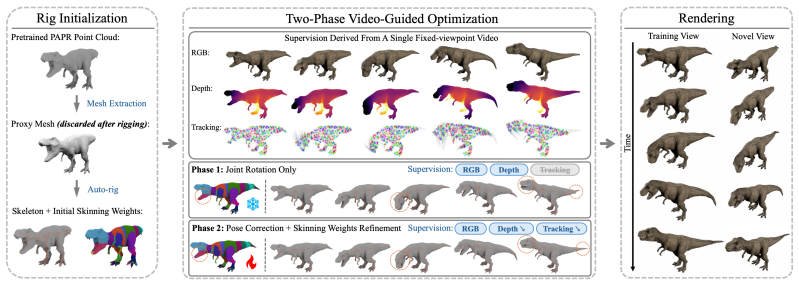
RigPAPR: Rig-Based Animation of Static Neural Point Clouds from a Fixed-Viewpoint Video
Pith reviewed 2026-06-28 01:48 UTC · model grok-4.3
The pith
RigPAPR animates static neural point clouds from a fixed-viewpoint video by auto-rigging and applying direct linear blend skinning without mesh proxies or per-primitive corrections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
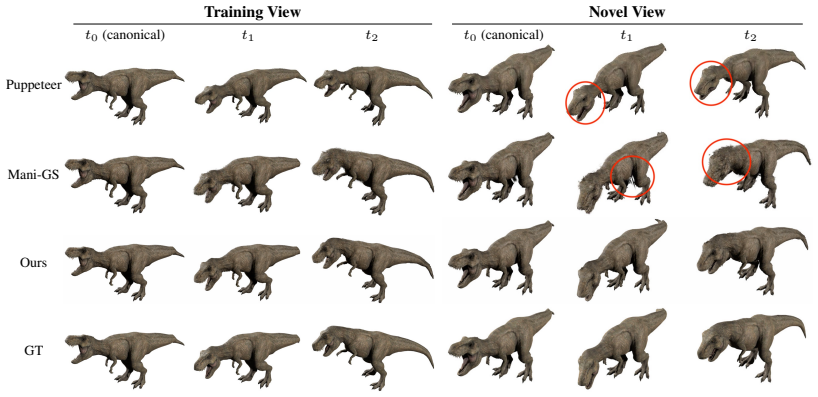
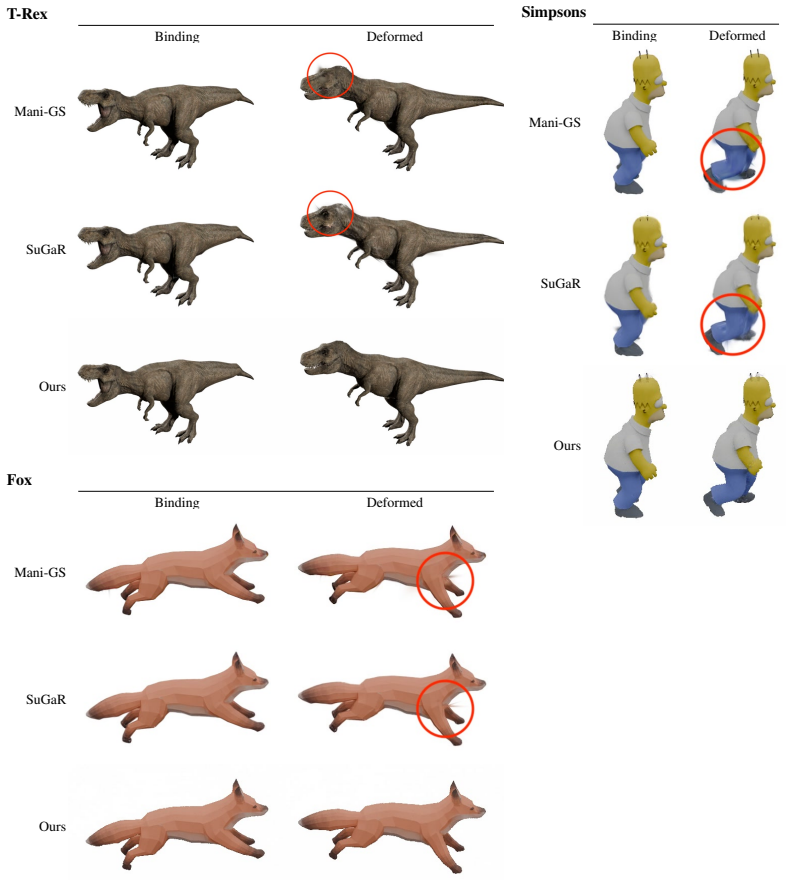
We present RigPAPR, which auto-rigs a static PAPR cloud and drives it under direct LBS from a single fixed-viewpoint video, without mesh proxy, pose-dependent correction, or category template. On synthetic subjects, RigPAPR matches the strongest baseline at the supervised view and exceeds mesh-based and Gaussian-splatting baselines at novel views by 3+dB PSNR, with cleaner joint-boundary renderings of both synthetic and real subjects.
What carries the argument
Proximity Attention Point Rendering (PAPR), which recomposes each pixel at render time from the positions of deformed primitives rather than storing per-primitive shapes that must tile in the canonical pose.
If this is right
- A static PAPR reconstruction can be turned into a drivable asset from one fixed-view video without category templates.
- Direct LBS on PAPR primitives produces fewer joint-boundary artifacts than the same skinning applied to Gaussian splats or meshes.
- Novel-view PSNR improves by more than 3 dB over mesh and Gaussian baselines while matching supervised-view performance.
- The same pipeline works for both synthetic and real captured subjects.
Where Pith is reading between the lines
- The absence of fixed per-primitive shapes may allow PAPR-style rendering to handle non-rigid deformations more gracefully than shape-carrying primitives.
- Auto-rigging from a single view could be combined with image-to-video models to create 3D assets from generated driving sequences.
- The method may reduce reliance on explicit mesh proxies in animation pipelines that start from neural point clouds.
Load-bearing premise
That recomposing pixels from the deformed positions of the primitives at render time will automatically restore surface continuity at joints under rigid linear blend skinning.
What would settle it
Rendering the rigged PAPR model under strong articulation and observing persistent gaps or spikes at joint boundaries in the output images.
Figures

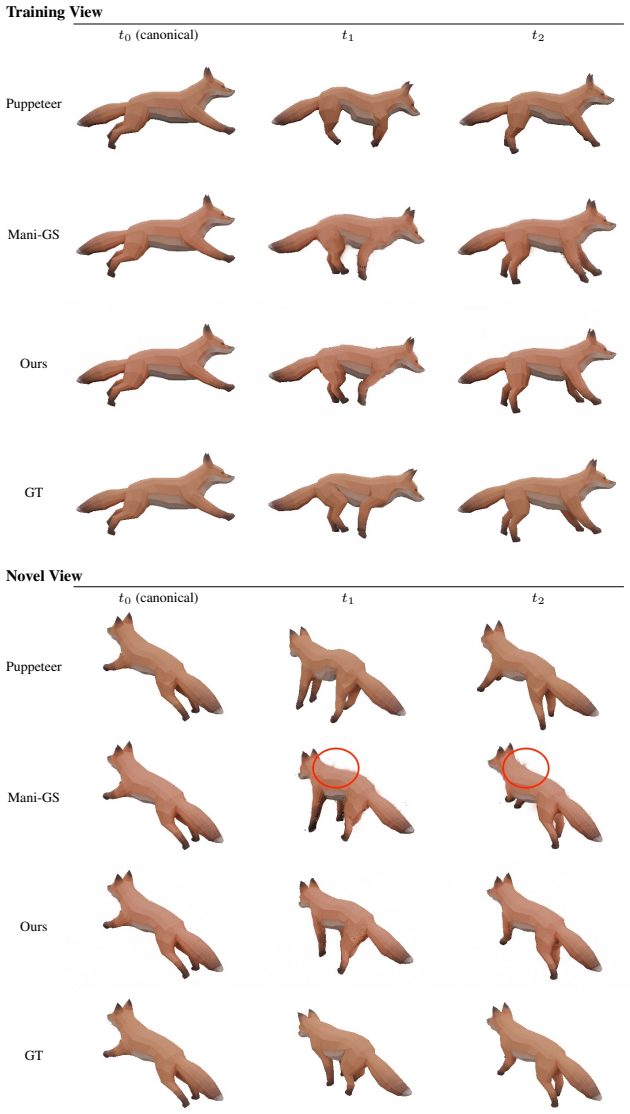
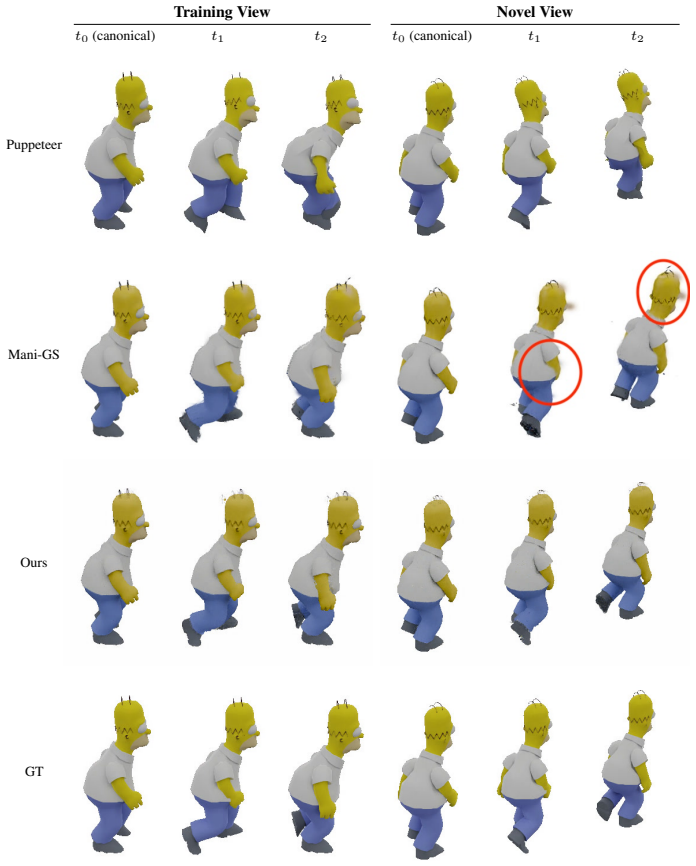




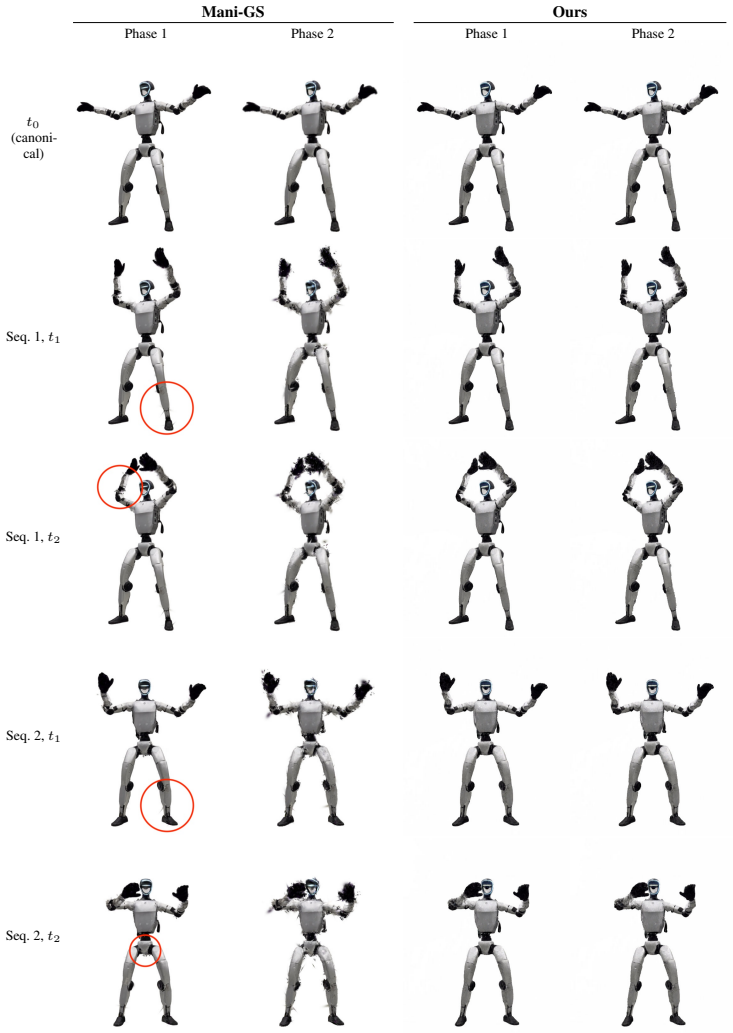

read the original abstract
Static neural point reconstructions capture a subject at high fidelity from posed images. Given such a reconstruction, we aim to animate it to follow a monocular fixed-viewpoint driving video of the subject, whether captured or produced by image-to-video (I2V) generation, and to recover a rigged, re-posable 3D asset. Existing methods deform Gaussian splats through direct linear blend skinning (LBS) or mesh proxies, both of which are prone to joint-boundary artifacts under articulation, even with per-primitive corrections. We trace the artifact to the representation: each splat carries an individual shape calibrated in the canonical pose to tile with its neighbours. Under rigid LBS, each splat moves with its bone but cannot bend, so the canonical tiling breaks at joint boundaries into gaps and spikes. Proximity attention point rendering (PAPR) instead carries no per-primitive shape; each pixel is recomposed at render time from the deformed primitives' positions, so the surface re-forms naturally with the articulation. We present RigPAPR, which auto-rigs a static PAPR cloud and drives it under direct LBS from a single fixed-viewpoint video, without mesh proxy, pose-dependent correction, or category template. On synthetic subjects, RigPAPR matches the strongest baseline at the supervised view and exceeds mesh-based and Gaussian-splatting baselines at novel views by 3+dB PSNR, with cleaner joint-boundary renderings of both synthetic and real subjects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
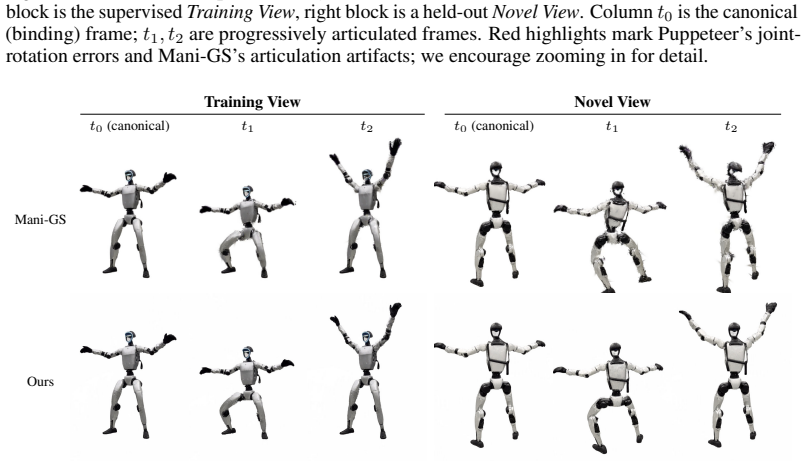
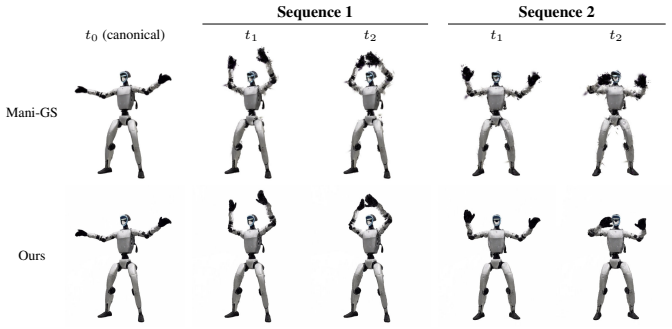
Summary. The paper introduces RigPAPR, a pipeline that auto-rigs a static PAPR (Proximity Attention Point Rendering) point cloud and drives it via direct linear blend skinning (LBS) from a single fixed-viewpoint video. It contrasts PAPR's position-only primitives, whose surface is recomposed per-pixel at render time, against Gaussian splats and mesh proxies whose fixed per-primitive shapes produce joint-boundary gaps and spikes under articulation. On synthetic subjects the method matches the strongest baseline at the supervised view and exceeds mesh-based and Gaussian-splatting baselines by more than 3 dB PSNR at novel views, while producing qualitatively cleaner joint boundaries on both synthetic and real subjects.
Significance. If the reported gains and artifact reduction hold under a reproducible protocol, the work supplies a concrete, template-free alternative to per-primitive correction or mesh proxy methods for animating neural point reconstructions. The central representational distinction—removing fixed per-primitive geometry so that the surface re-forms naturally under LBS—is internally consistent and directly addresses the mechanism that generates the cited artifacts.
minor comments (3)
- [Abstract] The abstract states quantitative PSNR gains and qualitative improvements but supplies no evaluation protocol, list of baselines, number of subjects, or error analysis; these details are required to assess whether the 3 dB margin is robust or subject to post-hoc selection.
- The claim that PAPR 'carries no per-primitive shape' would benefit from an explicit equation or pseudocode fragment showing how the per-pixel recomposition is performed after LBS deformation (e.g., the weighting or attention mechanism).
- Figure captions and table headers should explicitly label which views are supervised versus novel and which baselines are mesh-based versus splatting-based to allow direct comparison with the text claims.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The referee's description of the method, its contrast to Gaussian splats and mesh proxies, and the reported gains accurately reflect the manuscript.
Circularity Check
No significant circularity
full rationale
The paper introduces RigPAPR as an empirical pipeline that auto-rigs a static PAPR point cloud and drives it via direct LBS from a fixed-viewpoint video. The core distinction (PAPR recomposes pixels from deformed positions at render time, unlike per-primitive shapes in Gaussian splats) is a representational property stated directly in the abstract and does not reduce any reported PSNR or artifact claim to a fitted parameter or self-citation by construction. Performance numbers are presented as measured outcomes on synthetic and real subjects against baselines; no equations, uniqueness theorems, or ansatzes are shown to collapse into the inputs. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automatic rigging and animation of 3D characters.ACM Transactions on Graphics, 26(3):72:1–72:8, 2007
Ilya Baran and Jovan Popovi ´c. Automatic rigging and animation of 3D characters.ACM Transactions on Graphics, 26(3):72:1–72:8, 2007
2007
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Video generation models as world simulators, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators, 2024
2024
-
[4]
SV-GS: Sparse view 4D reconstruction with skeleton-driven gaussian splatting, 2026
Jun-Jee Chao and V olkan Isler. SV-GS: Sparse view 4D reconstruction with skeleton-driven gaussian splatting, 2026
2026
-
[5]
Kling-Omni technical report, 2025
Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jing He, Kang He, Xiao Hu, Xiaohuan Hu, Boyuan Jiang, Fangyuan Kong, Hang Li, Jie Li, Qingyu Li, Shen Li, Xiaohan Li, Yan Qiang Li, Jiajun Liang, Borui Liao, Yiqiao Liao, Weihong Lin, Quande Liu, Xiaokun Liu, Yilun Liu, Yuliang Liu, Shun Lu, Hangyu Mao, Yu-Fei Mao, Haodong O...
2025
-
[6]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3D objects.arXiv preprint arXiv:2212.08051, 2022
-
[7]
Mani-GS: Gaussian splatting manipulation with triangular mesh
Xiangjun Gao, Xiaoyu Li, Yiyu Zhuang, Qi Zhang, Wenbo Hu, Chaopeng Zhang, Yao Yao, Ying Shan, and Long Quan. Mani-GS: Gaussian splatting manipulation with triangular mesh. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21392– 21402, 2025
2025
-
[8]
Diffusion as shader: 3D-aware video diffusion for versatile video generation control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, Wenping Wang, and Yuan Liu. Diffusion as shader: 3D-aware video diffusion for versatile video generation control. InACM SIGGRAPH 2025 Conference Papers, pages 62:1–62:12. ACM, 2025
2025
-
[9]
SuGaR: Surface-aligned gaussian splatting for efficient 3D mesh reconstruction and high-quality mesh rendering
Antoine Guédon and Vincent Lepetit. SuGaR: Surface-aligned gaussian splatting for efficient 3D mesh reconstruction and high-quality mesh rendering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5354–5363, 2024
2024
-
[10]
Real-time meshless deformation.Computer Animation and Virtual Worlds, 16(3-4):189–200, 2005
Xiaohu Guo and Hong Qin. Real-time meshless deformation.Computer Animation and Virtual Worlds, 16(3-4):189–200, 2005
2005
-
[11]
SC- GS: Sparse-controlled Gaussian splatting for editable dynamic scenes
Yi-Hua Huang, Yang-Tian Sun, Ziyi Yang, Xiaoyang Lyu, Yan-Pei Cao, and Xiaojuan Qi. SC- GS: Sparse-controlled Gaussian splatting for editable dynamic scenes. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4220–4230, 2024
2024
-
[12]
NeRFshop: Interactive editing of neural radiance fields.Proceedings of the ACM on Computer Graphics and Interactive Techniques, 6(1), May 2023
Clément Jambon, Bernhard Kerbl, Georgios Kopanas, Stavros Diolatzis, Thomas Leimkühler, and George Drettakis. NeRFshop: Interactive editing of neural radiance fields.Proceedings of the ACM on Computer Graphics and Interactive Techniques, 6(1), May 2023
2023
-
[13]
CoTracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. CoTracker3: Simpler and better point tracking by pseudo-labelling real videos. In IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[14]
Skinning with dual quaternions
Ladislav Kavan, Steven Collins, Jiˇrí Žára, and Carol O’Sullivan. Skinning with dual quaternions. InProceedings of the 2007 Symposium on Interactive 3D Graphics and Games, pages 39–46, 2007. 10
2007
-
[15]
Geometric skinning with approximate dual quaternion blending.ACM Transactions on Graphics, 27(4):1–23, 2008
Ladislav Kavan, Steven Collins, Ji ˇrí Žára, and Carol O’Sullivan. Geometric skinning with approximate dual quaternion blending.ACM Transactions on Graphics, 27(4):1–23, 2008
2008
-
[16]
3D Gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3D Gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
2023
-
[17]
Rigidity-aware 3D gaussian deformation from a single image
Jinhyeok Kim, Jaehun Bang, Seunghyun Seo, and Kyungdon Joo. Rigidity-aware 3D gaussian deformation from a single image. InSIGGRAPH Asia 2025 Conference Papers, pages 179:1– 179:11. ACM, 2025
2025
-
[18]
Mor- phGS: Morphology-adaptive articulated 3D motion transfer from videos, 2026
Taeyeon Kim, Youngju Na, Jumin Lee, Sebin Lee, Minhyuk Sung, and Sung-Eui Yoon. Mor- phGS: Morphology-adaptive articulated 3D motion transfer from videos, 2026
2026
-
[19]
HUGS: Human Gaussian splats
Muhammed Kocabas, Jen-Hao Rick Chang, James Gabriel, Oncel Tuzel, and Anurag Ranjan. HUGS: Human Gaussian splats. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[20]
Pulsar: Efficient sphere-based neural rendering
Christoph Lassner and Michael Zollhöfer. Pulsar: Efficient sphere-based neural rendering. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1440–1449, 2021
2021
-
[21]
OffsetOPT: Explicit surface reconstruction without normals
Huan Lei. OffsetOPT: Explicit surface reconstruction without normals. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[22]
Pose space deformation: A unified approach to shape interpolation and skeleton-driven deformation
John P Lewis, Matt Cordner, and Nickson Fong. Pose space deformation: A unified approach to shape interpolation and skeleton-driven deformation. InProceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, pages 165–172, 2000
2000
-
[23]
Black, Hao Li, and Javier Romero
Tianye Li, Timo Bolkart, Michael J. Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4D scans.ACM Transactions on Graphics, 36:1–17, 2017
2017
-
[24]
Taylor, Mathias Unberath, Ming-Yu Liu, and Chen-Hsuan Lin
Zhaoshuo Li, Thomas Müller, Alex Evans, Russell H. Taylor, Mathias Unberath, Ming-Yu Liu, and Chen-Hsuan Lin. Neuralangelo: High-fidelity neural surface reconstruction. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[25]
Animatable Gaussians: Learning pose- dependent Gaussian maps for high-fidelity human avatar modeling
Zhe Li, Zerong Zheng, Lizhen Wang, and Yebin Liu. Animatable Gaussians: Learning pose- dependent Gaussian maps for high-fidelity human avatar modeling. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[26]
DreamMesh4D: Video-to-4D generation with sparse- controlled gaussian-mesh hybrid representation
Zhiqi Li, Yiming Chen, and Peidong Liu. DreamMesh4D: Video-to-4D generation with sparse- controlled gaussian-mesh hybrid representation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[27]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
RigAnything: Template-free autoregressive rigging for diverse 3D assets.ACM Transactions on Graphics, 44(4):1–12, 2025
Isabella Liu, Zhan Xu, Wang Yifan, Hao Tan, Zexiang Xu, Xiaolong Wang, Hao Su, and Zifan Shi. RigAnything: Template-free autoregressive rigging for diverse 3D assets.ACM Transactions on Graphics, 44(4):1–12, 2025
2025
-
[29]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: A skinned multi-person linear model.ACM Trans. Graphics (Proc. SIGGRAPH Asia), 34(6):248:1–248:16, October 2015
2015
-
[30]
Joint-dependent local deformations for hand animation and object grasping
Nadia Magnenat-Thalmann, Richard Laperrière, and Daniel Thalmann. Joint-dependent local deformations for hand animation and object grasping. InProceedings on Graphics Interface’88, pages 26–33, 1989
1989
-
[31]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision (ECCV), 2020. 11
2020
-
[32]
Barron, Sofien Bouaziz, Dan B Goldman, Steven M
Keunhong Park, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 5865–5874, 2021
2021
-
[33]
D-NeRF: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-NeRF: Neural radiance fields for dynamic scenes. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10318–10327, 2021
2021
-
[34]
GaussianAvatars: Photorealistic head avatars with rigged 3D Gaussians
Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, and Matthias Nießner. GaussianAvatars: Photorealistic head avatars with rigged 3D Gaussians. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[35]
3DGS- Avatar: Animatable avatars via deformable 3D gaussian splatting
Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, and Siyu Tang. 3DGS- Avatar: Animatable avatars via deformable 3D gaussian splatting. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5020–5030, 2024
2024
-
[36]
Rivers and Doug L
Alec R. Rivers and Doug L. James. FastLSM: Fast lattice shape matching for robust real-time deformation. InACM SIGGRAPH 2007 Papers, pages 82:1–82:6, 2007
2007
-
[37]
ADOP: Approximate differentiable one-pixel point rendering.ACM Transactions on Graphics, 41(4):99:1–99:14, 2022
Darius Rückert, Linus Franke, and Marc Stamminger. ADOP: Approximate differentiable one-pixel point rendering.ACM Transactions on Graphics, 41(4):99:1–99:14, 2022
2022
-
[38]
Meshless simulation for skeleton driven elastic deformation.Journal of Zhejiang University-Science A, 7(9):1596–1602, 2006
Chao Song, Hong-xin Zhang, Jin Huang, and Hu-jun Bao. Meshless simulation for skeleton driven elastic deformation.Journal of Zhejiang University-Science A, 7(9):1596–1602, 2006
2006
-
[39]
Puppeteer: Rig and animate your 3D models
Chaoyue Song, Xiu Li, Fan Yang, Zhongcong Xu, Jiacheng Wei, Fayao Liu, Jiashi Feng, Guosheng Lin, and Jianfeng Zhang. Puppeteer: Rig and animate your 3D models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[40]
As-rigid-as-possible surface modeling
Olga Sorkine-Hornung and Marc Alexa. As-rigid-as-possible surface modeling. InEurographics Symposium on Geometry Processing, volume 4, pages 109–116, 2007
2007
-
[41]
Template-free articulated neural point clouds for reposable view synthesis
Lukas Uzolas, Elmar Eisemann, and Petr Kellnhofer. Template-free articulated neural point clouds for reposable view synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, pages 31621–31637, 2023
2023
-
[42]
Joanna Waczy´nska, Piotr Borycki, Sławomir Tadeja, Jacek Tabor, and Przemysław Spurek. GaMeS: Mesh-based adapting and modification of Gaussian splatting.arXiv preprint arXiv:2402.01459, 2024
-
[43]
Template-free articulated Gaussian splatting for real-time reposable dynamic view synthesis
Diwen Wan, Yuxiang Wang, Ruijie Lu, and Gang Zeng. Template-free articulated Gaussian splatting for real-time reposable dynamic view synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, pages 62000–62023, 2024
2024
-
[44]
NeuS: Learning neural implicit surfaces by volume rendering for multi-view reconstruction
Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. NeuS: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[45]
Bovik, Hamid R
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600– 612, 2004
2004
-
[46]
4D Gaussian Splatting for real-time dynamic scene rendering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4D Gaussian Splatting for real-time dynamic scene rendering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20310– 20320, 2024
2024
-
[47]
SC4D: Sparse- controlled video-to-4D generation and motion transfer
Zijie Wu, Chaohui Yu, Yanqin Jiang, Chenjie Cao, Fan Wang, and Xiang Bai. SC4D: Sparse- controlled video-to-4D generation and motion transfer. InEuropean Conference on Computer Vision (ECCV), pages 361–379. Springer, 2024
2024
-
[48]
AnimaMimic: Imitating 3D animation from video priors, 2025
Tianyi Xie, Yunuo Chen, Yaowei Guo, Yin Yang, Bolei Zhou, Demetri Terzopoulos, Ying Jiang, and Chenfanfu Jiang. AnimaMimic: Imitating 3D animation from video priors, 2025. 12
2025
-
[49]
Point-NeRF: Point-based neural radiance fields
Qiangeng Xu, Zexiang Xu, Julien Philip, Sai Bi, Zhixin Shu, Kalyan Sunkavalli, and Ulrich Neumann. Point-NeRF: Point-based neural radiance fields. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5438–5448, 2022
2022
-
[50]
RigNet: Neural rigging for articulated characters.ACM Transactions on Graphics, 39(4):58:1–58:14, 2020
Zhan Xu, Yang Zhou, Evangelos Kalogerakis, Chris Landreth, and Karan Singh. RigNet: Neural rigging for articulated characters.ACM Transactions on Graphics, 39(4):58:1–58:14, 2020
2020
-
[51]
MoRig: Motion-aware rigging of character meshes from point clouds
Zhan Xu, Yang Zhou, Li Yi, and Evangelos Kalogerakis. MoRig: Motion-aware rigging of character meshes from point clouds. InSIGGRAPH Asia 2022 Conference Papers, 2022
2022
-
[52]
Deformable 3D Gaussians for high-fidelity monocular dynamic scene reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3D Gaussians for high-fidelity monocular dynamic scene reconstruction. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 20331–20341, 2024
2024
-
[53]
RigGS: Rigging of 3D gaussians for modeling articulated objects in videos
Yuxin Yao, Zhi Deng, and Junhui Hou. RigGS: Rigging of 3D gaussians for modeling articulated objects in videos. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5592–5601, 2025
2025
-
[54]
A3-GS: Animate any articulated objects with 3D Gaussian splatting, 2026
Yuxin Yao and Junhui Hou. A3-GS: Animate any articulated objects with 3D Gaussian splatting, 2026
2026
-
[55]
PhysRig: Differen- tiable physics-based skinning and rigging framework for realistic articulated object modeling
Hao Zhang, Haolan Xu, Chun Feng, Varun Jampani, and Narendra Ahuja. PhysRig: Differen- tiable physics-based skinning and rigging framework for realistic articulated object modeling. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[56]
One model to rig them all: Diverse skeleton rigging with UniRig.ACM Transactions on Graphics, 44(4):1–18, 2025
Jia-Peng Zhang, Cheng-Feng Pu, Meng-Hao Guo, Yan-Pei Cao, and Shi-Min Hu. One model to rig them all: Diverse skeleton rigging with UniRig.ACM Transactions on Graphics, 44(4):1–18, 2025
2025
-
[57]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 586–595, 2018
2018
-
[58]
Motion blender gaussian splatting for dynamic reconstruction
Xinyu Zhang, Haonan Chang, Yuhan Liu, and Abdeslam Boularias. Motion blender gaussian splatting for dynamic reconstruction. InProceedings of the 9th Conference on Robot Learning (CoRL), volume 305 ofProceedings of Machine Learning Research, pages 5107–5128. PMLR, 2025
2025
-
[59]
decays a→0
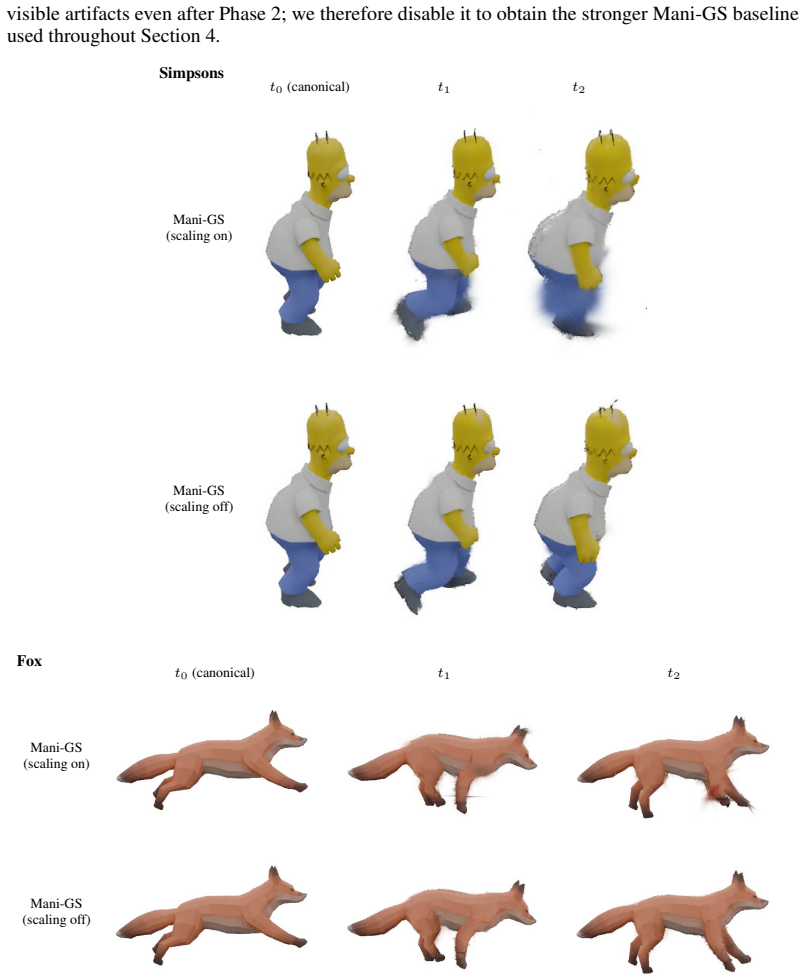
Yanshu Zhang, Shichong Peng, Alireza Moazeni, and Ke Li. PAPR: Proximity attention point rendering. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 13 This appendix is organized into four parts. Section A extends the qualitative comparison of the main paper to the four remaining synthetic subjects (fox, Simpsons, wolf, spider) and to ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.