Multiscale POD of Transformer Attention Fields: Scale-Selective Analysis via Morlet Scalogram
Pith reviewed 2026-06-27 23:20 UTC · model grok-4.3
The pith
Transformer attention fields exhibit layer-dependent scale organisation extracted by applying POD at scales identified via Morlet wavelets on attention lag structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
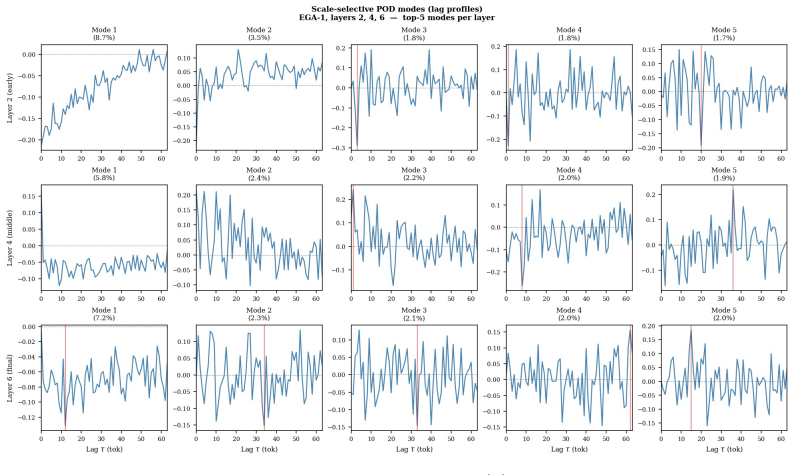
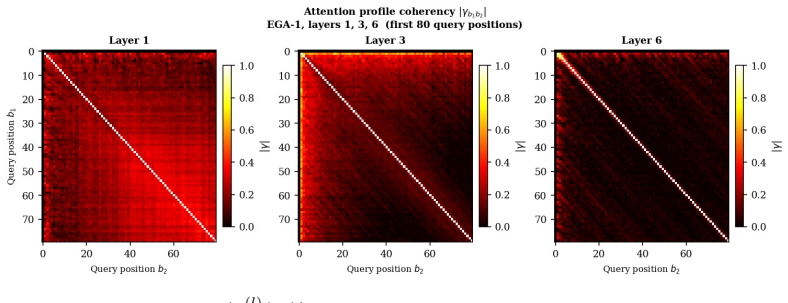
By identifying dominant scales in the attention lag structure with the Morlet continuous wavelet transform and then extracting modes via scale-specific POD, the analysis produces modes that reveal early layers emphasising fine scales and later layers shifting toward coarser scales, while the spectral concentration index from eigenvalue decay differentiates layers by attention field complexity; the modes minimise average L2 reconstruction error over the ensemble by the classical POD optimality theorem and supply a data-driven effective rank for each layer.
What carries the argument
Morlet scalogram identification of dominant scales in attention lag structure, followed by scale-selective POD on the ensemble of attention fields to extract energetically dominant modes at each scale.
If this is right
- The extracted modes minimise the average L2 reconstruction error over the document ensemble by the classical POD theorem.
- Each layer obtains a data-driven effective rank from the decay rate of its POD eigenvalues.
- Dominant attention patterns emerge directly from ensemble statistics without any architectural modification or linguistic annotations.
- The spectral concentration index quantifies attention field complexity and differentiates layers on that basis.
- The method applies to any transformer model and any document ensemble without further adaptation.
Where Pith is reading between the lines
- The same workflow could be applied to attention fields from non-text sequence models to test whether the fine-to-coarse layer shift is language-specific.
- Tracking how the spectral concentration index changes with model depth or width would give a scalar signature of scale organisation across architectures.
- The turbulence-inspired ensemble treatment suggests that other modal-analysis tools from fluid dynamics could be tested on attention data for additional structure.
- Holding the model fixed and varying only the document ensemble would isolate whether the observed scale shift depends on data statistics rather than architecture.
Load-bearing premise
The ensemble of attention fields collected across documents can be treated as statistically equivalent to an ensemble of turbulent flow fields so that the classical POD optimality theorem applies and yields dominant modes.
What would settle it
Computing the scale-selective POD on attention fields from a new document ensemble and finding no consistent shift from fine-scale emphasis in early layers to coarser-scale emphasis in later layers would falsify the layer-dependent organisation result.
Figures

read the original abstract
We introduce scale-selective Proper Orthogonal Decomposition (POD) for transformer attention fields, inspired by the use of POD for extracting energetically dominant modes from turbulent flow ensembles. The Morlet continuous wavelet transform identifies dominant temporal scales in the attention lag structure across a document ensemble; POD then extracts the energetically dominant modes at each scale from the ensemble of attention fields. The resulting modes reveal layer-dependent scale organisation, with early layers emphasising fine scales and later layers shifting toward coarser scales. We define a spectral concentration index from the POD eigenvalue decay rate and show empirically that it differentiates layers by their attention field complexity. By the classical POD optimality theorem, the extracted modes minimise the average L2 reconstruction error over the ensemble (Theorem 1), giving a data-driven effective rank for each layer. The method requires no architectural modification and no linguistic annotations: dominant attention patterns emerge from ensemble statistics alone. The turbulence analogy is structural rather than physical: we borrow ensemble covariance and modal analysis, not fluid dynamics itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multiscale Proper Orthogonal Decomposition (POD) method for analyzing transformer attention fields. It uses the Morlet continuous wavelet transform to identify dominant temporal scales in attention lag structures across a document ensemble, followed by POD to extract energetically dominant modes at each scale. The authors claim that the resulting modes show layer-dependent scale organisation, with early layers emphasising fine scales and later layers shifting to coarser scales. They define a spectral concentration index from the POD eigenvalue decay rate that empirically differentiates layers by attention field complexity. The approach relies on the classical POD optimality theorem for minimising L2 reconstruction error and requires no architectural modifications or linguistic annotations. The turbulence analogy is presented as structural, borrowing ensemble covariance and modal analysis without invoking fluid dynamics.
Significance. If the empirical results on layer differentiation hold, this method could provide a valuable data-driven tool for interpreting the hierarchical processing in transformer models by adapting modal analysis techniques from fluid dynamics. The general applicability of the POD theorem strengthens the theoretical foundation, and the lack of need for annotations makes it broadly applicable. However, the absence of quantitative validation in the presented material limits the assessed significance.
major comments (2)
- [Abstract] Abstract: The abstract states empirical observations of layer-dependent scale organisation and differentiation via the spectral concentration index, but supplies no quantitative results, error bars, dataset details, or validation against baselines, making the central claims impossible to evaluate.
- [Empirical claims section] Empirical claims section: No specific numerical values for the spectral concentration index, eigenvalue spectra, or scalogram analyses are provided to support the differentiation of layers by attention field complexity.
minor comments (1)
- [Abstract] Abstract: The reference to 'Theorem 1' is mentioned but not stated or proven in the provided text; if it is the classical POD theorem, it should be explicitly recalled for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed report and the recommendation for major revision. We agree that the abstract and empirical claims section require quantitative support to make the layer-differentiation results evaluable, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states empirical observations of layer-dependent scale organisation and differentiation via the spectral concentration index, but supplies no quantitative results, error bars, dataset details, or validation against baselines, making the central claims impossible to evaluate.
Authors: We agree that the abstract as written does not supply the requested quantitative elements. In the revised manuscript we will insert concise numerical highlights (mean spectral concentration index per layer with standard deviation, ensemble size, and dataset identifiers) while preserving the abstract length limit. This directly addresses the evaluability concern without altering the method description. revision: yes
-
Referee: [Empirical claims section] Empirical claims section: No specific numerical values for the spectral concentration index, eigenvalue spectra, or scalogram analyses are provided to support the differentiation of layers by attention field complexity.
Authors: The referee correctly notes the absence of explicit numerical values in the empirical claims section. We will expand the section with a new table reporting layer-wise spectral concentration indices (means and standard errors), representative eigenvalue spectra, and dominant scalogram scales, together with a brief statement of the document ensemble size and preprocessing. These additions will furnish the quantitative backing for the claimed layer differentiation. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper applies the classical POD optimality theorem (a general result on covariance operators for any square-integrable ensemble) to attention fields after identifying scales via Morlet scalogram; the spectral concentration index is defined directly from the resulting eigenvalue decay rates, and layer differentiation is reported as an empirical observation from those quantities. The turbulence analogy is explicitly limited to borrowing ensemble covariance structure and is not invoked to justify the theorem or the index. No equations define a quantity in terms of itself, no parameters are fitted to a subset and then called a prediction of a related quantity, and no load-bearing steps reduce to self-citations or imported uniqueness results. The derivation remains self-contained with respect to the attention ensemble statistics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The classical POD optimality theorem applies directly to ensembles of transformer attention fields.
Reference graph
Works this paper leans on
-
[1]
Energy- G ated A ttention: S pectral S alience as an I nductive B ias for T ransformer A ttention
Zeris, A. Energy- G ated A ttention: S pectral S alience as an I nductive B ias for T ransformer A ttention. arXiv preprint arXiv 2605.21842v1, 2026
Pith/arXiv arXiv 2026
-
[2]
Zeris, A. E nergy- G ated A ttention and W avelet P ositional E ncoding: C omplementary I nductive B iases for T ransformer A ttention. arXiv preprint arXiv 2605.26355v1, 2026
Pith/arXiv arXiv 2026
-
[3]
B eyond S inusoids: A M orlet W avelet F ramework for T rasformer P ositional E ncoding
Zeris, A. B eyond S inusoids: A M orlet W avelet F ramework for T rasformer P ositional E ncoding. arXiv preprint arXiv 2606.01258v1, 2026
Pith/arXiv arXiv 2026
-
[4]
Rethinking attention with P erformers
Choromanski, K., Likhosherstov, V., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J., Mohiuddin, A., Kaiser, L., Belanger, D., Colwell, L., and Weller, A. Rethinking attention with P erformers. In ICLR, 2021
2021
-
[5]
What does BERT look at? A n analysis of BERT 's attention
Clark, K., Khandelwal, U., Levy, O., and Manning, C. What does BERT look at? A n analysis of BERT 's attention. In BlackboxNLP Workshop, 2019
2019
-
[6]
A mathematical framework for transformer circuits
Elhage, N., Nanda, N., Olsson, C., et al. A mathematical framework for transformer circuits. Transformer Circuits Thread, 2021
2021
-
[7]
G., and Tropp, J
Halko, N., Martinsson, P. G., and Tropp, J. A. Finding structure with randomness: P robabilistic algorithms for constructing approximate matrix decompositions. SIAM Review, 53(2):217--288, 2011
2011
-
[8]
and Manning, C
Hewitt, J. and Manning, C. D. A structural probe for finding syntax in word representations. In NAACL, 2019
2019
-
[9]
L., and Berkooz, G
Holmes, P., Lumley, J. L., and Berkooz, G. Turbulence, Coherent Structures, Dynamical Systems and Symmetry. Cambridge University Press, 1996
1996
-
[10]
Lumley, J. L. The structure of inhomogeneous turbulent flows. In Yaglom, A. M. and Tatarski, V. I., editors, Atmospheric Turbulence and Radio Wave Propagation, pp.\ 166--178. Nauka, Moscow, 1967
1967
-
[11]
Locating and editing factual associations in GPT
Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and editing factual associations in GPT . In NeurIPS, 2022
2022
-
[12]
Are sixteen heads really better than one? In NeurIPS, 2019
Michel, P., Levy, O., and Neubig, G. Are sixteen heads really better than one? In NeurIPS, 2019
2019
-
[13]
In-context learning and induction heads
Olsson, C., Elhage, N., Nanda, N., et al. In-context learning and induction heads. Transformer Circuits Thread, 2022
2022
-
[14]
Turbulence and the dynamics of coherent structures
Sirovich, L. Turbulence and the dynamics of coherent structures. Quarterly of Applied Mathematics, 45(3):561--590, 1987
1987
-
[15]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. In NeurIPS, volume 30, 2017
2017
-
[16]
Verma, P. and Pilanci, M. Towards signal processing in large language models. arXiv preprint arXiv:2406.10254, 2024
arXiv 2024
-
[17]
WaveletGPT : Wavelets meet large language models
Jin, M., Zheng, Y., Li, Y.F., Chen, S., Yang, B., and Pan, S. WaveletGPT : Wavelets meet large language models. arXiv preprint arXiv:2309.14122, 2024
arXiv 2024
-
[18]
Analyzing multi-head self-attention: S pecialized heads do the heavy lifting, the rest can be pruned
Voita, E., Talbot, D., Moiseev, F., Sennrich, R., and Titov, I. Analyzing multi-head self-attention: S pecialized heads do the heavy lifting, the rest can be pruned. In ACL, 2019
2019
-
[19]
Efficient streaming language models with attention sinks
Xiao, G., Tang, Y., Zuo, J., Shao, J., Jiang, S., Han, S., Chen, Y., and Dai, J. Efficient streaming language models with attention sinks. In ICLR, 2024
2024
-
[20]
AudioLM : a language modeling approach to audio generation
Borsos, Z., Marinier, R., Vincent, D., Kharitonov, E., Pietquin, O., Sharifi, M., Roblek, D., Teboul, O., Grangier, D., Tagliasacchi, M., and Zeghidour, N. AudioLM : a language modeling approach to audio generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2523--2533, 2023
2023
-
[21]
Simple and controllable music generation
Copet, J., Kreuk, F., Gat, I., Remez, T., Kant, D., Synnaeve, G., Adi, Y., and D\' e fossez, A. Simple and controllable music generation. In NeurIPS, 2023
2023
-
[22]
n - W idths in A pproximation T heory
Pinkus, A. n - W idths in A pproximation T heory. Springer, 1985
1985
-
[23]
Fonctions aléatoires du second ordre
Loève, M. Fonctions aléatoires du second ordre. In Lévy, P., Processus Stochastiques et Mouvement Brownien, 1948
1948
-
[24]
Spectral energy distribution in a turbulent flow
Obukhov, A.M. Spectral energy distribution in a turbulent flow. Izvestiya Akademii Nauk SSSR, Seriya Geograficheskaya i Geofizicheskaya, 5(4--5):453--466, 1941
1941
-
[25]
W., Xu, T., Brockman, G., McLeavey, C., and Sutskever, I
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., and Sutskever, I. Robust speech recognition via large-scale weak supervision. In ICML, 2023
2023
-
[26]
A Wavelet Tour of Signal Processing
Mallat, S. A Wavelet Tour of Signal Processing. Academic Press, 2nd edition, 1999
1999
-
[27]
Testing for nonlinearity in time series: the method of surrogate data
Theiler, J., Eubank, S., Longtin, A., Galdrikian, B., and Farmer, J.D. Testing for nonlinearity in time series: the method of surrogate data. Physica D, 58:77--94, 1992
1992
-
[28]
Transformer dissection: An unified understanding for transformer's attention via the lens of kernel
Tsai, Y.H., Bai, S., Yamada, M., Morency, L.P., and Salakhutdinov, R. Transformer dissection: An unified understanding for transformer's attention via the lens of kernel. In EMNLP, 2019
2019
-
[29]
Smooth regression analysis
Watson, G.S. Smooth regression analysis. Sankhya A, 26:359--372, 1964
1964
-
[30]
Z., Khabsa, M., Fang, H., and Ma, H
Wang, S., Li, B. Z., Khabsa, M., Fang, H., and Ma, H. Linformer : S elf-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020
Pith/arXiv arXiv 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.