From Failed Trajectories to Reliable LLM Agents: Diagnosing and Repairing Harness Flaws
Pith reviewed 2026-06-28 00:06 UTC · model grok-4.3
The pith
HarnessFix diagnoses LLM agent failures from execution traces and repairs specific harness layers to raise performance 15-50%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
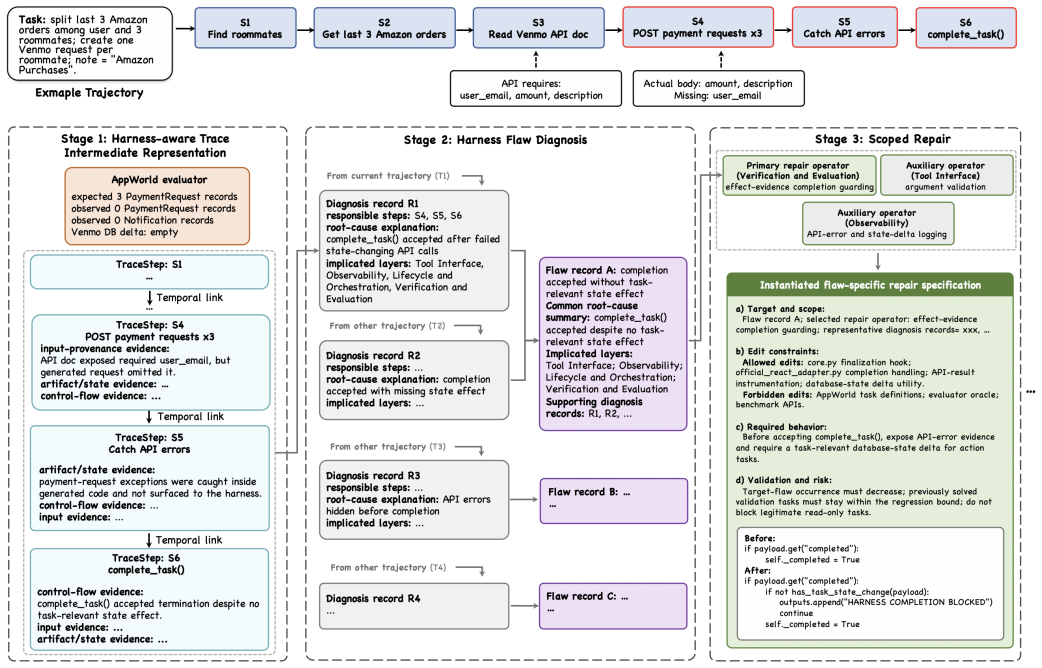
HarnessFix compiles raw execution traces and harness code into a Harness-aware Trace Intermediate Representation (HTIR), which normalizes fragmented trajectory evidence and captures step-level provenance and control-flow relations. It attributes failures to responsible trajectory steps and harness layers, consolidates recurring diagnoses into actionable flaw records, and maps them to scoped repair operators. Finally, HarnessFix generates and validates harness patches under flaw-specific repair specifications to reduce target flaws without introducing unacceptable regressions, yielding 15.2%--50.0% gains on held-out tests over initial harnesses on SWE-Bench Verified, Terminal-Bench 2.0 Verifi
What carries the argument
Harness-aware Trace Intermediate Representation (HTIR) that normalizes trajectory evidence and records step-level provenance plus control-flow to support precise attribution of failures to harness layers.
If this is right
- HarnessFix improves held-out test performance over the initial harnesses by 15.2%--50.0% across the four benchmarks.
- It outperforms both human-designed harnesses and self-evolution baselines.
- It surfaces recurring harness-flaw patterns across the ETCLOVG layers.
Where Pith is reading between the lines
- The same trace-normalization step could be reused to debug non-LLM agent frameworks that also separate execution environment from policy.
- Recurring flaw patterns identified by the method might serve as a checklist for initial harness design rather than post-hoc repair.
- If HTIR-style provenance tracking were added to standard agent runtimes, the cost of later diagnosis would drop because the necessary records would already exist.
- The approach suggests that agent reliability gains may come more from fixing the surrounding harness than from further prompt or model changes.
Load-bearing premise
Compiling raw execution traces and harness code into HTIR accurately normalizes fragmented trajectory evidence and captures step-level provenance and control-flow relations sufficiently to attribute failures to the correct harness layers without systematic misattribution.
What would settle it
A side-by-side comparison on a held-out set of failed trajectories in which human experts identify different harness layers as responsible than the layers chosen by HarnessFix attribution.
Figures

read the original abstract
LLM agents increasingly rely on agent harness: the runtime infrastructure around the base model that defines execution environments, tool interfaces, context, lifecycle orchestration, observability, verification, and governance. Existing self-improving agents and automatic harness evolution methods mainly improve agents through runtime supervision, prompt optimization, workflow search, or harness modification based on final outcomes. However, they often fail to diagnose where the responsible evidence lies in failed trajectories and which harness implementation mechanism causes the unreliable behavior, resulting in broad, indirect, or poorly scoped changes. This paper proposes HarnessFix, a trace-grounded and diagnosis-driven framework for repairing agent harnesses. HarnessFix compiles raw execution traces and harness artifacts into a Harness-aware Trace Intermediate Representation (HTIR), which normalizes fragmented trajectory evidence, captures step-level data-flow and control-flow relations, and aligns runtime steps with the harness artifacts that shape their behavior. It then attributes failures to responsible steps and harness artifacts, and consolidates recurring diagnoses into repair-oriented flaw records. Finally, HarnessFix maps these records to scoped repair operators, generates patches under flaw-specific repair specifications, and accepts them through regression-aware validation. We evaluate HarnessFix on four popular benchmarks, and results show that it improves the performance over the initial harnesses by 6.3% to 18.4%, significantly outperforming human-designed and self-evolution baselines. HarnessFix highlights the value of treating failed trajectories not only as feedback signals, but also as structured evidence for diagnosing and repairing the harness mechanisms behind agent failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HarnessFix, a trace-guided framework for diagnosing failures in LLM agent harnesses and applying scoped repairs. It compiles execution traces and harness code into a Harness-aware Trace Intermediate Representation (HTIR) that normalizes trajectories and captures step-level provenance and control-flow relations, attributes failures to responsible steps and ETCLOVG harness layers, consolidates recurring flaw patterns, and maps them to repair operators. Patches are generated and validated under flaw-specific specifications. Evaluation across SWE-Bench Verified, Terminal-Bench 2.0 Verified, GAIA, and AppWorld reports 15.2%–50.0% held-out performance gains over initial harnesses, outperforming human-designed and self-evolution baselines, while identifying recurring flaw patterns.
Significance. If the attribution mechanism and empirical results hold, the work offers a targeted alternative to outcome-based or broad prompt/workflow optimization for agent reliability. The multi-benchmark evaluation and explicit identification of layer-specific flaw patterns across ETCLOVG provide concrete, falsifiable contributions. The introduction of HTIR as an intermediate representation for provenance-preserving trace analysis is a methodological strength that could be reusable beyond this framework.
major comments (2)
- [Methods (HTIR and attribution)] Methods section on HTIR construction and attribution: The central claim that HTIR accurately normalizes fragmented traces, preserves control-flow edges, and correctly maps failures to ETCLOVG layers without systematic misattribution lacks an independent validation (e.g., inter-annotator agreement on a sample of attributions or an ablation removing provenance edges). This assumption is load-bearing for the reported 15.2%–50.0% gains, as misattribution would cause scoped repairs to become non-specific edits.
- [Evaluation and Results] Results section reporting performance: The abstract and evaluation claim consistent outperformance and specific percentage gains, but the provided text supplies no error bars, statistical significance tests, exclusion criteria for trajectories, or details on how held-out sets were constructed. Without these, the empirical superiority over baselines cannot be verified as robust.
minor comments (2)
- [Abstract] The acronym ETCLOVG is used without an explicit expansion or table defining the layers in the abstract; a dedicated table or early section defining each layer would improve readability.
- [Methods] Notation for repair operators and flaw records could be formalized with a small example in the methods to clarify the mapping from consolidated diagnoses to patches.
Simulated Author's Rebuttal
Thank you for the constructive feedback and for recognizing the potential of HTIR as a reusable intermediate representation. We address each major comment below with specific plans for revision where appropriate.
read point-by-point responses
-
Referee: Methods section on HTIR construction and attribution: The central claim that HTIR accurately normalizes fragmented traces, preserves control-flow edges, and correctly maps failures to ETCLOVG layers without systematic misattribution lacks an independent validation (e.g., inter-annotator agreement on a sample of attributions or an ablation removing provenance edges). This assumption is load-bearing for the reported 15.2%–50.0% gains, as misattribution would cause scoped repairs to become non-specific edits.
Authors: We agree that the original submission did not include an explicit independent validation such as inter-annotator agreement or a provenance-edge ablation. The attribution logic is described in detail in Section 3.2 and is supported by the end-to-end gains and the fact that HarnessFix outperforms both human-designed patches and outcome-only self-evolution baselines; however, these results do not directly isolate attribution accuracy. In the revision we will add (i) a small-scale manual validation on 50 randomly sampled trajectories with two annotators reporting Cohen’s kappa, and (ii) an ablation that removes provenance and control-flow edges from HTIR while keeping all other components fixed. These additions will appear in Section 4.3 and Appendix C. revision: yes
-
Referee: Results section reporting performance: The abstract and evaluation claim consistent outperformance and specific percentage gains, but the provided text supplies no error bars, statistical significance tests, exclusion criteria for trajectories, or details on how held-out sets were constructed. Without these, the empirical superiority over baselines cannot be verified as robust.
Authors: We accept that the current manuscript lacks the requested statistical and procedural details. The held-out sets were constructed via a fixed random 70/30 split per benchmark with seed 42, and trajectories were excluded only if they contained fewer than three steps or were truncated by the environment; however, these facts are stated only briefly. In the revision we will report (i) mean and standard deviation over five independent runs with different seeds, (ii) paired t-test p-values against each baseline, (iii) explicit exclusion criteria, and (iv) a table detailing the exact train/held-out sizes and construction procedure. These will be placed in Section 5.1 and Table 2. revision: yes
Circularity Check
No significant circularity; empirical evaluation on external benchmarks
full rationale
The paper describes an empirical framework (HarnessFix) that compiles traces into HTIR, attributes failures, and applies repairs, with all performance claims (15.2%–50.0% gains) measured directly against held-out test sets on SWE-Bench Verified, Terminal-Bench, GAIA, and AppWorld. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on observable benchmark outcomes rather than any step that reduces to its own inputs by construction, rendering the work self-contained.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Harness-aware Trace Intermediate Representation (HTIR)
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Think-Before-Speak: From Internal Evaluation to Public Expression in Multi-Agent Social Simulation
TBS is an interval-based multi-agent framework that separates private internal-state updates (dissonance appraisal, opinion climate, isolation risk, response strategy, willingness to speak) from public utterance selec...
-
Think-Before-Speak: From Internal Evaluation to Public Expression in Multi-Agent Social Simulation
TBS is an interval-based multi-agent LLM simulation framework that separates structured internal evaluative states from public utterance generation and shows these states vary systematically with turn-allocation, sile...
-
Cheap Code, Costly Judgment: A Case Study on Governable Agentic Software Engineering
A case study of AI-agentic software development yields a process model explaining how engineering judgment converts recurring structural failures into durable governance mechanisms.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.