Workflow-to-Skill: Skill Creation via Routing-Workflow-Semantics-Attachments Decomposition
Pith reviewed 2026-06-27 22:05 UTC · model grok-4.3
The pith
Decomposing interaction traces into workflow structures, semantics, and attachments produces more consistent LLM agent skills than text summarization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
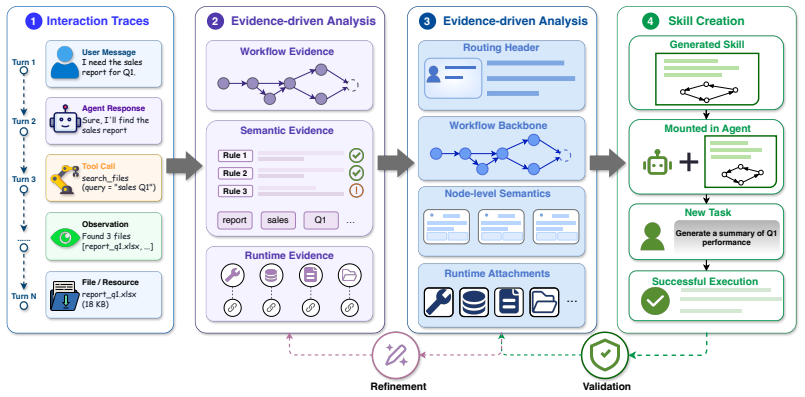
Trace-to-skill construction is not a summarization task; instead, an intermediate representation called RWSA decomposes each skill into Workflow structure, execution Semantics, and runtime Attachments so that fragmented traces can be segmented, locally drafted, aligned, branch-reconciled, and compressed while preserving evidence and confidence annotations, yielding skills whose behavioral replay consistency exceeds that of summarization baselines by 10.5 percent on 70 skills.
What carries the argument
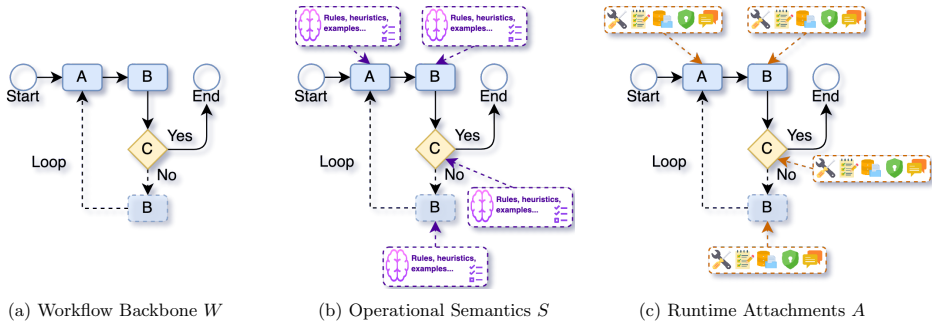
RWSA, the workflow-oriented intermediate representation that decomposes a Skill into its Workflow structure, execution Semantics, and runtime Attachments to capture task decomposition, control flow, verification, safety, rollback, and state management.
If this is right
- Skills retain explicit evidence and confidence annotations from the source traces rather than losing them in summarization.
- Redundant material across traces is removed while control-flow branches and safety checks are kept.
- The same decomposition steps can be applied to new heterogeneous evidence without requiring hand-written skill code.
- Behavioral replay consistency becomes a measurable proxy for skill quality instead of relying on human judgment of summaries.
Where Pith is reading between the lines
- The same RWSA decomposition could be applied to extract procedural knowledge from execution logs in non-agent software systems.
- If the method scales, it would allow skills to be regenerated automatically whenever fresh traces become available.
- Domains with high uncertainty or many parallel branches would provide a direct test of how well branch reconciliation works.
Load-bearing premise
Heterogeneous interaction evidence contains the information needed to recover rare but safety-critical behaviors when decomposed via RWSA into workflow, semantics, and attachments.
What would settle it
If skills produced by the W2S pipeline replay safety-critical behaviors from the original traces at the same or lower rate than summarization baselines, the advantage of the RWSA decomposition would be falsified.
Figures
read the original abstract
Large language model agents increasingly rely on Skills to encode procedural knowledge, yet high-quality Skills remain costly to hand-write. This paper studies automatic Skill construction from heterogeneous interaction evidence, including demonstrations, agent trajectories, tool traces, and execution logs. We argue that trace-to-skill construction is not simple summarization tasks, because traces are fragmented, redundant, and may miss rare but safety-critical behaviors. To address this, we introduce RWSA, a workflow-oriented intermediate representation that decomposes Skills into Workflow structure, execution Semantics, and runtime Attachments, capturing task decomposition, control flow, verification, safety, rollback, and state management. Building on RWSA, we propose W2S, a framework that segments traces, induces local Skill drafts, aligns shared structures, reconciles branches, and compresses redundancy while preserving evidence and confidence annotations. Experiments on 70 Skills show that W2S improves behavioral replay consistency by 10.5% over summarization- and prompting-based baselines, highlighting the need to treat traces as executable runtime specifications rather than compressible text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that trace-to-skill construction is not simple summarization because traces are fragmented, redundant, and may miss rare safety-critical behaviors. It introduces RWSA as a workflow-oriented intermediate representation decomposing skills into Workflow structure, execution Semantics, and runtime Attachments, and proposes the W2S framework that segments traces, induces local drafts, aligns shared structures, reconciles branches, and compresses redundancy while preserving evidence. Experiments on 70 Skills report that W2S improves behavioral replay consistency by 10.5% over summarization- and prompting-based baselines.
Significance. If the empirical gains hold under detailed scrutiny, the work could advance automatic skill construction for LLM agents by treating traces as executable specifications rather than compressible text. The RWSA decomposition provides a structured way to capture control flow, verification, safety, rollback, and state management. No machine-checked proofs or open reproducible code are mentioned, but the explicit intermediate representation is a constructive contribution.
major comments (2)
- [Experiments] Experiments section: the central claim of a 10.5% improvement in behavioral replay consistency provides no details on the consistency metric, exact baselines, error bars, statistical tests, or data exclusion rules. This directly affects verifiability of the reported result.
- [Introduction / Method] Introduction and Method sections: the motivation states that traces 'may miss rare but safety-critical behaviors' and positions RWSA/W2S as the solution that captures safety/rollback/state management. However, W2S performs segmentation, draft induction, alignment, reconciliation, and compression only on existing traces and contains no mechanism to synthesize or infer absent execution paths. The replay-consistency experiment therefore does not test recovery of missing behaviors, which is load-bearing for the paper's positioning and motivating claim.
minor comments (2)
- The expansion of the RWSA acronym is given only in the title; repeating it at first use in the abstract and introduction would improve readability.
- Notation for the three RWSA components (Workflow, Semantics, Attachments) should be introduced with consistent symbols or formatting when first defined.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim of a 10.5% improvement in behavioral replay consistency provides no details on the consistency metric, exact baselines, error bars, statistical tests, or data exclusion rules. This directly affects verifiability of the reported result.
Authors: We agree that the Experiments section requires additional detail for verifiability. In the revision we will add: (1) a formal definition of the behavioral replay consistency metric, (2) exact descriptions of all baselines including prompting variants, (3) error bars computed over multiple independent runs, (4) results of appropriate statistical tests, and (5) explicit data exclusion rules. These additions will be placed in a new subsection and referenced from the main results table. revision: yes
-
Referee: [Introduction / Method] Introduction and Method sections: the motivation states that traces 'may miss rare but safety-critical behaviors' and positions RWSA/W2S as the solution that captures safety/rollback/state management. However, W2S performs segmentation, draft induction, alignment, reconciliation, and compression only on existing traces and contains no mechanism to synthesize or infer absent execution paths. The replay-consistency experiment therefore does not test recovery of missing behaviors, which is load-bearing for the paper's positioning and motivating claim.
Authors: The observation is accurate: W2S processes only the traces provided and does not synthesize unobserved paths. The reported replay-consistency metric therefore measures fidelity to observed behaviors rather than recovery of missing ones. We will revise the Introduction and Method sections to (a) distinguish between preserving safety-critical elements that appear in the traces and the separate problem of inferring absent behaviors, (b) rephrase the motivating claim to emphasize improved structuring of available evidence, and (c) note the limitation regarding unobserved paths as future work. The experimental claims will be scoped accordingly. revision: yes
Circularity Check
No circularity: empirical comparison only
full rationale
The paper describes RWSA as a decomposition into workflow/semantics/attachments and W2S as a segmentation/alignment/compression pipeline over existing traces. The sole quantitative claim is an empirical 10.5% replay-consistency gain versus summarization baselines on 70 skills. No equations, fitted parameters, or self-citations are invoked to derive this gain; it is presented as a measured outcome of the procedural method. The derivation chain therefore contains no self-definitional, fitted-input, or self-citation reductions and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Traces are fragmented, redundant, and may miss rare but safety-critical behaviors, making simple summarization insufficient.
invented entities (2)
-
RWSA
no independent evidence
-
W2S
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. Large language model agent: A survey on methodol- ogy, applications and challenges.arXiv preprint arXiv:2503.21460,
-
[2]
Agent workflow memory.arXiv preprint arXiv:2409.07429,
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory.arXiv preprint arXiv:2409.07429,
-
[3]
Tool learning in the wild: Empowering language models as automatic tool agents
Zhengliang Shi, Shen Gao, Lingyong Yan, Yue Feng, Xiuyi Chen, Zhumin Chen, Dawei Yin, Suzan Ver- berne, and Zhaochun Ren. Tool learning in the wild: Empowering language models as automatic tool agents. InProceedings of the ACM on Web Conference 2025, pages 2222–2237,
2025
-
[4]
George Ling, Shanshan Zhong, and Richard Huang. Agent skills: A data-driven analysis of claude skills for extending large language model functionality. arXiv preprint arXiv:2602.08004,
-
[5]
Xiangyi Li, Wenbo Chen, Yimin Liu, Sheng- han Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026a. Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, se- curity, and th...
-
[6]
Sok: Agentic skills–beyond tool use in llm agents.arXiv preprint arXiv:2602.20867,
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guangsheng Yu. Sok: Agentic skills–beyond tool use in llm agents.arXiv preprint arXiv:2602.20867,
-
[7]
Yingli Zhou, Wang Shu, Yaodong Su, Wenchuan Du, Yixiang Fang, and Xuemin Lin. A comprehen- sive survey on agent skills: Taxonomy, techniques, and applications.arXiv preprint arXiv:2605.07358, 2026a. Xingyan Liu, Xiyue Luo, Linyu Li, Ganghong Huang, Jianfeng Liu, and Honglin Qiao. Skill- forge: Forging domain-specific, self-evolving agent skills in cloud t...
-
[8]
Zisu Huang, Jingwen Xu, Yifan Yang, Ziyang Gong, Qihao Yang, Muzhao Tian, Xiaohua Wang, Changze Lv, Xuemei Gao, Qi Dai, et al. From raw experience to skill consumption: A system- atic study of model-generated agent skills.arXiv preprint arXiv:2605.23899,
-
[9]
Re- act: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. Re- act: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
-
[10]
Yifan Zhou, Zhentao Zhang, Ziming Cheng, Shuo Zhang, Qizhen Lan, Zhangquan Chen, Zhi Yang, Ronghao Chen, Huacan Wang, Sen Hu, et al. Skill- genbench: Benchmarking skill generation pipelines for llm agents.arXiv preprint arXiv:2605.18693, 2026b. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda ...
-
[11]
Tptu: Task planning and tool usage of large language model-based ai agents
Jingqing Ruan, Yihong Chen, Bin Zhang, Zhiwei Xu, Tianpeng Bao, Hangyu Mao, Ziyue Li, Xingyu Zeng, Rui Zhao, et al. Tptu: Task planning and tool usage of large language model-based ai agents. InNeurIPS 2023 foundation models for decision making workshop,
2023
-
[12]
Accessed: 2026-05-24. Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolv- ing agents via recursive skill-augmented reinforce- ment learning.arXiv preprint arXiv:2602.08234,
Pith/arXiv arXiv 2026
-
[13]
Skillx: Automatically constructing skill knowledge bases for agents.arXiv preprint arXiv:2604.04804,
Chenxi Wang, Zhuoyun Yu, Xin Xie, Wuguannan Yao, Runnan Fang, Shuofei Qiao, Kexin Cao, Guozhou Zheng, Xiang Qi, Peng Zhang, et al. Skillx: Automatically constructing skill knowledge bases for agents.arXiv preprint arXiv:2604.04804,
-
[14]
Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Erchao Zhao, Xiaoxi Jiang, and Guan- jun Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158,
-
[15]
Yu Li, Rui Miao, Zhengling Qi, and Tian Lan. Arise: Agent reasoning with intrinsic skill evolution in hierarchical reinforcement learning.arXiv preprint arXiv:2603.16060, 2026c. Zora Zhiruo Wang, Apurva Gandhi, Graham Neubig, and Daniel Fried. Inducing programmatic skills for agentic tasks.arXiv preprint arXiv:2504.06821,
-
[16]
Yutao Yang, Junsong Li, Qianjun Pan, Bihao Zhan, Yuxuan Cai, Lin Du, Jie Zhou, Kai Chen, Qin Chen, Xin Li, Bo Zhang, and Liang He. Autoskill: Experience-driven lifelong learning via skill self- evolution.arXiv preprint arXiv:2603.01145, 2026b. Hongyi Liu, Haoyan Yang, Tao Jiang, Bo Tang, Feiyu Xiong, and Zhiyu Li. Skillsvote: Lifecycle gover- nance of age...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.