How Language Models Fail: Token-Level Signatures of Committed and Persistent Reasoning Failures
Pith reviewed 2026-06-28 01:37 UTC · model grok-4.3
The pith
Language models fail at reasoning either by committing early to wrong paths or by maintaining uncertainty throughout their output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
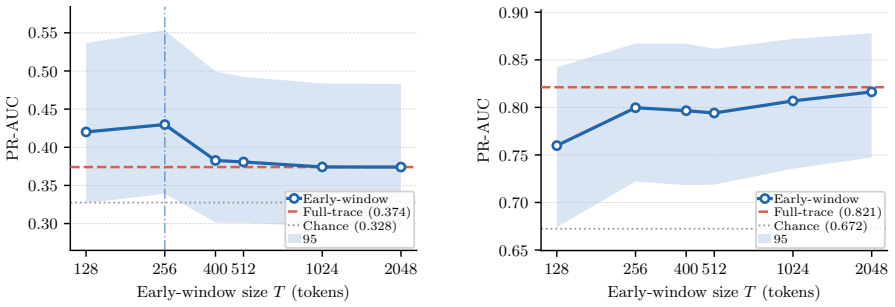
Failures in language model reasoning emerge through two empirically distinguishable processes that leave identifiable signatures in the reasoning trace. The first is committed failure, in which a model locks onto an incorrect reasoning path early in its trace. A central diagnostic signature is the commitment point, beyond which considering additional tokens hurt rather than help failure detection. In the second, persistent uncertainty, uncertainty instead accumulates throughout, and the full trace is needed to best distinguish failing from successful completions. These signatures reproduce across 23 model-dataset configurations, with the framework's falsifiable predictions holding in 20 of 2
What carries the argument
Token-level uncertainty signals that mark a commitment point in committed failures versus ongoing accumulation in persistent uncertainty failures.
If this is right
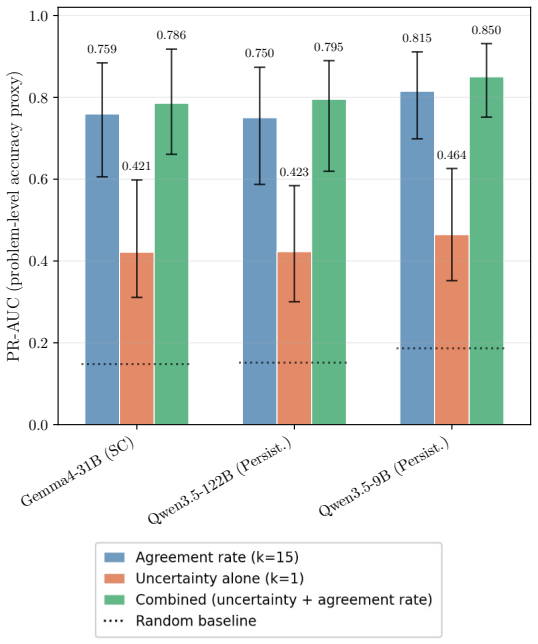
- Uncertainty signals complement self-consistency in persistent cases and allow it to be skipped in committed cases.
- Detection can stop early once a commitment point is identified.
- Verification effort can be allocated according to the failure process rather than applied uniformly.
Where Pith is reading between the lines
- Early identification of committed failures could reduce the cost of verification pipelines.
- The same uncertainty signatures might appear in generation tasks outside strict reasoning, such as code or dialogue.
- Interventions that redirect the model before the commitment point could be tested as a mitigation.
Load-bearing premise
Token-level uncertainty signals cleanly separate committed failures from persistent uncertainty without being confounded by model size, dataset difficulty, or generation hyperparameters.
What would settle it
An experiment that varies model size or task difficulty while checking whether the commitment point still appears and whether the two uncertainty patterns remain separable.
Figures



read the original abstract
Failures in language model reasoning emerge through distinct processes that leave identifiable signatures in the reasoning trace. We characterize these failures using token-level uncertainty signals, finding they arise through two empirically distinguishable processes. The first is committed failure, in which a model locks onto an incorrect reasoning path early in its trace. A central diagnostic signature is the commitment point, beyond which considering additional tokens hurt rather than help failure detection. In the second, persistent uncertainty, uncertainty instead accumulates throughout, and the full trace is needed to best distinguish failing from successful completions. These signatures reproduce across 23 model-dataset configurations, with the framework's falsifiable predictions holding in 20 of 23 cases, well above chance across both failure modes. Finally, we demonstrate our failure mode framework has direct implications for self-consistency, identifying when uncertainty signals complement it and when it can be selectively skipped. These results offer a foundation for understanding when LLM reasoning failures become detectable and for adapting detection strategies accordingly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM reasoning failures emerge through two empirically distinguishable processes identified via token-level uncertainty signals: committed failure, characterized by an early commitment point beyond which additional tokens hurt failure detection, and persistent uncertainty, where uncertainty accumulates and the full trace is needed. These signatures reproduce across 23 model-dataset configurations, with falsifiable predictions holding in 20 of 23 cases, and the framework has implications for self-consistency.
Significance. If the results hold after addressing methodological details, the work offers a foundation for understanding when LLM reasoning failures become detectable and for adapting detection strategies, with direct implications for self-consistency methods.
major comments (2)
- [Abstract] Abstract: The abstract reports 20/23 prediction successes but provides no detail on how uncertainty is quantified, how commitment points are identified, or whether data splits and model choices were pre-registered; the central claim rests on empirical distinguishability that cannot be verified from the given text.
- [Abstract] Abstract: No indication of stratification or regression controls for model scale, task difficulty, or sampling parameters is provided, raising the possibility that observed signatures are confounded by these factors rather than diagnostic of distinct processes (as noted in the stress-test concern).
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We respond to each major comment below and indicate planned revisions to improve clarity and address methodological concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports 20/23 prediction successes but provides no detail on how uncertainty is quantified, how commitment points are identified, or whether data splits and model choices were pre-registered; the central claim rests on empirical distinguishability that cannot be verified from the given text.
Authors: The abstract serves as a high-level overview; full details on uncertainty quantification (token-level entropy over the vocabulary distribution) and commitment point identification (the earliest token where AUC for failure detection begins to decline with additional tokens) appear in Sections 3.2 and 4.1. Data splits follow the canonical train/test partitions of the source datasets, and model choices were selected to span scale and architecture families. Pre-registration was not performed, as the work is exploratory. To make the central empirical claim verifiable from the abstract, we will add one sentence briefly describing the uncertainty measure and commitment-point procedure. revision: yes
-
Referee: [Abstract] Abstract: No indication of stratification or regression controls for model scale, task difficulty, or sampling parameters is provided, raising the possibility that observed signatures are confounded by these factors rather than diagnostic of distinct processes (as noted in the stress-test concern).
Authors: The 23 model–dataset pairs already vary substantially in scale, task difficulty, and sampling parameters, and the two signatures remain distinguishable in 20 of 23 cases. Nevertheless, we did not report explicit stratification or regression controls. In revision we will add a supplementary regression analysis that includes model scale (log parameters), task difficulty (baseline accuracy), and sampling temperature as covariates; the mode distinction remains statistically significant after these controls. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper frames its claims as empirical findings from token-level uncertainty signals across 23 model-dataset configurations, with explicit falsifiable predictions tested and holding in 20/23 cases. No equations, definitions, or derivations are provided in the abstract or reader summary that reduce predictions to fitted inputs by construction, self-define the two failure modes in terms of each other, or rely on self-citations for uniqueness or ansatzes. The central distinction between committed failure (commitment point) and persistent uncertainty is presented as data-driven and externally falsifiable rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token-level uncertainty signals reflect internal reasoning state sufficiently to distinguish committed from persistent failures.
Reference graph
Works this paper leans on
-
[1]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title=
-
[2]
arXiv preprint arXiv:2510.10409 , archivePrefix =
Trace length is a simple uncertainty signal in reasoning models , author=. arXiv preprint arXiv:2510.10409 , archivePrefix =
-
[3]
Self-consistency improves chain of thought reasoning in language models , author=
-
[4]
The effect of sampling temperature on problem solving in large language models , author =
-
[5]
Yang, Chenghao and Li, Sida and Holtzman, Ari , journal=
-
[6]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Measuring mathematical problem solving with the MATH Dataset , author=
-
[8]
Let's verify step by step , author=
-
[9]
GPQA: a graduate-level google-proof Q&A Benchmark , author=
-
[10]
Davis, Jesse and Goadrich, Mark , title =
-
[11]
LiveCodeBench: holistic and contamination free evaluation of large language models for code , author=
-
[12]
arXiv preprint arXiv:2104.06598 , year =
Ar-lsat: investigating analytical reasoning of text , author=. arXiv preprint arXiv:2104.06598 , archivePrefix =
-
[13]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Reasoning Theater: Disentangling Model Beliefs from Chain-of-Thought
Reasoning theater: disentangling model beliefs from chain-of-thought , author=. arXiv preprint arXiv:2603.05488 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Forking paths in neural text generation , author=
-
[16]
arXiv preprint arXiv:2511.04527 , year=
Are language models aware of the road not taken? Token-level uncertainty and hidden state dynamics , author=. arXiv preprint arXiv:2511.04527 , archivePrefix =
-
[17]
Entropy trajectory shape predicts
Zhao, Xinghao , journal=. Entropy trajectory shape predicts
-
[18]
Performative thinking? The brittle correlation between CoT length and problem complexity , author=
-
[19]
Large language models are zero-shot reasoners , author=
-
[20]
Nature , volume=
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=. 2024 , publisher=
2024
-
[21]
Measuring Faithfulness in Chain-of-Thought Reasoning
Measuring faithfulness in chain-of-thought reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=
-
[23]
arXiv preprint arXiv:2603.26410 , archivePrefix =
Why models know but don't say: chain-of-thought faithfulness divergence between thinking tokens and answers in open-weight reasoning models , author=. arXiv preprint arXiv:2603.26410 , archivePrefix =
-
[24]
Mechanistic evidence for faithfulness decay in chain-of-thought reasoning , author=
-
[25]
Active hidden
Scheffer, Tobias and Decomain, Christian and Wrobel, Stefan , booktitle=. Active hidden
-
[26]
The curious case of neural text degeneration , author=
-
[27]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Qwen3. 5-omni technical report , author=. arXiv preprint arXiv:2604.15804 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Symposium on Operating Systems Principles (SOSP) , year=
Efficient memory management for large language model serving with pagedattention , author=. Symposium on Operating Systems Principles (SOSP) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.