Towards One-to-Many Temporal Grounding
Pith reviewed 2026-06-28 02:09 UTC · model grok-4.3
The pith
A new benchmark, 56k dataset, and caption rewards let models localize multiple disjoint video segments for one query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
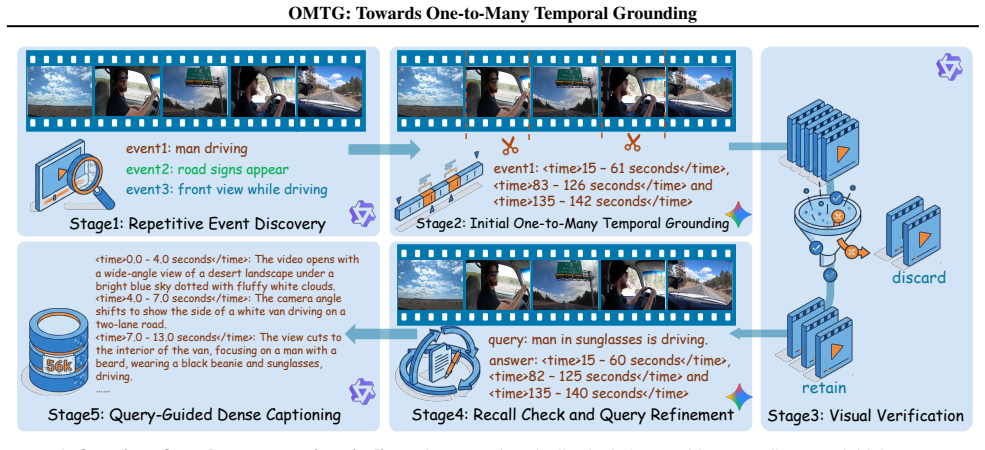
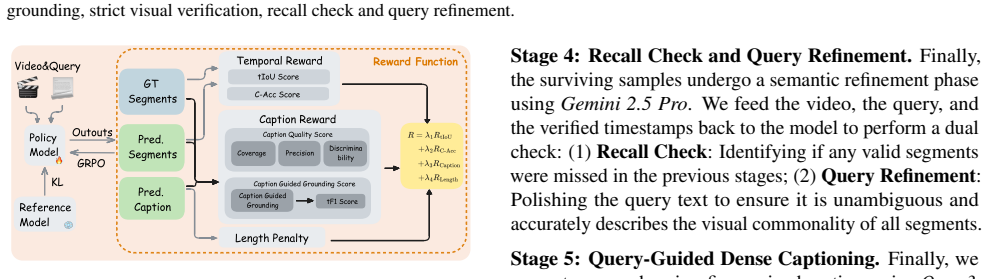
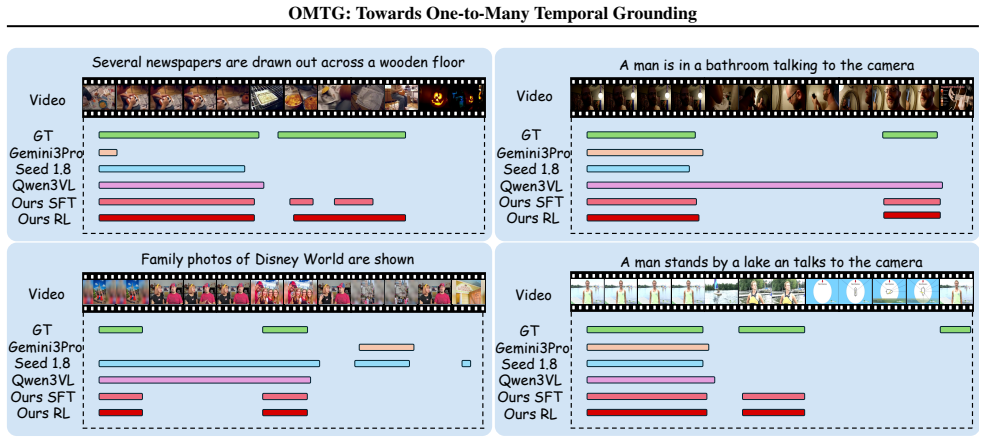
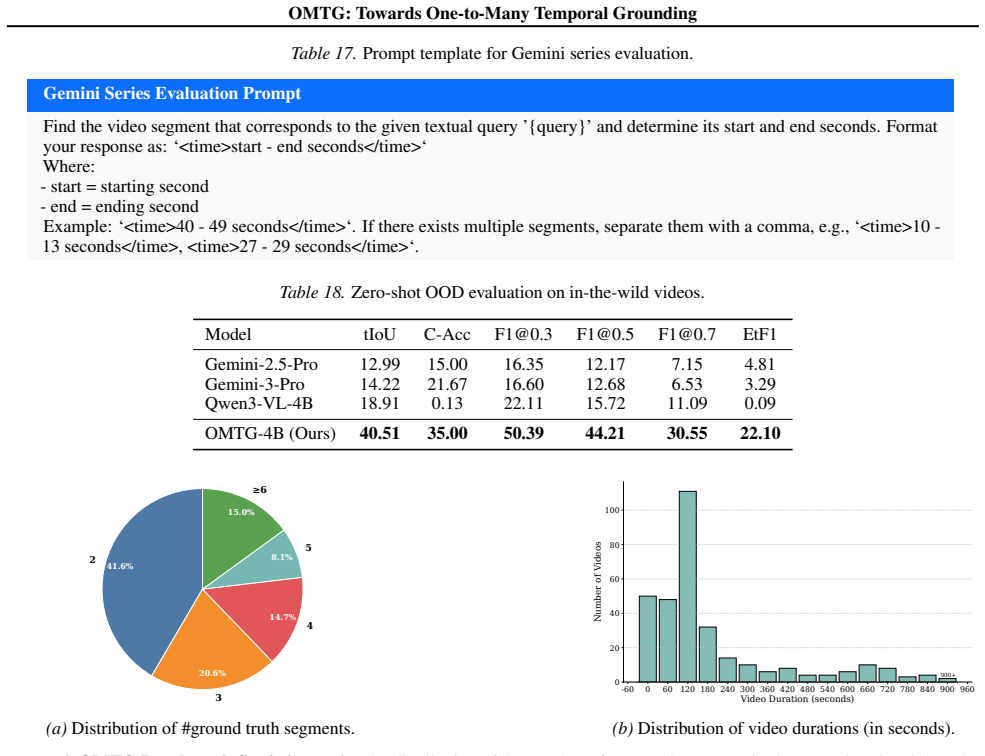
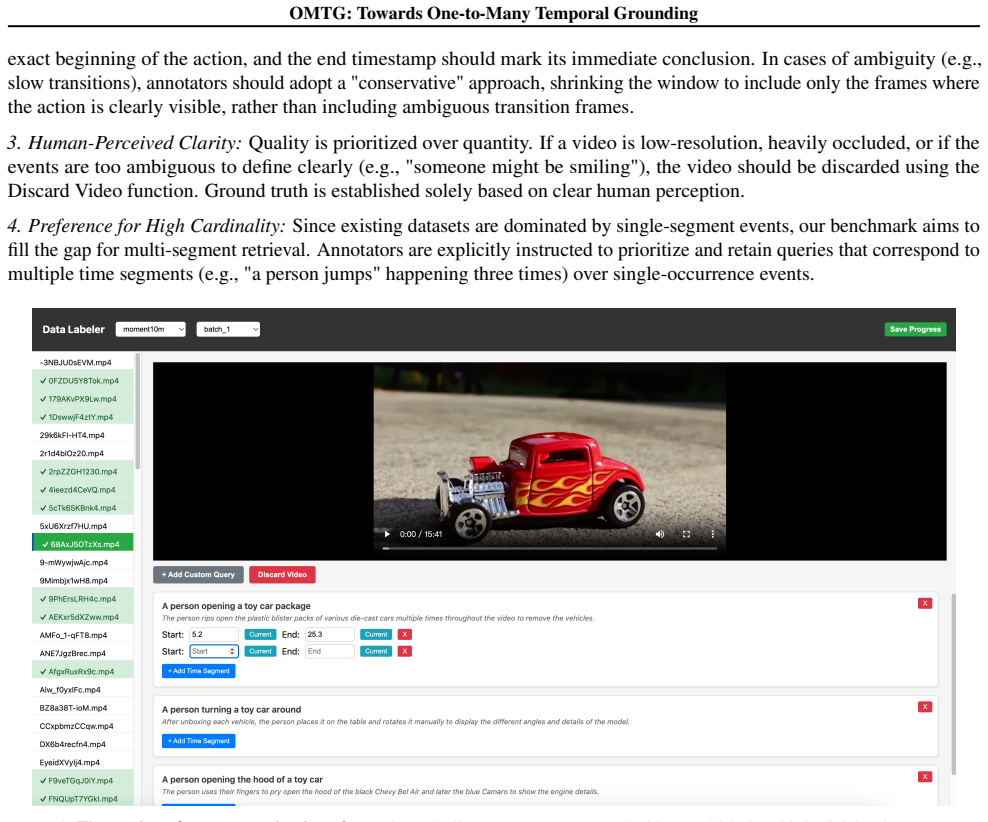
We establish the one-to-many temporal grounding task and supply a complete solution: the first OMTG benchmark, a 56k-sample dataset built through a sophisticated construction pipeline, and novel temporal plus caption reward functions, where the caption reward uses Chain-of-Thought reasoning over dense video captions to steer optimization toward both preciseness and completeness, reaching 43.65% EtF1.
What carries the argument
Caption reward function that applies Chain-of-Thought reasoning over dense video captions to guide policy optimization for both preciseness and completeness.
If this is right
- One-to-one temporal grounding methods are insufficient once queries require multiple disjoint segments.
- Explicit cardinality perception must be trained through rewards that penalize both missing events and incorrect boundaries.
- Chain-of-thought reasoning inside the reward can simultaneously enforce precision on segment boundaries and completeness across all matching events.
- Large curated datasets are required to move MLLMs from near-zero to usable performance on this task.
Where Pith is reading between the lines
- The same caption-reward pattern could be tested on other cardinality-sensitive tasks such as counting repeated actions across long videos.
- The benchmark construction steps may transfer to audio or 3D scene data where one description maps to several disjoint intervals.
- Models trained this way might improve downstream applications like video editing or surveillance query systems that naturally involve multiple matching clips.
Load-bearing premise
The 56k-sample dataset construction pipeline and the C-Acc/EtF1 metrics accurately reflect real-world one-to-many scenarios without systematic bias from the curation choices or metric definitions.
What would settle it
If models trained with the new rewards show no gain over standard fine-tuning when evaluated on a fresh set of human-annotated one-to-many queries drawn from sources outside the curation pipeline, the performance claim would be falsified.
Figures



read the original abstract
Temporal Grounding (TG) aims to localize video segments corresponding to a textual query. Prior research predominantly focuses on single-segment retrieval. Real-world scenarios, however, often require localizing multiple disjoint segments for a single query -- a setting we term One-to-Many Temporal Grounding (OMTG). Previous state-of-the-art MLLMs, optimized for one-to-one settings, struggle in this context, often yielding near-zero scores due to a lack of event cardinality perception. To bridge this gap, we present a systematic solution with three key contributions. First, we establish the first comprehensive OMTG benchmark, introducing Count Accuracy (C-Acc) and Effective Temporal F1 (EtF1) as evaluation metrics. Second, we curate a high-quality OMTG dataset comprising 56k samples through a sophisticated construction pipeline. Third, we develop novel temporal and caption reward functions specifically designed for OMTG. In particular, the caption reward leverages Chain-of-Thought reasoning over dense video captions to explicitly guide policy optimization toward both preciseness and completeness. Extensive experiments show our model achieves a new state-of-the-art EtF1 of 43.65\% on OMTG Bench, outperforming Gemini 2.5 Pro and Seed-1.8 by 15.85\% and 15.61\%, respectively. Project Page: https://insomniaaac.github.io/OMTG/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces One-to-Many Temporal Grounding (OMTG), a task requiring localization of multiple disjoint video segments for one textual query. It establishes the first OMTG benchmark with new metrics Count Accuracy (C-Acc) and Effective Temporal F1 (EtF1), curates a 56k-sample dataset through a sophisticated construction pipeline, and proposes novel temporal and caption reward functions (the latter using Chain-of-Thought reasoning over dense captions) for policy optimization of MLLMs. Experiments report a new SOTA EtF1 of 43.65% on OMTG Bench, outperforming Gemini 2.5 Pro and Seed-1.8 by 15.85% and 15.61%.
Significance. If the new benchmark and metrics prove free of systematic curation or definition bias and accurately reflect real-world multi-event scenarios, the work would meaningfully extend temporal grounding beyond one-to-one settings. The caption reward with explicit CoT guidance for preciseness and completeness represents a targeted technical contribution. The 56k-sample dataset and benchmark release would provide a useful resource for the community.
major comments (2)
- [Abstract] Abstract: The headline SOTA claim (43.65% EtF1, +15.85% over Gemini 2.5 Pro) depends entirely on the newly introduced OMTG Bench, C-Acc/EtF1 metrics, and 56k-sample dataset. The abstract supplies no experimental details, ablation studies, error analysis, or validation that the construction pipeline and metric definitions avoid systematic bias in segment selection, annotation, or scoring. This is load-bearing for the central claim.
- [Abstract] Abstract / Experiments: No evidence is provided that the new metrics were validated against human judgments or existing one-to-many annotations, nor are ablations shown for the temporal vs. caption reward components. Without these, the performance gains cannot be attributed to the proposed method rather than benchmark-specific artifacts.
minor comments (1)
- [Abstract] The abstract introduces 'EtF1' and 'C-Acc' without an upfront definition or reference to their precise formulas, which should appear in the first paragraph where the metrics are named.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline SOTA claim (43.65% EtF1, +15.85% over Gemini 2.5 Pro) depends entirely on the newly introduced OMTG Bench, C-Acc/EtF1 metrics, and 56k-sample dataset. The abstract supplies no experimental details, ablation studies, error analysis, or validation that the construction pipeline and metric definitions avoid systematic bias in segment selection, annotation, or scoring. This is load-bearing for the central claim.
Authors: We agree the abstract is highly condensed. The full paper details the construction pipeline (Section 3), metric definitions with bias-mitigation rationale (Section 4), and experiments with ablations plus error analysis (Section 5). We will revise the abstract to briefly note the pipeline validation steps and key ablation outcomes supporting the SOTA result. revision: yes
-
Referee: [Abstract] Abstract / Experiments: No evidence is provided that the new metrics were validated against human judgments or existing one-to-many annotations, nor are ablations shown for the temporal vs. caption reward components. Without these, the performance gains cannot be attributed to the proposed method rather than benchmark-specific artifacts.
Authors: Metrics extend standard IoU-based F1 and cardinality measures; dataset construction included multi-round human verification. We will add an explicit subsection on metric design rationale and any available validation evidence. Ablations comparing reward components appear in the experiments; we will highlight them more clearly with cross-references and expand discussion of their incremental contributions. revision: partial
Circularity Check
No significant circularity; new benchmark, metrics, and rewards presented as independent contributions
full rationale
The paper introduces an original OMTG benchmark, C-Acc/EtF1 metrics, 56k-sample dataset via a described construction pipeline, and custom reward functions without any derivation that reduces by construction to fitted parameters, self-citations, or prior ansatzes from the same authors. The reported EtF1 score is an empirical result on the newly defined benchmark rather than a statistical prediction forced by the input data or metric definitions. No self-definitional loops, fitted-input predictions, or load-bearing self-citation chains appear in the provided text. The central claims rest on external model comparisons and the novelty of the OMTG setting, which are self-contained against the paper's own contributions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE international conference on computer vision , pages=
Tall: Temporal activity localization via language query , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[2]
Proceedings of the IEEE international conference on computer vision , pages=
Dense-captioning events in videos , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[3]
Advances in Neural Information Processing Systems , volume=
Detecting moments and highlights in videos via natural language queries , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
arXiv preprint arXiv:2401.00849 , year=
Cosmo: Contrastive streamlined multimodal model with interleaved pre-training , author=. arXiv preprint arXiv:2401.00849 , year=
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vtimellm: Empower llm to grasp video moments , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[6]
Proceedings of the 41st International Conference on Machine Learning , pages=
Momentor: advancing video large language model with fine-grained temporal reasoning , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[7]
arXiv preprint arXiv:2512.14698 , year=
TimeLens: Rethinking Video Temporal Grounding with Multimodal LLMs , author=. arXiv preprint arXiv:2512.14698 , year=
-
[8]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[9]
arXiv preprint arXiv:2501.00574 , year=
Videochat-flash: Hierarchical compression for long-context video modeling , author=. arXiv preprint arXiv:2501.00574 , year=
-
[10]
arXiv preprint arXiv:2504.06958 , year=
Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning , author=. arXiv preprint arXiv:2504.06958 , year=
-
[11]
arXiv preprint arXiv:2503.13377 , year=
Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding , author=. arXiv preprint arXiv:2503.13377 , year=
-
[12]
5-vl technical report , author=
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[13]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[14]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[15]
Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages =
Rasley, Jeff and Rajbhandari, Samyam and Ruwase, Olatunji and He, Yuxiong , title =. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages =. 2020 , doi =
2020
-
[16]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[17]
arXiv preprint arXiv:2506.18883 , year=
Universal Video Temporal Grounding with Generative Multi-modal Large Language Models , author=. arXiv preprint arXiv:2506.18883 , year=
-
[18]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[19]
arXiv preprint arXiv:2410.19702 , year=
Timesuite: Improving mllms for long video understanding via grounded tuning , author=. arXiv preprint arXiv:2410.19702 , year=
-
[20]
5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception , author=
Videochat-r1. 5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception , author=. arXiv preprint arXiv:2509.21100 , year=
-
[21]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Univtg: Towards unified video-language temporal grounding , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[22]
arXiv preprint arXiv:2412.00811 , year=
Vid-Morp: Video Moment Retrieval Pretraining from Unlabeled Videos in the Wild , author=. arXiv preprint arXiv:2412.00811 , year=
-
[23]
2024 , eprint=
HawkEye: Training Video-Text LLMs for Grounding Text in Videos , author=. 2024 , eprint=
2024
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Man: Moment alignment network for natural language moment retrieval via iterative graph adjustment , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Query-dependent video representation for moment retrieval and highlight detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[26]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Timechat: A time-sensitive multimodal large language model for long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[28]
arXiv preprint arXiv:2410.05643 , year=
Trace: Temporal grounding video llm via causal event modeling , author=. arXiv preprint arXiv:2410.05643 , year=
-
[29]
arXiv preprint arXiv:2503.13444 , year=
VideoMind: A Chain-of-LoRA Agent for Long Video Reasoning , author=. arXiv preprint arXiv:2503.13444 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Self-chained image-language model for video localization and question answering , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
arXiv preprint arXiv:2411.14505 , year=
Llava-mr: Large language-and-vision assistant for video moment retrieval , author=. arXiv preprint arXiv:2411.14505 , year=
-
[32]
European Conference on Computer Vision , pages=
Training-free video temporal grounding using large-scale pre-trained models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[33]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Question-answering dense video events , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[34]
Naval research logistics quarterly , volume=
The Hungarian method for the assignment problem , author=. Naval research logistics quarterly , volume=. 1955 , publisher=
1955
-
[35]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[36]
arXiv preprint arXiv:2401.06066 , year=
DeepSeek-R1: Incentivizing Reasoning Capability in Large Language Models , author=. arXiv preprint arXiv:2401.06066 , year=
-
[37]
arXiv preprint arXiv:2303.08774 , year=
GPT-4 Technical Report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[38]
arXiv preprint arXiv:2503.21776 , year=
Video-R1: Reinforcing Video Reasoning in Multimodal Large Language Models , author=. arXiv preprint arXiv:2503.21776 , year=
-
[39]
arXiv preprint arXiv:2304.08485 , year=
Visual Instruction Tuning , author=. arXiv preprint arXiv:2304.08485 , year=
-
[40]
arXiv preprint arXiv:2301.12597 , year=
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models , author=. arXiv preprint arXiv:2301.12597 , year=
-
[41]
arXiv preprint arXiv:2204.14198 , year=
Flamingo: a Visual Language Model for Few-Shot Learning , author=. arXiv preprint arXiv:2204.14198 , year=
-
[42]
arXiv preprint arXiv:2306.02858 , year=
Video-llama: An instruction-tuned audio-visual language model for video understanding , author=. arXiv preprint arXiv:2306.02858 , year=
-
[43]
Science China Information Sciences , volume=
Videochat: Chat-centric video understanding , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[44]
arXiv preprint arXiv:2503.05132 , year=
R1-Zero's ``Aha Moment'' in Visual Reasoning on a 2B Non-SFT Model , author=. arXiv preprint arXiv:2503.05132 , year=
-
[45]
arXiv preprint arXiv:2503.18013 , year=
Vision-R1: Evolving Human-Free Alignment in Large Vision-Language Models via Vision-Guided Reinforcement Learning , author=. arXiv preprint arXiv:2503.18013 , year=
-
[46]
arXiv preprint arXiv:2503.07065 , year=
Boosting the Generalization and Reasoning of Vision-Language Models with Curriculum Reinforcement Learning , author=. arXiv preprint arXiv:2503.07065 , year=
-
[47]
arXiv preprint arXiv:2503.01785 , year=
Visual-RFT: Visual Reinforcement Fine-Tuning , author=. arXiv preprint arXiv:2503.01785 , year=
-
[48]
arXiv preprint arXiv:2503.10615 , year=
R1-OneVision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization , author=. arXiv preprint arXiv:2503.10615 , year=
-
[49]
arXiv preprint arXiv:2503.12937 , year=
R1-VL: Learning to Reason with Multimodal Large Language Models via Step-Wise Group Relative Policy Optimization , author=. arXiv preprint arXiv:2503.12937 , year=
-
[50]
arXiv preprint arXiv:2510.20579 , year=
Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence , author=. arXiv preprint arXiv:2510.20579 , year=
-
[51]
arXiv preprint arXiv:2506.07971 , year=
CyberV: Cybernetics for Test-time Scaling in Video Understanding , author=. arXiv preprint arXiv:2506.07971 , year=
-
[52]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[53]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[54]
2025 , month=
Introducing. 2025 , month=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.