Declarative Skills for AI Agents in Knowledge-Grounded Tool-Use Workflows
Pith reviewed 2026-06-27 21:57 UTC · model grok-4.3
The pith
Declarative skill files improve AI agent accuracy on procedural tasks and reduce orchestration errors when retrieval quality is high.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Declarative agents that append three domain-specific natural-language skill files to the system prompt and decide their own control flow outperform both an imperative state-machine agent and an unscaffolded baseline on procedural accuracy and orchestration compliance once retrieval supplies complete evidence; all three agents degrade sharply when evidence is incomplete or skewed.
What carries the argument
Declarative skill files: natural-language descriptions of domain skills that the agent reads at inference time to generate its own control flow.
If this is right
- High-quality retrieval is required before any orchestration method can deliver reliable gains.
- Declarative skill files reduce the need for hand-coded phase logic in procedural workflows.
- Imperative state machines add structural complexity without delivering proportional reliability improvements.
- Skill-file performance is tied to the completeness of the underlying knowledge base rather than to model scale alone.
Where Pith is reading between the lines
- Natural-language skill descriptions may scale more easily across new domains than hand-written state machines.
- The same retrieval-quality bottleneck would likely appear in any tool-use setting that depends on external unstructured data.
- Testing whether skill files remain effective when the underlying model is smaller or when workflows become longer could reveal limits on the declarative approach.
Load-bearing premise
The three agent designs represent meaningfully distinct orchestration paradigms whose performance gaps can be isolated from differences in prompt engineering or model behavior.
What would settle it
A controlled run in which declarative agents show no accuracy or compliance advantage over the imperative state machine even when retrieval returns every relevant document without skew.
Figures


read the original abstract
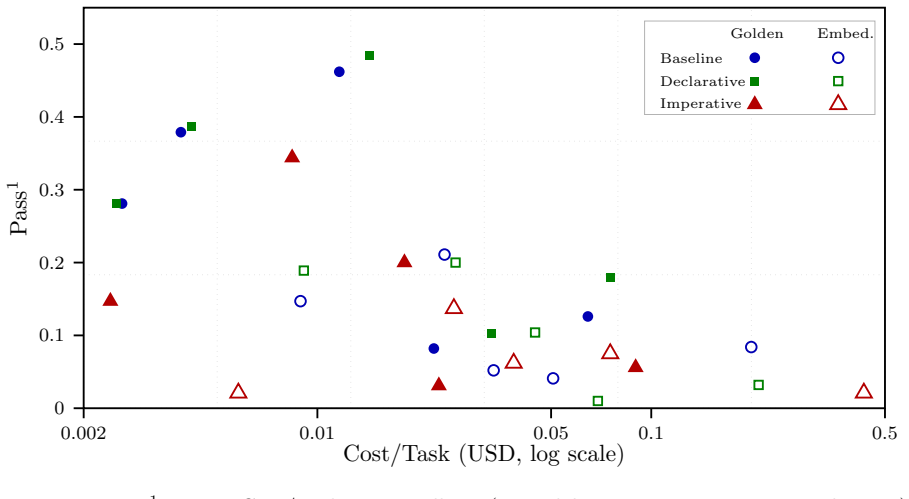
We study orchestration mechanisms for tool-using AI agents in realistic customer-service workflows over an unstructured knowledge base. We argue that declarative agents -- AI agents equipped with natural-language skill files appended to the system prompt -- are an effective orchestration paradigm. Concretely, we compare (i) a DeclarativeAgent that reads three domain-specific skill files at inference time and decides its own control flow, (ii) an ImperativeAgent based on a programmatic state machine with explicit phases, and (iii) an unscaffolded baseline agent modeled after the $\tau$-Knowledge benchmark agent. Our ImperativeAgent is motivated by externalised-control inference as in Recursive Language Models and graph-based orchestration frameworks. We formalise the three agents as policy classes within a decentralised partially-observable Markov decision process and analyse their information-theoretic and structural properties; we then test the predicted differences empirically on five language models and two retrieval regimes. Our results show that retrieval quality is a dominant bottleneck for AI agents: when evidence is incomplete or skewed, all agents degrade substantially, and skill files cannot recover lost performance. Under high-quality retrieval, however, declarative skills consistently improve accuracy on procedural tasks and reduce orchestration errors, while the imperative state machine's brittleness does not reliably improve task success or compliance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that declarative agents equipped with natural-language skill files appended to the system prompt are an effective orchestration paradigm for tool-using AI agents in customer-service workflows over unstructured knowledge bases. It compares three designs—DeclarativeAgent (three domain-specific skill files), ImperativeAgent (programmatic state machine with explicit phases), and an unscaffolded baseline—formalized as distinct policy classes in a decentralised partially-observable Markov decision process (Dec-POMDP). The work analyzes their information-theoretic and structural properties and reports empirical results on five language models across two retrieval regimes, concluding that retrieval quality is the dominant bottleneck but that, under high-quality retrieval, declarative skills improve accuracy on procedural tasks and reduce orchestration errors while the imperative state machine does not.
Significance. If the central empirical claim holds after proper controls, the work would offer a useful comparison of orchestration mechanisms grounded in a Dec-POMDP formalization, with potential implications for designing more robust tool-use agents. The emphasis on retrieval quality as a bottleneck is a valuable practical observation, and the distinction between declarative and imperative control could inform future agent scaffolding if the designs are shown to be isolated from confounds.
major comments (3)
- [abstract and agent design section] Agent design descriptions (abstract and §3): the three agents are presented as representing distinct orchestration paradigms, yet no evidence is supplied that prompt length, level of detail, or explicitness of procedural guidance were matched; the DeclarativeAgent appends three skill files while the ImperativeAgent uses a programmatic encoding, so any measured advantage could be attributable to prompt quality rather than the declarative/imperative distinction formalized in the Dec-POMDP policy classes.
- [abstract and results section] Empirical results (abstract and results section): the claimed improvements in accuracy and reduction in orchestration errors under high-quality retrieval are summarized without reporting concrete metrics, statistical tests, error bars, or per-model/per-regime breakdowns, making it impossible to assess whether the differences are reliable or driven by the intended variable.
- [§4] Dec-POMDP formalization (§4): the information-theoretic and structural properties derived for the three policy classes are not shown to predict or explain the specific empirical pattern that declarative skills succeed where the imperative state machine fails; the formal analysis therefore appears disconnected from the load-bearing empirical claim.
minor comments (2)
- [abstract] The abstract introduces terms such as 'orchestration errors' and 'compliance' without brief definitions, which would aid readability for readers outside the immediate subfield.
- [§4] Notation for the Dec-POMDP components (e.g., observation and action spaces for each policy class) could be presented more explicitly in a single table or equation block for easier cross-reference.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and outline revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [abstract and agent design section] Agent design descriptions (abstract and §3): the three agents are presented as representing distinct orchestration paradigms, yet no evidence is supplied that prompt length, level of detail, or explicitness of procedural guidance were matched; the DeclarativeAgent appends three skill files while the ImperativeAgent uses a programmatic encoding, so any measured advantage could be attributable to prompt quality rather than the declarative/imperative distinction formalized in the Dec-POMDP policy classes.
Authors: We agree that the manuscript does not report or control for prompt length, level of detail, or explicitness of procedural guidance across agents. The designs intentionally contrast natural-language declarative skill files against a programmatic imperative state machine, as formalized in the Dec-POMDP policy classes. To address potential confounds, we will add to §3 a comparison of system-prompt token counts, skill-file content, and state-machine code structure, plus an appendix with full prompt examples. This will enable readers to evaluate whether differences arise from the declarative/imperative distinction or from prompt characteristics, while preserving the core paradigm comparison. revision: partial
-
Referee: [abstract and results section] Empirical results (abstract and results section): the claimed improvements in accuracy and reduction in orchestration errors under high-quality retrieval are summarized without reporting concrete metrics, statistical tests, error bars, or per-model/per-regime breakdowns, making it impossible to assess whether the differences are reliable or driven by the intended variable.
Authors: The results section already contains per-model and per-regime accuracy tables and orchestration-error breakdowns. However, the abstract and high-level claims omit specific numbers, statistical tests, and error bars. We will revise the abstract to report key quantitative results (e.g., accuracy deltas under high-quality retrieval) and add error bars plus notes on statistical tests (paired comparisons across models) to the figures and text in §5. These changes will make the empirical claims directly verifiable. revision: yes
-
Referee: [§4] Dec-POMDP formalization (§4): the information-theoretic and structural properties derived for the three policy classes are not shown to predict or explain the specific empirical pattern that declarative skills succeed where the imperative state machine fails; the formal analysis therefore appears disconnected from the load-bearing empirical claim.
Authors: The information-theoretic analysis derives policy entropy and observability properties intended to explain why declarative policies reduce orchestration complexity. We acknowledge that the manuscript does not explicitly connect these properties to the observed pattern (declarative success versus imperative failure). We will add a bridging paragraph in §4.3 that maps the formal results (e.g., lower state-space entropy in declarative policies) to the empirical reductions in orchestration errors under high-quality retrieval, thereby tightening the link between theory and experiment. revision: yes
Circularity Check
No significant circularity; formalization and empirical tests are independent
full rationale
The paper's central chain formalizes three agent designs (DeclarativeAgent, ImperativeAgent, baseline) as distinct policy classes inside a Dec-POMDP, derives information-theoretic and structural properties from that formalization, and then tests the predicted differences on five models and two retrieval regimes. No equation or step reduces a claimed performance difference to a fitted parameter, a self-citation, or a quantity defined by the target result itself. The Dec-POMDP policy classes are presented as an external modeling choice whose consequences are then measured empirically; retrieval quality is treated as an independent variable. This structure is self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Agents can be formalized as policy classes within a decentralised partially-observable Markov decision process
Forward citations
Cited by 1 Pith paper
-
SkillCoach: Self-Evolving Rubrics for Evaluating and Enhancing Agentic Skill-Use
SkillCoach introduces self-evolving rubrics derived from rollouts to evaluate and supervise four process dimensions of agentic skill-use separately from outcome success.
Reference graph
Works this paper leans on
-
[1]
τ- Knowledge: Evaluating Conversational Agents over Unstructured Knowledge
Quan Shi, Alexandra Zytek, Pedram Razavi, Karthik Narasimhan, and Victor Barres. τ- Knowledge: Evaluating Conversational Agents over Unstructured Knowledge. Sierra Research / Princeton, arXiv:2603.04370, 2026.https://arxiv.org/abs/2603.04370
-
[2]
τ-Bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Yao, S., Shinn, N., Razavi, P., Narasimhan, K. τ-Bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. ICLR, 2025. 13
2025
-
[3]
τ-Bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains (Codebase)
Sierra Research. τ-Bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains (Codebase). GitHub repository, 2025. https://github.com/sierra-research/ tau2-bench
2025
-
[4]
Mathematics of Operations Research, 27(4):819–840, 2002
Bernstein, D.S., Givan, R., Immerman, N., Zilberstein, S.The Complexity of Decentralized Control of Markov Decision Processes. Mathematics of Operations Research, 27(4):819–840, 2002
2002
-
[5]
https://agentskills.io, 2025
Anthropic.Agent Skills: Composable, Model-Read Procedural Knowledge for LLM Agents. https://agentskills.io, 2025
2025
-
[6]
Firecrawl Blog, 2026
Firecrawl.How SKILL.md Files Work and Why They’re Everywhere. Firecrawl Blog, 2026. https://www.firecrawl.dev/blog/agent-skills
2026
-
[7]
LlamaIndex Blog, 2026
LlamaIndex.Files for AI Agents: Context, Search, Skills Guide. LlamaIndex Blog, 2026. https://www.llamaindex.ai/blog/files-are-all-you-need
2026
-
[8]
Anonymous.Recursive Language Models. arXiv:2512.24601, 2025. https://arxiv.org/abs/ 2512.24601
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Blog post, 2025
Zhang, A.Recursive Language Models. Blog post, 2025. https://alexzhang13.github.io/ blog/2025/rlm/
2025
-
[10]
et al.LangGraph: Building Stateful, Multi-Actor Applications with LLMs
Chase, H. et al.LangGraph: Building Stateful, Multi-Actor Applications with LLMs. LangChain, 2024.https://langchain-ai.github.io/langgraph/
2024
-
[11]
ICLR, 2023
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.ReAct: Synergizing Reasoning and Acting in Language Models. ICLR, 2023
2023
-
[12]
EACL Industry Track, 2026.https://aclanthology.org/2026.eacl-industry
[Redacted for blind review].Benchmarking Customer Support LLM Agents for Business- Adherence. EACL Industry Track, 2026.https://aclanthology.org/2026.eacl-industry. 15.pdf
2026
-
[13]
Toloka AI Blog, 2026
Toloka AI.TAU-bench extension: benchmarking policy-aware agents in realistic settings. Toloka AI Blog, 2026. https://toloka.ai/blog/ tau-bench-extension-benchmarking-policy-aware-agents-in-realistic-settings/
2026
-
[14]
τ 3-Bench: Advancing Agent Benchmarking to Knowledge and Voice
Sierra Research. τ 3-Bench: Advancing Agent Benchmarking to Knowledge and Voice. Sierra Blog, 2026. https://sierra.ai/blog/ bench-advancing-agent-benchmarking-to-knowledge-and-voice
2026
-
[15]
Communications of the ACM, 5(11):558– 562, 1962
Kahn, A.B.Topological sorting of large networks. Communications of the ACM, 5(11):558– 562, 1962. Appendix 9.1 Running the Experiments A pilot run (5 tasks, 2 conditions) and full experiment (97 tasks, 4 conditions) are available via the project Makefile: 1# 5 - task pilot 2make pilot 3 4# Full 97 - task e x p e r i m e n t 5make e x p e r i m e n t 14 9....
1962
-
[16]
Request credit limit increase
-
[17]
\n < task_queue >\ n
File t r a n s a c t i o n dispute 4E ND _T AS KS The parsed list is stored in state.pending tasks and injected into the EXECUTION phase instruction as a<task queue>hint: 1q u e u e _ h i n t = ( 2" \n < task_queue >\ n " 3f " Pending : ␣ { ’ , ␣ ’. join ( f ’{ i +1}. ␣ { t } ’ ␣ for ␣i , ␣ t ␣ in ␣ en um er at e ( state . p e n d i n g _ t a s k s ) ) }\...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.