AgileOS: A GPU Operating System Layer for Protected CUDA Services
Pith reviewed 2026-06-28 00:14 UTC · model grok-4.3
The pith
AgileOS virtualizes CUDA at the library boundary so a trusted worker can mediate access and protect service state from applications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
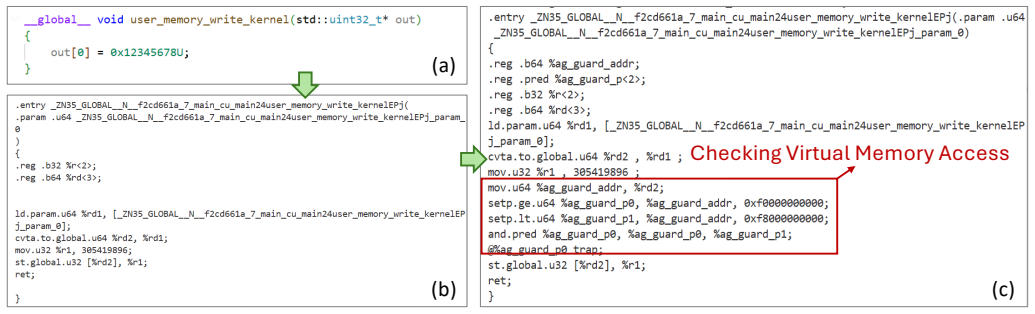
AgileOS virtualizes CUDA at the library boundary: applications link against client-side CUDA Runtime, Driver, and selected library shims, while a trusted runtime worker owns the real CUDA context and mediates supported operations. To protect service state and module interfaces, AgileOS defines a GPU memory-management model that separates user allocations from protected module/MMIO ranges, using pointer validation and memory access guards via PTX injection.
What carries the argument
The library-boundary virtualization with a trusted runtime worker owning the CUDA context and PTX-injected memory access guards for separating user and protected allocations.
If this is right
- Applications can interact with protected GPU services without direct access to context or device pointers.
- Library shims enable compatibility with existing code while routing calls to the worker.
- The memory model prevents exposure of protected ranges to untrusted kernels.
- Modular design supports various services and libraries such as cuFFT and PyTorch.
Where Pith is reading between the lines
- This design could enable more secure sharing of GPU resources in multi-user environments.
- PTX injection might be adaptable for other forms of runtime enforcement in GPU code.
- Future extensions could include support for additional device interactions like storage or networking.
Load-bearing premise
That applications cannot bypass the client-side shims to access the real CUDA context directly, and that PTX-level guards can enforce memory separation without breaking library compatibility.
What would settle it
An application that successfully accesses protected module state or MMIO regions without mediation by the trusted worker would disprove the isolation claim.
Figures

read the original abstract
Modern GPU applications increasingly interact with storage systems, network devices, vendor libraries, and GPU-resident services rather than executing only isolated compute kernels. This shift creates a need for operating-system-like protection around GPU services, where service metadata, device queues, memory-mapped I/O regions, and library-internal state should not be directly exposed to untrusted application kernels. However, today's CUDA programming model, by default, still gives each application direct ownership of its CUDA context, device pointers, runtime handles, module loading path, and kernel launches, leaving protected GPU services to build their own ad hoc interfaces and isolation mechanisms. This paper presents the initial design and prototype scope of AgileOS, a GPU operating-system layer for protected CUDA services. AgileOS virtualizes CUDA at the library boundary: applications link against client-side CUDA Runtime, Driver, and selected library shims, while a trusted runtime worker owns the real CUDA context and mediates supported operations. To protect service state and module interfaces, AgileOS also defines a GPU memory-management model that separates user allocations from protected module/MMIO ranges, using pointer validation and memory access guards via PTX injection. AgileOS is modularized and flexible, supporting a range of protected services and existing libraries such as cuFFT and PyTorch. The prototype includes client-side interceptors, worker-side CUDA handlers, virtualized CUDA object tables, protected AgileOS modules, a GPU memory manager that separates user allocations from protected module/MMIO ranges, selected trusted library adapters, and the PTX-level kernel memory guard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the initial design and prototype scope of AgileOS, a GPU operating-system layer for protected CUDA services. It virtualizes CUDA at the library boundary by having applications link against client-side CUDA Runtime, Driver, and library shims, while a trusted runtime worker owns the real CUDA context and mediates operations. Protection of service state uses a GPU memory-management model separating user allocations from protected module/MMIO ranges via pointer validation and PTX injection guards. The prototype includes client-side interceptors, worker-side handlers, virtualized object tables, protected modules, a memory manager, trusted library adapters, and the PTX-level kernel memory guard. It claims support for libraries such as cuFFT and PyTorch.
Significance. If the protection claims hold, AgileOS could address a real need for OS-like isolation around GPU services in modern applications interacting with storage, networks, and vendor libraries. However, the manuscript supplies no evaluation data, security analysis, performance numbers, or bypass testing, so the significance cannot be assessed beyond the architectural proposal itself.
major comments (2)
- [Prototype description] Prototype description (abstract and full design section): The central protection claim rests on the assumption that linking against client-side shims prevents direct CUDA context ownership and that PTX injection reliably separates user allocations from protected ranges. No coverage analysis of CUDA entry points, direct driver handles, inline PTX, or module loading paths is provided, nor any attack surface evaluation.
- [Memory management model] Memory management model (abstract): The PTX-level memory access guards are presented as enforcing separation, but the manuscript contains no formal argument, test cases, or compatibility analysis showing that guards catch all loads/stores to protected MMIO/module ranges without false negatives or breaking existing libraries.
minor comments (1)
- The abstract and prototype list could benefit from explicit section numbering or a diagram of the client/worker boundary to improve readability of the modular design.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the scope of our initial design and prototype. The manuscript focuses on the architecture and implementation of the virtualization layer rather than a complete security evaluation. We respond to each major comment below.
read point-by-point responses
-
Referee: [Prototype description] Prototype description (abstract and full design section): The central protection claim rests on the assumption that linking against client-side shims prevents direct CUDA context ownership and that PTX injection reliably separates user allocations from protected ranges. No coverage analysis of CUDA entry points, direct driver handles, inline PTX, or module loading paths is provided, nor any attack surface evaluation.
Authors: We agree that the manuscript lacks a coverage analysis of CUDA entry points, direct driver handles, inline PTX, module loading paths, and attack surface evaluation. This is because the work presents an initial design and prototype scope; a full security analysis and bypass testing are outside the current contribution. We will revise the manuscript to explicitly discuss the assumptions, the limited set of supported entry points in the prototype, and the planned directions for comprehensive analysis. revision: partial
-
Referee: [Memory management model] Memory management model (abstract): The PTX-level memory access guards are presented as enforcing separation, but the manuscript contains no formal argument, test cases, or compatibility analysis showing that guards catch all loads/stores to protected MMIO/module ranges without false negatives or breaking existing libraries.
Authors: We acknowledge that the manuscript provides no formal argument, test cases, or compatibility analysis for the PTX guards. The current prototype implements the guards as part of the memory manager, but without the requested verification. We will add a revised section describing the guard insertion mechanism, its intended coverage for loads/stores, and any observed compatibility with the supported libraries (cuFFT, PyTorch), while noting the absence of exhaustive testing. revision: partial
Circularity Check
No circularity: architectural design proposal without derivations or fitted predictions
full rationale
The paper presents an architectural proposal for AgileOS, describing a virtualization approach at the CUDA library boundary with PTX injection for memory guards. No equations, parameter fittings, predictions, or derivation chains are present in the abstract or described content. The work relies on design choices and prototype implementation rather than any self-referential mathematical reductions or self-citation load-bearing claims. This is a standard non-finding for systems papers that do not claim first-principles derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Today's CUDA programming model gives each application direct ownership of its CUDA context, device pointers, runtime handles, module loading path, and kernel launches.
Reference graph
Works this paper leans on
-
[1]
Deep Learning Workload Scheduling in GPU Datacenters: A Survey,
Z. Ye, W. Gao, Q. Hu, P. Sun, X. Wang, Y . Luo, T. Zhang, and Y . Wen, “Deep Learning Workload Scheduling in GPU Datacenters: A Survey,” ACM Computing Surveys, vol. 56, no. 6, pp. 1–38, 2024
2024
-
[2]
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better,
G. Menghani, “Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better,”ACM Computing Surveys, vol. 55, no. 12, pp. 1–37, 2023
2023
-
[3]
Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems,
X. Miao, G. Oliaro, Z. Zhang, X. Cheng, H. Jin, T. Chen, and Z. Jia, “Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems,”ACM Computing Surveys, vol. 58, no. 1, pp. 1–37, 2025
2025
-
[4]
BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing,
T. Liu, Y . Chen, D. Li, C. Wu, Y . Zhu, J. He, Y . Peng, H. Chen, H. Chen, and C. Guo, “BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), 2023, pp. 103–118
2023
-
[5]
GraphBLAST: A High- Performance Linear Algebra-based Graph Framework on the GPU,
C. Yang, A. Buluc ¸, and J. D. Owens, “GraphBLAST: A High- Performance Linear Algebra-based Graph Framework on the GPU,” ACM Transactions on Mathematical Software (TOMS), vol. 48, no. 1, pp. 1–51, 2022
2022
-
[6]
gSampler: General and Efficient GPU-based Graph Sampling for Graph Learning,
P. Gong, R. Liu, Z. Mao, Z. Cai, X. Yan, C. Li, M. Wang, and Z. Li, “gSampler: General and Efficient GPU-based Graph Sampling for Graph Learning,” inProceedings of the 29th Symposium on Operating Systems Principles, 2023, pp. 562–578
2023
-
[7]
Efficient and Scalable Graph Pattern Mining on GPUs,
X. Chenet al., “Efficient and Scalable Graph Pattern Mining on GPUs,” in16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), 2022, pp. 857–877
2022
-
[8]
The Transformational Role of GPU Computing and Deep Learning in Drug Discovery,
M. Pandey, M. Fernandez, F. Gentile, O. Isayev, A. Tropsha, A. C. Stern, and A. Cherkasov, “The Transformational Role of GPU Computing and Deep Learning in Drug Discovery,”Nature Machine Intelligence, vol. 4, no. 3, pp. 211–221, 2022
2022
-
[9]
Jax-fem: A differentiable gpu-accelerated 3d finite element solver for automatic inverse design and mechanistic data science,
T. Xue, S. Liao, Z. Gan, C. Park, X. Xie, W. K. Liu, and J. Cao, “Jax-fem: A differentiable gpu-accelerated 3d finite element solver for automatic inverse design and mechanistic data science,”Computer Physics Communications, vol. 291, p. 108802, 2023
2023
-
[10]
cuquantum sdk: A high-performance library for accelerating quantum science,
H. Bayraktar, A. Charara, D. Clark, S. Cohen, T. Costa, Y .-L. L. Fang, Y . Gao, J. Guan, J. Gunnels, A. Haidaret al., “cuquantum sdk: A high-performance library for accelerating quantum science,” in2023 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1. IEEE, 2023, pp. 1050–1061
2023
-
[11]
GPU-Initiated On-Demand High- Throughput Storage Access in the BaM System Architecture,
Z. Qureshi, V . S. Mailthody, I. Gelado, S. Min, A. Masood, J. Park, J. Xiong, C. J. Newburn, D. Vainbrand, I.-H. Chung, M. Gar- land, W. Dally, and W.-m. Hwu, “GPU-Initiated On-Demand High- Throughput Storage Access in the BaM System Architecture,” inPro- ceedings of the 28th ACM International Conference on Architectural Support for Programming Languages...
2023
-
[12]
GMT: GPU Orchestrated Memory Tiering for the Big Data Era,
C.-H. Chang, J. Han, A. Sivasubramaniam, V . Sharma Mailthody, Z. Qureshi, and W.-M. Hwu, “GMT: GPU Orchestrated Memory Tiering for the Big Data Era,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2024, pp. 464–478
2024
-
[13]
AGILE: Lightweight and Efficient Asynchronous GPU-SSD Integration,
Z. Yang, J. Zhuang, X. Chen, A. Jones, and P. Zhou, “AGILE: Lightweight and Efficient Asynchronous GPU-SSD Integration,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2025, pp. 1028–1042
2025
-
[14]
Asynchrony and GPUs: Bridging this Dichotomy for I/O with AGIO,
J. Han, A. Sivasubramaniam, C.-H. Chang, V . S. Mailthody, Z. Qureshi, and W.-M. Hwu, “Asynchrony and GPUs: Bridging this Dichotomy for I/O with AGIO,” inProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2026, pp. 208–222
2026
-
[15]
GeminiFS: A Companion File System for GPUs,
S. Qiu, W. Liu, Y . Hu, J. Yan, Z. Shen, X. Yao, R. Chen, G. Zhang, and Y . Zhang, “GeminiFS: A Companion File System for GPUs,” in 23rd USENIX Conference on File and Storage Technologies (FAST 25). Santa Clara, CA: USENIX Association, Feb. 2025, pp. 221–236
2025
-
[16]
Managing Scalable Direct Storage Accesses for GPUs with GoFS,
S. Li, Y . E. Zhou, Y . Xue, Y . Xu, and J. Huang, “Managing Scalable Direct Storage Accesses for GPUs with GoFS,” inProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, 2025, pp. 979–995
2025
-
[17]
FpgaNIC: An FPGA-based Versatile 100Gb SmartNIC for GPUs,
Z. Wang, H. Huang, J. Zhang, F. Wu, and G. Alonso, “FpgaNIC: An FPGA-based Versatile 100Gb SmartNIC for GPUs,” in2022 USENIX Annual Technical Conference (USENIX ATC 22), 2022, pp. 967–986
2022
-
[18]
Enabling Efficient GPU Communication over Multiple NICs with FuseLink,
Z. Ren, Y . Li, Z. Wang, X. Huang, W. Li, K. Xu, X. Liao, Y . Sun, B. Liu, H. Tian, J. Zhang, M. Wang, Z. Zhong, G. Liu, Y . Zhang, and K. Chen, “Enabling Efficient GPU Communication over Multiple NICs with FuseLink,” in19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), 2025, pp. 91–108
2025
-
[19]
GPUOS: A GPU Operating System Primitive for Transparent Operation Fusion
Y . Yang, X. Gao, Y . Zhou, Y . Gan, Y . Zheng, and A. Quinn, “GPUOS: A GPU Operating System Primitive for Transparent Operation Fusion,” arXiv preprint arXiv:2604.17861, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
LithOS: An Operating System for Efficient Machine Learning on GPUs,
P. H. Coppock, B. Zhang, E. H. Solomon, V . Kypriotis, L. Yang, B. Sharma, D. Schatzberg, T. C. Mowry, and D. Skarlatos, “LithOS: An Operating System for Efficient Machine Learning on GPUs,” in Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, 2025, pp. 1–17
2025
-
[21]
Ai and memory wall,
A. Gholami, Z. Yao, S. Kim, C. Hooper, M. W. Mahoney, and K. Keutzer, “Ai and memory wall,”IEEE Micro, vol. 44, no. 3, pp. 33–39, 2024
2024
-
[22]
Zero- infinity: Breaking the gpu memory wall for extreme scale deep learning,
S. Rajbhandari, O. Ruwase, J. Rasley, S. Smith, and Y . He, “Zero- infinity: Breaking the gpu memory wall for extreme scale deep learning,” inProceedings of the international conference for high performance computing, networking, storage and analysis, 2021, pp. 1–14
2021
-
[23]
Mlp- offload: Multi-level, multi-path offloading for llm pre-training to break the gpu memory wall,
A. K. Maurya, M. M. Rafique, F. Cappello, and B. Nicolae, “Mlp- offload: Multi-level, multi-path offloading for llm pre-training to break the gpu memory wall,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2025, pp. 1381–1394
2025
-
[24]
G10: Enabling an efficient unified gpu memory and storage architecture with smart tensor migrations,
H. Zhang, Y . Zhou, Y . Xue, Y . Liu, and J. Huang, “G10: Enabling an efficient unified gpu memory and storage architecture with smart tensor migrations,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, 2023, pp. 395–410
2023
-
[25]
Overcoming the memory wall with{CXL- Enabled}{SSDs},
S.-P. Yang, M. Kim, S. Nam, J. Park, J.-Y . Choi, E. H. Nam, E. Lee, S. Lee, and B. S. Kim, “Overcoming the memory wall with{CXL- Enabled}{SSDs},” in2023 USENIX Annual Technical Conference (USENIX ATC 23), 2023, pp. 601–617
2023
-
[26]
Demystifying nccl: An in-depth analysis of gpu communication protocols and algorithms,
Z. Hu, S. Shen, T. Bonato, S. Jeaugey, C. Alexander, E. Spada, J. Dinan, J. Hammond, and T. Hoefler, “Demystifying nccl: An in-depth analysis of gpu communication protocols and algorithms,” in2025 IEEE Symposium on High-Performance Interconnects (HOTI). IEEE, 2025, pp. 48–59
2025
-
[27]
CUDA Graphs,
NVIDIA Corporation, “CUDA Graphs,”CUDA Programming Guide, Version 13.3, 2026, accessed: 2026-06-03. [Online]. Available: https://docs.nvidia.com/cuda/cuda-programming-guide/04-special-topic s/cuda-graphs.html
2026
-
[28]
Breakable CUDA Graph,
SGLang Team, “Breakable CUDA Graph,”SGLang Documentation, 2026, last updated: Jun. 4, 2026. Accessed: 2026-06-03. [Online]. Available: https://sgl-project.github.io/advanced features/breakable cud a graph.html
2026
-
[29]
Medusa: Accelerating Serverless LLM Inference with Materialization,
S. Zeng, M. Xie, S. Gao, Y . Chen, and Y . Lu, “Medusa: Accelerating Serverless LLM Inference with Materialization,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, 2025, pp. 653–668
2025
-
[30]
Multi-Process Service,
NVIDIA Corporation, “Multi-Process Service,”NVIDIA GPU Management and Deployment Documentation, 2026, accessed: 2026- 06-03. [Online]. Available: https://docs.nvidia.com/deploy/mps/latest/in dex.html
2026
-
[31]
NVIDIA Multi-Instance GPU,
——, “NVIDIA Multi-Instance GPU,”NVIDIA Technologies, 2026, accessed: 2026-06-03. [Online]. Available: https://www.nvidia.com/e n-us/technologies/multi-instance-gpu/
2026
-
[32]
Transparent GPU Sharing in Container Clouds for Deep Learning Workloads,
B. Wu, Z. Zhang, Z. Bai, X. Liu, and X. Jin, “Transparent GPU Sharing in Container Clouds for Deep Learning Workloads,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), 2023, pp. 69–85
2023
-
[33]
Characterizing network requirements for gpu api remoting in ai applications,
T. Wang, Z. Chen, X. Wei, J. Gu, R. Chen, and H. Chen, “Characterizing network requirements for gpu api remoting in ai applications,”arXiv preprint arXiv:2401.13354, 2024
-
[34]
{gVulkan}: Scalable{GPU}pooling for{Pixel-Grained}rendering in ray tracing,
Y . Gu, Y . Wang, Y . Sun, Y . Xiang, Y . Jiang, X. Hu, Z. Qi, and H. Guan, “{gVulkan}: Scalable{GPU}pooling for{Pixel-Grained}rendering in ray tracing,” in2024 USENIX Annual Technical Conference (USENIX ATC 24), 2024, pp. 1151–1165
2024
-
[35]
Krisp: Enabling kernel-wise right-sizing for spatial partitioned gpu inference servers,
M. Chow, A. Jahanshahi, and D. Wong, “Krisp: Enabling kernel-wise right-sizing for spatial partitioned gpu inference servers,” in2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2023, pp. 624–637
2023
-
[36]
Efficient Performance-Aware GPU Sharing with Compatibility and Isolation through Kernel Space Interception,
S. Zhang, A. Xu, Q. Chen, H. Zhao, W. Cui, Z. Wang, Y . Li, L. Xiao, and M. Guo, “Efficient Performance-Aware GPU Sharing with Compatibility and Isolation through Kernel Space Interception,” in2025 USENIX Annual Technical Conference (USENIX ATC 25), 2025, pp. 1003–1019
2025
-
[37]
GPU Memory Exploitation for Fun and Profit,
Y . Guo, Z. Zhang, and J. Yang, “GPU Memory Exploitation for Fun and Profit,” in33rd USENIX Security Symposium (USENIX Security 24), 2024, pp. 4033–4050
2024
-
[38]
Virtual Memory Management,
NVIDIA Corporation, “Virtual Memory Management,”CUDA Programming Guide, Version 13.3, 2026, accessed: 2026-06-03. [Online]. Available: https://docs.nvidia.com/cuda/cuda-programming-g uide/04-special-topics/virtual-memory-management.html
2026
-
[39]
DONGLE: Direct FPGA-Orchestrated NVMe Storage for HLS,
Wong, Linus Y and Zhang, Jialiang and Li, Jing, “DONGLE: Direct FPGA-Orchestrated NVMe Storage for HLS,” inProceedings of the 2023 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, 2023, pp. 3–13
2023
-
[40]
DONGLE 2.0: Direct FPGA- Orchestrated NVMe Storage for HLS,
L. Y . Wong, J. Zhang, and J. Li, “DONGLE 2.0: Direct FPGA- Orchestrated NVMe Storage for HLS,”ACM Transactions on Recon- figurable Technology and Systems, vol. 17, no. 3, pp. 1–32, 2024
2024
-
[41]
HiLFS: FPGA-Orchestrated File System for High-Level Synthesis,
Y . Na, L. Y . Wong, A. DeHon, and J. Li, “HiLFS: FPGA-Orchestrated File System for High-Level Synthesis,” inProceedings of the 2026 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, 2026, pp. 126–136
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.