SCALE: Scalable Cross-Attention Learning with Extrapolation for Agentic Workflow Scheduling
Pith reviewed 2026-06-27 22:50 UTC · model grok-4.3
The pith
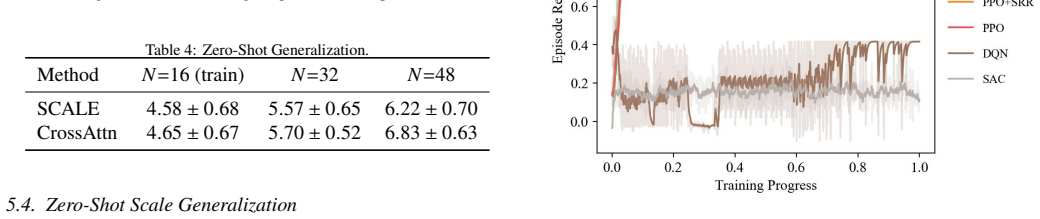
A cross-attention scheduler trained on 16-node clusters generalizes directly to 32- and 48-node clusters when features are regularized against scale-induced shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
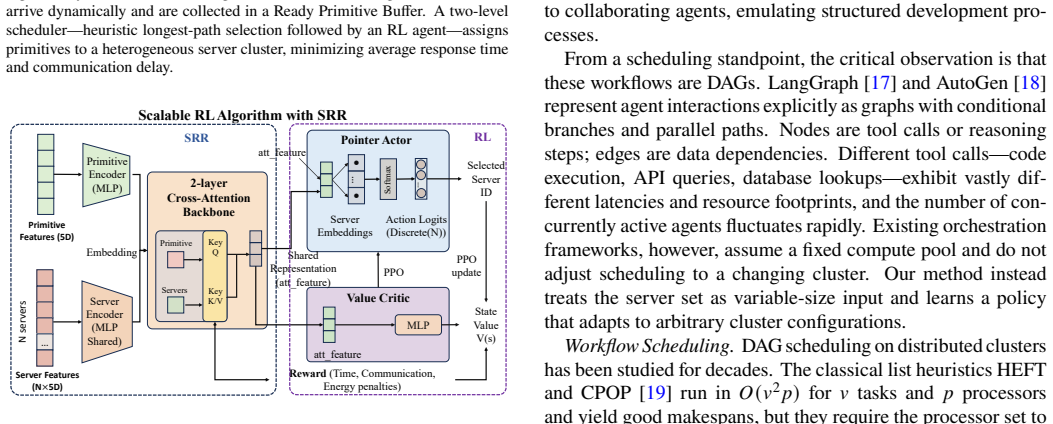
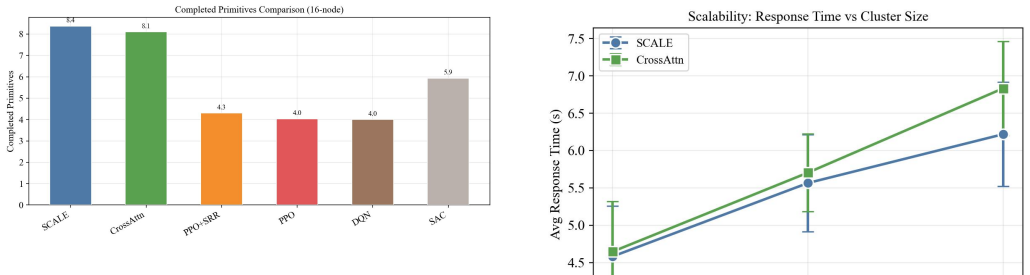
SCALE employs a cross-attention pointer network in which task features query server features, allowing the model to accept variable cluster sizes without architectural change. The authors demonstrate that this alone does not prevent distribution shift in the attention features as server count increases; they therefore introduce Structured Representation Regularization (decorrelation loss plus KL penalty to standard normal) that stabilizes feature statistics across input sizes. Trained exclusively on 16-node instances and tested directly on 32- and 48-node instances, the regularized model produces an 8.9 percent reduction in average response time at N=48 compared with the same network trained
What carries the argument
Cross-attention pointer network whose task-to-server queries are kept distributionally stable by Structured Representation Regularization (decorrelation loss combined with KL penalty to the standard normal).
If this is right
- A single training run on a modest cluster size suffices for deployment on larger clusters without retraining.
- Permutation-invariant attention architecture must be supplemented by explicit feature regularization to achieve scale generalization.
- Response-time gains from SRR increase with the gap between training and test cluster sizes.
- Scheduling decisions remain feasible for any number of servers once the model has been regularized on a fixed training size.
Where Pith is reading between the lines
- The same regularization pattern could be tested on other variable-cardinality attention models that currently require per-size retraining.
- Dynamic cloud environments that add or remove servers on the fly could adopt the method to avoid repeated training cycles.
- If the KL term dominates, the features become approximately Gaussian regardless of input size; this could be verified by tracking higher moments at extreme scales such as N=128.
Load-bearing premise
That attention features undergo a distribution shift when the number of servers increases and that the decorrelation-plus-KL term is sufficient to keep those statistics stable for any cluster size.
What would settle it
Direct measurement showing that average response time at N=48 is no better (or is worse) when SRR is included than when the identical cross-attention architecture is used without it.
Figures


read the original abstract
Agentic Large Language Model (LLM) systems decompose complex tasks into workflow Directed Acyclic Graphs (DAGs) whose primitives must be scheduled on heterogeneous clusters. Existing deep reinforcement learning (DRL) schedulers are tied to a fixed cluster size and require retraining whenever the number of servers changes. We propose SCALE (Scalable Cross-Attention Learning with Extrapolation), a DRL scheduler that generalizes to unseen cluster scales without fine-tuning. SCALE employs a cross-attention pointer network where task features query against server features, so the architecture accepts any number of servers by construction. We observe, however, that permutation-invariant architecture alone does not guarantee good performance at new scales - the attention feature undergoes distribution shift as the server count grows. To counter this, we introduce Structured Representation Regularization (SRR): a decorrelation loss combined with a KL penalty toward the standard normal, which keeps feature statistics stable regardless of input size. Trained on 16 nodes and tested directly on 32 and 48 nodes, SCALE reduces average response time by 8.9% at N=48 relative to the same architecture without SRR, confirming that explicit regularization is necessary to close the scale-generalization gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SCALE, a deep reinforcement learning scheduler for agentic LLM workflow DAGs on heterogeneous clusters. It employs a cross-attention pointer network that accepts variable numbers of servers by construction, combined with Structured Representation Regularization (SRR: decorrelation loss plus KL penalty to N(0,1)) to counteract distribution shift in attention features as cluster size N grows. Trained on 16 nodes and evaluated directly on 32 and 48 nodes, SCALE reports an 8.9% reduction in average response time at N=48 relative to the identical architecture without SRR.
Significance. If the mechanism and results are substantiated, the work would address a practical barrier in DRL scheduling by enabling scale extrapolation without retraining, which is relevant for dynamic cluster environments in agentic systems. The explicit regularization strategy for stabilizing features under variable input cardinality offers a concrete direction for improving generalization in pointer-network architectures.
major comments (2)
- [Abstract] Abstract: The claim that attention features undergo distribution shift with growing server count and that SRR is required to close the scale-generalization gap rests solely on the end-to-end 8.9% response-time improvement. No feature-level evidence (means, variances, correlations, or histograms) is supplied showing divergence in the unregularized model or stability under SRR across N=16/32/48; the performance delta alone does not distinguish scale-specific stabilization from generic regularization effects. This is load-bearing for the central contribution.
- [Abstract] Abstract: The reported 8.9% improvement supplies no experimental details on baselines beyond the no-SRR ablation, number of independent runs, variance or standard error, or statistical tests. Without these, the reliability of the generalization claim cannot be assessed.
minor comments (1)
- [Abstract] The pointer-network architecture is described as permutation-invariant and variable-length by construction; a short clarification on why this alone is insufficient (beyond the stated observation) would aid readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which identify key areas where the manuscript's claims require stronger substantiation. We address each major comment below and will revise the paper to incorporate the requested evidence and details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that attention features undergo distribution shift with growing server count and that SRR is required to close the scale-generalization gap rests solely on the end-to-end 8.9% response-time improvement. No feature-level evidence (means, variances, correlations, or histograms) is supplied showing divergence in the unregularized model or stability under SRR across N=16/32/48; the performance delta alone does not distinguish scale-specific stabilization from generic regularization effects. This is load-bearing for the central contribution.
Authors: We agree that the manuscript currently supports the distribution-shift claim only through the end-to-end performance delta and does not supply direct feature-level statistics or visualizations. This leaves open the possibility that SRR provides generic regularization benefits rather than scale-specific stabilization. In the revision we will add an appendix section with means, variances, pairwise correlations, and histograms of the cross-attention features for both the unregularized and SRR models at N=16, 32, and 48, thereby distinguishing the two effects. revision: yes
-
Referee: [Abstract] Abstract: The reported 8.9% improvement supplies no experimental details on baselines beyond the no-SRR ablation, number of independent runs, variance or standard error, or statistical tests. Without these, the reliability of the generalization claim cannot be assessed.
Authors: We acknowledge the omission of run counts, variance measures, and statistical tests. The revised manuscript will report results aggregated over 10 independent random seeds, include standard errors, and provide paired t-test p-values comparing SCALE against the no-SRR baseline at each scale. These details will be added to both the abstract and the experimental section. revision: yes
Circularity Check
No circularity: empirical scale-extrapolation result stands on measured performance delta
full rationale
The paper's central claim is an empirical observation: a cross-attention pointer network (permutation-invariant and variable-length by architectural construction) is trained at N=16 and evaluated at N=32/48; adding SRR (decorrelation + KL) yields an 8.9% response-time reduction versus the identical architecture without SRR. No derivation, equation, or self-citation reduces the reported improvement to a fitted parameter or prior result by construction. The architecture's variable-length property is stated as given, and the necessity of SRR is supported only by the held-out scale test, not by re-deriving the same quantity from the training objective. This is a standard empirical generalization experiment with no load-bearing self-referential step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Plaat, M
A. Plaat, M. van Duijn, N. Van Stein, M. Preuss, P. van der Putten, K. J. Batenburg, Agentic large language models, a survey, Journal of Artificial Intelligence Research 84 (2025)
2025
- [2]
-
[3]
Armbrust, A
M. Armbrust, A. Fox, R. Griffith, A. D. Joseph, R. Katz, A. Konwin- ski, G. Lee, D. Patterson, A. Rabkin, I. Stoica, et al., A view of cloud computing, Communications of the ACM 53 (4) (2010) 50–58
2010
-
[4]
J. Dean, S. Ghemawat, Mapreduce: simplified data processing on large clusters, Communications of the ACM 51 (1) (2008) 107–113
2008
-
[5]
Y.Zhang,W.Hua,Z.Zhou,G.E.Suh,C.Delimitrou,Sinan: Ml-basedand qos-awareresourcemanagementforcloudmicroservices,in: Proceedings of the 26th ACM international conference on architectural support for programming languages and operating systems, 2021, pp. 167–181
2021
- [6]
- [7]
- [8]
-
[9]
C. Ma, A. Li, Y. Du, H. Dong, Y. Yang, Efficient and scalable reinforce- mentlearningforlarge-scalenetworkcontrol,NatureMachineIntelligence 6 (9) (2024) 1006–1020
2024
-
[10]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, O. Klimov, Proximal policy optimization algorithms, arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Z. Liu, L. Huang, Z. Gao, M. Luo, S. Hosseinalipour, H. Dai, Ga-drl: Graph neural network-augmented deep reinforcement learning for dag task scheduling over dynamic vehicular clouds, IEEE Transactions on Network and Service Management 21 (4) (2024) 4226–4242
2024
-
[12]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in neural information processing systems 30 (2017)
2017
-
[13]
Vinyals, M
O. Vinyals, M. Fortunato, N. Jaitly, Pointer networks, Advances in neural information processing systems 28 (2015)
2015
-
[14]
Significant-Gravitas,Autogpt: Anautonomousgpt-4experiment,https: //github.com/Significant-Gravitas/AutoGPT, gitHub repository (2023)
2023
-
[15]
Chase, Langchain: Building applications with llms through com- posability,https://github.com/langchain-ai/langchain,gitHub repository (2022)
H. Chase, Langchain: Building applications with llms through com- posability,https://github.com/langchain-ai/langchain,gitHub repository (2022)
2022
-
[16]
S. Hong, X. Zheng, J. Chen, Y. Cheng, C. Wang, Y. Zhang, Z. Wang, S.K.S.Yau,Z.Lin,L.Zhou,etal.,Metagpt: Metaprogrammingformulti- agent collaborative framework, in: International Conference on Learning Representations (ICLR), 2024
2024
-
[17]
LangChain Inc., Langgraph: Building stateful multi-agent applica- tions,https://langchain-ai.github.io/langgraph/,documenta- tion (2024)
2024
-
[18]
Q. Wu, G. Bansal, J. Zhang, Y. Wu, S. Zhang, E. Zhu, B. Li, L. Jiang, X. Zhang, C. Wang, Autogen: Enabling next-gen llm applications via multi-agent conversation, arXiv preprint arXiv:2308.08155 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Topcuoglu, S
H. Topcuoglu, S. Hariri, M.-Y. Wu, Task scheduling algorithms for het- erogeneous processors, Proceedings. Eighth Heterogeneous Computing Workshop (1999) 3–14
1999
-
[20]
H. Mao, M. Alizadeh, I. Menache, S. Kandula, Resource management with deep reinforcement learning, in: ACM Workshop on Hot Topics in Networks (HotNets), 2016, pp. 50–56
2016
-
[21]
H. Mao, M. Schwarzkopf, S. B. Venkatakrishnan, Z. Meng, M. Alizadeh, Learning scheduling algorithms for data processing clusters, in: ACM SIGCOMM Conference, 2019, pp. 270–288. 9
2019
-
[22]
T. N. Kipf, M. Welling, Semi-supervised classification with graph convo- lutional networks, in: International Conference on Learning Representa- tions (ICLR), 2017
2017
-
[23]
Zaheer, S
M. Zaheer, S. Kottur, S. Ravanbakhsh, B. Poczos, R. Salakhutdinov, A. Smola, Deep sets, in: Advances in neural information processing systems, 2017
2017
-
[24]
3744–3753
J.Lee,Y.Lee,J.Kim,A.R.Kosiorek,S.Choi,Y.W.Teh,Settransformer: A framework for attention-based permutation-invariant neural networks, in: International Conference on Machine Learning (ICML), 2019, pp. 3744–3753
2019
-
[25]
W.Kool,H.vanHoof,M.Welling,Attention,learntosolveroutingprob- lems!, in: International Conference on Learning Representations (ICLR), 2019
2019
-
[26]
J. Park, J. Chun, S. H. Kim, Y. Kim, J. Park, Learning to schedule job- shop problems with attention networks, in: International Conference on Automated Planning and Scheduling (ICAPS), 2021, pp. 301–309
2021
-
[27]
Bengio, A
Y. Bengio, A. Lodi, A. Prouvost, Machine learning for combinatorial optimization: Amethodologicaltourd’horizon,EuropeanJournalofOp- erational Research 290 (2) (2021) 405–421. Author Biographies ZhifeiXuiscurrentlypursuingabachelor’sde- greeintheFacultyofArtsandSciences,Beijing Normal University at Zhuhai, China. His main researchinterestsincludeedgecomput...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.