GOPAgen: Motion-Aware and Efficient Agentic Long-Video Understanding with Structural Memory and Hierarchical Reasoning
Pith reviewed 2026-06-28 06:30 UTC · model grok-4.3
The pith
A motion agent trained on video codec GOPs, paired with GOP tree reasoning and structural memory, improves long-video question answering accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
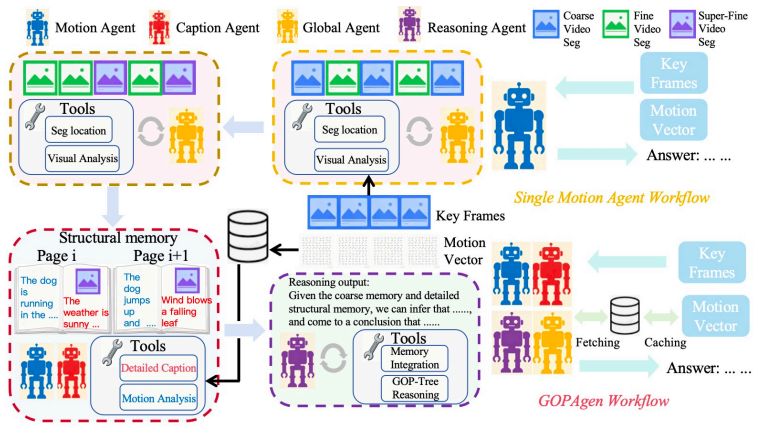
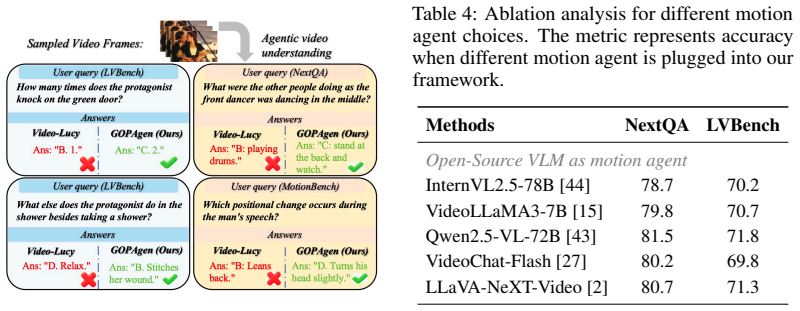
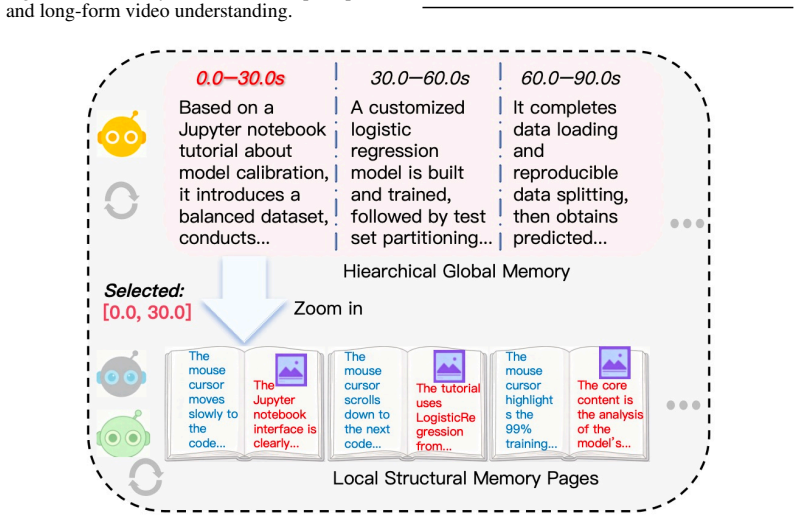
GOPAgen integrates a motion agent trained directly on GOPs from video codecs, a GOP tree reasoning algorithm aligned with video codec structures, a structural memory mechanism that places local motion information with detailed captions in structural pages, an efficient coarse-to-fine zoom-in algorithm, and a motion vector database for retrieval at different granularities, achieving superior Video Question Answering performance on benchmarks including MotionBench and Egoschema.
What carries the argument
The motion agent trained on GOP structures together with the GOP tree reasoning algorithm, which together enable detailed local motion comprehension while staying aligned with video codec formats.
If this is right
- Superior VQA scores on motion-focused benchmarks follow directly from the codec-integrated motion agent and tree reasoning.
- Structural memory combined with the zoom-in algorithm reduces the need to reprocess entire long videos for each query.
- The motion vector database enables retrieval at multiple levels of granularity without full decompression.
- Local detailed motions become accessible through the GOP tree without requiring separate optical flow computation.
Where Pith is reading between the lines
- Systems built this way could run directly on already-compressed video streams in storage or streaming pipelines.
- The same GOP-aligned structures might transfer to other temporal reasoning tasks such as action segmentation or event localization.
- Real-time video agents could gain lower latency by skipping full frame decoding when motion vectors suffice.
Load-bearing premise
Training a motion agent directly on GOP structures from standard video codecs will reliably capture detailed local motions without codec-induced artifacts or loss of information that would degrade downstream VQA accuracy.
What would settle it
Compare VQA accuracy on the same long videos when fine motion details are known to be distorted by GOP compression versus when the same model is run on uncompressed frames; if accuracy drops below non-GOP baselines the central claim is undermined.
Figures

read the original abstract
Despite significant progress in agentic long video understanding, existing methods still lack detailed motion comprehension coupled with an efficient memory architecture. In this paper, we propose GOPAgen, a novel approach that first integrates video codec into the video understanding framework via a meticulously designed motion agent trained on Groups of Pictures (GOPs) from video codec. We further develop a GOP tree reasoning algorithm, which is naturally aligned with video codec and enhances the model's ability to understand local detailed motions in videos. Additionally, we carefully design a structural memory mechanism that integrates local motion information with detailed captions in structural pages, and propose an efficient coarse-to-fine zoom-in algorithm to fully exploit the structural memory. Furthermore, we incorporate a motion vector database into the framework to enable efficient retrieval of motion vectors at different granularities. Overall, our method achieves superior Video Question Answering (VQA) performance on various video understanding benchmarks, including MotionBench and Egoschema, thereby demonstrating the superiority of our proposed framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GOPAgen, a framework for agentic long-video understanding that first trains a motion agent on Groups of Pictures (GOPs) extracted from standard video codecs, then applies a GOP tree reasoning algorithm, a structural memory mechanism that pairs local motion data with detailed captions in structural pages, a coarse-to-fine zoom-in algorithm, and a motion vector database for multi-granularity retrieval. The central claim is that this codec-aligned architecture yields superior Video Question Answering performance on benchmarks including MotionBench and Egoschema.
Significance. If the performance claims are substantiated with proper controls, the explicit use of codec GOP structures for motion extraction and hierarchical reasoning could provide a practical efficiency gain over pixel-level or frame-level agentic baselines by reusing existing compression artifacts as features rather than discarding them.
major comments (2)
- [Abstract] Abstract: the claim of 'superior' VQA performance on MotionBench and Egoschema supplies no baselines, quantitative deltas, error bars, dataset splits, or ablation results, which is load-bearing for the central empirical claim of framework superiority.
- [Method (motion agent and GOP tree reasoning)] Motion agent and GOP tree reasoning sections: the pipeline trains directly on standard codec GOPs (block-based motion vectors and lossy quantization) without any described compensation for quantization noise or sub-pixel inaccuracies; if these artifacts propagate into the structural memory, the asserted motion-awareness advantage cannot be guaranteed.
minor comments (1)
- [Abstract] Abstract: the phrase 'meticulously designed motion agent' is non-specific and should be replaced by concrete architectural or training details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'superior' VQA performance on MotionBench and Egoschema supplies no baselines, quantitative deltas, error bars, dataset splits, or ablation results, which is load-bearing for the central empirical claim of framework superiority.
Authors: We agree that the abstract would benefit from greater specificity to support the performance claim. In the revised version we will incorporate concise quantitative results (including deltas versus listed baselines), mention of dataset splits, and a reference to the ablation studies already present in the experimental section. revision: yes
-
Referee: [Method (motion agent and GOP tree reasoning)] Motion agent and GOP tree reasoning sections: the pipeline trains directly on standard codec GOPs (block-based motion vectors and lossy quantization) without any described compensation for quantization noise or sub-pixel inaccuracies; if these artifacts propagate into the structural memory, the asserted motion-awareness advantage cannot be guaranteed.
Authors: The motion agent is intentionally trained end-to-end on the native codec GOP outputs, so any quantization effects are part of the training distribution rather than post-hoc noise to be removed. The reported gains on MotionBench indicate that the learned representations still capture useful motion structure. We will add a short discussion paragraph in the method section acknowledging codec artifacts and their implicit handling through training. revision: yes
Circularity Check
No circularity; empirical framework with no derivations or self-referential fits
full rationale
The paper describes an agentic video understanding system (GOPAgen) that trains a motion agent on codec GOP structures, adds GOP tree reasoning, structural memory pages, coarse-to-fine zoom-in, and a motion vector database. All central claims are empirical performance statements on VQA benchmarks (MotionBench, Egoschema). No equations, parameter-fitting procedures, uniqueness theorems, or self-citations appear in the abstract or described sections. No step reduces a claimed prediction or result to its own inputs by construction. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Moviechat: From dense token to sparse memory for long video understanding
Song, Enxin, Chai, Wenhao, Wang, Guanhong, Zhang, Yucheng, Zhou, Haoyang, Wu, Feiyang, and others. Moviechat: From dense token to sparse memory for long video understanding. CVPR, pages 18221–18232, 2024
2024
-
[2]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Li, Feng, Zhang, Renrui, Zhang, Hao, Zhang, Yuanhan, Li, Bo, Li, Wei, and others. Llava-next- interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Longvideobench: A benchmark for long- context interleaved video-language understanding.Advances in Neural Information Processing Systems (NeurIPS), 2024
Wu, Haoning, Li, Dongxu, Chen, Bei, and Li, Junnan. Longvideobench: A benchmark for long- context interleaved video-language understanding.Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[4]
Fu, Chaoyou, Dai, Yuhan, Luo, Yongdong, Li, Lei, Ren, Shuhuai, Zhang, Renrui, and others. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis.Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 24108–24118, 2025
2025
-
[5]
LLaVA-OneVision: Easy Visual Task Transfer
Li, Bo, Zhang, Yuanhan, Guo, Dong, Zhang, Renrui, Li, Feng, Zhang, Hao, and others. Llava- onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, Peng, Bai, Shuai, Tan, Sinan, Wang, Shijie, Fan, Zhihao, Bai, Jinze, and others. Qwen2- vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Chen, Shimin, Lan, Xiaohan, Yuan, Yitian, Jie, Zequn, and Ma, Lin. Timemarker: A versatile video-llm for long and short video understanding with superior temporal localization ability. arXiv preprint arXiv:2411.18211, 2024
-
[8]
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Chen, Yukang, Xue, Fuzhao, Li, Dacheng, Hu, Qinghao, Zhu, Ligeng, Li, Xiuyu, and oth- ers. Longvila: Scaling long-context visual language models for long videos.arXiv preprint arXiv:2408.10188, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Yashima, Daichi, Kurita, Shuhei, Oda, Yusuke, and Sugiura, Komei. ReMoRa: Multimodal Large Language Model based on Refined Motion Representation for Long-Video Understanding. arXiv preprint arXiv:2602.16412, 2026
-
[10]
Chen, Zhe, Wang, Weiyun, Cao, Yue, Liu, Yangzhou, Gao, Zhangwei, Cui, Erfei, and others. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
arXiv preprint arXiv:2408.14023 , year=
Fei, Jiajun, Li, Dian, Deng, Zhidong, Wang, Zekun, Liu, Gang, and Wang, Hui. Video-ccam: Enhancing video-language understanding with causal cross-attention masks for short and long videos.arXiv preprint arXiv:2408.14023, 2024
-
[12]
Gao, Lishuai, Zhong, Yujie, Zeng, Yingsen, Tan, Haoxian, Li, Dengjie, and Zhao, Zheng. Linvt: Empower your image-level large language model to understand videos.arXiv preprint arXiv:2412.05185, 2024
-
[13]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team GLM, Zeng, Aohan, Xu, Bin, Wang, Bowen, Zhang, Chenhui, Yin, Da, and others. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Scaling video-language models to 10k frames via hierarchical differential distillation.ICML, 2025
Cheng, Chuanqi, Guan, Jian, Wu, Wei, and Yan, Rui. Scaling video-language models to 10k frames via hierarchical differential distillation.ICML, 2025
2025
-
[15]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Zhang, Boqiang, Li, Kehan, Cheng, Zesen, Hu, Zhiqiang, Yuan, Yuqian, Chen, Guanzheng, and others. Videollama 3: Frontier multimodal foundation models for image and video understand- ing.arXiv preprint arXiv:2501.13106, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Videomind: A chain-of-lora agent for long video reasoning,
Liu, Zuyan, Dong, Yuhao, Liu, Ziwei, Hu, Winston, Lu, Jiwen, and Rao, Yongming. Videomind: A chain-of-lora agent for long video reasoning.arXiv preprint arXiv:2503.13444, 2025
-
[17]
Oryx mllm: On-demand spatial-temporal understanding at arbitrary resolution.ICLR, 2025
Liu, Zuyan, Dong, Yuhao, Liu, Ziwei, Hu, Winston, Lu, Jiwen, and Rao, Yongming. Oryx mllm: On-demand spatial-temporal understanding at arbitrary resolution.ICLR, 2025
2025
-
[18]
arXiv preprint arXiv:2406.09396 , year=
Park, Jongwoo, Ranasinghe, Kanchana, Kahatapitiya, Kumara, Ryu, Wonjeong, Kim, Donghyun, and Ryoo, Michael S. Too many frames, not all useful: Efficient strategies for long-form video qa.arXiv preprint arXiv:2406.09396, 2024
-
[19]
arXiv preprint arXiv:2409.14485 , year=
Shu, Yan, Liu, Zheng, Zhang, Peitian, Qin, Minghao, Zhou, Junjie, Liang, Zhengyang, and others. Video-xl: Extra-long vision language model for hour-scale video understanding.arXiv preprint arXiv:2409.14485, 2024
-
[20]
Lin, Bin, Ye, Yang, Zhu, Bin, Cui, Jiaxi, Ning, Munan, Jin, Peng, and others. Video-llava: Learning united visual representation by alignment before projection.Proceedings of the 2024 conference on empirical methods in natural language processing, pages 5971–5984, 2024
2024
-
[21]
arXiv preprint arXiv:2411.13093 , year=
Luo, Yongdong, Zheng, Xiawu, Yang, Xiao, Li, Guilin, Lin, Haojia, Huang, Jinfa, and others. Video-rag: Visually-aligned retrieval-augmented long video comprehension.arXiv preprint arXiv:2411.13093, 2024
-
[22]
arXiv preprint arXiv:2510.12422 , url =
Zuo, Jialong, Deng, Yongtai, Kong, Lingdong, Yang, Jingkang, Jin, Rui, Zhang, Yiwei, and others. Videolucy: Deep memory backtracking for long video understanding.arXiv preprint arXiv:2510.12422, 2025
-
[23]
Zhao, Jun, Zu, Can, Xu, Hao, Lu, Yi, He, Wei, Ding, Yiwen, and others. Longagent: scaling language models to 128k context through multi-agent collaboration.arXiv preprint arXiv:2402.11550, 2024
-
[24]
Zhang, Xiaoyi, Jia, Zhaoyang, Guo, Zongyu, Li, Jiahao, Li, Bin, Li, Houqiang, and others. Deep video discovery: Agentic search with tool use for long-form video understanding.arXiv preprint arXiv:2505.18079, 2025
-
[25]
Long Context Transfer from Language to Vision
Zhang, Peiyuan, Zhang, Kaichen, Li, Bo, Zeng, Guangtao, Yang, Jingkang, Zhang, Yuanhan, and others. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Llama-vid: An image is worth 2 tokens in large language models.European Conference on Computer Vision, pages 323–340, 2024
Li, Yanwei, Wang, Chengyao, and Jia, Jiaya. Llama-vid: An image is worth 2 tokens in large language models.European Conference on Computer Vision, pages 323–340, 2024
2024
-
[27]
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Li, Xinhao, Wang, Yi, Yu, Jiashuo, Zeng, Xiangyu, Zhu, Yuhan, Huang, Haian, and others. VideoChat-Flash: Hierarchical compression for long-context video modeling.arXiv preprint arXiv:2501.00574, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Wang, Ziyang, Yu, Shoubin, Stengel-Eskin, Elias, Yoon, Jaehong, Cheng, Feng, Bertasius, Gedas, and others. Videotree: Adaptive tree-based video representation for llm reasoning on long videos.Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 3272–3283, 2025
2025
-
[29]
Introducing GPT-4.1 in the API
OpenAI. Introducing GPT-4.1 in the API. 2025
2025
-
[30]
Gemini: A Family of Highly Capable Multimodal Models
Team, Gemini, Anil, Rohan, Borgeaud, Sebastian, Alayrac, Jean-Baptiste, Yu, Jiahui, Soricut, Radu, and others. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Introducing Deep Research
OpenAI. Introducing Deep Research. 2025
2025
-
[32]
DeepSearch
Jina AI. DeepSearch. 2025
2025
-
[33]
Grok 3 Beta — The Age of Reasoning Agents
xAI. Grok 3 Beta — The Age of Reasoning Agents. 2025
2025
-
[34]
Videoagent: A memory-augmented multimodal agent for video understanding.European Conference on Computer Vision (ECCV), pages 75–92, 2024
Fan, Yue, Ma, Xiaojian, Wu, Rujie, Du, Yuntao, Li, Jiaqi, Gao, Zhi, and others. Videoagent: A memory-augmented multimodal agent for video understanding.European Conference on Computer Vision (ECCV), pages 75–92, 2024. 11
2024
-
[35]
Vca: Video curious agent for long video understanding.Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 20168–20179, 2025
Yang, Zeyuan, Chen, Delin, Yu, Xueyang, Shen, Maohao, and Gan, Chuang. Vca: Video curious agent for long video understanding.Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 20168–20179, 2025
2025
-
[36]
Visual instruction tuning
Liu, Haotian, Li, Chunyuan, Wu, Qingyang, and Lee, Yong Jae. Visual instruction tuning. Advances in neural information processing systems (NeurIPS), volume 36, pages 34892–34916, 2023
2023
-
[37]
mPLUG- OWL3: Towards long image-sequence understanding in multi-modal large language models
Ye, Jiabo, Xu, Haiyang, Liu, Haowei, Hu, Anwen, Yan, Ming, Qian, Qi, and others. mPLUG- OWL3: Towards long image-sequence understanding in multi-modal large language models. International Conference on Learning Representations (ICLR), 2025
2025
-
[38]
Growing a twig to accelerate large vision-language models.Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 20064–20074, 2025
Shao, Zhenwei, Wang, Mingyang, Yu, Zhou, Pan, Wenwen, Yang, Yan, Wei, Tao, and others. Growing a twig to accelerate large vision-language models.Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 20064–20074, 2025
2025
-
[39]
Yu, Zhou, Ouyang, Xuecheng, Shao, Zhenwei, Wang, Meng, and Yu, Jun. Prophet: Prompting large language models with complementary answer heuristics for knowledge-based visual question answering.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
2025
-
[40]
Imp: Highly capable large multimodal models for mobile devices.IEEE Transactions on Multimedia (TMM), 2025
Shao, Zhenwei, Yu, Zhou, Yu, Jun, Ouyang, Xuecheng, Zheng, Lihao, Gai, Zhenbiao, and others. Imp: Highly capable large multimodal models for mobile devices.IEEE Transactions on Multimedia (TMM), 2025
2025
-
[41]
Introducing OpenAI o3 and o4-mini
OpenAI. Introducing OpenAI o3 and o4-mini. 2025
2025
-
[42]
Achiam, Josh, Adler, Steven, Agarwal, Sandhini, Ahmad, Lama, Akkaya, Ilge, Aleman, Floren- cia Leoni, and others. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Wang, Yi, Li, Xinhao, Yan, Ziang, He, Yinan, Yu, Jiashuo, Zeng, Xiangyu, and others. Intern- Video2.5: Empowering video MLLMs with long and rich context modeling.arXiv preprint arXiv:2501.12386, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Visual context window extension: A new perspective for long video understanding.Proceedings of the 33rd ACM International Conference on Multimedia (ACM MM), pages 4281–4289, 2025
Wei, Hongchen, and Chen, Zhenzhong. Visual context window extension: A new perspective for long video understanding.Proceedings of the 33rd ACM International Conference on Multimedia (ACM MM), pages 4281–4289, 2025
2025
-
[46]
Yang, Chenyu, Dong, Xuan, Zhu, Xizhou, Su, Weijie, Wang, Jiahao, Tian, Hao, and others. Pvc: Progressive visual token compression for unified image and video processing in large vision- language models.Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 24939–24949, 2025
2025
-
[47]
Dycoke: Dynamic compres- sion of tokens for fast video large language models.Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 18992–19001, 2025
Tao, Keda, Qin, Can, You, Haoxuan, Sui, Yang, and Wang, Huan. Dycoke: Dynamic compres- sion of tokens for fast video large language models.Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 18992–19001, 2025
2025
-
[48]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Shen, Xiaoqian, Xiong, Yunyang, Zhao, Changsheng, Wu, Lemeng, Chen, Jun, Zhu, Chenchen, and others. Longvu: Spatiotemporal adaptive compression for long video-language understand- ing.arXiv preprint arXiv:2410.17434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Large language models are strong audio-visual speech recognition learners
Cappellazzo, Umberto, Kim, Minsu, Chen, Honglie, Ma, Pingchuan, Petridis, Stavros, Falavigna, Daniele, and others. Large language models are strong audio-visual speech recognition learners. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2025
2025
-
[50]
Audio-visual llm for video under- standing.Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 4246–4255, 2025
Shu, Fangxun, Zhang, Lei, Jiang, Hao, and Xie, Cihang. Audio-visual llm for video under- standing.Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 4246–4255, 2025. 12
2025
-
[51]
Xu, Jin, Guo, Zhifang, He, Jinzheng, Hu, Hangrui, He, Ting, Bai, Shuai, and others. Qwen2.5- omni technical report.arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Moviechat+: Question-aware sparse memory for long video question answering.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2025
Song, Enxin, Chai, Wenhao, Ye, Tian, Hwang, Jenq-Neng, Li, Xi, and Wang, Gaoang. Moviechat+: Question-aware sparse memory for long video question answering.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[53]
Generative frame sampler for long video understanding.Findings of the Association for Computational Linguistics: ACL 2025, pages 17900–17917, 2025
Yao, Linli, Wu, Haoning, Ouyang, Kun, Zhang, Yuanxing, Xiong, Caiming, Chen, Bei, and others. Generative frame sampler for long video understanding.Findings of the Association for Computational Linguistics: ACL 2025, pages 17900–17917, 2025
2025
-
[54]
Adaptive keyframe sampling for long video understanding.Proceedings of the Computer Vision and Pattern Recognition Conference, pages 29118–29128, 2025
Tang, Xi, Qiu, Jihao, Xie, Lingxi, Tian, Yunjie, Jiao, Jianbin, and Ye, Qixiang. Adaptive keyframe sampling for long video understanding.Proceedings of the Computer Vision and Pattern Recognition Conference, pages 29118–29128, 2025
2025
-
[55]
Token Merging: Your ViT But Faster
Bolya, Daniel, Fu, Cheng-Yang, Dai, Xiaoliang, Zhang, Peizhao, Feichtenhofer, Christoph, and Hoffman, Judy. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
Adaretake: Adaptive redundancy reduction to perceive longer for video-language understanding.Findings of the Association for Computational Linguistics (ACL), pages 5417–5432, 2025
Wang, Xiao, Si, Qingyi, Zhu, Shiyu, Wu, Jianlong, Cao, Li, and Nie, Liqiang. Adaretake: Adaptive redundancy reduction to perceive longer for video-language understanding.Findings of the Association for Computational Linguistics (ACL), pages 5417–5432, 2025
2025
-
[57]
Lan- guage repository for long video understanding.Findings of the Association for Computational Linguistics: ACL 2025, pages 5627–5646, 2025
Kahatapitiya, Kumara, Ranasinghe, Kanchana, Park, Jongwoo, and Ryoo, Michael S. Lan- guage repository for long video understanding.Findings of the Association for Computational Linguistics: ACL 2025, pages 5627–5646, 2025
2025
-
[58]
VideoAgent: Long-form video understanding with large language model as agent.European Conference on Computer Vision (ECCV), 2024
Wang, Xiaohan, Zhang, Yuhui, Zohar, Orr, and Yeung-Levy, Serena. VideoAgent: Long-form video understanding with large language model as agent.European Conference on Computer Vision (ECCV), 2024
2024
-
[59]
Drvideo: Document retrieval based long video understanding.CVPR, 2025
Ma, Ziyu, Gou, Chenhui, Shi, Hengcan, Sun, Bin, Li, Shutao, Rezatofighi, Hamid, and others. Drvideo: Document retrieval based long video understanding.CVPR, 2025
2025
-
[60]
arXiv preprint arXiv:2503.10200 , year=
Chen, Boyu, Yue, Zhengrong, Chen, Siran, Wang, Zikang, Liu, Yang, Li, Peng, and others. Lvagent: Long video understanding by multi-round dynamical collaboration of mllm agents. arXiv preprint arXiv:2503.10200, 2025
-
[61]
Li, Chuanhao, Li, Zhen, Jing, Chenchen, Liu, Shuo, Shao, Wenqi, Wu, Yuwei, and others. Searchlvlms: A plug-and-play framework for augmenting large vision-language models by searching up-to-date internet knowledge.Advances in Neural Information Processing Systems (NeurIPS), volume 37, pages 64582–64603, 2024
2024
-
[62]
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding
He, Bo, Li, Hengduo, Jang, Young Kyun, Jia, Menglin, Cao, Xuefei, Shah, Ashish, and others. Ma-lmm: Memory-augmented large multimodal model for long-term video understanding. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 13504–13514, 2024
2024
- [63]
-
[64]
Videorag: Retrieval- augmented generation over video corpus.arXiv preprint arXiv:2501.05874, 2025
Jeong, Soyeong, Kim, Kangsan, Baek, Jinheon, and Hwang, Sung Ju. Videorag: Retrieval- augmented generation over video corpus.arXiv preprint arXiv:2501.05874, 2025
-
[65]
VideoARM: Agentic Reasoning over Hierarchical Memory for Long-Form Video Understanding
Yin, Yufei, Meng, Qianke, Chen, Minghao, Ding, Jiajun, Shao, Zhenwei, and Yu, Zhou. VideoARM: Agentic Reasoning over Hierarchical Memory for Long-Form Video Understanding. arXiv preprint arXiv:2512.12360, 2025
-
[66]
ReAct: Synergizing reasoning and acting in language models.International Conference on Learning Representations (ICLR), 2023
Yao, Shunyu, Zhao, Jeffrey, Yu, Dian, Du, Nan, Shafran, Izhak, Narasimhan, Karthik, and others. ReAct: Synergizing reasoning and acting in language models.International Conference on Learning Representations (ICLR), 2023
2023
-
[67]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, and others. Qwen2.5- VL Technical Report.ArXiv, volume abs/2502.13923, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
AuroraCap: Efficient, performant video detailed captioning and a new benchmark,
Chai, Wenhao, Song, Enxin, Du, Yilun, Meng, Chenlin, Madhavan, Vashisht, Bar-Tal, Omer, and others. Auroracap: Efficient, performant video detailed captioning and a new benchmark. arXiv preprint arXiv:2410.03051, 2024
-
[69]
Liu, Aixin, Feng, Bei, Xue, Bing, Wang, Bingxuan, Wu, Bochao, Lu, Chengda, and others. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Tschannen, Michael, Gritsenko, Alexey, Wang, Xiao, Naeem, Muhammad Ferjad, Alabdul- mohsin, Ibrahim, Parthasarathy, Nikhil, and others. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Vijay, M, Bhavana, T, Pranavi, C, Sethu, N Hasika, and Prashsanth, K. Automating Personalized Email Outreach: A LangChain–LLaMA Framework with ChromaDB and Groq Cloud.2025 5th International Conference on Ubiquitous Computing and Intelligent Information Systems (ICUIS), pages 243–250, 2025
2025
-
[72]
Hong, Wenyi, Cheng, Yean, Yang, Zhuoyi, Wang, Weihan, Wang, Lefan, Gu, Xiaotao, and others. Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models.Proceedings of the Computer Vision and Pattern Recognition Conference, pages 8450–8460, 2025
2025
-
[73]
Next-qa: Next phase of question-answering to explaining temporal actions.Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9777–9786, 2021
Xiao, Junbin, Shang, Xindi, Yao, Angela, and Chua, Tat-Seng. Next-qa: Next phase of question-answering to explaining temporal actions.Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9777–9786, 2021
2021
-
[74]
Lvbench: An extreme long video understanding benchmark.Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958–22967, 2025
Wang, Weihan, He, Zehai, Hong, Wenyi, Cheng, Yean, Zhang, Xiaohan, Qi, Ji, and others. Lvbench: An extreme long video understanding benchmark.Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958–22967, 2025
2025
-
[75]
Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, volume 36, pages 46212–46244, 2023
Mangalam, Karttikeya, Akshulakov, Raiymbek, and Malik, Jitendra. Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, volume 36, pages 46212–46244, 2023
2023
-
[76]
Mlvu: Benchmarking multi-task long video understanding.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13691–13701, 2025
Zhou, Junjie, Shu, Yan, Zhao, Bo, Wu, Boya, Liang, Zhengyang, Xiao, Shitao, and others. Mlvu: Benchmarking multi-task long video understanding.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13691–13701, 2025
2025
-
[77]
Collecting highly parallel data for paraphrase evaluation
Chen, David, and Dolan, William B. Collecting highly parallel data for paraphrase evaluation. Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, pages 190–200, 2011
2011
-
[78]
Msr-vtt: A large video description dataset for bridging video and language.Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016
Xu, Jun, Mei, Tao, Yao, Ting, and Rui, Yong. Msr-vtt: A large video description dataset for bridging video and language.Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016
2016
-
[79]
Yu, Zhou, Xu, Dejing, Yu, Jun, Yu, Ting, Zhao, Zhou, Zhuang, Yueting, and others. Activitynet- qa: A dataset for understanding complex web videos via question answering.Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 9127–9134, 2019
2019
-
[80]
Guo, Weiyu, Chen, Ziyang, Wang, Shaoguang, He, Jianxiang, Xu, Yijie, Ye, Jinhui, and others. Logic-in-frames: Dynamic keyframe search via visual semantic-logical verification for long video understanding.arXiv preprint arXiv:2503.13139, 2025
-
[81]
Mvbench: A comprehensive multi-modal video understanding benchmark.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
Li, Kunchang, Wang, Yali, He, Yinan, Li, Yizhuo, Wang, Yi, Liu, Yi, and others. Mvbench: A comprehensive multi-modal video understanding benchmark.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.