MacArena: Benchmarking Computer Use Agents on an Online macOS Environment
Pith reviewed 2026-06-28 02:59 UTC · model grok-4.3
The pith
MacArena benchmark shows model rankings invert on macOS-native tasks, with a top model trailing by over 26 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MacArena demonstrates that macOS presents distinct GUI challenges beyond those in Linux environments. When the same models are tested on ported tasks versus the 49 new macOS-native tasks, rankings invert and the leading model falls more than 26 percent behind on the MacArena subset. This pattern indicates that high scores on prior benchmarks often reflect familiarity with specific task distributions rather than robust cross-platform capability.
What carries the argument
The MacArena benchmark suite, which mixes curated ported tasks with new macOS-native tasks to expose platform-specific generalization gaps in GUI agents.
If this is right
- Existing Linux benchmarks like OSWorld may not suffice as sole training or evaluation environments for agents intended to work on multiple platforms.
- macOS GUI elements such as native menu structures and window management create failure modes not seen in ported tasks.
- The 49 new native tasks identify concrete areas where current agents need additional capability.
- Agents that succeed on MacArena would demonstrate broader GUI competence than those succeeding only on prior benchmarks.
- Development of cross-platform agents will require explicit multi-OS test suites rather than single-environment optimization.
Where Pith is reading between the lines
- Developers could use MacArena to prioritize training data collection for macOS-specific interaction patterns.
- Similar native benchmarks on other desktop platforms might reveal comparable generalization shortfalls.
- The inversion pattern suggests that reinforcement learning loops on single-OS environments may entrench platform biases.
- Future agent architectures might incorporate explicit platform-invariant representations to mitigate these drops.
Load-bearing premise
Performance gaps arise from genuine macOS GUI differences rather than from unequal task difficulty or uneven training data exposure across operating systems.
What would settle it
Re-running the full model suite after equalizing task difficulty distributions or after balanced macOS-specific fine-tuning, then checking whether the ranking inversion disappears.
Figures

read the original abstract
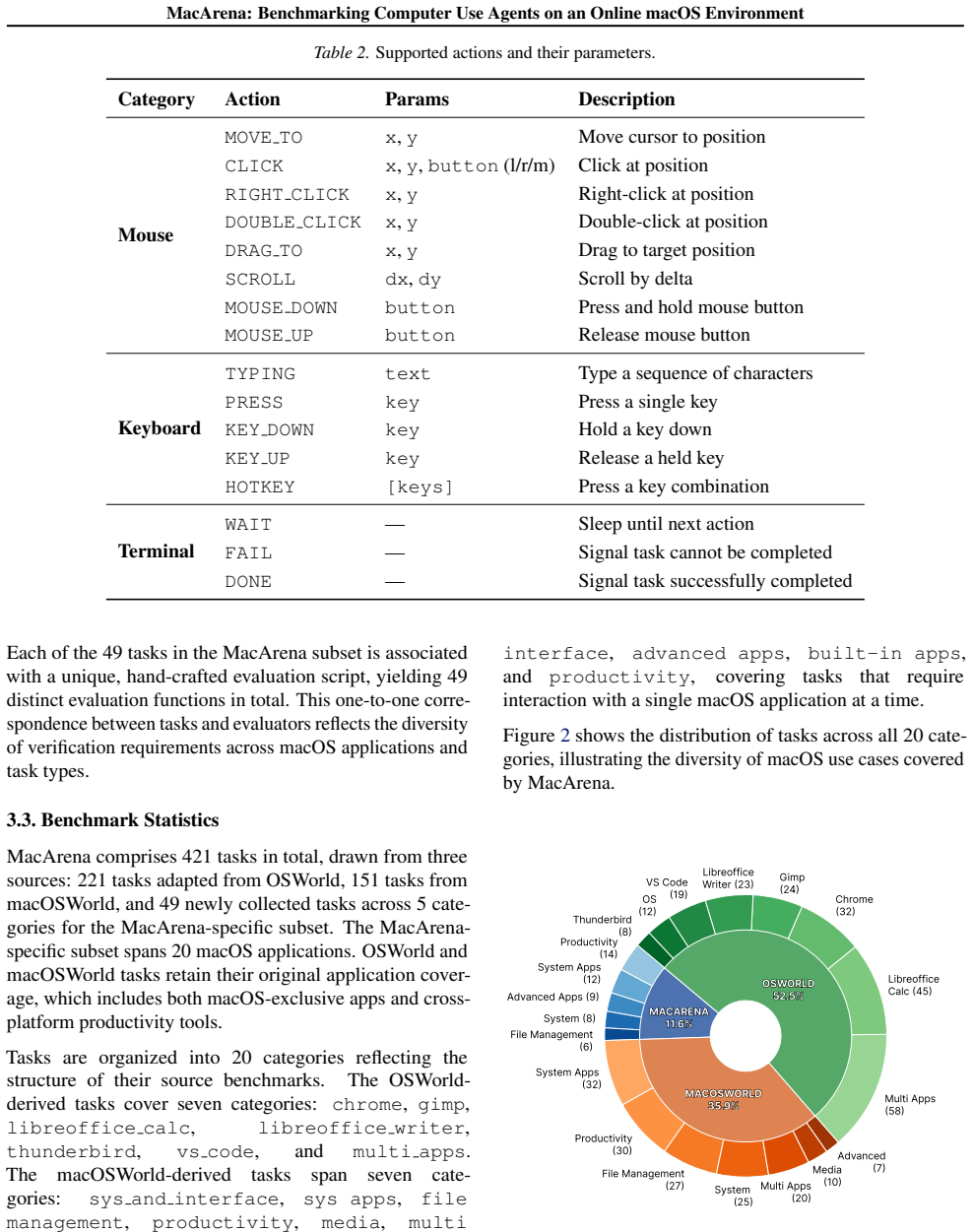
Computer-use agents (CUAs) operate graphical user interfaces (GUIs) through vision and control primitives, and their capabilities have advanced rapidly, driven in part by standardized online evaluation benchmarks such as OSWorld, which serve both as evaluation tools and as training environments for reinforcement learning. However, macOS remains underserved in this landscape: the only existing benchmark, macOSWorld, covers a narrow slice of first-party applications with simpler tasks, and runs on x86 virtual machines incompatible with Apple Silicon. We introduce MacArena, a benchmark of 421 manually verified tasks spanning 50 applications that combines a curated port of OSWorld tasks, content sourced from macOSWorld, and 49 new macOS-native tasks, all running on Apple's native Virtualization framework on Apple Silicon. We argue that macOS presents distinct GUI challenges beyond what Linux-based benchmarks capture, and our evaluation supports this claim: strong model performance on existing benchmarks can reflect familiarity with task distributions rather than genuine cross-platform GUI competence. Notably, model rankings invert between ported and macOS-native tasks, with a leading model trailing by over 26% on the MacArena subset, suggesting that macOS poses a genuinely harder environment for current GUI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MacArena, a benchmark of 421 manually verified tasks across 50 applications for computer-use agents on macOS. It combines a port of OSWorld tasks, content from macOSWorld, and 49 new macOS-native tasks, all running natively on Apple Silicon via the Virtualization framework. The central claim is that macOS presents distinct GUI challenges not captured by Linux-based benchmarks, supported by an observed inversion in model rankings between ported and native tasks, with a leading model trailing by over 26% on the MacArena native subset.
Significance. If the inversion result holds after controlling for task difficulty, the work would be significant for highlighting limitations in cross-platform generalization of current GUI agents and for providing the first substantial macOS-native benchmark on Apple Silicon hardware. The combination of ported and new tasks offers a direct comparison point that could inform future agent training and evaluation.
major comments (2)
- [Task construction and results sections] The headline inversion result (leading model trailing >26% on the native subset) is load-bearing for the claim that macOS poses genuinely harder GUI challenges. However, the manuscript provides no matched difficulty metrics (e.g., average step count, UI element density, or action-sequence complexity) between the 49 new macOS-native tasks and the ported OSWorld subset; without these controls, selection bias in task construction cannot be ruled out as an alternative explanation for the ranking inversion.
- [Abstract] The abstract states that the evaluation supports the inversion claim but supplies no details on task selection criteria for the 49 new tasks, statistical tests for the ranking difference, or error analysis; this absence leaves the causal attribution to macOS-specific GUI features underdetermined.
minor comments (1)
- [Methods] Clarify in the methods how the 421 tasks were manually verified and how the ported versus native subsets were balanced in application coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The feedback correctly identifies areas where additional controls and details would strengthen the presentation of the inversion result. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Task construction and results sections] The headline inversion result (leading model trailing >26% on the native subset) is load-bearing for the claim that macOS poses genuinely harder GUI challenges. However, the manuscript provides no matched difficulty metrics (e.g., average step count, UI element density, or action-sequence complexity) between the 49 new macOS-native tasks and the ported OSWorld subset; without these controls, selection bias in task construction cannot be ruled out as an alternative explanation for the ranking inversion.
Authors: We agree that matched difficulty metrics are necessary to strengthen the interpretation of the ranking inversion. In the revised manuscript we will add a dedicated comparison in the results section reporting average step count, UI element density, and action-sequence complexity for the 49 native tasks versus the ported OSWorld subset. This will allow readers to evaluate the plausibility of selection bias as an alternative explanation. revision: yes
-
Referee: [Abstract] The abstract states that the evaluation supports the inversion claim but supplies no details on task selection criteria for the 49 new tasks, statistical tests for the ranking difference, or error analysis; this absence leaves the causal attribution to macOS-specific GUI features underdetermined.
Authors: We acknowledge that the abstract would be improved by including these supporting details. We will revise the abstract to briefly state the task selection criteria used for the 49 new macOS-native tasks, report the statistical tests applied to the ranking difference, and summarize the error analysis. These additions will make the evidential basis for attributing performance differences to macOS-specific GUI features more explicit. revision: yes
Circularity Check
No circularity: empirical benchmark with direct performance comparisons
full rationale
The paper introduces MacArena as a new benchmark by porting OSWorld tasks, incorporating macOSWorld content, and adding 49 new native tasks, then reports model success rates on ported vs. native subsets. No equations, fitted parameters, or derivations exist. No self-citations are used to establish uniqueness theorems or ansatzes that bear on the central claims. Model ranking inversion is presented as an empirical observation from the evaluations, not reduced to any input by construction. This is a standard empirical benchmark paper whose claims rest on external model runs rather than self-referential reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption macOS presents distinct GUI challenges beyond what Linux-based benchmarks capture
- domain assumption The 421 tasks are manually verified and comparable across ported and native subsets
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and Liu, Yitao and Xu, Yiheng and Zhou, Shuyan and Savarese, Silvio and Xiong, Caiming and Zhong, Victor and Yu, Tao , title =. Proceedings of the 38th International Conference on Neu...
2024
-
[2]
2025 , eprint=
macOSWorld: A Multilingual Interactive Benchmark for GUI Agents , author=. 2025 , eprint=
2025
-
[3]
2024 , month =
Bonatti, Rogerio and Zhao, Dan and Bonacci, Francesco and Dupont, Dillon and Abdali, Sara and Li, Yinheng and Wagle, Justin and Koishida, Kazuhito and Bucker, Arthur and Jang, Lawrence and Hui, Zack , title =. 2024 , month =
2024
-
[4]
2024 , eprint=
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents , author=. 2024 , eprint=
2024
-
[5]
2025 , eprint=
OS-Harm: A Benchmark for Measuring Safety of Computer Use Agents , author=. 2025 , eprint=
2025
-
[6]
International Conference on Learning Representations (
Evan Zheran Liu and Kelvin Guu and Panupong Pasupat and Tianlin Shi and Percy Liang , title =. International Conference on Learning Representations (
-
[7]
CogAgent: A Visual Language Model for GUI Agents , year=
Hong, Wenyi and Wang, Weihan and Lv, Qingsong and Xu, Jiazheng and Yu, Wenmeng and Ji, Junhui and Wang, Yan and Wang, Zihan and Dong, Yuxiao and Ding, Ming and Tang, Jie , booktitle=. CogAgent: A Visual Language Model for GUI Agents , year=
-
[8]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Zheng, Boyuan and Gou, Boyu and Kil, Jihyung and Sun, Huan and Su, Yu , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[9]
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao
Zhang, Chaoyun and Li, Liqun and He, Shilin and Zhang, Xu and Qiao, Bo and Qin, Si and Ma, Minghua and Kang, Yu and Lin, Qingwei and Rajmohan, Saravan and Zhang, Dongmei and Zhang, Qi. UFO : A UI -Focused Agent for Windows OS Interaction. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguis...
-
[10]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
UI-TARS: Pioneering Automated GUI Interaction with Native Agents , author=. arXiv preprint arXiv:2501.12326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
2024 , eprint=
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction , author=. 2024 , eprint=
2024
-
[12]
2025 , eprint=
Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents , author=. 2025 , eprint=
2025
-
[13]
2024 , eprint=
DigiRL: Training In-The-Wild Device-Control Agents with Autonomous Reinforcement Learning , author=. 2024 , eprint=
2024
-
[14]
2025 , eprint=
ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning , author=. 2025 , eprint=
2025
-
[16]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Deng, Xiang and Gu, Yu and Zheng, Boyuan and Chen, Shijie and Stevens, Samuel and Wang, Boshi and Sun, Huan and Su, Yu , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[17]
2023 , eprint=
Android in the Wild: A Large-Scale Dataset for Android Device Control , author=. 2023 , eprint=
2023
-
[18]
2024 , eprint=
SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents , author=. 2024 , eprint=
2024
-
[19]
2024 , eprint=
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents , author=. 2024 , eprint=
2024
-
[20]
ScreenSpot-Pro:
Kaixin Li and Meng Ziyang and Hongzhan Lin and Ziyang Luo and Yuchen Tian and Jing Ma and Zhiyong Huang and Tat-Seng Chua , booktitle=. ScreenSpot-Pro:. 2025 , url=
2025
-
[21]
2026 , eprint=
GUIrilla: A Scalable Framework for Automated Desktop UI Exploration , author=. 2026 , eprint=
2026
-
[22]
2024 , eprint=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. 2024 , eprint=
2024
-
[23]
V isual W eb A rena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Koh, Jing Yu and Lo, Robert and Jang, Lawrence and Duvvur, Vikram and Lim, Ming and Huang, Po-Yu and Neubig, Graham and Zhou, Shuyan and Salakhutdinov, Russ and Fried, Daniel. V isual W eb A rena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
-
[24]
and Del Verme, Manuel and Marty, Tom and Vazquez, David and Chapados, Nicolas and Lacoste, Alexandre , booktitle =
Drouin, Alexandre and Gasse, Maxime and Caccia, Massimo and Laradji, Issam H. and Del Verme, Manuel and Marty, Tom and Vazquez, David and Chapados, Nicolas and Lacoste, Alexandre , booktitle =. 2024 , editor =
2024
-
[25]
2025 , eprint=
Benchmarking Mobile Device Control Agents across Diverse Configurations , author=. 2025 , eprint=
2025
-
[26]
Are We Done Yet?
"Are We Done Yet?": A Vision-Based Judge for Autonomous Task Completion of Computer Use Agents , author=. 2025 , eprint=
2025
-
[27]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[28]
2025 , eprint=
Screen2AX: Vision-Based Approach for Automatic macOS Accessibility Generation , author=. 2025 , eprint=
2025
-
[29]
2024 , eprint=
OmniParser for Pure Vision Based GUI Agent , author=. 2024 , eprint=
2024
-
[30]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[31]
2025 , url=
Computer-Using Agent: Introducing a universal interface for AI to interact with the digital world , author=. 2025 , url=
2025
-
[32]
Sager, Pascal J. and Meyer, Benjamin and Yan, Peng and Von Wartburg-Kottler, Rebekka and Etaiwi, Layan and Enayati, Aref and Nobel, Gabriel and Abdulkadir, Ahmed and Grewe, Benjamin F. and Stadelmann, Thilo , year=. A Comprehensive Survey of Agents for Computer Use: Foundations, Challenges, and Future Directions , volume=. doi:10.1613/jair.1.19490 , journal=
-
[33]
2025 , eprint=
GUI Agents: A Survey , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.