Double Preconditioning (DoPr): Optimization for Test-Time Performance, not Validation Loss
Pith reviewed 2026-06-28 02:31 UTC · model grok-4.3
The pith
Adding activation-wise preconditioning to standard optimizers improves downstream performance in test-time feedback settings even when validation loss stays flat.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
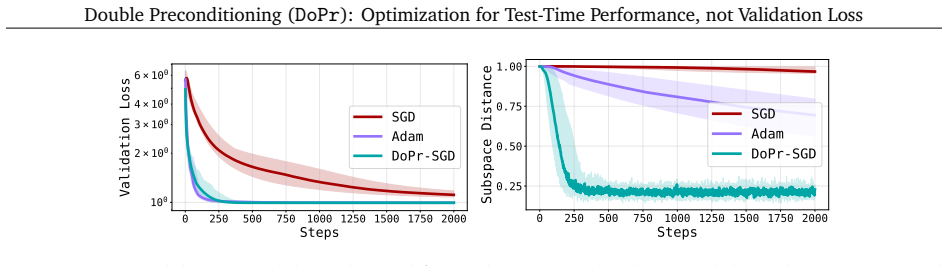
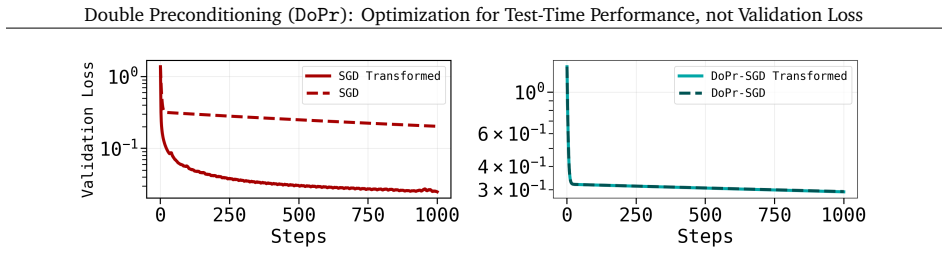
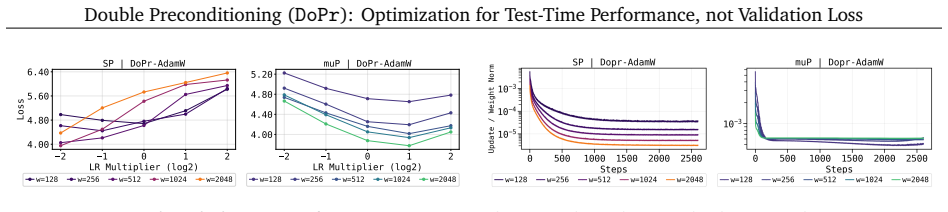
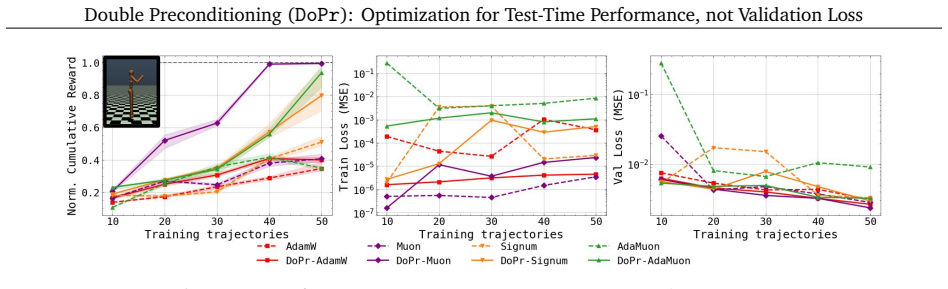
We introduce a new optimization paradigm called double-preconditioning (DoPr) that combines gradient-wise preconditioning with activation-wise preconditioning. We show that the addition of AP yields a drop-in intervention for increasing downstream model performance across a range of TTF settings. Interestingly, these gains in test-time performance do not consistently accompany improvements in validation loss, opening new questions about how to properly evaluate models trained with one-step supervised objectives.
What carries the argument
Double-preconditioning (DoPr), which augments gradient-wise preconditioners with activation-wise preconditioning (AP) such as KFAC to target error accumulation during test-time rollouts.
If this is right
- DoPr can be inserted into existing training pipelines for autoregressive language models, flow-based generators, and robot policies without altering the loss or architecture.
- Downstream metrics such as task success rate and generation quality rise while the one-step validation loss often remains unchanged.
- Optimization choices become a distinct lever for mitigating train-test mismatch in sequential deployment, alongside data curation and objective design.
- Evaluation protocols for one-step supervised models should track rollout quality separately from validation loss.
Where Pith is reading between the lines
- Standard validation loss may be an incomplete signal for model selection when deployment involves long iterative predictions.
- Activation-wise statistics appear to encode information that stabilizes iterative outputs beyond what gradient preconditioning alone captures.
- The method could be tested on longer rollout horizons or on tasks with explicit compounding noise to measure how far the benefit extends.
Load-bearing premise
The reported gains in downstream metrics are caused by the addition of activation-wise preconditioning rather than by differences in hyperparameter tuning, implementation details, or dataset-specific effects.
What would settle it
A controlled comparison in which the only change is the addition of activation-wise preconditioning, with all other hyperparameters and code paths held fixed, shows no consistent lift in downstream TTF metrics across multiple tasks.
Figures






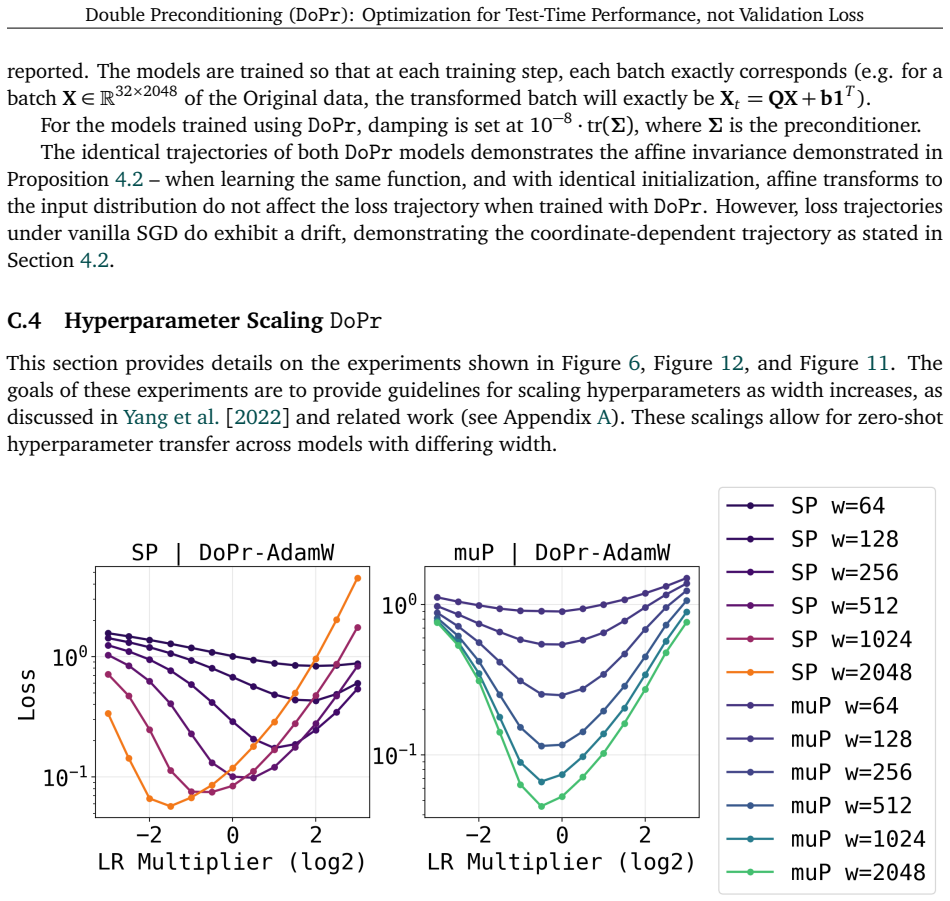
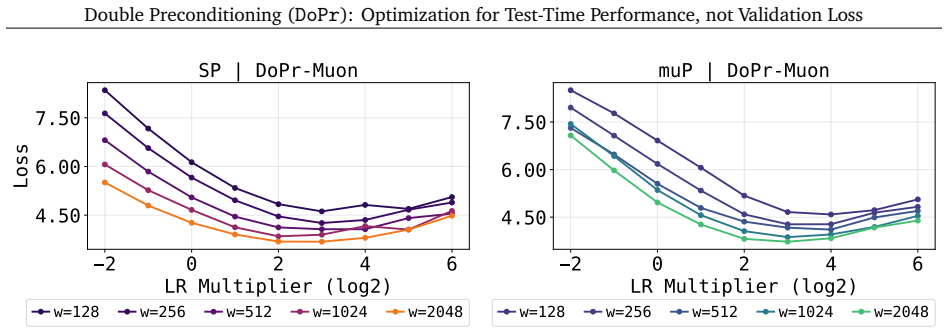








read the original abstract
Many modern applications of deep learning involve training a neural network via a one-step prediction loss (e.g., $L^2$ regression, cross-entropy), but deploy the network by rolling out along its own predictions. Key examples include autoregressive language modeling, flow-based generative modeling, and robot policy learning. It is well-documented that these settings induce a phenomenon we call test-time feedback (TTF): the mismatch between the training/validation loss and downstream metrics of interest, such as task success rate and generation quality, which grows with task length. While data curation, architecture, and objective design have been proposed to combat train-test shift in TTF settings, this paper proposes optimization as a new design axis to mitigate error accumulation. Specifically, we introduce a new optimization paradigm called double-preconditioning (DoPr) uniquely tailored to the challenges of TTF. DoPr combines gradient-wise preconditioning, as in Adam and Muon, with activation-wise preconditioning (AP), such as in KFAC. We show that the addition of AP yields a drop-in intervention for increasing downstream model performance across a range of TTF settings. Interestingly, these gains in test-time performance do not consistently accompany improvements in validation loss, opening new questions about how to properly evaluate models trained with one-step supervised objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces double preconditioning (DoPr), which combines gradient-wise preconditioning (e.g., Adam, Muon) with activation-wise preconditioning (AP, e.g., KFAC), as a method to improve downstream performance in test-time feedback (TTF) settings like autoregressive language modeling, flow-based generative modeling, and robot policy learning. It claims that adding AP acts as a drop-in intervention to boost task success rate and generation quality, even when validation loss does not improve, suggesting optimization as a new design axis beyond data, architecture, and objectives.
Significance. If the empirical gains are robustly demonstrated and attributable to the activation-wise component, this work would be significant for providing an optimization-based approach to mitigate error accumulation in TTF settings. It would also highlight limitations in using validation loss for evaluating models trained with one-step objectives, potentially influencing training practices in sequential prediction tasks.
major comments (2)
- [Abstract] Abstract: The central claim that 'the addition of AP yields a drop-in intervention for increasing downstream model performance across a range of TTF settings' is presented without any experiment details, baselines, statistical tests, ablation results, or controls for hyperparameter tuning effort. This makes it impossible to assess whether the gains are caused by AP or by unequal tuning budgets or implementation differences.
- [Abstract] Abstract: No specific TTF settings, models, datasets, quantitative results, or matched experimental protocols are described, preventing evaluation of the generality and magnitude of the claimed improvements or isolation of the AP effect from confounding factors.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The two major comments both concern the level of detail in the abstract. We agree that abstracts are high-level by design and will revise the abstract to incorporate more specifics on settings, results, and controls while preserving its brevity. Full experimental details, ablations, and protocols remain in the body of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the addition of AP yields a drop-in intervention for increasing downstream model performance across a range of TTF settings' is presented without any experiment details, baselines, statistical tests, ablation results, or controls for hyperparameter tuning effort. This makes it impossible to assess whether the gains are caused by AP or by unequal tuning budgets or implementation differences.
Authors: We acknowledge the abstract's conciseness omits these elements. The manuscript reports experiments across autoregressive language modeling, flow-based generative modeling, and robot policy learning, with direct comparisons to gradient-wise preconditioners (Adam, Muon) and ablations isolating the activation-wise component. Hyperparameter search budgets were matched across conditions where feasible, and results include task-success metrics with variability estimates. We will expand the abstract with one or two sentences summarizing the TTF settings and the observed dissociation between validation loss and downstream performance. revision: yes
-
Referee: [Abstract] Abstract: No specific TTF settings, models, datasets, quantitative results, or matched experimental protocols are described, preventing evaluation of the generality and magnitude of the claimed improvements or isolation of the AP effect from confounding factors.
Authors: The abstract intentionally remains high-level. Sections 4–5 of the manuscript specify the models (transformers, flow networks, policy networks), datasets, rollout lengths, and evaluation protocols, including controls that hold optimizer hyperparameters fixed except for the addition of the activation-wise preconditioner. We will revise the abstract to name the three TTF domains and note that improvements appear in downstream metrics even when validation loss is comparable. revision: yes
Circularity Check
No circularity; purely empirical claim with no derivation chain
full rationale
The paper presents no equations, derivations, or first-principles results. Its central claim—that adding activation-wise preconditioning (AP) improves downstream TTF metrics—is supported solely by experimental observations, not by any fitted parameter, self-referential definition, or self-citation chain that reduces the result to its inputs. Citations to Adam, Muon, and KFAC are to external prior work and do not bear the load of the empirical finding. The result is therefore self-contained against external benchmarks and receives the default non-circularity outcome.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2004 , publisher=
Optimal control theory: an introduction , author=. 2004 , publisher=
2004
-
[2]
Advances in Neural Information Processing Systems , volume=
TaSIL: Taylor series imitation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
International Conference on Machine Learning , pages=
Information-theoretic considerations in batch reinforcement learning , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[4]
SIAM journal on control and optimization , volume=
A Lyapunov-like characterization of asymptotic controllability , author=. SIAM journal on control and optimization , volume=. 1983 , publisher=
1983
-
[5]
arXiv preprint arXiv:2404.14367 , year=
Preference fine-tuning of llms should leverage suboptimal, on-policy data , author=. arXiv preprint arXiv:2404.14367 , year=
-
[6]
2025 , eprint=
Gymnasium: A Standard Interface for Reinforcement Learning Environments , author=. 2025 , eprint=
2025
-
[7]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[8]
arXiv preprint arXiv:1608.03983 , year=
SGDR: Stochastic gradient descent with warm restarts , author=. arXiv preprint arXiv:1608.03983 , year=
-
[9]
Proceedings of the AAAI conference on artificial intelligence , volume=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[10]
arXiv preprint arXiv:2306.06253 , year=
Decision Stacks: Flexible Reinforcement Learning via Modular Generative Models , author=. arXiv preprint arXiv:2306.06253 , year=
-
[11]
arXiv preprint arXiv:2309.08587 , year=
Compositional Foundation Models for Hierarchical Planning , author=. arXiv preprint arXiv:2309.08587 , year=
-
[12]
arXiv preprint arXiv:2205.09991 , year=
Planning with diffusion for flexible behavior synthesis , author=. arXiv preprint arXiv:2205.09991 , year=
-
[13]
arXiv preprint arXiv:2301.10677 , year=
Imitating human behaviour with diffusion models , author=. arXiv preprint arXiv:2301.10677 , year=
-
[14]
arXiv preprint arXiv:2211.15657 , year=
Is Conditional Generative Modeling all you need for Decision-Making? , author=. arXiv preprint arXiv:2211.15657 , year=
-
[15]
arXiv preprint arXiv:2303.04137 , year=
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion , author=. arXiv preprint arXiv:2303.04137 , year=
-
[16]
arXiv preprint arXiv:2304.13705 , year=
Learning fine-grained bimanual manipulation with low-cost hardware , author=. arXiv preprint arXiv:2304.13705 , year=
-
[17]
Advances in neural information processing systems , volume=
Behavior Transformers: Cloning k modes with one stone , author=. Advances in neural information processing systems , volume=
-
[18]
Advances in neural information processing systems , volume=
Decision transformer: Reinforcement learning via sequence modeling , author=. Advances in neural information processing systems , volume=
-
[19]
Neural computing and applications , volume=
Deep imitation learning for 3D navigation tasks , author=. Neural computing and applications , volume=. 2018 , publisher=
2018
-
[20]
ACM Computing Surveys (CSUR) , volume=
Imitation learning: A survey of learning methods , author=. ACM Computing Surveys (CSUR) , volume=. 2017 , publisher=
2017
-
[21]
2015 , eprint=
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
2015
-
[22]
Nature , volume=
Champion-level drone racing using deep reinforcement learning , author=. Nature , volume=. 2023 , publisher=
2023
-
[23]
2018 , eprint=
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author=. 2018 , eprint=
2018
-
[24]
Keller Jordan , title =
-
[25]
2024 , eprint=
Fast TRAC: A Parameter-Free Optimizer for Lifelong Reinforcement Learning , author=. 2024 , eprint=
2024
-
[26]
2024 , eprint=
Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training , author=. 2024 , eprint=
2024
-
[27]
2024 , url =
Keller Jordan and Jeremy Bernstein and Brendan Rappazzo and @fernbear.bsky.social and Boza Vlado and You Jiacheng and Franz Cesista and Braden Koszarsky and @Grad62304977 , title =. 2024 , url =
2024
-
[28]
2024 , eprint=
The Ingredients for Robotic Diffusion Transformers , author=. 2024 , eprint=
2024
-
[29]
arXiv preprint arXiv:2108.03298 , year=
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation , author=. arXiv preprint arXiv:2108.03298 , year=
-
[30]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[31]
2023 , eprint=
Symbolic Discovery of Optimization Algorithms , author=. 2023 , eprint=
2023
-
[32]
arXiv preprint arXiv:1604.07316 , year=
End to end learning for self-driving cars , author=. arXiv preprint arXiv:1604.07316 , year=
-
[33]
Conference on robot learning , pages=
One-shot visual imitation learning via meta-learning , author=. Conference on robot learning , pages=. 2017 , organization=
2017
-
[34]
2018 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Deep imitation learning for complex manipulation tasks from virtual reality teleoperation , author=. 2018 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2018 , organization=
2018
-
[35]
arXiv preprint arXiv:1812.03079 , year=
Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst , author=. arXiv preprint arXiv:1812.03079 , year=
-
[36]
Learning for Dynamics and Control Conference , pages=
On the sample complexity of stability constrained imitation learning , author=. Learning for Dynamics and Control Conference , pages=. 2022 , organization=
2022
-
[37]
Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=
A reduction of imitation learning and structured prediction to no-regret online learning , author=. Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=. 2011 , organization=
2011
-
[38]
Conference on robot learning , pages=
Dart: Noise injection for robust imitation learning , author=. Conference on robot learning , pages=. 2017 , organization=
2017
-
[39]
2019 International Conference on Robotics and Automation (ICRA) , pages=
Hg-dagger: Interactive imitation learning with human experts , author=. 2019 International Conference on Robotics and Automation (ICRA) , pages=. 2019 , organization=
2019
-
[40]
arXiv preprint arXiv:2303.00638 , year=
MEGA-DAgger: Imitation Learning with Multiple Imperfect Experts , author=. arXiv preprint arXiv:2303.00638 , year=
-
[41]
arXiv preprint arXiv:2106.03207 , year=
Mitigating covariate shift in imitation learning via offline data without great coverage , author=. arXiv preprint arXiv:2106.03207 , year=
-
[42]
Advances in Neural Information Processing Systems , volume=
Causal confusion in imitation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=
Efficient reductions for imitation learning , author=. Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=. 2010 , organization=
2010
-
[44]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Is Behavior Cloning All You Need? Understanding Horizon in Imitation Learning , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[45]
2003 , publisher=
On the sample complexity of reinforcement learning , author=. 2003 , publisher=
2003
-
[46]
Distributional and L^q norm inequalities for polynomials over convex bodies in
Carbery, Anthony and Wright, James , journal=. Distributional and L^q norm inequalities for polynomials over convex bodies in. 2001 , publisher=
2001
-
[47]
International conference on machine learning , pages=
How to escape saddle points efficiently , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[48]
Mathematics of Computation , volume=
Recovery of Sobolev functions restricted to iid sampling , author=. Mathematics of Computation , volume=
-
[49]
arXiv preprint cs/0408007 , year=
Online convex optimization in the bandit setting: gradient descent without a gradient , author=. arXiv preprint cs/0408007 , year=
-
[50]
Nonlinear and optimal control theory: lectures given at the CIME summer school held in Cetraro, Italy June 19--29, 2004 , pages=
Input to state stability: Basic concepts and results , author=. Nonlinear and optimal control theory: lectures given at the CIME summer school held in Cetraro, Italy June 19--29, 2004 , pages=. 2008 , publisher=
2004
-
[51]
Statistics & Probability Letters , volume=
Optimal global rates of convergence for interpolation problems with random design , author=. Statistics & Probability Letters , volume=. 2013 , publisher=
2013
-
[52]
arXiv preprint arXiv:2406.13447 , year=
High-probability minimax lower bounds , author=. arXiv preprint arXiv:2406.13447 , year=
-
[53]
2006 , publisher=
A distribution-free theory of nonparametric regression , author=. 2006 , publisher=
2006
-
[54]
Advances in Neural Information Processing Systems , year=
Provable guarantees for generative behavior cloning: Bridging low-level stability and high-level behavior , author=. Advances in Neural Information Processing Systems , year=
-
[55]
IFAC Proceedings Volumes , volume=
Uncertainty in unstable systems: the gap metric , author=. IFAC Proceedings Volumes , volume=. 1981 , publisher=
1981
-
[56]
2000 , publisher=
Empirical Processes in M-estimation , author=. 2000 , publisher=
2000
-
[57]
2019 , publisher=
High-dimensional statistics: A non-asymptotic viewpoint , author=. 2019 , publisher=
2019
-
[58]
The Thirty Seventh Annual Conference on Learning Theory , pages=
Minimax Linear Regression under the Quantile Risk , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
2024
-
[59]
Proceedings of The 7th Conference on Robot Learning , pages =
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control , author =. Proceedings of The 7th Conference on Robot Learning , pages =. 2023 , editor =
2023
-
[60]
Advances in Neural Information Processing Systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
arXiv preprint arXiv:2110.06169 , year=
Offline reinforcement learning with implicit q-learning , author=. arXiv preprint arXiv:2110.06169 , year=
-
[62]
Advances in neural information processing systems , volume=
Generative adversarial imitation learning , author=. Advances in neural information processing systems , volume=
-
[63]
International Conference on Machine Learning , pages=
Of moments and matching: A game-theoretic framework for closing the imitation gap , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[64]
arXiv preprint arXiv:2410.13855 , year=
Diffusing States and Matching Scores: A New Framework for Imitation Learning , author=. arXiv preprint arXiv:2410.13855 , year=
-
[65]
arXiv preprint arXiv:2410.24164 , year=
pi_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. arXiv preprint arXiv:2410.24164 , year=
-
[66]
arXiv preprint arXiv:2304.10573 , year=
Idql: Implicit q-learning as an actor-critic method with diffusion policies , author=. arXiv preprint arXiv:2304.10573 , year=
-
[67]
The Annals of Statistics , volume=
On nonparametric estimation of density level sets , author=. The Annals of Statistics , volume=. 1997 , publisher=
1997
-
[68]
Journal of Multivariate Analysis , volume=
Nonparametric estimation of a function from noiseless observations at random points , author=. Journal of Multivariate Analysis , volume=. 2017 , publisher=
2017
-
[69]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[70]
IEEE Transactions on Intelligent Vehicles , volume=
Motion planning for autonomous driving: The state of the art and future perspectives , author=. IEEE Transactions on Intelligent Vehicles , volume=. 2023 , publisher=
2023
-
[71]
2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Grasping with chopsticks: Combating covariate shift in model-free imitation learning for fine manipulation , author=. 2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2021 , organization=
2021
-
[72]
2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Seil: simulation-augmented equivariant imitation learning , author=. 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2023 , organization=
2023
-
[73]
International conference on machine learning , pages=
Wilds: A benchmark of in-the-wild distribution shifts , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[74]
International Conference on Machine Learning , pages=
The dormant neuron phenomenon in deep reinforcement learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[75]
arXiv preprint arXiv:2206.02126 , year=
Learning dynamics and generalization in reinforcement learning , author=. arXiv preprint arXiv:2206.02126 , year=
-
[76]
arXiv preprint arXiv:2506.15544 , year=
Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning , author=. arXiv preprint arXiv:2506.15544 , year=
-
[77]
Advances in Neural Information Processing Systems , volume=
Adam on local time: Addressing nonstationarity in rl with relative adam timesteps , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
arXiv preprint arXiv:2402.18762 , year=
Disentangling the causes of plasticity loss in neural networks , author=. arXiv preprint arXiv:2402.18762 , year=
-
[79]
International Conference on Learning Representations , year=
Kronecker-factored curvature approximations for recurrent neural networks , author=. International Conference on Learning Representations , year=
-
[80]
Advances in neural information processing systems , volume=
Scalable trust-region method for deep reinforcement learning using kronecker-factored approximation , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.