DRIFT: From Robustness Gaps to Invariance Manifolds for AI-Generated Image Detection
Pith reviewed 2026-06-27 22:31 UTC · model grok-4.3
The pith
Detection of AI-generated images works by learning an invariance manifold from real images alone and flagging margin violations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
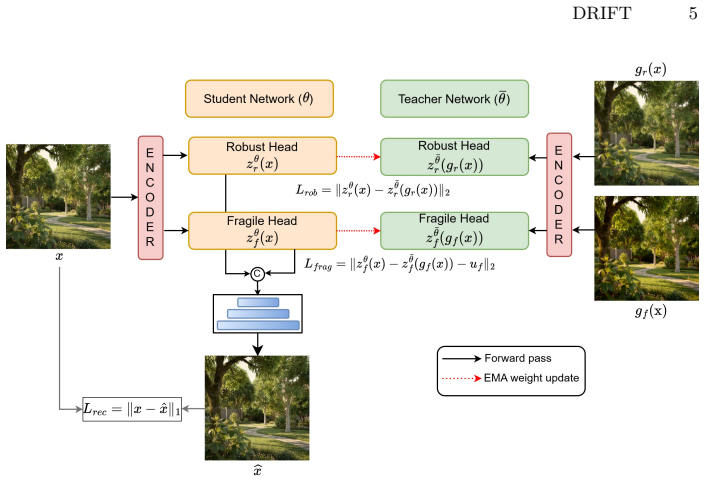
We formulate AI-generated image detection as learning a structured invariance manifold of real images under one-class supervision. Building upon a frozen VFM, we introduce lightweight projection heads that decompose representation space into complementary robust and fragile subspaces. The robust subspace is explicitly trained to suppress variations induced by physically plausible imaging transformations, approximating tangent directions of a real-image manifold, while the fragile subspace retains sensitivity to edit-like perturbations. A structured ordering margin enforces hierarchical separation between physical invariance and edit-induced variability, enabling detection as a margin-violati
What carries the argument
structured invariance manifold with robust and fragile subspaces separated by a structured ordering margin
If this is right
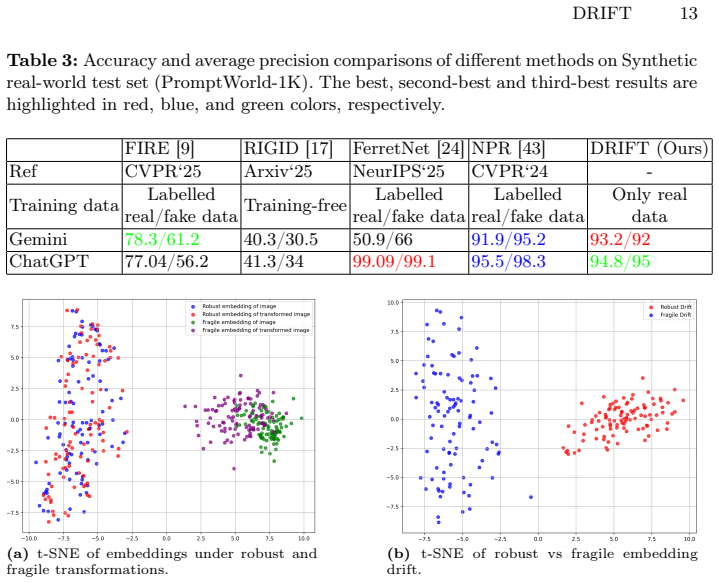
- Images from unseen generators trigger margin violations relative to the learned real-image manifold, allowing detection without any fake training data.
- Multi-scale patch-wise drift supplies both an overall detection score and spatially localized invariance-violation maps.
- The dual-channel signature from robust and fragile subspaces improves open-world performance over fixed pretraining robustness gaps.
- The method generalizes across generator types and image resolutions by construction of the manifold rather than by retraining on new fakes.
Where Pith is reading between the lines
- The same one-class manifold construction could be tested on video or audio by swapping the definition of physically plausible transformations.
- The fragile subspace might be inspected directly to surface recurring artifacts that current generators still produce.
- Combining the margin-violation score with existing pixel-level detectors could yield ensembles that remain stable when generators change.
- The approach suggests experiments on whether smaller real-image sets from a single camera model still suffice to build a usable manifold.
Load-bearing premise
One-class training on real images using physically plausible transformations will produce a manifold whose margin violations reliably flag images from entirely unseen generators at different resolutions.
What would settle it
A newly released generator that produces images consistently inside the margin boundaries at multiple scales and under both transformation families would show the detection rule does not hold.
Figures





read the original abstract
The rapid evolution of generative image models challenges existing AI-generated image detectors, particularly in open-world settings with unseen generators. Recent training-free approaches measure robustness gaps in frozen vision foundation models (VFMs), detecting fakes via perturbation-induced embedding drift. However, these methods rely on fixed invariance geometry inherited from pretraining and lack principled adaptation to the detection task. We instead formulate AI-generated image detection as learning a structured invariance manifold of real images under one-class supervision. Building upon a frozen VFM, we introduce lightweight projection heads that decompose representation space into complementary robust and fragile subspaces. The robust subspace is explicitly trained to suppress variations induced by physically plausible imaging transformations, approximating tangent directions of a real-image manifold, while the fragile subspace retains sensitivity to edit-like perturbations. A structured ordering margin enforces hierarchical separation between physical invariance and edit-induced variability, enabling detection as a margin-violation test relative to the learned manifold. At inference, multi-scale patch-wise drift under both transformation families yields a dual-channel invariance signature and interpretable localization. Extensive experiments demonstrate strong open-world generalization across unseen generators and resolutions, consistently outperforming training-free robustness-based baselines while providing interpretable invariance-violation maps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that AI-generated image detection can be reformulated as learning a structured invariance manifold of real images under one-class supervision on a frozen VFM. Lightweight projection heads decompose the representation into complementary robust (suppressing physically plausible transforms) and fragile subspaces, separated by a structured ordering margin that enforces hierarchical separation; detection then reduces to a margin-violation test, with multi-scale patch-wise drift yielding a dual-channel signature and localization maps. The abstract asserts that this yields strong open-world generalization across unseen generators and resolutions while outperforming training-free robustness baselines.
Significance. If the experimental claims hold, the work would offer a principled, adaptive alternative to fixed-geometry training-free detectors, with added interpretability via invariance-violation maps. The one-class formulation and explicit subspace decomposition could influence future detector design in open-world settings.
major comments (2)
- [Abstract] Abstract: the central claim of strong open-world generalization and consistent outperformance rests on experimental assertions, yet the abstract supplies no quantitative results, ablation details, error bars, or dataset statistics, leaving the load-bearing generalization claim unverified in the provided summary.
- [Method] Method description (one-class supervision and subspace decomposition): the assumption that training solely on real images plus physically plausible transforms will cause the fragile subspace to flag artifacts from entirely unseen generators via margin violation is load-bearing for the open-world claim, but nothing in the formulation explicitly penalizes leakage or ensures the margin enforces sensitivity to generator-specific edits rather than the training transform families.
minor comments (2)
- Clarify the precise optimization objective for the projection heads and the structured ordering margin (including whether the margin value is a learned free parameter or derived from data).
- Provide dataset statistics, generator names, and resolution ranges used in the claimed extensive experiments to allow assessment of the open-world scope.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of strong open-world generalization and consistent outperformance rests on experimental assertions, yet the abstract supplies no quantitative results, ablation details, error bars, or dataset statistics, leaving the load-bearing generalization claim unverified in the provided summary.
Authors: We agree that the abstract would be strengthened by including key quantitative support. In the revised version we will add concise performance highlights (e.g., mean AUC on unseen generators, number of generators and resolutions tested) while remaining within length limits. revision: yes
-
Referee: [Method] Method description (one-class supervision and subspace decomposition): the assumption that training solely on real images plus physically plausible transforms will cause the fragile subspace to flag artifacts from entirely unseen generators via margin violation is load-bearing for the open-world claim, but nothing in the formulation explicitly penalizes leakage or ensures the margin enforces sensitivity to generator-specific edits rather than the training transform families.
Authors: The structured ordering margin and complementary subspace objectives already enforce the desired separation: the robust head is explicitly optimized to absorb only the listed physical transforms, while the fragile head retains all residual directions. Any generator-induced edit lies outside the learned real-image manifold by construction and therefore triggers a margin violation in the fragile channel. We will insert a short clarifying paragraph in Section 3.3 that makes this leakage-prevention argument explicit and references the margin loss term. revision: yes
Circularity Check
No significant circularity; new trainable components learned independently from data
full rationale
The derivation introduces lightweight projection heads and a structured ordering margin that are explicitly trained under one-class supervision on real images with physical transformations. These elements decompose the space into robust and fragile subspaces and enforce separation via a learned margin, rather than reducing by construction to any pre-fitted parameters, self-citations, or renamed known results. The central claim of open-world detection via margin violation is an empirical generalization step outside the training loop, with no load-bearing self-definitional or fitted-input reductions visible in the formulation.
Axiom & Free-Parameter Ledger
free parameters (2)
- projection head parameters
- ordering margin value
axioms (2)
- domain assumption Frozen vision foundation models supply a representation space in which physically plausible transformations approximate tangent directions of a real-image manifold
- ad hoc to paper One-class supervision on real images is sufficient to learn a manifold that generalizes to detect fakes from unseen generators
invented entities (4)
-
structured invariance manifold
no independent evidence
-
robust subspace
no independent evidence
-
fragile subspace
no independent evidence
-
structured ordering margin
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Openjourney
Prompthero. Openjourney. https://openjourney.art (2023)
2023
-
[2]
https://huggingface.co/Yntec/YiffyMix (2023)
Yiffymix v31. https://huggingface.co/Yntec/YiffyMix (2023)
2023
-
[3]
https://huggingface.co/dataautogpt3/ProteusV0.3 (2024)
Proteus v0.3. https://huggingface.co/dataautogpt3/ProteusV0.3 (2024)
2024
-
[4]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Brock, A., Donahue, J., Simonyan, K.: Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2011)
Bychkovsky, V., Paris, S., Chan, E., Durand, F.: Learning photographic global tonal adjustment with a database of input/output image pairs. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2011)
2011
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[7]
Cheng, S., Lyu, L., Wang, Z., Zhang, X., Sehwag, V.: Co-spy: Combining semantic andpixelfeaturestodetectsyntheticimagesbyai.In:ProceedingsoftheComputer Vision and Pattern Recognition Conference. pp. 13455–13465 (2025)
2025
-
[8]
arXiv preprint arXiv:2511.14030 (2025)
Choi, S., Lee, H., Lee, M.: Training-free detection of ai-generated images via crop- ping robustness. arXiv preprint arXiv:2511.14030 (2025)
-
[9]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Chu, B., Xu, X., Wang, X., Zhang, Y., You, W., Zhou, L.: Fire: Robust detection of diffusion-generated images via frequency-guided reconstruction error. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 12830–12839 (2025)
2025
-
[10]
In: ICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Corvi, R., Cozzolino, D., Zingarini, G., Poggi, G., Nagano, K., Verdoliva, L.: On the detection of synthetic images generated by diffusion models. In: ICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2023)
2023
-
[11]
Dang-Nguyen, D.T., Pasquini, C., Conotter, V., Boato, G.: Raise: A raw images datasetfordigitalimageforensics.In:ProceedingsoftheACMMultimediaSystems Conference (MMSys) (2015)
2015
-
[12]
Advances in neural information processing systems34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021)
2021
-
[14]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[15]
Advances in neural information processing systems33, 21271–21284 (2020) 16 A
Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., Do- ersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M., et al.: Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems33, 21271–21284 (2020) 16 A. Ameta, S. Banerjee et al
2020
-
[16]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Gu, S., Chen, D., Bao, J., Wen, F., Zhang, B., Chen, D., Yuan, L., Guo, B.: Vector quantized diffusion model for text-to-image synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10696– 10706 (2022)
2022
-
[17]
arXiv preprint arXiv:2405.20112 (2024)
He, Z., Chen, P.Y., Ho, T.Y.: Rigid: A training-free and model-agnostic framework for robust ai-generated image detection. arXiv preprint arXiv:2405.20112 (2024)
-
[18]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Jeong, Y., Kim, D., Min, S., Joe, S., Gwon, Y., Choi, J.: Bihpf: Bilateral high-pass filters for robust deepfake detection. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 48–57 (2022)
2022
-
[19]
In: Proceedings of the AAAI conference on artificial intelligence
Jeong, Y., Kim, D., Ro, Y., Choi, J.: Frepgan: robust deepfake detection using frequency-level perturbations. In: Proceedings of the AAAI conference on artificial intelligence. vol. 36(1), pp. 1060–1068 (2022)
2022
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Karageorgiou, D., Papadopoulos, S., Kompatsiaris, I., Gavves, E.: Any-resolution ai-generated image detection by spectral learning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18706–18717 (2025)
2025
-
[21]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for im- proved quality, stability, and variation. arXiv preprint arXiv:1710.10196 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4401–4410 (2019)
2019
-
[23]
In: Pro- ceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Li, O., Cai, J., Hao, Y., Jiang, X., Hu, Y., Feng, F.: Improving synthetic image detection towards generalization: An image transformation perspective. In: Pro- ceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. pp. 2405–2414 (2025)
2025
-
[24]
arXiv preprint arXiv:2509.20890 (2025)
Liang,S.,Liu,J.,Chen,R.,Guan,Q.:Ferretnet:Efficientsyntheticimagedetection via local pixel dependencies. arXiv preprint arXiv:2509.20890 (2025)
-
[25]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, H., Tan, Z., Tan, C., Wei, Y., Wang, J., Zhao, Y.: Forgery-aware adaptive transformer for generalizable synthetic image detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10770– 10780 (2024)
2024
-
[27]
arXiv preprint arXiv:2202.09778 (2022)
Liu, L., Ren, Y., Lin, Z., Zhao, Z.: Pseudo numerical methods for diffusion models on manifolds. arXiv preprint arXiv:2202.09778 (2022)
-
[28]
In: Proceedings of the IEEE international conference on computer vision
Liu, Z., Luo, P., Wang, X., Tang, X.: Deep learning face attributes in the wild. In: Proceedings of the IEEE international conference on computer vision. pp. 3730– 3738 (2015)
2015
-
[29]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., Chen, M.: Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ojha, U., Li, Y., Lee, Y.J.: Towards universal fake image detectors that gener- alize across generative models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24480–24489 (2023)
2023
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Park, T., Liu, M.Y., Wang, T.C., Zhu, J.Y.: Semantic image synthesis with spatially-adaptive normalization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2337–2346 (2019) DRIFT 17
2019
-
[33]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
In: European conference on computer vision
Qian,Y.,Yin,G.,Sheng,L.,Chen,Z.,Shao,J.:Thinkinginfrequency:Faceforgery detection by mining frequency-aware clues. In: European conference on computer vision. pp. 86–103. Springer (2020)
2020
-
[35]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[36]
In: International conference on machine learning
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: International conference on machine learning. pp. 8821–8831. Pmlr (2021)
2021
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ricker, J., Lukovnikov, D., Fischer, A.: Aeroblade: Training-free detection of latent diffusion images using autoencoder reconstruction error. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9130– 9140 (2024)
2024
-
[38]
High-Resolution Image Synthesis with Latent Diffusion Models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High- resolution image synthesis with latent diffusion models, 2022. URL https://arxiv. org/abs/2112.107522112(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
In: Proceedings of the IEEE/CVF international conference on computer vision
Rossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.: Face- forensics++: Learning to detect manipulated facial images. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1–11 (2019)
2019
-
[40]
International journal of computer vision115(3), 211–252 (2015)
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al.: Imagenet large scale visual recog- nition challenge. International journal of computer vision115(3), 211–252 (2015)
2015
-
[41]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
2022
-
[42]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Tan, C., Zhao, Y., Wei, S., Gu, G., Liu, P., Wei, Y.: Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38(5), pp. 5052–5060 (2024)
2024
-
[43]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Tan, C., Zhao, Y., Wei, S., Gu, G., Liu, P., Wei, Y.: Rethinking the up-sampling op- erations in cnn-based generative network for generalizable deepfake detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 28130–28139 (2024)
2024
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tan, C., Zhao, Y., Wei, S., Gu, G., Wei, Y.: Learning on gradients: Generalized artifacts representation for gan-generated images detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12105– 12114 (2023)
2023
-
[45]
arXiv preprint arXiv:2411.19117 (2024)
Tsai, C.T., Ko, C.Y., Chung, I., Wang, Y.C.F., Chen, P.Y., et al.: Understanding and improving training-free ai-generated image detections with vision foundation models. arXiv preprint arXiv:2411.19117 (2024)
-
[46]
Wang, S.Y., Wang, O., Zhang, R., Owens, A., Efros, A.A.: Cnn-generated images are surprisingly easy to spot... for now. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 8695–8704 (2020)
2020
-
[47]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Wang, Z., Bao, J., Zhou, W., Wang, W., Hu, H., Chen, H., Li, H.: Dire for diffusion- generated image detection. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 22445–22455 (2023) 18 A. Ameta, S. Banerjee et al
2023
-
[48]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
Yu, F., Seff, A., Zhang, Y., Song, S., Funkhouser, T., Xiao, J.: Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[49]
In: Proceedings of the IEEE interna- tional conference on computer vision
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE interna- tional conference on computer vision. pp. 2223–2232 (2017) DRIFT 1 DRIFT: From Robustness Gaps to Invariance Manifolds for AI-Generated Image Detection Supplementary Material 6 Geometric Interpr...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.