Energy-Gated Attention and Wavelet Positional Encoding: Complementary Inductive Biases for Transformer Attention
Pith reviewed 2026-06-29 22:18 UTC · model grok-4.3
The pith
Combining energy-gated attention with wavelet positional encoding produces superadditive gains in transformer performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
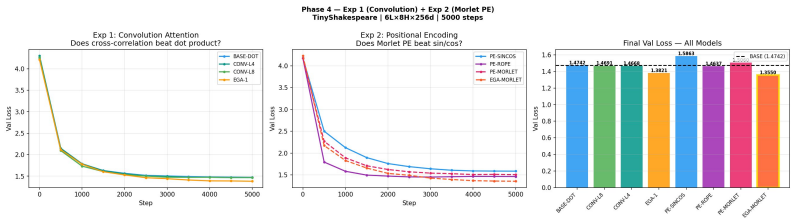
The central claim is that Energy-Gated Attention and Morlet Positional Encoding are complementary inductive biases. Energy-Gated Attention gates value aggregation by a learned energy estimate of key token embeddings computed via a single linear projection. Morlet Positional Encoding replaces fixed sinusoidal encodings with learned Gaussian-windowed wavelets that adapt the joint position-frequency localization to the corpus. Their joint application achieves a validation loss improvement of 0.119, exceeding the sum of the individual contributions of +0.092 and -0.032, with the superadditivity observed across two independent training runs.
What carries the argument
Energy-Gated Attention gates value aggregation by a learned energy estimate of key token embeddings via a single linear projection; Morlet Positional Encoding replaces fixed sinusoidal encodings with learned Gaussian-windowed wavelets that adapt joint position-frequency localization.
If this is right
- The two components address gaps in standard attention that neither fills alone.
- Learned unconstrained versions of the components outperform structured spectral priors such as fixed Morlet gates or sinusoidal encodings.
- The superadditive interaction holds across independent training runs on the character-level benchmark.
- Ablations indicate that complementary learned components interact more effectively than constrained ones.
Where Pith is reading between the lines
- Larger-scale multi-seed validation on varied datasets would test whether the observed complementarity generalizes beyond the current small-scale setup.
- The finding suggests that attention designs could systematically pair selection biases with multi-scale positional biases rather than optimizing either in isolation.
Load-bearing premise
The superadditivity observed on two runs with models up to 6 million parameters on TinyShakespeare reflects a general complementary relationship between energy salience and scale-selective locality rather than training stochasticity or dataset-specific effects.
What would settle it
A multi-seed experiment at larger scale or on a different dataset in which the combined improvement equals or falls below the sum of the separate improvements would falsify the claim that the biases are complementary.
Figures
read the original abstract
Standard transformer attention computes pairwise token similarity but treats all tokens as equally salient and all positions as equally local, regardless of the informational structure of the input. We identify two complementary inductive biases that standard attention lacks: energy salience (which tokens concentrate informational energy, learned end-to-end without explicit frequency decomposition) and scale-selective locality (how far positional influence extends at each frequency, implemented via Morlet wavelet encoding). We address both with two simple components. Energy-Gated Attention (EGA) gates value aggregation by a learned energy estimate of key token embeddings, computed via a single linear projection; it selects what to attend to. Morlet Positional Encoding (MoPE) replaces fixed sinusoidal encodings with learned Gaussian-windowed wavelets that adapt the joint position-frequency localization to the corpus; it specifies where attention operates at each scale. On TinyShakespeare, EGA alone achieves +0.092 validation loss improvement over standard attention (+0.103 over Phase 1-3 baseline); MoPE alone is -0.032 (below baseline as a standalone encoding); but their combination achieves +0.119 -- more than the sum of parts. This superadditivity, observed across two independent training runs, is the central empirical finding: salience and locality are complementary inductive biases, each addressing a gap the other cannot fill alone. Ablations confirm that structured spectral priors (Morlet wavelet gates, scale-initialized heads, fixed sinusoidal PE) consistently underperform their unconstrained learned counterparts, while complementary learned components interact superadditively. All experiments are at small scale (<=6M parameters, character-level benchmarks, single seed); larger-scale multi-seed validation is the most important direction for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Energy-Gated Attention (EGA), which gates value aggregation via a learned linear projection on key embeddings to capture token salience, and Morlet Positional Encoding (MoPE), which replaces sinusoidal encodings with learned Gaussian-windowed Morlet wavelets for scale-selective positional influence. On TinyShakespeare at ≤6M parameters, EGA alone yields +0.092 validation loss improvement, MoPE alone -0.032, and the combination +0.119 (exceeding the sum), observed across two runs; ablations show learned components outperform structured spectral priors, supporting the claim that salience and locality biases are complementary.
Significance. If the superadditivity is robust, the result would indicate that energy-based selection and adaptive wavelet locality address distinct gaps in standard attention, providing a concrete example of how targeted inductive biases can interact positively. The small-scale empirical demonstration and explicit note that larger multi-seed validation is needed are appropriately cautious; the work supplies initial evidence for complementarity but does not yet establish generality.
major comments (1)
- [Abstract] Abstract: the headline superadditivity result (+0.119 exceeding the sum of +0.092 and -0.032) is reported from two single-seed runs with no standard deviations, confidence intervals, or statistical test for the interaction term. At this scale, optimizer and initialization variance commonly produce loss differences of several hundredths; without replication or significance assessment the central claim that the components are complementary rather than reflecting sampling fluctuation cannot be evaluated.
minor comments (1)
- [Abstract] The reference to a 'Phase 1-3 baseline' in the abstract is not defined in the provided summary; a brief description of what this baseline consists of would aid readability.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater statistical caution in presenting the superadditivity result. We agree that the current reporting from two runs without variance measures or tests limits the strength of the complementarity claim, and we will revise the abstract to reflect this more accurately while preserving the manuscript's existing acknowledgment of its small-scale, preliminary scope.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline superadditivity result (+0.119 exceeding the sum of +0.092 and -0.032) is reported from two single-seed runs with no standard deviations, confidence intervals, or statistical test for the interaction term. At this scale, optimizer and initialization variance commonly produce loss differences of several hundredths; without replication or significance assessment the central claim that the components are complementary rather than reflecting sampling fluctuation cannot be evaluated.
Authors: We agree that the absence of standard deviations, confidence intervals, or an interaction test means the superadditivity cannot be statistically distinguished from run-to-run variance at this scale. The manuscript already notes that results are from two independent training runs and states that larger-scale multi-seed validation is the most important future direction. We will revise the abstract to explicitly qualify the +0.119 figure as observed across two runs, remove any implication of confirmed complementarity, and frame the finding as initial evidence consistent with the hypothesis rather than a demonstrated interaction. This change directly addresses the referee's concern. revision: yes
Circularity Check
No circularity; central claim is direct empirical measurement
full rationale
The paper presents no derivation chain or equations that reduce its claimed superadditivity (+0.119 validation loss) to fitted parameters or self-citations. The result is stated as an observed difference in held-out validation loss across two training runs on TinyShakespeare. No self-definitional steps, fitted-input predictions, uniqueness theorems, or ansatzes appear in the provided text. The empirical measurements stand as independent observations against external benchmarks (standard attention baseline), satisfying the criteria for a self-contained non-circular finding.
Axiom & Free-Parameter Ledger
free parameters (2)
- energy projection matrix
- Morlet wavelet parameters
axioms (1)
- domain assumption Base transformer attention and feed-forward blocks function as described in the standard architecture.
Forward citations
Cited by 2 Pith papers
-
Beyond Sinusoids: A Morlet Wavelet Framework for Transformer Positional Encoding
MoPE replaces fixed sinusoidal or rotary positional encodings with per-dimension learned Morlet wavelets that recover prior methods as limits and add a Gaussian locality kernel, yielding a 0.119 gain on TinyShakespear...
-
Multiscale POD of Transformer Attention Fields: Scale-Selective Analysis via Morlet Scalogram
Applies multiscale POD with Morlet scalograms to transformer attention fields to extract dominant modes per scale and reports layer-dependent scale organisation.
Reference graph
Works this paper leans on
-
[1]
Energy-Gated Attention: Spectral Salience as an Inductive Bias for Transformer Attention
Zeris, A. Energy- G ated A ttention: S pectral S alience as an I nductive B ias for T ransformer A ttention. arXiv preprint arXiv:2605.21842v1, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Neural machine translation by jointly learning to align and translate
Bahdanau, D., Cho, K., and Bengio, Y. Neural machine translation by jointly learning to align and translate. In ICLR, 2015
2015
-
[3]
P., et al
Bello, J. P., et al. A tutorial on onset detection in music signals. IEEE Trans. Speech Audio Process., 13(5):1035--1047, 2005
2005
-
[4]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M. E., and Cohan, A. Longformer : The Long-Document Transformer. arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[5]
NTK -aware scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning
Bloc97. NTK -aware scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning. Reddit / GitHub, 2023
2023
-
[6]
V., and Tan, M
Dai, Z., Liu, H., Le, Q. V., and Tan, M. CoAtNet : Marrying convolution and attention for all data sizes. In NeurIPS, volume 34, 2021
2021
-
[7]
A mathematical framework for transformer circuits
Elhage, N., et al. A mathematical framework for transformer circuits. Transformer Circuits Thread, 2021
2021
-
[8]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. Mamba : Linear-time sequence modeling with selective state spaces. arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
L., and Berkooz, G
Holmes, P., Lumley, J. L., and Berkooz, G. Turbulence, Coherent Structures, Dynamical Systems and Symmetry. Cambridge University Press, 1996
1996
-
[10]
On the equivalence of deep neural networks and graph neural networks
Joshi, C., Laurent, T., and Bresson, X. On the equivalence of deep neural networks and graph neural networks. arXiv:2001.12232, 2020
-
[11]
The unreasonable effectiveness of recurrent neural networks, 2015
Karpathy, A. The unreasonable effectiveness of recurrent neural networks, 2015
2015
-
[12]
FNet : Mixing tokens with F ourier transforms
Lee-Thorp, J., Ainslie, J., Eckstein, I., and Ontanon, S. FNet : Mixing tokens with F ourier transforms. In NAACL, 2022
2022
-
[13]
In-context learning and induction heads
Olsson, C., et al. In-context learning and induction heads. Transformer Circuits Thread, 2022
2022
-
[14]
YaRN: Efficient Context Window Extension of Large Language Models
Peng, B., et al. YaRN : Efficient context window extension of large language models. arXiv:2309.00071, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Hyena hierarchy: Towards larger convolutional language models
Poli, M., et al. Hyena hierarchy: Towards larger convolutional language models. In ICML, 2023
2023
-
[16]
A., and Lewis, M
Press, O., Smith, N. A., and Lewis, M. Train short, test long: Attention with linear biases enables input length extrapolation. In ICLR, 2022
2022
-
[17]
R., Manke, W., Liu, H., Dai, Z., Shazeer, N., and Le, Q
So, D. R., Manke, W., Liu, H., Dai, Z., Shazeer, N., and Le, Q. V. Searching for efficient transformers for language modeling. In NeurIPS, volume 34, 2021
2021
-
[18]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., and Liu, Y. RoFormer : Enhanced transformer with rotary position embedding. arXiv:2104.09864, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Language through a prism: A spectral approach for multiscale language representations
Tamkin, A., Jurafsky, D., and Goodman, N. Language through a prism: A spectral approach for multiscale language representations. In NeurIPS, volume 33, 2020
2020
-
[20]
Attention is all you need
Vaswani, A., et al. Attention is all you need. In NeurIPS, volume 30, 2017
2017
-
[21]
Verma, P. and Pilanci, M. Towards signal processing in large language models. arXiv:2406.10254, 2024
-
[22]
CvT : Introducing convolutions to vision transformers
Wu, H., et al. CvT : Introducing convolutions to vision transformers. In ICCV, 2021
2021
-
[23]
Big Bird : Transformers for longer sequences
Zaheer, M., et al. Big Bird : Transformers for longer sequences. In NeurIPS, volume 33, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.