1):71–86, 1991. doi: 10.1162/jocn.1991.3.1.71. 1
-
[46]
Gas sensor array drift at different concentrations
Alexander Vergara. Gas sensor array drift at different concentrations. UCI Machine Learning Repository, 2012. Dataset. 9, 36
2012
-
[47]
Alexander Vergara, Shankar Vembu, Tuba Ayhan, Margie A. Ryan, Margie L. Homer, and Ramón Huerta. Chemical gas sensor drift compensation using classifier ensembles.Sensors and Actuators B: Chemical, 166–167:320–329, 2012. doi: 10.1016/j.snb.2012.01.074. 9 12
-
[48]
Semiparametric partial common principal component analysis for covariance matrices.Biometrics, 77(4):1175–1186, 2021
Bingkai Wang, Xi Luo, Yi Zhao, and Brian Caffo. Semiparametric partial common principal component analysis for covariance matrices.Biometrics, 77(4):1175–1186, 2021. doi: 10.1111/ biom.13369. 15
2021
-
[49]
Provable domain generalization via invariant- feature subspace recovery
Haoxiang Wang, Haozhe Si, Bo Li, and Han Zhao. Provable domain generalization via invariant- feature subspace recovery. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 23...
2022
-
[50]
Zhenyu Wang, Molei Liu, Jing Lei, Francis Bach, and Zijian Guo. StablePCA: Distribu- tionally robust learning of shared representations from multi-source data.arXiv preprint arXiv:2505.00940, 2025. 1, 15
arXiv 2025
-
[51]
Wright, Peter B
Ian J. Wright, Peter B. Reich, Mark Westoby, David D. Ackerly, Zdravko Baruch, et al. The worldwide leaf economics spectrum.Nature, 428(6985):821–827, 2004. doi: 10.1038/ nature02403. 1
2004
-
[52]
Yi Yu, Tengyao Wang, and Richard J. Samworth. A useful variant of the Davis–Kahan theorem for statisticians.Biometrika, 102(2):315–323, 2015. doi: 10.1093/biomet/asv008. 22 13 Contents of the Appendix A Further related work 14 A.1 Multi-domain dimension reduction . . . . . . . . . . . . . . . . . . . . . . . . . . 14 A.2 Invariance for prediction . . . . ...
-
[53]
, up)∈R p×p and split its columns into S:= (u 1,
Invariant subspace.We draw a Haar orthogonal matrix U= (u 1, . . . , up)∈R p×p and split its columns into S:= (u 1, . . . , um), R:= (u m+1, . . . , up), so that S is an orthonormal basis of S⋆ := Im(S) and R is an orthonormal basis of S ⊥ ⋆ . The remaining construction works inR-coordinates insideS ⊥ ⋆
-
[54]
standard Gaussian entries, take the Q factor of its reduced QR decomposition to obtain an orthonormal matrix He ∈R d×q, and set Be :=RH e
Bottom subspace per domain.For each domain e∈ E , we draw a bottom subspace of dimension q inside S ⊥ ⋆ : sample a d×q matrix with i.i.d. standard Gaussian entries, take the Q factor of its reduced QR decomposition to obtain an orthonormal matrix He ∈R d×q, and set Be :=RH e. If the resulting collection (B1, . . . , BE) does not jointly span S ⊥ ⋆ , we di...
-
[55]
Let Ge ∈R d×(k−m) be an orthonormal basis of ker(H⊤ e ) and setC e :=RG e
Top subspace per domain.The remaining k−m top directions in domain e∈ E lie in the complement of Be inside S ⊥ ⋆ . Let Ge ∈R d×(k−m) be an orthonormal basis of ker(H⊤ e ) and setC e :=RG e. The top-keigenspace for alle∈ Eis then Ue := Im(S, Ce) =S ⋆ ⊕Im(C e). By construction,T e∈E Ue =T e∈E Im(Be)⊥ = S e∈E Im(Be) ⊥ = (S ⊥ ⋆ )⊥ =S ⋆. For alle∈ E, given the...
2000
-
[56]
Small-E configuration: (E, p, k, m) = (2,8,5,2) shown in Fig. 7. This configuration uses the minimal feasible invariant dimension. Indeed, since each domain has a q=p−k= 3 dimensional bottom space and the bottom spaces must spanS ⊥ ⋆ , feasibility requires p−m≤Eq,equivalentlym≥p−E(p−k) = 2. D.3.4 Recovering the invariant subspaceS ⋆ We now repeat the expe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.