SVHighlights: Towards Extremely Long Sport Video Highlight Detection
Pith reviewed 2026-06-27 22:28 UTC · model grok-4.3
The pith
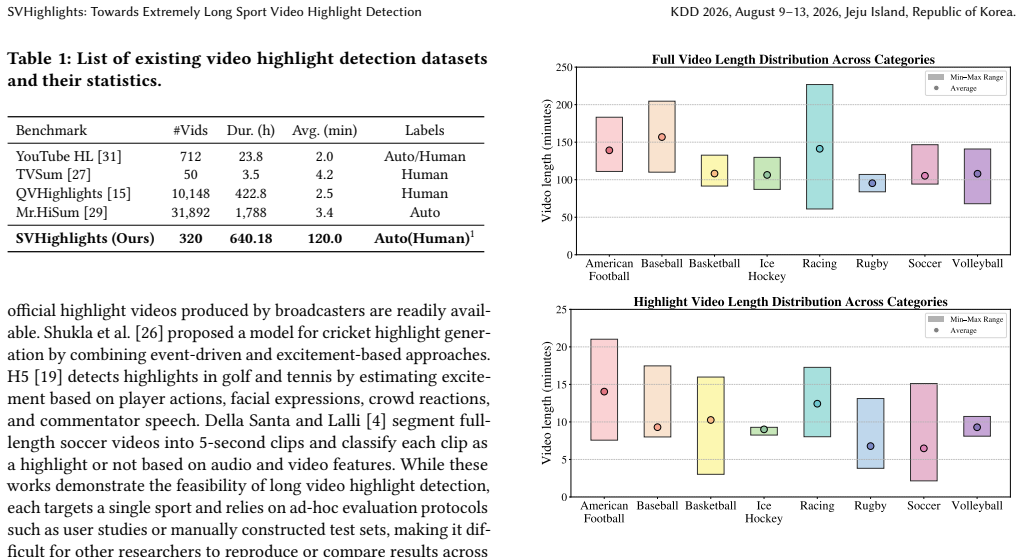
SVHighlights supplies the first benchmark for detecting highlights in sports videos longer than one hour by pairing full games with official recaps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SVHighlights is the first benchmark for highlight detection in extremely long sports videos exceeding one hour, built by matching full-length videos to official highlight videos for scalable label generation, and TF-SELECTOR, a training-free approach that divides videos into semantic segments and predicts saliency via multimodal LLM inputs, outperforms VTG-tuned baselines on this benchmark.
What carries the argument
TF-SELECTOR, which merges adjacent shots sharing semantic content into segments and feeds visual captions, transcripts, and audio volume to a large language model for segment-level saliency scores.
If this is right
- Label generation for long videos becomes scalable without exhaustive per-clip annotation.
- Models can process hour-long content by operating on merged segments rather than fixed short clips.
- Multimodal inputs including audio volume improve saliency prediction over vision-only or text-only baselines.
- A single training-free method can serve as a strong baseline across multiple sports categories.
Where Pith is reading between the lines
- The same pairing strategy could label highlights in other long-form domains such as lectures or surveillance footage.
- Segment merging might reduce compute cost for downstream tasks like summarization or search in long videos.
- If official highlights contain editorial bias, the benchmark may systematically under-represent certain event types.
Load-bearing premise
Matching full-length sports videos to their official highlight videos produces accurate, unbiased ground-truth labels for saliency.
What would settle it
Human annotators rating saliency on a random sample of clips produce labels that diverge substantially from the official-highlight-derived labels on the same clips.
Figures





read the original abstract
While highlight detection for long-form videos is of great practical importance, most existing methods remain limited to short-form content, largely due to the absence of a suitable benchmark. To bridge this gap, we introduce SVHighlights, to the best of our knowledge, the first benchmark for highlight detection in extremely long sports videos, each exceeding one hour in duration, across multiple sports categories. SVHighlights is constructed from pairs of full-length sports videos and their corresponding official highlight videos using a dataset generation pipeline, enabling scalable label generation without conventional per-clip saliency annotation. The benchmark comprises 320 videos with an average duration of 2.00 hours and a total of 640.18 hours, substantially exceeding previous datasets. Existing methods also face fundamental challenges on long videos: models trained on short clips fail to generalize to hour-long content, and their clip-level scoring lacks the broader context needed to identify highlights. To address this and provide a strong baseline, we present TF-SELECTOR, a training-free segment-based approach that divides each video into context-aware segments by merging adjacent shots sharing the same semantic content, and predicts segment-level saliency scores using a large language model with multimodal inputs including visual captions, transcripts, and audio volume. Experiments demonstrate that TF-SELECTOR achieves superior performance across most metrics compared to Video Temporal Grounding (VTG)-tuned baselines, with improvements of +2.50 in HIT@1, +4.04 in HIT@K, and +2.95 in IoU. These results establish SVHighlights as a challenging testbed for long-form highlight detection and demonstrate that a simple segment-based strategy can effectively scale to hour-long videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce SVHighlights as the first benchmark for highlight detection in extremely long sports videos (>1 hour each), built from 320 videos (avg. 2h, total 640h) by aligning full-length content with official highlight reels to generate labels scalably without per-clip annotation. It further proposes TF-SELECTOR, a training-free segment-based baseline that merges semantically similar shots and scores segments via LLM using multimodal inputs (captions, transcripts, audio volume). Experiments report TF-SELECTOR outperforming VTG-tuned baselines by +2.50 HIT@1, +4.04 HIT@K, and +2.95 IoU.
Significance. If the generated labels prove reliable, the work supplies a much-needed large-scale testbed for long-form video saliency that prior short-clip datasets cannot address, and the training-free LLM-based approach demonstrates a practical path to scaling without retraining on hour-long content. The dataset scale and avoidance of per-clip annotation are concrete strengths.
major comments (3)
- [Dataset Generation Pipeline] Dataset construction section: The central claim that temporal alignment between full-length videos and official highlights yields accurate, unbiased saliency ground truth is unsupported by any reported human-agreement study, inter-annotator consistency check, or comparison against conventional per-clip annotations. This directly undermines all quantitative results, including the reported +2.50 HIT@1, +4.04 HIT@K, and +2.95 IoU gains of TF-SELECTOR.
- [Experiments] Experiments section: Performance improvements are stated as point estimates without error bars, statistical significance tests, details of the train/test split protocol, or ablation studies on segment merging and LLM prompting choices. This makes it impossible to assess whether the superiority claim is robust.
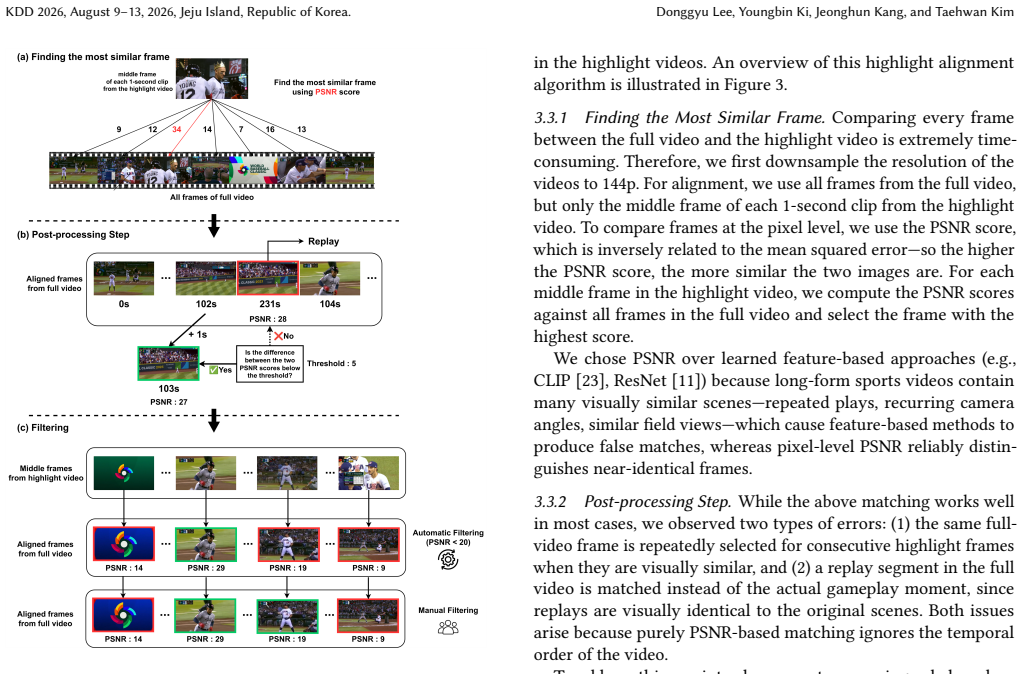
- [Method] TF-SELECTOR description: The method for merging adjacent shots and constructing the multimodal LLM prompt is presented only conceptually, with no pseudocode, exact merging criteria, or input formatting details. Reproducibility of the core baseline therefore cannot be verified from the text.
minor comments (2)
- The abstract states 'to the best of our knowledge' the first benchmark; a brief comparison table against prior long-video datasets would strengthen the novelty claim.
- Notation for HIT@K and IoU should be defined on first use in the main text rather than assumed from the abstract.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We address each of the major comments below, indicating the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Dataset Generation Pipeline] Dataset construction section: The central claim that temporal alignment between full-length videos and official highlights yields accurate, unbiased saliency ground truth is unsupported by any reported human-agreement study, inter-annotator consistency check, or comparison against conventional per-clip annotations. This directly undermines all quantitative results, including the reported +2.50 HIT@1, +4.04 HIT@K, and +2.95 IoU gains of TF-SELECTOR.
Authors: We acknowledge the importance of validating the generated labels. The SVHighlights dataset is constructed by aligning full-length videos with official highlight reels, which are produced by domain experts and represent authoritative selections of highlights. While we did not include a human study in the original submission, we agree this would enhance credibility. In the revision, we will add a human evaluation study on a subset of videos to report inter-annotator agreement and consistency with the generated labels. This addresses the concern about the reliability of the ground truth. revision: yes
-
Referee: [Experiments] Experiments section: Performance improvements are stated as point estimates without error bars, statistical significance tests, details of the train/test split protocol, or ablation studies on segment merging and LLM prompting choices. This makes it impossible to assess whether the superiority claim is robust.
Authors: We agree that providing error bars, statistical tests, split details, and ablations would improve the robustness assessment. In the revised manuscript, we will include standard deviations from multiple runs where applicable, p-values for significance, explicit description of the train/test split protocol, and ablation studies on the segment merging criteria and LLM prompt variations. revision: yes
-
Referee: [Method] TF-SELECTOR description: The method for merging adjacent shots and constructing the multimodal LLM prompt is presented only conceptually, with no pseudocode, exact merging criteria, or input formatting details. Reproducibility of the core baseline therefore cannot be verified from the text.
Authors: We will enhance the method section with pseudocode for the shot merging algorithm, precise criteria (such as semantic similarity thresholds using embeddings), and detailed examples of the multimodal prompt formatting including how captions, transcripts, and audio volume are integrated. This will ensure full reproducibility. revision: yes
Circularity Check
No circularity: empirical benchmark and training-free method rest on external comparisons
full rationale
The paper introduces SVHighlights via a dataset pipeline matching full videos to official highlights and evaluates TF-SELECTOR (a segment-merging + LLM scoring baseline) against VTG-tuned methods using standard metrics. No equations, fitted parameters, or derivations appear that reduce any reported gain (+2.50 HIT@1 etc.) to the inputs by construction. No self-citations are load-bearing for uniqueness theorems or ansatzes; the central claims are falsifiable via external baselines and do not rename known results or smuggle assumptions through prior author work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Official highlight videos serve as reliable proxies for human-perceived saliency without per-clip annotation
Reference graph
Works this paper leans on
-
[1]
Taivanbat Badamdorj, Mrigank Rochan, Yang Wang, and Li Cheng. 2021. Joint Visual and Audio Learning for Video Highlight Detection. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8107–8117
2021
-
[2]
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. 2023. WhisperX: Time-Accurate Speech Transcription of Long-Form Audio. InInterspeech 2023. 4489–4493
2023
-
[3]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al . 2024. Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling.arXiv preprint arXiv:2412.05271(2024). KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Donggyu Lee, You...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [4]
-
[5]
Ana Garcia del Molino and Michael Gygli. 2018. PHD-GIFs: Personalized High- light Detection for Automatic GIF Creation. InProceedings of the 26th ACM International Conference on Multimedia. 600–608
2018
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Qihao Guan. 2024. The Impact of Short Videos on Long Video Engagement: A Comparative Analysis of Promotional and Non-Promotional Content on YouTube. A vailable at SSRN 4979201(2024)
2024
-
[8]
Yongxin Guo, Jingyu Liu, Mingda Li, Dingxin Cheng, Xiaoying Tang, Dianbo Sui, Qingbin Liu, Xi Chen, and Kevin Zhao. 2025. VTG-LLM: Integrating Times- tamp Knowledge into Video LLMs for Enhanced Video Temporal Grounding. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 3302–3310
2025
-
[9]
Yongxin Guo, Jingyu Liu, Mingda Li, Qingbin Liu, Xi Chen, and Xiaoying Tang
-
[10]
In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
TRACE: Temporal Grounding Video LLM via Causal Event Modeling. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net
2025
-
[11]
Michael Gygli, Yale Song, and Liangliang Cao. 2016. Video2GIF: Automatic Gen- eration of Animated GIFs from Video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1001–1009
2016
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 770–778
2016
-
[13]
Zahidul Islam, Sujoy Paul, and Mrigank Rochan. 2025. Unsupervised Video Highlight Detection by Learning from Audio and Visual Recurrence. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). IEEE, 8702–8711
2025
-
[14]
Yifan Jiao, Xiaoshan Yang, Tianzhu Zhang, Shucheng Huang, and Changsheng Xu. 2017. Video Highlight Detection via Deep Ranking Modeling. InImage and Video Technology: 8th Pacific-Rim Symposium, PSIVT 2017, Wuhan, China, November 20-24, 2017, Revised Selected Papers 8. Springer, 28–39
2017
-
[15]
Sungshin Kwak, Jaedong Lee, and Sohyun Park. 2025. The Effective Highlight- Detection Model for Video Clips Using Spatial—Perceptual.Electronics14, 18 (2025), 3640
2025
-
[16]
Jie Lei, Tamara L Berg, and Mohit Bansal. 2021. Detecting Moments and High- lights in Videos via Natural Language Queries. InAdvances in Neural Information Processing Systems, Vol. 34. 11846–11858
2021
-
[17]
Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shraman Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, and Mike Zheng Shou. 2023. UniVTG: Towards Unified Video-Language Temporal Grounding. InProceedings of the IEEE/CVF International Conference on Computer Vision. 2782–2792
2023
-
[18]
Ye Liu, Jixuan He, Wanhua Li, Junsik Kim, Donglai Wei, Hanspeter Pfister, and Chang Wen Chen. 2024. R2-Tuning: Efficient Image-to-Video Transfer Learning for Video Temporal Grounding. InEuropean Conference on Computer Vision. Springer, 421–438
2024
-
[19]
Ye Liu, Siyuan Li, Yang Wu, Chang Wen Chen, Ying Shan, and Xiaohu Qie. 2022. UMT: Unified Multi-modal Transformers for Joint Video Moment Retrieval and Highlight Detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3032–3041
2022
-
[20]
Michele Merler, Khoi-Nguyen C Mac, Dhiraj Joshi, Quoc-Bao Nguyen, Stephen Hammer, John Kent, Jinjun Xiong, Minh N Do, John R Smith, and Rogério Schmidt Feris. 2019. Automatic Curation of Sports Highlights Using Multimodal Excite- ment Features.IEEE Transactions on Multimedia21, 5 (2019), 1147–1160
2019
- [21]
-
[22]
WonJun Moon, Sangeek Hyun, Sanguk Park, Dongchan Park, and Jae-Pil Heo
-
[23]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Query-Dependent Video Representation for Moment Retrieval and High- light Detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23023–23033
-
[24]
John Paparrizos, Paul Boniol, Themis Palpanas, Ruey S Tsay, Aaron J Elmore, and Michael J Franklin. 2022. Volume Under the Surface: A New Accuracy Evaluation Measure for Time-Series Anomaly Detection.Proc. VLDB Endow.15, 11 (2022), 2774–2787
2022
-
[25]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InInternational Conference on Machine Learning. PMLR, 8748–8763
2021
-
[26]
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. 2024. TimeChat: A Time- sensitive Multimodal Large Language Model for Long Video Understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14313–14323
2024
-
[27]
Mrigank Rochan, Mahesh Kumar Krishna Reddy, Linwei Ye, and Yang Wang
-
[28]
In European Conference on Computer Vision
Adaptive Video Highlight Detection by Learning from User History. In European Conference on Computer Vision. Springer, 261–278
-
[29]
Pushkar Shukla, Hemant Sadana, Apaar Bansal, Deepak Verma, Carlos E. L. Elmadjian, Balasubramanian Raman, and Matthew Turk. 2018. Automatic Cricket Highlight Generation Using Event-Driven and Excitement-Based Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 1800–1808
2018
-
[30]
Yale Song, Jordi Vallmitjana, Amanda Stent, and Alejandro Jaimes. 2015. TVSum: Summarizing web videos using titles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5179–5187
2015
-
[31]
Tomáš Souček and Jakub Lokoč. 2024. TransNet V2: An Effective Deep Network Architecture for Fast Shot Transition Detection. InProceedings of the 32nd ACM International Conference on Multimedia. 11218–11221
2024
-
[32]
Jinhwan Sul, Jihoon Han, and Joonseok Lee. 2023. Mr. HiSum: A Large-scale Dataset for Video Highlight Detection and Summarization. InAdvances in Neural Information Processing Systems, Vol. 36. 40542–40555
2023
-
[33]
Hao Sun, Mingyao Zhou, Wenjing Chen, and Wei Xie. 2024. TR-DETR: Task- Reciprocal Transformer for Joint Moment Retrieval and Highlight Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 4998–5007
2024
-
[34]
Min Sun, Ali Farhadi, and Steven M. Seitz. 2014. Ranking Domain-Specific Highlights by Analyzing Edited Videos. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13. Springer, 787–802
2014
-
[35]
Caroline Violot, Tuğrulcan Elmas, Igor Bilogrevic, and Mathias Humbert. 2024. Shorts vs. Regular Videos on YouTube: A Comparative Analysis of User Engage- ment and Content Creation Trends. InProceedings of the 16th ACM Web Science Conference. 213–223
2024
-
[36]
Xiangfeng Wang, Xiao Li, Yadong Wei, Xueyu Song, Yang Song, Xiaoqiang Xia, Fangrui Zeng, Zaiyi Chen, Liu Liu, Gu Xu, and Tong Xu. 2025. From Long Videos to Engaging Clips: A Human-Inspired Video Editing Framework with Multimodal Narrative Understanding. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Trac...
2025
-
[37]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing13, 4 (2004), 600–612
2004
-
[38]
Minghao Xu, Hang Wang, Bingbing Ni, Riheng Zhu, Zhenbang Sun, and Changhu Wang. 2021. Cross-category Video Highlight Detection via Set-based Learning. InProceedings of the IEEE/CVF International Conference on Computer Vision. 7950– 7959
2021
-
[39]
Yifang Xu, Yunzhuo Sun, Benxiang Zhai, Youyao Jia, and Sidan Du. 2024. MH- DETR: Video Moment and Highlight Detection with Cross-modal Transformer. In2024 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–8
2024
-
[40]
Youngjae Yu, Sangho Lee, Joonil Na, Jaeyun Kang, and Gunhee Kim. 2018. A Deep Ranking Model for Spatio-Temporal Highlight Detection From a 360◦ Video. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32. 7525–7533. A Prompt Details We provide the detailed prompt for segment-level score prediction in Figure 6. B Video Trimming Details...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.