DataEvolver: Automatic Data Preparation for Large Language Models through Multi-Level Self-Evolving
Pith reviewed 2026-06-27 20:34 UTC · model grok-4.3
The pith
DataEvolver automatically constructs self-evolving pipelines that turn raw data into higher-quality training sets for large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
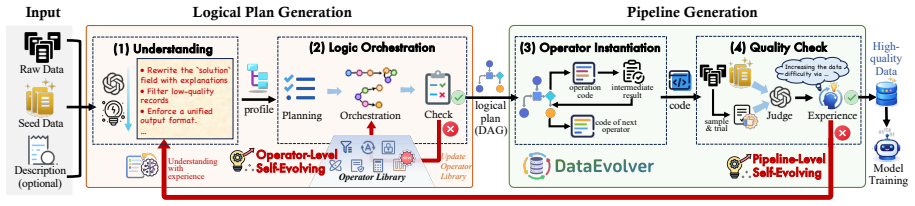
DataEvolver is the first self-evolving data preparation system that automatically constructs pipelines to transform raw data into high-quality data. At the operator level it incrementally expands the operator set to construct a logical plan while resolving dependency conflicts. At the pipeline level it instantiates logical plans into executable code and iteratively refines pipeline orchestration through a feedback loop that reduces the distribution gap between prepared data and high-quality examples.
What carries the argument
The multi-level self-evolving mechanism: operator-level incremental plan construction with dependency resolution, plus pipeline-level code instantiation and feedback-driven refinement.
If this is right
- LLMs trained on DataEvolver output outperform those trained on the same raw data by an average of 10 percent across tested benchmarks.
- The system adapts preparation logic to varied data distributions without requiring predefined pipelines or per-task human instructions.
- Pipeline executability is maintained while effectiveness is improved through the two-level refinement process.
- Data quality gains are achieved automatically and can be measured directly on downstream model performance.
- The approach supports iterative co-evolution between data preparation and model capability.
Where Pith is reading between the lines
- The same loop could be run repeatedly, letting each improved model version generate still-better preparation pipelines.
- Cost of data curation for new domains or languages could drop sharply if the method generalizes beyond the seven tested benchmarks.
- The operator-expansion step might be replaced by learned operators, turning the whole system into a meta-learning loop over data transformations.
- Similar multi-level evolution could be tested on non-LLM tasks that also need cleaned training data, such as vision or tabular models.
Load-bearing premise
The feedback loop can close the distribution gap to high-quality examples without creating new errors or biases in the prepared data.
What would settle it
Apply DataEvolver to a fresh raw dataset, train an LLM on the output, and observe whether downstream task scores show no gain or a loss relative to training on the original data.
Figures







read the original abstract
High-quality training data is essential to large language models (LLMs) and typically requires extensive and costly manual curation. Existing automatic data preparation methods rely on predefined pipelines or customized human instructions, which limits their adaptability to diverse data distributions and lacks principled guidance from high-quality examples. In this paper, we introduce DataEvolver, the first self-evolving data preparation system that automatically constructs pipelines to transform raw data into high-quality data. DataEvolver employs a multi-level mechanism to ensure both pipeline executability and effectiveness. At the operator level, it incrementally expands the operator set to construct a logical plan while resolving dependency conflicts. At the pipeline level, it instantiates logical plans into executable code and iteratively refines pipeline orchestration through a feedback loop that reduces the distribution gap between prepared data and high-quality examples. Experiments on seven benchmarks show that DataEvolver substantially improves data quality and achieves an average 10\% gain in downstream LLM performance compared with training on original data, highlighting new opportunities for the iterative co-evolution of LLMs and data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DataEvolver, the first self-evolving automatic data preparation system for LLMs. It uses a multi-level mechanism (operator-level incremental expansion of operators with dependency resolution, and pipeline-level instantiation into executable code with iterative feedback-loop refinement) to transform raw data into high-quality examples that reduce distribution gaps. Experiments on seven benchmarks are reported to show substantial data-quality improvements and an average 10% gain in downstream LLM performance versus training on the original unprepared data.
Significance. If the empirical claims hold under proper controls, the work would demonstrate a viable path for automated, adaptive data preparation that co-evolves with LLMs, potentially reducing reliance on manual curation. The multi-level self-evolution idea is conceptually novel relative to fixed-pipeline approaches.
major comments (2)
- [Experiments] Experimental evaluation (abstract and Experiments section): all reported gains (average 10% downstream improvement) are measured exclusively against training on the original raw data. No comparisons are provided against the “predefined pipelines or customized human instructions” methods that the introduction criticizes as limited; this leaves the central claim that the multi-level self-evolving machinery delivers improvement beyond existing automatic preparation techniques untested.
- [§3.2] Feedback-loop claim (abstract and §3.2): the assertion that the pipeline-level feedback loop “reduces the distribution gap … without introducing new errors or biases” is not supported by any ablation that isolates the loop’s effect on bias or error introduction, nor by quantitative distribution-distance metrics before/after refinement.
minor comments (1)
- [Abstract] The abstract states results on “seven benchmarks” but does not name them or describe the downstream tasks, model sizes, or training protocols; this information should appear in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our claims. We address each major comment below and commit to revisions that strengthen the empirical support.
read point-by-point responses
-
Referee: [Experiments] Experimental evaluation (abstract and Experiments section): all reported gains (average 10% downstream improvement) are measured exclusively against training on the original raw data. No comparisons are provided against the “predefined pipelines or customized human instructions” methods that the introduction criticizes as limited; this leaves the central claim that the multi-level self-evolving machinery delivers improvement beyond existing automatic preparation techniques untested.
Authors: We agree that direct comparisons to the methods criticized in the introduction would more convincingly demonstrate the advantage of the self-evolving approach over fixed pipelines or human-instructed methods. The current experiments prioritize measuring gains relative to raw data to establish the value of automated preparation. In the revised manuscript we will add these baselines using representative predefined-pipeline and instruction-based systems on the same seven benchmarks. revision: yes
-
Referee: [§3.2] Feedback-loop claim (abstract and §3.2): the assertion that the pipeline-level feedback loop “reduces the distribution gap … without introducing new errors or biases” is not supported by any ablation that isolates the loop’s effect on bias or error introduction, nor by quantitative distribution-distance metrics before/after refinement.
Authors: We acknowledge the need for explicit evidence isolating the feedback loop. The current description relies on the iterative refinement process and downstream performance, but additional controls are warranted. In revision we will add an ablation that disables the loop, report quantitative distribution-distance metrics (e.g., KL divergence on embedding distributions) before and after refinement, and discuss observed effects on error or bias introduction. revision: yes
Circularity Check
No circularity: system description with no derivations or self-referential reductions.
full rationale
The paper presents a descriptive system (DataEvolver) for automatic data preparation via multi-level self-evolution, with claims resting on empirical benchmarks rather than any mathematical derivation chain. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims (10% downstream gain, distribution gap reduction) are tested against raw data baselines and do not reduce to inputs by construction. This is the expected non-finding for an applied systems paper without formal derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
AlpaGasus: Training A Better Alpaca with Fewer Data , author=. 2024 , eprint=
2024
-
[2]
2026 , eprint=
A Survey of Data Agents: Emerging Paradigm or Overstated Hype? , author=. 2026 , eprint=
2026
-
[3]
2023 , eprint=
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning , author=. 2023 , eprint=
2023
-
[4]
2023 , eprint=
LIMA: Less Is More for Alignment , author=. 2023 , eprint=
2023
-
[5]
2023 , eprint=
\# InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models , author=. 2023 , eprint=
2023
-
[6]
2023 , eprint=
MoDS: Model-oriented Data Selection for Instruction Tuning , author=. 2023 , eprint=
2023
-
[7]
2023 , eprint=
Self-Refine: Iterative Refinement with Self-Feedback , author=. 2023 , eprint=
2023
-
[8]
IEEE Data Engineering Bulletin , volume=
Data Cleaning: Problems and Current Approaches , author=. IEEE Data Engineering Bulletin , volume=. 2000 , url=
2000
-
[9]
Introducing ChatGPT , year =
-
[10]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[11]
2023 , eprint=
LLaMA: Open and Efficient Foundation Language Models , author=. 2023 , eprint=
2023
-
[12]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[13]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[14]
2019 , eprint=
AlphaClean: Automatic Generation of Data Cleaning Pipelines , author=. 2019 , eprint=
2019
-
[15]
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages =
Kandel, Sean and Paepcke, Andreas and Hellerstein, Joseph and Heer, Jeffrey , title =. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages =. 2011 , isbn =. doi:10.1145/1978942.1979444 , abstract =
-
[16]
and Ehrenberg, Henry and Fries, Jason and Wu, Sen and R\'
Ratner, Alexander and Bach, Stephen H. and Ehrenberg, Henry and Fries, Jason and Wu, Sen and R\'. Snorkel: rapid training data creation with weak supervision , year =. Proc. VLDB Endow. , month = nov, pages =. doi:10.14778/3157794.3157797 , abstract =
-
[17]
2023 , eprint=
SemDeDup: Data-efficient learning at web-scale through semantic deduplication , author=. 2023 , eprint=
2023
-
[18]
2023 , eprint=
Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation , author=. 2023 , eprint=
2023
-
[19]
2023 , eprint=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. 2023 , eprint=
2023
-
[20]
2023 , eprint=
The Rise and Potential of Large Language Model Based Agents: A Survey , author=. 2023 , eprint=
2023
-
[21]
2023 , eprint=
Data-Juicer: A One-Stop Data Processing System for Large Language Models , author=. 2023 , eprint=
2023
-
[22]
2025 , eprint=
Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for and with Foundation Models , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Text-to-Pipeline: Bridging Natural Language and Data Preparation Pipelines , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
Prompt2DAG: A Modular Methodology for LLM-Based Data Enrichment Pipeline Generation , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
LLaPipe: LLM-Guided Reinforcement Learning for Automated Data Preparation Pipeline Construction , author=. 2025 , eprint=
2025
-
[27]
Grafberger, Stefan and Groth, Paul and Schelter, Sebastian , title =. 2025 , issue_date =. doi:10.14778/3750601.3750671 , journal =
-
[28]
2024 , eprint=
DoPAMine: Domain-specific Pre-training Adaptation from seed-guided data Mining , author=. 2024 , eprint=
2024
-
[29]
2025 , eprint=
Language Models as Continuous Self-Evolving Data Engineers , author=. 2025 , eprint=
2025
-
[30]
2025 , eprint=
AgentEvolver: Towards Efficient Self-Evolving Agent System , author=. 2025 , eprint=
2025
-
[31]
2024 , eprint=
Symbolic Learning Enables Self-Evolving Agents , author=. 2024 , eprint=
2024
-
[32]
2025 , eprint=
A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems , author=. 2025 , eprint=
2025
-
[33]
2020 , eprint =
Scaling Laws for Neural Language Models , author =. 2020 , eprint =
2020
-
[34]
2022 , eprint=
Training Compute-Optimal Large Language Models , author=. 2022 , eprint=
2022
-
[35]
2025 , eprint=
DataComp-LM: In search of the next generation of training sets for language models , author=. 2025 , eprint=
2025
-
[36]
2023 , eprint =
Data-centric Artificial Intelligence: A Survey , author =. 2023 , eprint =
2023
-
[37]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[38]
2021 , eprint =
Finetuned Language Models Are Zero-Shot Learners , author =. 2021 , eprint =
2021
-
[39]
2022 , eprint =
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author =. 2022 , eprint =
2022
-
[40]
2023 , eprint =
WizardLM: Empowering Large Language Models to Follow Complex Instructions , author =. 2023 , eprint =
2023
-
[41]
ActiveClean: Interactive Data Cleaning For Statistical Modeling , author =. Proc. VLDB Endow. , year =. doi:10.14778/2994509.2994514 , url =
-
[42]
2019 , eprint =
AlphaClean: Automatic Generation of Data Cleaning Pipelines , author =. 2019 , eprint =
2019
-
[43]
2023 , eprint =
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines , author =. 2023 , eprint =
2023
-
[44]
Proceedings of the ACM on Management of Data , volume =
SAGA: A Scalable Framework for Optimizing Data Cleaning Pipelines for Machine Learning Applications , author =. Proceedings of the ACM on Management of Data , volume =. 2023 , doi =
2023
-
[45]
Proceedings of the 38th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL) , pages =
Automating String Processing in Spreadsheets Using Input-Output Examples , author =. Proceedings of the 38th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL) , pages =. 2011 , doi =
2011
-
[46]
Proceedings of the 2017 ACM International Conference on Management of Data (SIGMOD) , pages =
Foofah: Transforming Data By Example , author =. Proceedings of the 2017 ACM International Conference on Management of Data (SIGMOD) , pages =. 2017 , doi =
2017
-
[47]
2023 , eprint =
Self-planning Code Generation with Large Language Models , author =. 2023 , eprint =
2023
-
[48]
2023 , eprint =
Teaching Large Language Models to Self-Debug , author =. 2023 , eprint =
2023
-
[49]
2023 , eprint =
Self-Refine: Iterative Refinement with Self-Feedback , author =. 2023 , eprint =
2023
-
[50]
2023 , eprint =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. 2023 , eprint =
2023
-
[51]
2024 , eprint =
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators , author =. 2024 , eprint =
2024
-
[52]
2023 , howpublished =
Stanford Alpaca: An Instruction-following LLaMA Model (Code and Data Release) , author =. 2023 , howpublished =
2023
-
[53]
2018 , eprint =
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author =. 2018 , eprint =
2018
-
[54]
2021 , eprint =
Training Verifiers to Solve Math Word Problems , author =. 2021 , eprint =
2021
-
[55]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , year =. Measuring Mathematical Problem Solving With the. 2103.03874 , archivePrefix =
-
[56]
Tao Yu and Rui Zhang and Kai Yang and Michihiro Yasunaga and Dongxu Wang and Zifan Li and James Ma and Irene Li and Qingning Yao and Shanelle Roman and Zilin Zhang and Dragomir Radev , year =. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-. 1809.08887 , archivePrefix =
-
[57]
2023 , eprint=
Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs , author=. 2023 , eprint=
2023
-
[58]
GitHub repository , url =
Penedo, Guilherme and Kydlíček, Hynek and Cappelli, Alessandro and Sasko, Mario and Wolf, Thomas , title =. GitHub repository , url =. 2024 , publisher =
2024
-
[59]
2024 , eprint=
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research , author=. 2024 , eprint=
2024
-
[60]
2023 , eprint=
Data Selection for Language Models via Importance Resampling , author=. 2023 , eprint=
2023
-
[61]
2023 , eprint=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. 2023 , eprint=
2023
-
[62]
2024 , eprint=
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework , author=. 2024 , eprint=
2024
-
[63]
2023 , eprint=
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining , author=. 2023 , eprint=
2023
-
[64]
2025 , eprint =
Qwen3 Technical Report , author =. 2025 , eprint =
2025
-
[65]
2025 , eprint =
Gemma 3 Technical Report , author =. 2025 , eprint =
2025
-
[66]
2024 , eprint=
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning , author=. 2024 , eprint=
2024
-
[67]
OpenCompass: A Universal Evaluation Platform for Foundation Models , author=
-
[68]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[69]
2026 , eprint=
MemGovern: Enhancing Code Agents through Learning from Governed Human Experiences , author=. 2026 , eprint=
2026
-
[70]
Sibei Chen and Nan Tang and Ju Fan and Xuemi Yan and Chengliang Chai and Guoliang Li and Xiaoyong Du , title =. Proc. 2023 , doi =
2023
-
[71]
2025 , eprint =
Meihao Fan and Ju Fan and Nan Tang and Lei Cao and Guoliang Li and Xiaoyong Du , title =. 2025 , eprint =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.